深入学习正则表达式


举个例子:当我们实现一段文本的语句,我们想要抽离出格式为连续的4个数字;
此时如果编写一个程序的话 代价会很高,因此我们搞出正则表达式
 正则表达式的底层实现:
正则表达式的底层实现:


底层源码分析:
——————————————————————————————————————————
查一条语法:
Java遵循左闭右开的原则: 虽然这里截取的是索引0到4 但是是左闭右开的区间 因此只打印abcd
虽然这里截取的是索引0到4 但是是左闭右开的区间 因此只打印abcd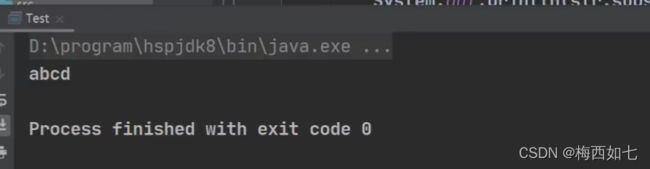
——————————————————————————————————————————
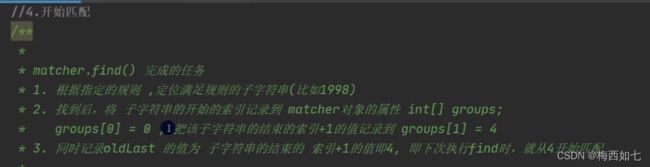
OK当我们执行第二次 find()操作的时候 还是matcher这个对象的属性:group数组进行存储它的索引位置,,,,第二次存的是1999。

我们这里还是默认是group[0]存储1999中首字符1的索引
group[1]存储1999中最后一个字符的索引下标
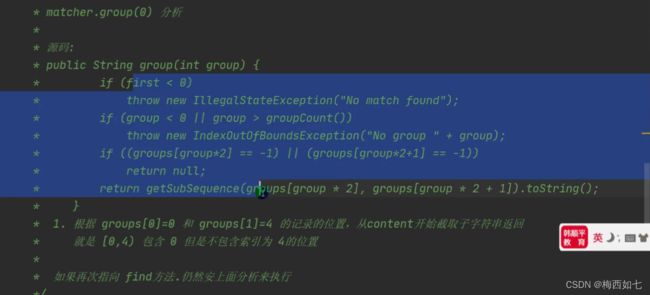
由源码可知:
每一次都getSubSequence根据数组中保存的索引值的范围进行截取,之后return返回截取的字符串

对于正则表达式_当我们考虑分组的时候:
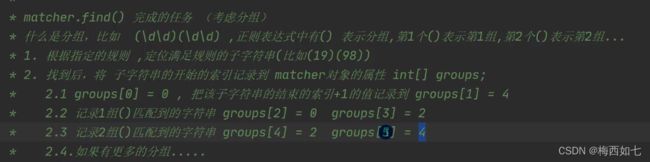
调试分析:

总结:当我们考虑正则表达式分组的时候,就不仅仅是group[0]和group[1]进行存储了
如上图所示
分组的形式再记一下:

分组代码:
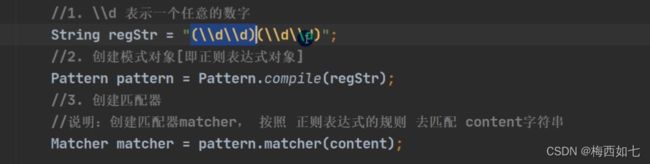
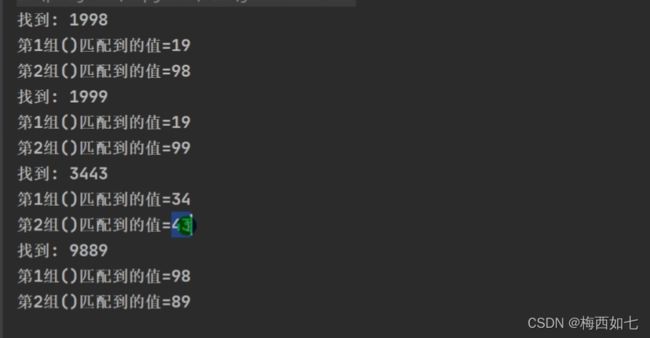
 结果:
结果:

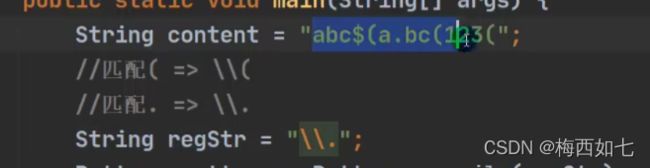
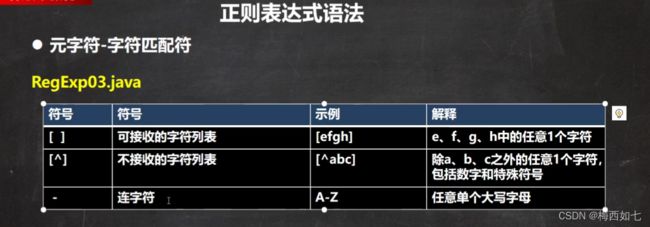
正则表达式语法:

我们要用\\代表\
 \\d{3}:代表\d出现三次。。。
\\d{3}:代表\d出现三次。。。
如图:

笔记:
1. 一个 . 占用一个字符大小空间
2.\\d{3}(\\d)?
其中问号表示0个或者1个
那么整体表示三个或四个数字的字符串
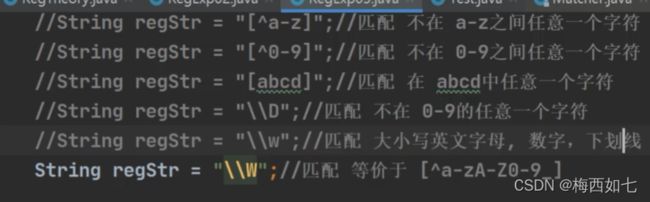
3.\\w可表示数字或者大小写字母字符![]()
4.大写字母表示取反面 \\W表示非数字非大小写字母
这里的 + 号表示1到多:这个例子\\W+\\d{2}
![]()

(?i)这个字符只对后面的字符起作用
 我们指定某一段不区分大小写:
我们指定某一段不区分大小写:

我们也可以用一个指定的参数来表示不区分大小写:



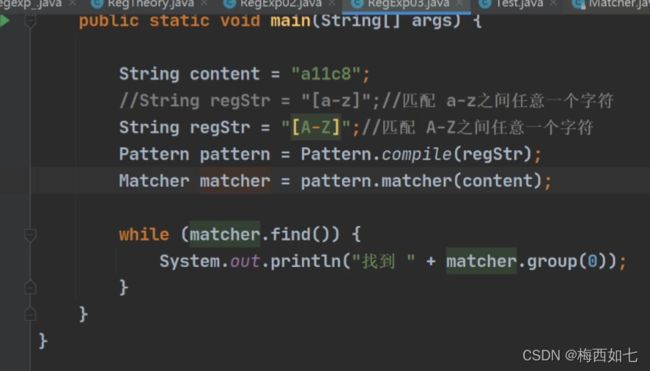
匹配字符的实例:

笔记:
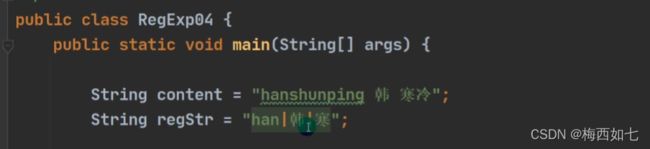
选择匹配符: |
下图:表示即可选择han也可选择韩也可选择寒
限定符:
 表示至少有一个m开头,?只与离它最近的c进行起作用,,,,
表示至少有一个m开头,?只与离它最近的c进行起作用,,,,


\\d{2}表示找到任意两位的数字字符 找到所有的任意两位数字字符,,,,,所有的,,
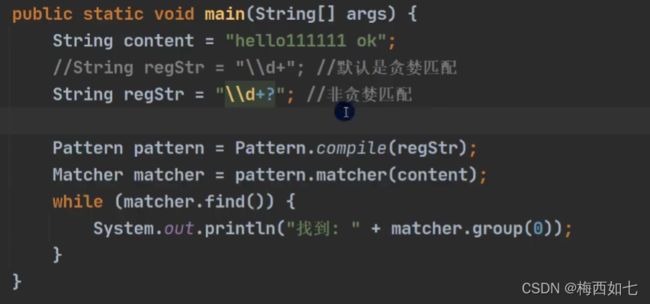
Java是贪婪匹配:
尽可能匹配多的。。。。。


 先进行贪婪匹配:匹配5个1 之后剩余两个1 由于我们设定的范围是2到5
先进行贪婪匹配:匹配5个1 之后剩余两个1 由于我们设定的范围是2到5
那么可以再匹配2个1

限定符:



a1?:表示a后面可接1也可不接1

定位符: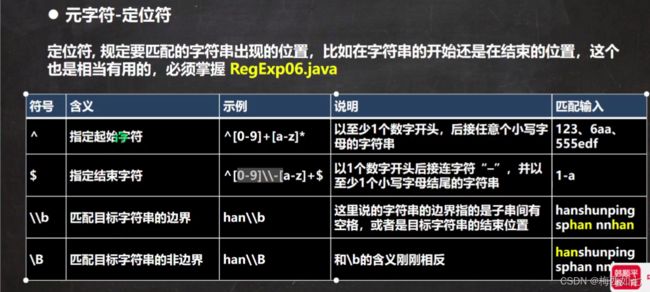
获得正则表达式对象的操作快捷键:
例子: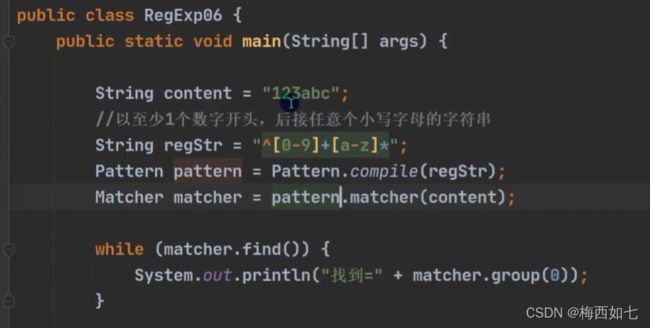

但是当我们更改content之后,把首字符改变成为a

匹配结果是空
 ——————————————————————————————————————————
——————————————————————————————————————————
 我们后面的[a-z]*表示的意思是0到多 那么我们就可以只匹配前面的
我们后面的[a-z]*表示的意思是0到多 那么我们就可以只匹配前面的
^表示起始 [0-9]+表示至少1个数字开头 但是由贪婪匹配原则可知:

——————————————————————————————————————————
结束符:
当题目中或实际开发出现必须以什么什么结束的时候
我们就要用到 $ 这个结束标识符了
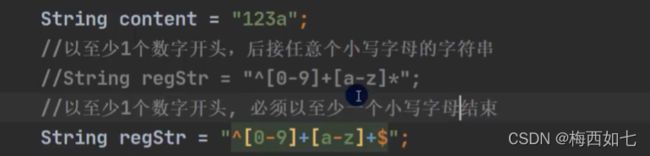

表示至少有一个小写字母结束 倘若最后一个字母不是小写字母那么匹配不成功


表示至少有一个 - 在中间,

han\\b 表示匹配的是边界的han
 注意一点就行:不一定非要结尾才能说是边界 当中间有空格的时候我们也可以称之为是边界
注意一点就行:不一定非要结尾才能说是边界 当中间有空格的时候我们也可以称之为是边界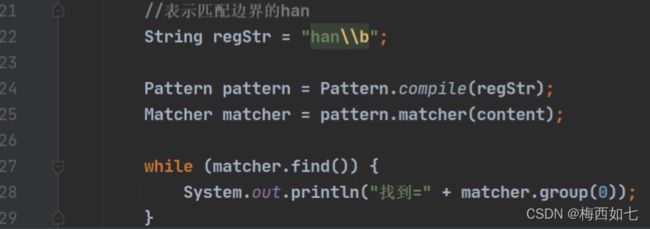


这个和小写的是正好相反的
———————————————————————————————————————————
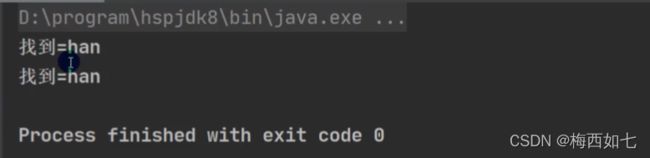
 情况一:
情况一: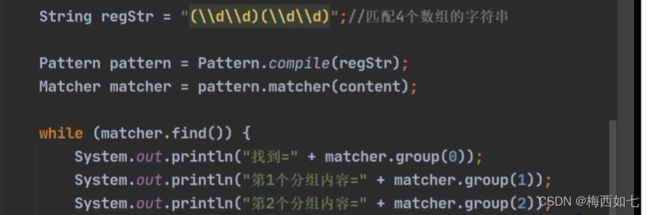
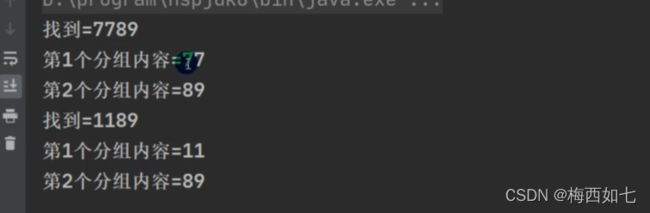
情况二:当我们分为三组的时候 是把77放到第一组中去了 把8放到第二组 9放到第三组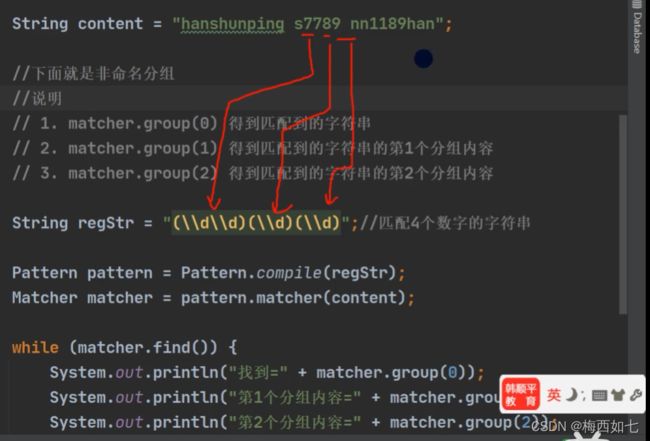
 命名分组:
命名分组:

好处在于我们之后可以通过别的方式去取:
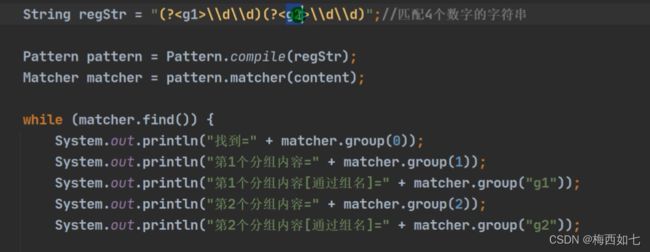 两种取的方法:
两种取的方法: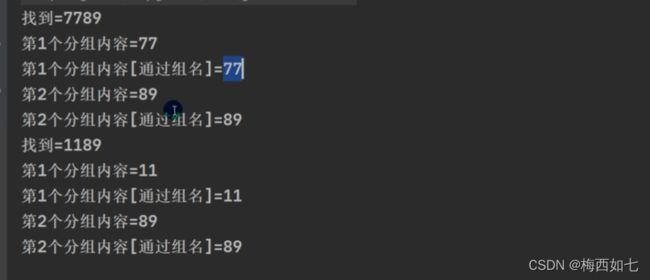
分组的多种形式:
演示非捕获分组:
1.


这两种写法是等价的
(?:|)
表示这三种都可能取到 表示的意思是可以取到韩顺平教育或韩顺平老师或韩顺平同学
但是对于非捕获的分组不可以写成:
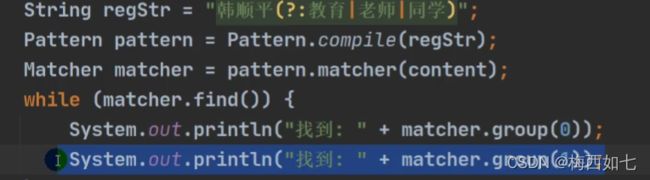

对于这种非捕获的分组我们只可以写一个group[0]不可以写再多的了
2.


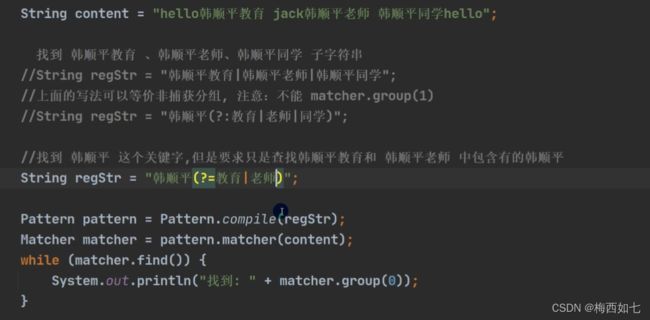

3.

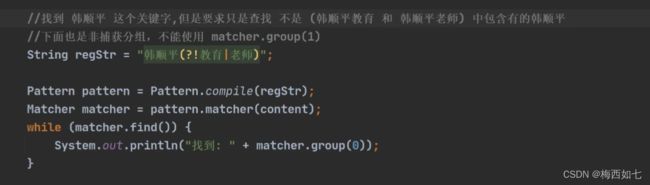
_____________________________________________________________________________非贪婪匹配:
在限定符后面加上一个 ? 表示尽可能的匹配少的
但是注意我们Java当中默认是贪婪匹配(尽可能的匹配多的)
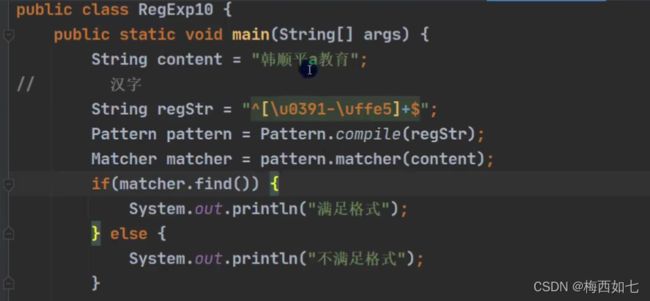
实例应用:

1.汉字
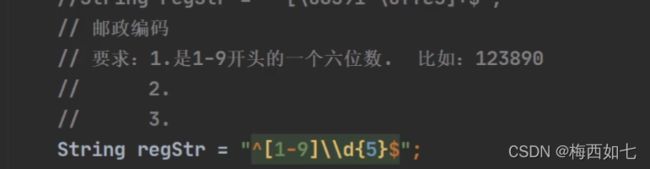
 2.邮政编码
2.邮政编码
3.QQ号
 4.手机号
4.手机号
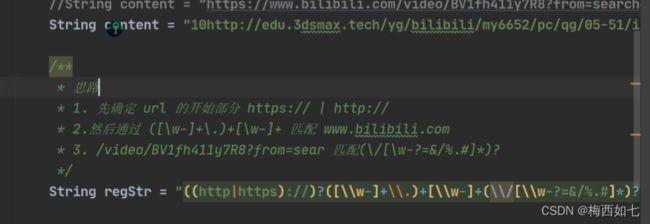
 5.URL验证
5.URL验证
 第一,二部分:
第一,二部分: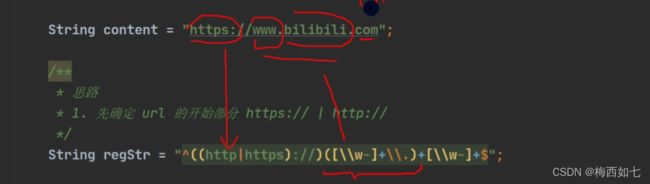
当我们把?写到[ ]里面的时候就代表 它是一个实实在在的 ?了 不再代表是限定符
当然 . 是同理

第三部分: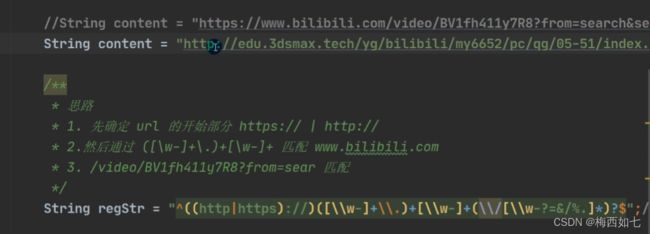
([\\w-?=&/%.]*)?
*表示在[ ]中的字符有任意多个
[ ]中的字符只是确定了一个可能取到的所有值的包括范围而已
但我们写域名的时候不一定非要取完
?在外面的时候表示的是限定符,表示为0个或1个


——————————————————————————————————————————
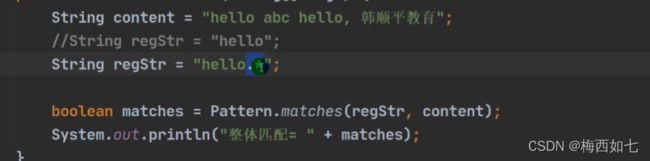
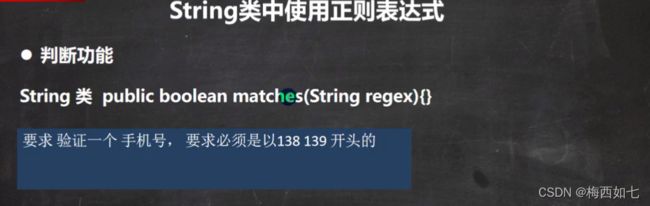
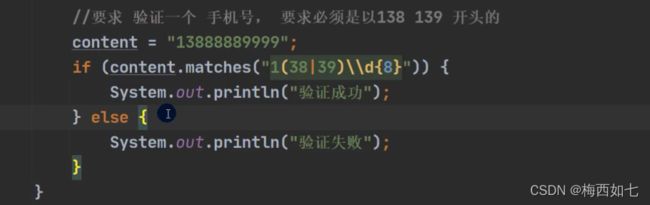
当我们要验证某一个字符串是否满足某一个规则的时候:
我们直接用matches进行匹配:

但是这里的hello并不能匹配整体的字符串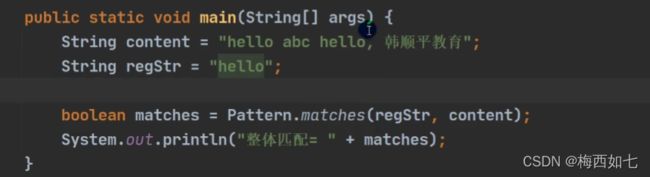
为了可以匹配到整体字符串:
我们在后面加上一个 . 一个 *
这里的*修饰这个 .表示可以后面接除了\n之外的所有字符 数量为任意多个


优点:简洁
缺点: 这可以匹配整体,不可以匹配部分
————————————————————————————————————————
当我们用find进行添加的时候
我们必须在开头和结尾加上定位符 ^和$
表示的意思就是我们以此开头 以此结尾
但是:
当我们用matches进行匹配的时候 就不用加定位符了
因为这里表示的是 regStr这个正则匹配的是整个content
当我们匹配一部分的时候是不可以返回true的

例子:
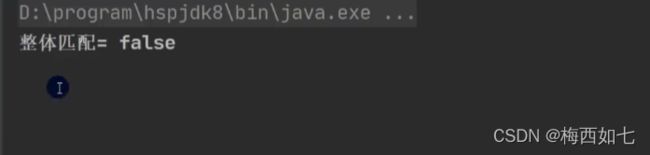
因为我们没有加首位的定位符 ^ 所以我们无法确定从哪里开始匹配
因此find()返回满足
然而匹配的不是整体 matches返回false
—————————————————————————————————————————

拿到每一个hello的索引下标: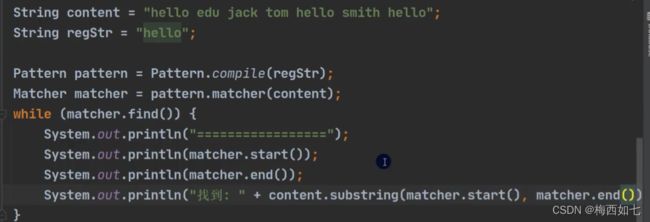

——————————————————————————————————————————
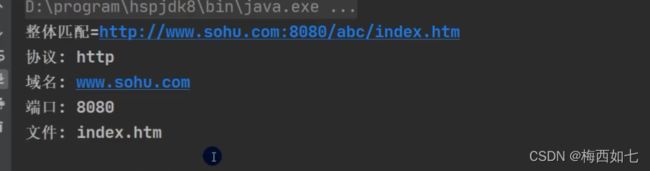
整体匹配:

两种匹配方式:
1.
 这一种返回true
这一种返回true
因为 .* 其中 . 表示除\n外的所有字符 * 表示任意多个
这种方法使 regStr把整个content都匹配上了
2.

返回false
只匹配到了hello 那么用matches方法必须返回整体才会返回true


 把匹配器和matcher都应该换一下
把匹配器和matcher都应该换一下
 返回后的字符串才是替换后的字符串 原来的content不变化
返回后的字符串才是替换后的字符串 原来的content不变化
输出:

反向引用:
 反向引用:
反向引用:
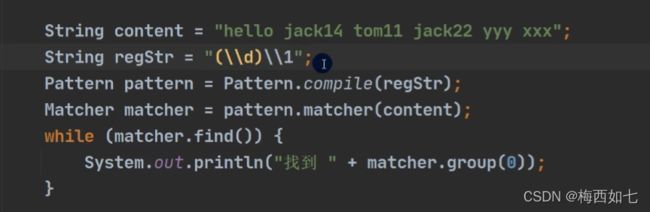
(\\d)\\1:\\d表示随机0到9的数字 之后\\1反向引用它 表示这一位的数字与第一位是相同的
(\\d)(\\d)\\2\\1:
\\2表示反向引用第二个子表达式
\\1表示反向引用第一个子表达式

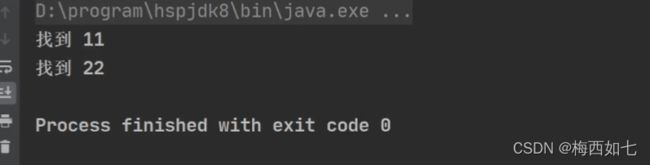
例子:14找不到。。。。
变式:
这里表示的(\\d)\\1{4}:
表示的意思是反向引用第一位的数字四次也就是要匹配五个连续相同的数字

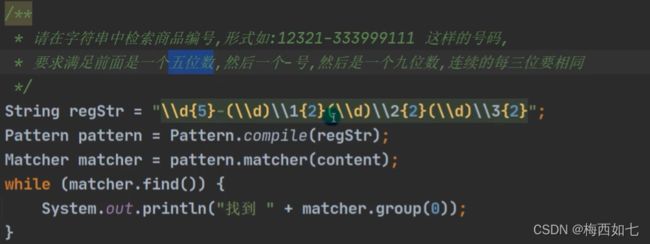

matcher直接调用replaceAll这个API:这个API表示的作用是用括号里面的内容进行代替我们已经匹配器匹配到的要取代的内容
如图:我们模式对象pattern把\\.传递给匹配器matcher 让匹配器按照这个原则去匹配content字符串 最后执行replaceAII 表示用空格代替所有的 .
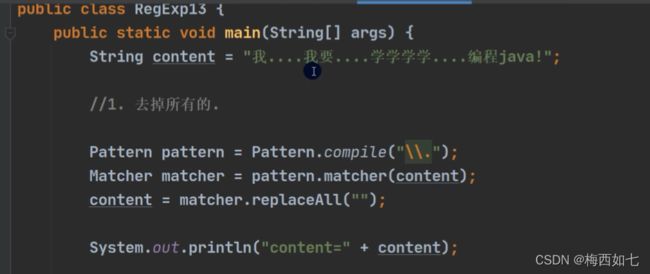
2.
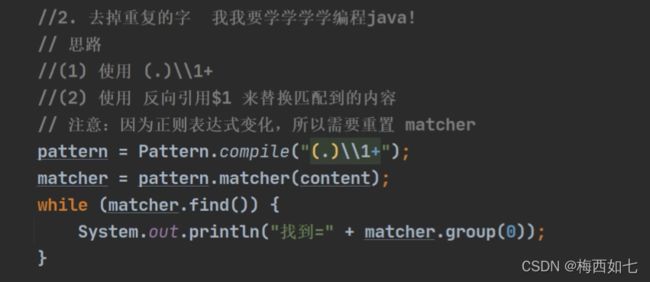 这里的(.)\\1+表示找到所有重复的字符 +表示重复的次数为至少一次
这里的(.)\\1+表示找到所有重复的字符 +表示重复的次数为至少一次
当然也可以用 *结尾 (已经测验过了)结果都一样

3.

$1表示反向引用所有重复的第一个子表达式:即是第一个分的组 (.)
这个组表达式表示的意思是除了\n的所有字符
但是()里面的内容只是重复一次 起到了去重的作用

用一条语句替换:
replaceAll("$1")表示的意思是用一个子表达式中单个的字符去替换所有重复的字符
因为

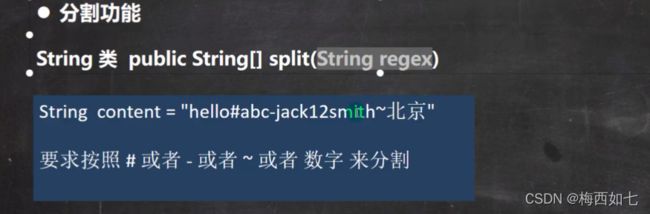
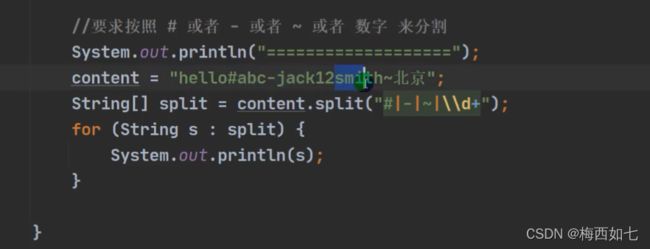
String类直接替换的方法:
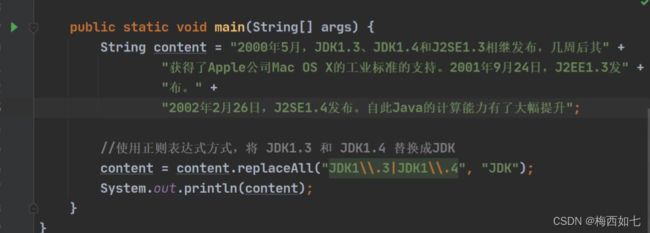
 ——————————————————————————————————————————
——————————————————————————————————————————
练习题:

注意一个细节:

这个 . 只有加在 [ ]中才是表示它本身其余的
加在( )里面的和其他的地方的都表示除\n的任意字符
因此我们必须转义



这个题比较难。

 细节注意总结:
细节注意总结:
我们在获取的时候是想要屏蔽abc的![]() 因为这是我们不需要的东西
因为这是我们不需要的东西
因此当我们进行分组的时候 不会把它放到( )里面之后去捕获它 而是放到 [ ]里面
当我们利用group数组进行打印时:不会打印[ ]里面的内容