第21章 JUC并发编程
通过本章的学习可以学到:掌握java.util.concurrent(JUC)开发框架的·核心接口与使用特点,掌握TimeUnit类的作用,并且可以使用此类实现日期时间数据转换,掌握多线程原子操作类的实现以及与volatile关键字的应用,理解ThreadFactory类的作用与使用,掌握线程同步锁的作用,理解互斥锁与读写锁的应用,掌握线程同步工具类的使用,掌握并发集合操作访问,可以深刻理解普通集合在并发访问下的异常产生原理,掌握阻塞队列与延迟队列的使用,并深刻理解延迟队列针对数据缓存的实现原理,掌握线程池的概念、分类以及线程池的拒绝策略。多线程是进行Java项目开发与设计中的重要组成部分,也是Java语言区别于其他语言的最大特点,但是传统的读线程实现机制在进行同步(包括等待与唤醒机制)处理时编写难度较高,所以为了进一步简化多线程同步处理机制,Java提供JUC并发编程开发包的支持。本章将完整讲解JUC的各个组成部分,并且将采用大量案例进行详细讲解。
21.1 JUC简介
多线程可以有效地提升程序的执行性能,在最初的Java编程模型中除了需要考虑程序性能外,还需要考虑线程死锁、公平性、资源管理以及如何避免线程安全性方面带来的危害等诸多因素,因而往往会采用一系列复杂的安全策略,加大了程序的实现困难。
为了简化多线程的开发难题,从JDK1.5开始提供了一个新的并发编程开发包java.util.concurrent(以下简称JUC),利用此包中提供的并发编程模型可以有效地减少竞争条件(race conditions)和死锁问题的出现。在java.util.concurrent包中支持的核心类如下

21.2 TimeUnit
TimeUnit(时间单元)是一个描述时间单元的枚举类,在该枚举类中定义有以下几个时间单元实例:天(DAYS)、时(HOURS)、分(MINUTES)、秒(SECONDS)、毫秒(MILLSECONDS)、微秒(MICROSECONDS)、纳秒(NANOSECONDS),利用此类可以方便的实现各个时间单元数据的转换,也可以更加方便的实现线程的休眠时间控制,该类提供的主要方法是
 范例:时间单元转换(将小时变为秒)
范例:时间单元转换(将小时变为秒)
package cn.mldn.demo;
import java.util.concurrent.TimeUnit;
public class JUCDemo
{
public static void main(String[]args)
{
long hour=1;
long second=TimeUnit.SECONDS.convert(hour,TimeUnit.HOURS);//由小时转化为秒单位
}
}
本程序通过TimeUnit获取了秒级对象SECONDS,随后将给定的小时转化为秒数据表示
范例:获取18天后的日期
package cn.mldn.demo;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.TimeUnit;
public class JUCDemo
{
public static void main(String[]args)
{
long current=System.currentTimeMills();//获取当前的时间
//利用当前的时间戳(毫秒)+18天的毫秒数
longafter=current+TimeUnit.MILLSECONDS.convert(18,TimeUnit.Days);
//将long数据转化为Date并且利用SimpleDateFormat进行格式化显示
System.out.println(new SimpleDateFormat("yyyy-MM-dd").format(new Date(after)));
}
}
本程序利用TimeUnit类提供的时间格式转换为处理操作,将指定的天数内容转为与之相匹配的毫秒数,而后在与当前的时间搓进行累加后即可得到18天后的日期时间戳数据。
在Thread类中提供的休眠方法Thread.sleep()是通过毫秒来定义休眠时间的,所以在进行休眠控制室往往都需要针对休眠时间对毫秒数据进行计算处理。而在TimeUnit类中也提供有sleep()休眠方法,此方法最大的特点是可以结合TimeUnit类提供的一系列实例化对象轻松地指定休眠时间的单位。
范例:使用TimeUnit休眠线程
package cn.mldn.demo;
import java.util.concurrent.TimeUnit;
public class JUCDemo
{
public static void main(String[]args)
{
new Thread(()->
{
for(int x=0;x<10;x++)
{
TimeUnit.MINUTES.sleep(1);
System.out.println(""+Thread.currentThread().getName()+x);
}
}).start();
}
}
本程序创建了一个线程对象,并且在本线程执行时利用TimeUnit类提供的sleep()方法直接设置休眠时间为一分钟。
21.3 原子操作类
在多线程操作中经常会出现多个线程对一个共享变量的并发修改,为了保证此操作的正确性,最初的时候可以通过synchronized关键字来操作。而从JDK1.5之后提供了java.util.concurrent.atomic操作包,该包中的原子操作类提供了一种用法简单、性能高效、线程安全的更新一个变量的方式。
在java.util.concurrent.atomic包中提供的原子操作类可以分为以下四类
基本类型:AtomicInterger、AtomicLong、AtomicBoolean
数组类型:AtomicIntergerArray、AtomicLongArray、AtomicReferenceArray
引用类型:AtomicReference、AtomicStampedReference、AtomicMarkableReference
对象的属性修改类型:AtomicIntergerFieldUpdater、AtomicLongFieldUpdater
提示:volatile关键字与原子操作类
原子操作类最大的特点是可以进行线程安全更新,即帮助用户使用一种更为简单地共享数据的线程同步操作,所以通过源代码可以发现,在这些原子类数据保存属性上都使用volatile关键字进行声明,这样就可以防止由于数据缓存所造成的数据更新不一致的问题。
21.3.1 基本类型原子操作类
基本类型原子操作类一共有三个:AtomicInterger、AtomicLong、AtomicBoolean,这三个类的原理和用啊类似,为了说明问题,将通过AtomicLong进行讲解,其常用方法如下: 提示:关于32位操作系统和64位操作系统在long操作上的区别
提示:关于32位操作系统和64位操作系统在long操作上的区别
在32位操作系统上,64位的long和double变量由于会被JVM当做两个个分离的32位来进行操作,所以不具备原子性,而使用AtomicLong能让long的操作保持原执行,下面给出了AtomicLong类中关于数据存储的部分源代码
private volatile long value;
public AtomicLong(long initialValue)
{
value=initialValue;
}
可以发现通过AtomicLong构造进行赋值时将数据内容通过value成员属性保存,而value成员塑性上使用了volatile关键字进行直接数据操作。
范例:使用AtomicLong进行原子性操作
package cn.mldn.demo;
import java.util.concurrent.atomic.AtomicLong;
public class JUCDemo
{
public static void main(String []args)
{
AtomicLong num=new AtomicLong(100L);//实例化原子操作类
num.addAndGet(200);//增加数据并取得
long curr=num.getAndIncrement();//先获取后自增
System.out.println(curr);//自增签的内容
System.out.println(num.get());
}
}
本程序啊将要操作的数据设置到了AtomicLong类示例中,并且对AtomicLong类中提供的原子性操作方法进行保存内容的操作。
范例:利用多线程操作数据
package cn.mldn.demo;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
AtomicLong num=new AtomicLong(100);//实例化原子操作类
for(int x=0;x<10;x++)
{
new Thread(()->{num.addAndGet(200);}).start();
}
TimeUnit.SECONDS.sleep(2);
System.out.println(num.get());自增后的内容
}
}
本程序启动10个线程同时帮助AtomicLong对象中保存的数据增加操作,通过最终的执行结果可以发现,AtomicLong已经帮助开发者实现了多线程的同步操作,通过最终的执行结果可以发现,AtomicLong已经帮助开发者实现了多线程的同步操作,得到了正确的计算结果。
范例:判断并设置新内容
package cn.mldn.demo;
import java.util.concurrent.atomic.AtomicLong;
public class JUCDemo
{
public static void main(String []args)throws Exception
{
AtomicLong num=new AtomicLong(100L);//实例化原子操作类
System.out.println(num.compareAndSet(100L,300L));//内容相同返回true
System.out.println(num.get());
}
}
本程序利用AtomicLong类中的compareAndSet()方法对要进行操作的内容进行判断,由于此时AtomicLong中保存的是100,并且判断的内容也是100,内容相同,所以可以保存新的数据,如果不相同则无法进行保存。
提示:关于CAS问题
在JUC中有两大核心操作:CAS、AQS,其中CAS是java.util.concurrentatomic包的基础,而AQS是同步缩的实现基础。
CAS(Compare And Swap)是一条CPU并发原语。它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程属于原子性操作。CAS并发原语体现在Java语言中就是sum.misc.Unsafe类中的各个方法。调用Unsafe类中的CAS方法,JVM会帮助开发者实现出CAS汇编指令。这是一种完全以雷雨硬件的功能,为了说明这个问题,下面来观察一下AtomicLong类中的源代码
| 成员属性 | private static final jdk.internal.misc.Unsafe U=jdk.internal.misc.Unsafe.getUnsafe(); |
| 成员属性 | private static finale long VALUE-U.objectFieldOffset(AtomicLong.class,"value"); |
| compareAndSet()方法 | public finale boolean compareAndSet(long expectedValue,long new Value){return U.compareAndSetLong(this,VALUE,expectedValue,newValue);} |
通过源代码的分析可以发现compareAndSet()方法时Unsafe()类负责执行CAS并发原语,由JVM转化为汇编,在代码中使用CAS自旋volatile变量的形式实现非阻塞并发,这种方式时CAS的主要使用方式。
CAS是乐观锁,是一种冲突重试机制,在并发竞争不是很激烈的情况下,其操作性能要好于悲观锁机制(synchronized同步处理)
21.3.2 数组原子操作类
数组原子操作类由3个:AtomicIntergerArray、AtomicLongArray、AtomicReferenceArray(对象数组),其操作原理和形式类似。下面使用AtomicReferenceArray类进行说明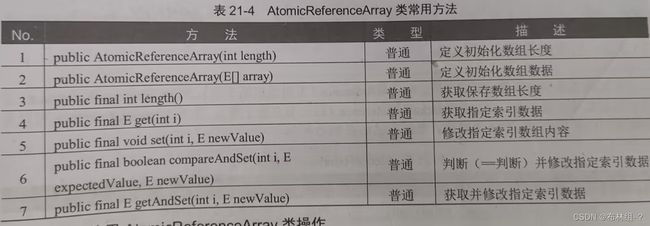
范例:使用AtomicReferenceArray类操作
package cn.mldn.demo;
import java.util.concurrent.atomic.AtomicReferenceArray;
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
String infos[]=new String[]{"A","B","C"};
AtomicReferenceArray
//自使用compareAndSet()方法进行比较时,是通过"=="方式实现的比较操作
System.out.println(array.compareAndSet(0,"AA","BB"));
System.out.println(array.get(0));
}
}
本程序实现了字符串对象数组的原子性保存,同时利用compareAndSet()方法实现了数组内容的修改。
提问:compareAndSet()修改时为什么传入匿名对象无法修改
对本程序而言,如果修改数据时通过匿名的String类对象比较,为什么无法成功设置:
System.out.println(array.compareAndSet(0,new String("AA"),"BBB"));
此时代码执行后的结果为false,内容也没有被交换,最为关键的是保存自定义类对象时法向此类方法同样也无法进行交换,为什么该方法不按照对象匹配的模式比较而只按照地址"=="的方式比较呢
回答:由底层C语言实现的
在Java层次上的数据比较有两类实现模式:hasCode()和equals()、比较器,但是在使用CAS方法时这两类操作都无法使用,只是简单实现了地址的比较,这实际上沿用了C语言的特点实现的。C语言是现代马参考如下:
int compare_and_swap(int *reg,int oldval,int newval)
{
int old_reg_val=*reg;
if(old_reg_val==oldval)
*reg=newval;
return old_reg_val;
}
可以发现此类操作是基于地址指针的形式实现的,所以只能使用"=="的方式进行地址判断
21.3.3 引用类型原子操作类
引用类型原子操作类一共有三种:AtomicReference(引用类型原子型)、AtomicStampedReference(带有引用版本的原子类)、AtomicMarkableReference(标记节点原子类)。其中,AtomicReference可以直接实现应用数据类型的原子操作,常用方法如下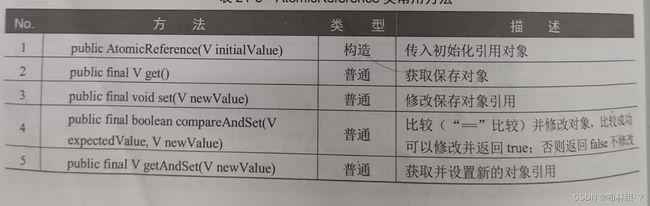
范例:使用AtomicReference操作引用数据
package cn.mldn.demo;
import java.util.concurrent.atomic.AtomicReference;
class Memeber
{
private String name;
private int age;
public Member(String name,int age){...}
}
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
Member memA=new Member("AAA",12);//实例化
Member memB=new Member("ABB",12);//实例化
AtomicReference
ref.compareAndSet(memA,memB);
System.out.println(ref);
}
}
本程序通过AtomicReference保存了一个引用对象,由于对象存在引用关联,这样就可以直接利用CAS正确判断并进行内容的替换。
AtomicStampedReference原子性应用类可以实现基于版本号的引用数据操作,在操作时可以基于版本号实现数据操作,常用方法: 范例:使用AtomicStampedReference进行应用原子性操作
范例:使用AtomicStampedReference进行应用原子性操作
package cn.mldn.demo;
import java.util.concurret.AtomicStampedReference;
//Member类不再重复定义
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
Member memA=new Member("AAA",12);//实例化menber对象
Member memB=new Member("AAA",12);//实例化menber对象
//由于AtomicStampedReference需要提供版本号,所以在初始化时定义版本号为1
AtomicStampedReference
//在进行CAS操作时除了要设置替换内容外,也需要设置正确的版本号,否则无法进行替换
ref.compareAndSet(memA,memA,1,2);
System.out.println(ref.getReference());//输出当前数据内容
System.out.println(ref.getStamp());
}
}
本程序在进行应用原子操作时除了设置应用数据外还设置有版本编号,这样在使用CAS进行数据修改的时候就需要传入比较内容与版本编号.
除了使用版本号的处理行驶外也可以使用AtomicMarkableReferences类实现boolean标记,常用方法如下: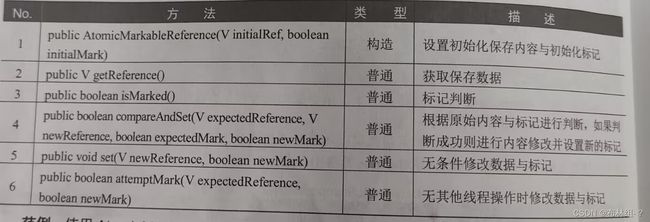
范例:使用AtomicMarkableReference进行标记原子性操作
public static void main(String[]args)throws Exception
{
Member memA=new Member("AAA",12);//实例化Member实例
Member memB=new Member("BBB",13);
//由于AtomicMarkableReference
//在进行CAS操作的时候除了要设置替换内容外,也需要设置标记号,否则无法替换
ref.compareAndSet(memA,memB,true,false);
System.out.println(ref.getReference());
本程序利用AtomicMarkableReference类进行标记原子性处理操作,这样在进行数据修改时就必须传入当前的标记状态(true或false)才可以实现内容更新.
提示:关于ABA访问问题
对于JUC提供的AtomicStampedReference和AtomicMarkableReference两个类所需要解决的是多线程访问下的数据操作ABA不同步问题,是指两个线程并发操作时,由于更新不同步所造成的更新错误,可以考虑以下流程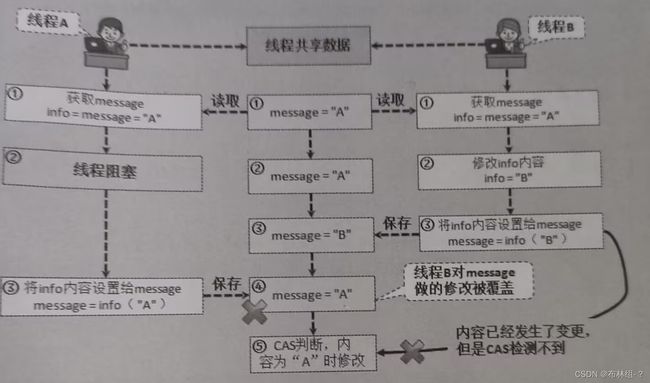 对于ABA问题最简单的理解就是:现在A和B两位开发工程师同时打开了一个相同的程序文件,A在打开之后由于有其他的事情要忙,所以暂时没有做任何的代码编写;而B却一直在进行代码编写,当B把代码写完之后并保存后观赏计算机离开了,而A处理完其它事情后发现没有什么可写的,于是直接保存退出了,这样B的修改就消失不见了。
对于ABA问题最简单的理解就是:现在A和B两位开发工程师同时打开了一个相同的程序文件,A在打开之后由于有其他的事情要忙,所以暂时没有做任何的代码编写;而B却一直在进行代码编写,当B把代码写完之后并保存后观赏计算机离开了,而A处理完其它事情后发现没有什么可写的,于是直接保存退出了,这样B的修改就消失不见了。
由于ABA问题的存在,那么就有可能造成CAS的数据更新错误,因为CAS是基于数据内容的判断来实现数据修改,所以此时的操作就会产生错误。为了解决这个问题,提出了版本号设计方案,这也就是JUC提供AtomicStampedReference和AtomicMarkableReference两个类的原因所在。
21.3.4 对象属性修改原子操作类
为了保证在并发编程访问下的类属性修改的正确性,JUC提供了3个塑性原子操作类:AtomicIntergerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater,这3个类都可以安全的进行属性更新。由于这几个累的实现原理和操作模式相同,本节将针对AtomicLongFieldUpdater类的使用来进行讲解:

范例:实现属性操作
class Book
{
//必须使用volatile定义
private volatile long id;
private String title;
public Book(long id,String title){...}
public void setId(long id)
{
AtomicLongFileUpdater
atoLong.compareAndSet(this.this.id,id);
}
}
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
Book book=new Book(10001,"AAA");
book.setId(2003);
}
}
本程序在定义Book类的时候通过AtomicLongFieldUpdater类进行了id属性的内容更新操作,但是此类操作更新的属性必须用volatile声明。
21.3.5 并发计算
使用原子操作类可以保证多线程访问下的数据操作安全性,而为了进一步加强多线程下的计算操作,所以从JDK1.8之后开始提供累加器(DoubleAccumulator、LongAccumulator)和加法器(DoubleAddler、LongAdder)的支持。但是原子性的累加器只是适合于进行基础的数据统计,并不适合于其他更加细粒度的操作。
范例:使用累加器计算
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
DoubleAccumulator da=new DoubleAccumulator((x,y)->x+y,1.1);//累加器
System.out.println(da.doubleValue());//原始内容
da.accumulate(20);//加法计算
System.out.println(da.get());//获取数据
}
}
本程序创建了一个累加器,并且设置了一个计算表达式(DoubleBinaryOperator接口实现),随后利用原始数据进行了指定数据内容的增加并获取结果。
范例:使用加法器计算
public static void main(String[]args)throws Exception
{
DoubleAdder da=new DoubleAddler();
da.add(10);
da.add(20);
System.out.println(da.sum());
}
本程序定义了一个加法器,同时设置了3个要进行加法计算的数字,最后通过sum()方法获取加法结果.
21.4 ThreadFactory
多线程的执行类需要实现Runnable或Callable接口标准,所以为了进一步规划线程类的对象产生,JUC提供了一个ThreadFactory接口,利用此接口可以获取THread类的实例化对象,该接口定义如下:
public interface ThreadFactory
{
//传入Runnable接口实例创建Thread类实例
//@param r Runnable线程核心操作实现
//@return Thread线程类对象
public Thread newThread(Runnable r);
}
在开发中ThreadFactory接口的使用结构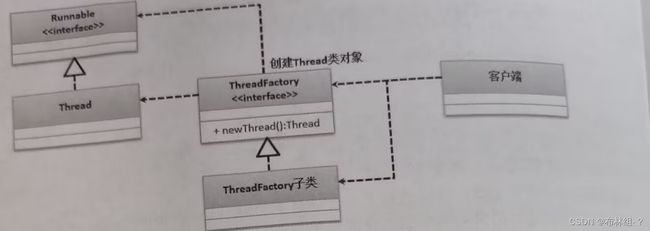
范例:使用ThreadFactory创建线程
public class JUCDemo
{
public static void main(String[]args)
{
Thread thread=DefaultThreadFactory.getInstance().newThread(()->
{
System.out.println("多线程执行"+Thread.currentThread().getName());
});
thread.start();
}
}
class DefaultThreadFactory implements ThreadFactory
{
//定义线程工厂实现类
private static final ThreadFactory INSTANCE=new DefaultThreadFactory();
private static final String title="AAA";//定义线程标记名称
private static int count=0;//线程个数统计
private DefaultThreadFactory(){}
public static ThreadFactory getInstance(){return INSTANCE;}
@Override
public Thread newThread(Runnable run){return new Thread(run,TITLE+count++);}//获取线程实例
}
本程序定义了一个ThreadFactory实现类,这样就可以依据此接口实现Thread类实例的统一管理。
21.5 线程锁
传统的线程锁机制需要依赖synchronized同步与Object类中wait()方法、notify()方法进行控制,然而这样的控制并不容易,所以JUC中提供有一个新的框架锁,再次框架中提供两个核心接口
Lock接口:支持各种不同定义(公平机制锁、非公平机制锁、可重入锁)
ReadWriteLock接口:针对线程的读或写提供不同的锁处理机制,在数据读取时采用共享锁,数据修改时使用独占锁,这样就可以保证数据访问的性能
在JUC提供的锁几只钟提供有大量不同类型的锁处理类,包括ReentranLock、StampedLock、LockSupport、Semaphore等
注意:AQS操作支持
在JUC中AQS有3个支持类:AbstractOwnableSynchronizer、AbstractQueuedSynchronizer、AbstractQueuedLongSynchronizer,这3个类的主要功能是实现锁以及阻塞线程执行的功能。JUC中的许多同步类都依赖于AQS支持,其中AbstractQueuedLongSynchronizer类提供同步状态的64为操作支持
21.5.1 ReentrantLock
ReentrantLock提供了一种互斥锁(或成为独占锁机制),这样在同一个时间点内只允许有一个线程持有该锁,而其他线程将等待与重新获取操作。ReentrantLock最大的特点在于它也属于一个可重用锁,这就意味着该锁可以被单个线程重复获取
范例:使用互斥锁实现多线程并发售票操作
class Ticket
{
//售票类,该类不是线程子类
private int count=3;//售票总数
private ReentrantLock reentrantLock=new ReentrantLock();//互斥锁(独占锁)
//售票操作方法,该方法不再使用synchronized进行同步处理,每次只允许一个线程操作
public void sal()
{
this.reentrantLock.lock();//锁定
if(this.count>0)
{
//票数有空余
TimeUnit.SECONDS.sleep(1);//模拟网络延迟
System.out.println(""+Thread.currentThread().getName()+"卖票,票数剩余"+this.count--);
}else
{
System.err.println(""+Thread.currentThread().getName()+"没票了");
}
this.reentrantLock.unlock();
}
}
public class JUCDemo
{
public static void main(String[]args)
{
Ticket ticket=new Ticket();//实例化内对象
for(int x=0;x<20;x++)
{
new Thread(()->{ticket.sal();},"售票员-"+x).start()
}
}
}
本程序针对卖票程序中的线程控制并没有使用传统的syncronized进行锁定,并且Ticket也不是Runnable或Callable线程类。在sal()方法中直接依据ReentranLock(本次为非公平机制)实现线程锁定(lock()方法),这样就保证只允许有一个现场恒进行买票的数据处理操作,而当此线程解锁后(unlock()方法),其他线程将根据优先级抢占独占锁并进行卖票操作。
提示:关于ReentrantLock公平锁与非公平锁的处理实现
互斥锁中针对所得获取可以使用lock()方法,释放锁可以使用unlock()方法。同时需要注意的是,锁的获取有两种不同的实现机制:公平机制和非公平机制,实际上这两种不同机制在进行锁或趋势的操作流程也有所不同,lock()方法代码实现如下
public void lock(){sync.acquire(1);}
acquire()方法·在AbstractQueuedSynchronizer类中的实现代码如下
public final void acquire(int arg)
{
if(!tryAcquire(arg)//尝试获取,失败进入等待序列
&&acquireQueued(//获取队列
addWaiter(Node.EXCLUSIVE),arg))//加入CLH队列
selfInterrupt();//等待中被中断,则自己中断
}
CLH是一个肺阻塞的FIFO队列。也就是说,往里面插入或移除一个节点的时候,在并发条件下不会产生阻塞,而是通过自旋锁和CAS保证节点插入与移除的原子性。
公平锁和非公平锁的区别是在获取锁的机制上的区别。
21.5.2 ReentrantReadWriteLock
使用独占锁最大的特点在于其只允许一个线程进行操作,这样在进行数据更新的时候可以保证操作的完整性,但是在进行数据读取时,独占锁会造成严重的性能问题。为了解决高并发下的快速访问与安全修改,JUC提供了ReentrantReadWriteLock读写锁,即在读取的时候上读锁,写的时候上写锁,这两种锁时呼呲的有JVM进行控制。其继承结果如图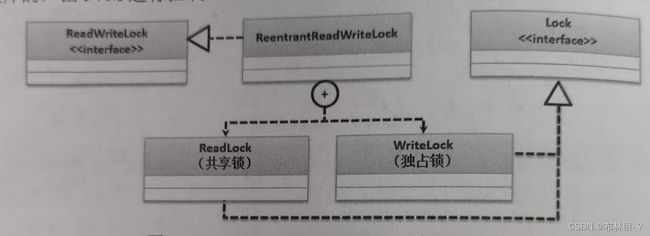
在ReentrantReadWriteLock中读锁属于共享锁,而写锁只允许一个线程进行操作,所以在使用时就需要通过不同的方式获取锁 例readLock()获取读锁,writeLock(),获取写锁。
范例:使用读、写锁实现银行账户的并发写入与并发读取
class Account
{
//银行账户
private String name;//账户名称
private double asset;//账户资产
private ReadWriteLock readWriteLock=new ReentrantReadWriteLock();//读/写锁
public Account(STring name,double asset)//设置账户信息
{
this.name=name;
this.asset=asset;
}
public void saveMoney(double money)
{
//资产追加
this.readWriteLock.writeLock().lock();//获取写锁(独占锁
this.asset+=mony;
TimeUnit.SECONDS.sleep(2);//模拟延迟
System.out.println(""+Thread.currentThread().getName()+"修改金额"+money+"当前总资产"+this.asset);
this.readWriteLock.writeLock().unlock();
}
public String toString()
{
this.readWriteLock.readLock().lock();//获取读锁
TimeUnit.SECONDS.sleep(2);//模拟延迟
System.out.println(""+Thread.currentThread().getName()+"修改金额"+money+"当前总资产"+this.asset);
this.readWriteLock.readLock().unlock();
}
}
public static void main(String[]args)
{
Account=new Account("AA",0.0);
double[]moneyData=new double[]{120,300,500,700,5000};
//5个写入线程
for(int x=0;x<5;x++)
{
new Thread(()->{for(int y=0;y
account.saveMoney(moneyData[y]);//存放金额
}}).start();
}
for(int x=0;x<5;x++)//5个读取线程
{
new Thread(()->{
while(true)
{
System.err.println(account.toString());//获取数据
}
}).start();
}
}
本程序定义了一个Account类描述银行账户,随后启动了5个写线程和5个读线程。在程序执行时可以发现写线程采用了独占锁的处理方式,多个写线程依次执行;而读线程是会有多个线程并行读取,这样保证了数据操作的正确性,也实现了数据的快速读取。
21.5.3 StampedLock
读、写锁可以保证并发访问下的数据写入和读取性能,但是在读线程非常多的情况下,有可能会造成写线程的长时间泽德,从而减少线程的调度次数。为此JUC针对读、写锁提出了改进方案,提供了无障碍锁(StampedLock),使用这种锁的特点在于:若干个读线程彼此之间不会相互影响,但是依然可以保证多个写线程的独占操作。
范例:使用StampedLock实现银行账户并发操作;
class Account
{
//银行账户
private String name;//账户名称
private double asset;//账户资产
private ReadWriteLock readWriteLock=new ReentrantReadWriteLock();//读/写锁
public Account(STring name,double asset)//设置账户信息
{
this.name=name;
this.asset=asset;
}
public void saveMoney(double money)
{
//资产追加
long tamp=this.stampedLock.readLock();//获取读锁,检查状态
boolean flag=true;
long writeStamp=this.stampedLock.tryConvertToWriteLock(stamp);//转为写锁
while(flag)
{
if(writeStamp!=0)
{//当前为写锁
stamp=writeStamp;//修改为写锁的标记
this.asset+=money;//进行资产修改
TimeUnit.SECONDS.sleep(1);//模拟延迟
flag=false;
}else
{
//没有获取到写锁
this.stampedLock.unlockRead(stamp);//释放读锁
writeStamp=this.stampedLock.writeLock();//获取写锁
stamp=writeStamp;
}
}
this.stampedLock.unlock(stamp);//解锁
}
public String toString()
{
long stamp=this.stampedLock.tryOptimisticRead();//获取乐观锁
double current=this.asset;//获取当前的资产
TimeUnit.SECONDS.sleep(1);//模拟延迟
//validate()方法虽然可以检测但是依然有可能出现异常,所以本处依据StampedLock类的源代码多追加了一个验证机制
if(!this.stampedLock.validate(stamp)||(stamp&(long)(Math.pow(2,7)-1))==0)
{
//验证记录点有效性
long readStamp=this.stampedLock.readLock();//获取互斥锁
current=this.asset;//修改当前内容
stamp=readStamp;//修改原始记录点
}
}
public static void main(String[]args)
{
Account=new Account("AA",0.0);
double[]moneyData=new double[]{120,300,500,700,5000};
//5个写入线程
for(int x=0;x<5;x++)
{
new Thread(()->{for(int y=0;y
account.saveMoney(moneyData[y]);//存放金额
}}).start();
}
for(int x=0;x<5;x++)//5个读取线程
{
new Thread(()->{
while(true)
{
System.err.println(account.toString());//获取数据
}
}).start();
}
}
本县城产生了30个读线程以及个写线程,在Account类中利用StampedLock类获取了读锁和写锁,为了放置过多读取所造成的写线程阻塞,所以在进行写入前都会判断读锁的状态,并利用转换方法实现了读锁和写锁的转换,这样就可以解决读写锁的缺陷。
21.5.4 Condition
在JUC中允许用户自己进行锁对象的创建,而这种锁对象可以通过接口进行描述,Ccondition提供了与Object类中类似的线程控制方法,同时有用户自己来决定使用的锁,既可以创建更多的锁来进行控制。
范例:Condition基本使用
public class JUCDemo
{
public static String msg=null;//信息保存
public static void main(String[]args)throws Exception
{
Lock lock=new ReentrantLock();//获取Lock接口实例
Condition condition=lock.newCondition();//获得一个写入锁
lock.lock();//获取锁
new Thread(()->
{
//获取锁
lock.lock();
System.out.println(""+Thread.currentThread().getName()+"进行数据处理");
msg="AAA";
condition.signal();//唤醒其他等待线程
lock.unlock();
},"数据处理线程").start();
condition.await();//主线程等待
lock.unlock();
}
}
本程序通过Lock接口与Condition接口实现了主线程等待子线程的程序结构,在本程序中通过Condition提供的await()和signal()两个方法实现了线程的锁定与唤醒操作。但是需要注意的是,在使用Condition接口操作时必须使用lock.lock()处理方法,否则代码中执行中就会出现异常。
Condition除了支持上面的功能外,它更强大的地方在于:能够更加精细地控制多线程的休眠和唤醒,对于同一个锁,开发者可以创建多个Condition,在不同的情况下使用不同的Condition。例如,现在要实现一个多线程并发读、写的缓冲区操作,当向缓冲区写入数据后可以唤醒读线程;当数据从缓冲区读取出来后,可以唤醒写线程;当缓冲区已经写满数据后,则可以将“写线程”设置为等待状态;当缓冲区为空时可以将“读线程”设置为等待状态;当缓冲区为空时可以将“读线程”设置为等待状态。此类操作如果使用Object类中提供的方法(wait()、notify()、notifyAll()操作)是无法明确地进行“读线程”或“写线程”的,而使用Condition就可以明确的唤醒指定的线程。
范例:使用Condition实现数据缓存操作
class DataBuffer
{
private static final int MAX_LENGTH=5;//保存元素的最大个数
private Lock lock=new ReentrantLock();//实例化Lock
private final Condition writeCondition=lock.newCondition();//设置写Condition
private final Condition readCondition=lock.newCondition();//设置读Condition
private final Object[]data=new Object[MAX_LENGTH];//数据存储空间
private int writeIndex=0;//数据写索引
private int readIndex=0;数据读索引
private int count=0;//保存的元素个数
public void put(Object obj)throws Exception
{
this.lock.lock();//获取锁
if(this.count==MAX_LENGTH){this.writeCondition.await();}//已达到最大缓存个数,保存线程等待
this.data[this.writeIndex++]=obj;//保存数据,修改指针
if(this.writeIndex==MAX_LENGTH){this.writeIndex=0;}//已达保存上线,重置保存索引脚标
this.count++;//修改元素保存个数
this.readCondition.signal();//唤醒消费线程
this.lock.unlock();
}
public Object get() throws Exception
{
this.lock.lock();//获取锁
if(this.count==0){this.readCondition.await();}//没有数据,消费线程等待
Object takeData=this.data[this.readIndex++];//取出索引数据
if(this.readIndex==MAX_LENGTH){this.readIndex=0;}//重置索引
this.count--;//消费后,保存个数-1
this.writeCondition.signal();//消费后,唤醒保存线程
return takeData;
this.loc.unlock();
}
}
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
DataBuffer buffer=new DataBuffer();//实例化数据缓冲区
for(int x=0;x<10;x++)//循环创建线程
{
final int tempData=x;//匿名内部类的使用
new Thread(()->{
Thread.sleep(1);//模拟延迟
buffer.put(tempData);//保存数据
},"PUT线程-"+x).start();
new Thread(()->
{
Thread.sleep(100);
},"Get线程"+x).start();
}
}
}
本程序针对读和写分别创见了两个Condition实例化对象,随后依据缓存数据的个数并结合相应的Condition就可以实现准确地读/写两个先后才能的等待与唤醒。
21.5.5 LockSupport
Thread类从JDK1.2版本开始为了方式可能出现的死锁问题,所以废除了Thread类中的一些线程控制方法(如suspend()、resume()),但是有部分开发者认为使用这几个飞出的方法实际上操作会更加直观。
范例:使用LockSupport阻塞线程
public class JUCDemo
{
public static String msg=null;//信息保存
public static void main(String[]args)throws Exception
{
//获取主线程对象
Thread mainThread=Thread,currentThread();
new Thread(()->{
System.out.println(""+Thread.currentThread().getName());
msg="AAA";
LockSupport.unpark(mainThread);//唤醒主线程
},"数据处理-Thread").start();//启动子线程
LockSupport.park(mainThread);//阻塞主线程
}
}
本程序直接利用LockSupport提供的park方法与unpark()方法简单地实现了子线程与主线程的同步操作,可以发现LockSupport可以直接针对线程实例进行挂起与恢复处理。
21.5.6 Semaphore
在大多数情况下服务器提供的资源不是无限的,所以当并发访问线程量较大时就需要针对所有的可用资源进行线程调度,这一点类似于生活中的银行业务办理。例如,在银行里并不是所有的业务窗口都会开启,往往只开几个窗口,如果线程办理银行业务的人较多,那么这些人将会通过依次叫号的功能获取业务办理资格,这样就可以实现有限资源的分配和调度,在JUC中的Semaphore类就可以实现此类调度处理。
范例:模拟银行办公业务(2个业务窗口、10位待办理人)
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
Semaphore sem=new Semaphore(2);//2个可用的资源
for(int x=0;x<10;x++)
{
//循环创建并启动线程
new Thread(()->
{
sem.acquire();//资源抢占,若无资源则等待
if(sem.availablePermits()>=0)//有空闲资源
{
System.out.println(""+Thread.currentThread().getName()+"抢占资源成功");
}else
{
System.err.println(""+Thread.currentThread().getName()+"资源抢占失败");
}
System.err.println(""+Thread.currentThread().getName()+"开始进行业务办理");
TimieUnit.SECONDS.slee(2);//业务办理延迟
System.err.println(""+Thread.currentThread().getName()+"业务办理成功");
sem.release();
},"业务办理人员-"+x).start();
}
}
}
本程序通过Semaphore实现了两个资源的线程抢占与释放处理,所有的线程都会根据有限的资源进行等待与唤醒处理。
21.5.7 CountDownLatch
CountDownLatch可以保证一组子线程全部执行完毕后再进行主线程的执行操作。例如,在服务器主线程启动前,可能需要启动若干子线程,这是就可以使用CountDownLatch来进行控制。
CountDownLatch是通过一个线程个数的计数器实现的同步处理操作,在初始化时可以为CountDownLatch设置一个线程执行总数,这样当一个子线程执行完毕后都执行一个减一的操作,当所有的子线程都执行完毕后,CountDownLatch中保存的计数内容为0,则主线程恢复执行,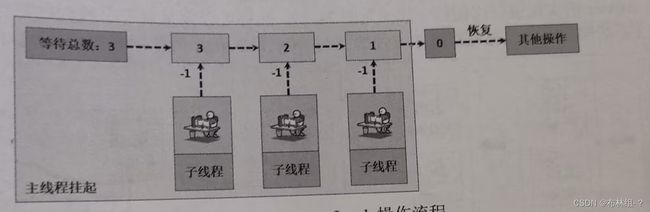
范例:使用CountDownLatch进行线程操作(模拟机场接人)
public static void main(String[]args)throws Exception
{
CountDownLatch latch=new CountDownLatch(2);//要接两位客人
//循环启动线程
for(int x=0;x<2;x++)
{
new Thread(()->{
System.out.println(""+Thread.currentThread().getName()+"上车");
latch.countDown();//等待数量-1
},"客人-"+x).start();
}
latch.await();//等待
}
本程序利用CountDownLatch定义了要等待的子线程数量,这样再统计数量不为0的时候,主线程暂时挂起,知道所有的子线程执行完毕(latch.countDown()进行-1操作)后主线程恢复运行。
21.5.8 CylicBarrier
CylicBarrier可以保证多个线程达到某一个公共屏障点(Common Barrier Point)的时候彩之星,如果没有达到此屏障点,那么线程将持续等待,由于访客较多,可能会猜中分批的模式进入(要求每满10个人才可以入场)
CylicBarrier的实现就好比栅栏一样,这样可以保证若干个线程的并发执行,同时还可以利用此方法更新屏障点的状态进行更加方便的控制
范例:使用CylicBarrier设置栅栏
public static void main(String[]args)throws Exception
{
CyclicBarrier cyclicBarrier=new CyclicBarrier(2,()->{...});//等待栅栏
//循环创建线程
for(int x=1;x<=5;x++)
{
final int temp=x;
if(x==3){TimeUnit.SECONDS.sleep(2);}
}
new Thread(()->
{
System.out.println(""+Thread.currentThread().getName());
if(temp==3){cyclicBarrier.reset();}else{cyclicBarrier.await();}
},"执行者-"+x).start();
}
本程序通过CyclicBarrier设置的屏障点数量为2,这样只有达到两个线程的时候才会接触锁定状态继续执行,同时会执行CyclicBarrier子线程进行其他业务处理,在线程等待期间也可以使用reset()方法重置栅栏技术。
提示:CyclicBarrier和CountDownLatch的区别
CountDownLatch采用单次计数的形式完成,并且该技术操作只允许执行一次,如果在执行中线程出现了错误,那么技术将无法重新开始。
CyclicBarrier采用屏障点的设计模式,可以进行循环技术处理,如果子线程出现了错误,则也可以使用reset()方法进行重置,CyclicBarrier能处理更为复杂的业务场景。
21.5.9 Exchanger
生产者和消费者模型需要有一个公共区域进行数据的保存于获取,在JUC中专门提供了一个交换区域的程序类:java.util.concurrent.Exchanger类
范例:使用Exchanger实现数据交换
public static void main(String[]args)throws Exception
{
Exchanger
boolean isEnd=false;//结束标记
new Thread(()->
{
String data=null;
for(int x=0;x<2;x++)//生产数据
{
data=""+x;
System.out.println("before"'+x+data);
Thread.sleep(1000);
exchanger.exchange(data);
System.out.println("after"'+x+data);
}
},"信息生产者").start();
new Thread(()->
{
String data=null;
while(!isEnd)
{
System.out.println("before"'+data);
Thread.sleep(2000);
data=exchanger.exchange(null);
System.out.println("after"'+data);
}
})
}
本程序定义了生产者和消费者线程,两个线程利用Echanger作为信息交换空间,生产者向xchanger设置数据,在消费者没有取走时将等待消费者取走后在继续进行生产。
21.5.10 CompletableFuture
JDK1.5提供的Future可以实现异步计算操作,虽然Future的相关方法提供了异步任务的执行能力,但是对于线程执行的结果的获取只能能采用阻塞和轮训的方式进行处理。阻塞的方式与多线程异步处理的初衷产生了分歧,轮训的方式又造成CPU资源的浪费,同时也无法及时的得到结果。为了解决这些设计问题,从JDK1.8开始提供了Future的扩展实现类CompleteFuture,可以帮助开发者简化异步编程的复杂性,同时又可以结合函数时模式利用回调的方式进行异步处理计算操作。
范例:使用CompletableFuture模拟炮兵听从命令打炮场景
public static void main(String[]args)throws Exception
{
//线程回调
CompletableFuture
for(int x=0;x<2;x++)
{
new Thread(()->
{
System.out.println(""+Thread.currentThread().getName()+"炮兵就绪");
System.out.println(""+Thread.currentThread().getName()+"解除阻塞"+future.get());
},"炮兵-"+x).start();
}
new Thread(()->
{
TimeUnit.SECONDS.sleep(2);
future.complete("开炮");//命令发出
})
}
21.6 并发集合
集合是数据结构的系统实现,传统的Java集合大多属于“非线程安全的”,虽然Java追加了Collections工具类以实现集合的同步处理操作,但是其并发效率并不高。所以为了更好地支持高并发任务处理,在JUC中提供了支持高并发的处理类,同时为了保证集合操作的一致性,这些高并发的集合类依然实现了集合标准接口,如List、Set、Map、Queue。
范例:传统集合进行多线程并发访问
public static void main(String[]args)throws Exception
{
//List集合
List
for(int num=0;num<10;x++)
{
new Thread(()->
{
for(int x=0;x<10;x++)
{
all.add(""+Thread.currentThread().getName());
System.out.println(all);
}
},"集合操作线程"+num).start();
}
}
本程序通过循环产生了10个线程,并且这10个线程对同一个集合进行数据保存于获取操作,而此程序一旦执行就会产生集合并发修改异常,即传统的集合都是围绕着单线程涉及展开的,只有JUC提供的集合类才支持多线程并发操作。
21.6.1 并发单值集合类
CopyOnWriteArrayList是基于数组实现的并发集合访问类,在使用此类进行数据的"添加/修改/删除"操作时都会创建一个新的数组,并将更新后的数据复制到新建的数组中。由于每次更新操作都回建立新的数组,所以在进行数据修改时CopyOnWriteArrayList类的性能并不高,但是在数据遍历查找时性能会较高。在使用Iterator进行迭代输出时不支持数据删除(remove()方法)操作
提示:CopyOnWriteArrayList部分源代码分析
CopyOnWriteArrayList采用复制与写入数组的形式组成,所以在源代码中定义有以下成员属性。
private transient volatile Object[]array;
在定义array数组时使用volatile定义了盖度向数组,这样就可以保证直接对原始数据进行操作,同时为了保证安全的读、写操作,还提供了一个互斥锁的成员属性。
final transient Object lock=new Object();
在JDK新版本中并没有直接使用ReentrantLook而是定义了一个Object对象,在操作时利用synchronized进行锁定处理。这样在对数据进行“添加、修改、删除”操作时会先获取“互斥锁”,但数据修改完毕后,先将数据更新到volatile数组中,然后在释放“互斥锁”,以此实现数据保护的目的。
范例:使用CopyOnWriteArrayList实现多线程并发访问
public static void main(String[]args)throws Exception
{
List
//循环定义线程
for(int num=0;num<10;num++)
{
new Thread(()->
{
for(int x=0;x<10;x++)
{
all.add(""+Thread.currentThread().getName());
}
},"集合线程操作"+num).start();
}
}
本程序利用CopyOnWriteArrayList类实现了多线程的并发访问操作,所以此时的代码中不会再抛出并发异常。与之相似的集合还有CopyOnWriteArraySet,它提供了一种无序的线程安全集合结构,可以理解为线程安全的HashSet实现,但是与HashSet的区别在于:HashSet是基于散列方式存放的,而其是基于数组实现的。
范例:使用CopyOnWriteArraySet操作
public static void main(String[]args)throws Exception
{
Set
for(int num=0;num<10;num++)
{
//循环定义线程
new Thread(()->
{
for(int x=0;x<1-;x++)
{
all.add(""+Thread.currentThread().getName());
}
},"集合操作线程-"+num).start();
}
}
本程序利用CopyOnWriteArraySet类实现了同样的多线程操作,需要注意的是,CopyOnWriteArraySet类的数据保存时依赖于CopyOnWriteArrayList类实现的,所以不支持remove方法。
21.6.2 ConcurrentHashMap
ConconcurrentHashMap是线程安全的哈希表实现类,在实现结构中他将哈希表分成许多片段,每一个片段中除了保存有哈希数据外还提供了一个可重用的互斥锁,以片段的形式实现多线程的操作,即在同一个片段内除了保存有哈希数据外还提供了一个可重用的互斥锁,以片段的形式实现多线程的操作,即在同一个片段内多个线程访问是互斥的,而不同片段的访问采用的是异步处理方式。
范例:多线程访问ConcurrentHashMap
public static void main(String[]args)throws Exception
{
Map
for(int num=0;num<10;num++)
{
new Thread(()->
{
map.put("AAA",x);
},"集合操作线程-"+num).start();
}
}
本程序创建了ConcurrentHshMap集合,这样该集合在进行并发访问控制时会根据所属的分段进行同步处理,而未分段的部分可以直接进行并行读取。
21.6.3 跳表集合
跳表是一种与平衡二叉树性能类似的数据结构,其主要是在有序链表上使用。在JUC提供的集合中有两个支持跳表操作的集合类型:ConcurrrentSkipListMap、ConcurrentSkipListSet
范例:使用ConcurrentSkipListMap集合
public static void main(String[]args)throws Exception
{
CountDownLatch latch=new CountDownLatch(10);//同步处理
Map
//多线程访问跳表
for(int num=0;num<100;num++)
{
//多线程访问跳表
new Thread(()->
{
map.put(""+Thread.currentThread().getName()+x,x);
latch.countDown();
},"集合操作线程-"+num).start();
}
latch.await();
}
本程序利用100个线程实现了Map集合数据的并发修改
范例:使用oncurrentSkipListSet集合
public static void main(String[]args)throws Exception
{
CountDownLatch latch=new CountDownLatch(10);//同步处理
Map
//多线程访问跳表
for(int num=0;num<100;num++)
{
//多线程访问跳表
new Thread(()->
{
set.add(""+Thread.currentThread().getName()+x,x);
latch.countDown();
},"集合操作线程-"+num).start();
}
latch.await();
}
21.7 阻塞队列
队列是一种FIFO模式处理的集合结构,可以利用队列进行批量数据的保存,例如在传统的生产者和消费者模型中,如果此时生产者的效率较高,而消费者效率较低,就可以通过队列保存生产的内容。
21.7.1 BlockingQueue
BlockingQueue类属于单端阻塞队列,所有的数据将按照FIFO算法进行保存与获取,BlockingQueue类提供有以下几个子类:ArrayBlockingQueue(数组结构)、LinkedBlockingQueue(链表单段·阻塞队列)、SynchronousQueue(同步队列)
ArrayBlockingQueue是一个利用数组控制形式实现的队列操作,需要在其实例化时直接提供数组的长度,也可以设置阻塞线程的公平非公平抢占原则。
范例:使用rrayBlockingQueue实现生产者和消费者模型
public static void main(String[]args)throws Exception
{
BlockingQueue
//10个生产者
for(int x=0;x<10;x++)
{
new Thread(()->
{
TimeUnit.SECONDS.sleep(2);
String msg=""+Thread.currentThread().getName()+y;
queue.put(msg);//队列保存数据
System.out.println("生产数据"+msg);
},"生产者-"+x).start();
}
for(int x=0;x<2;x++)//2个消费者
{
new Thread(()->
{
while(true)
{
TimeUnit.SEDONDS.sleep(1);//延迟操作
System.err.println(queue.take());
}
})
}
}
本程序定义了10个生产者线程和2个消费者线程,通过程序的执行结果可以发现,消费者线程在队列未保存数据时会进行等待,而如果生产者生产的数据超过了队列设置的长度也会进行等待,消费者取消数据后才允许继续生产。
21.7.2 BlockingDeque
BlockingDeque为双端阻塞队列,可以实现FIFO和FILO操作,BlocingDeque只有LinkedBlockingDequeue一个实现子类。
范例:使用双端阻塞队列实现生产者和消费者模型
public static void main(String[]args)throws Exception
{
//双端阻塞队列
BlockingDeque
for(int x=0;x<10;x++)
{
if(x%2==0)
{
new Thread(()->
{
for(int y=0;y<100;y++)
{
TimeUnit.SECONDS.sleep(2);//操作延迟
String msg=""+Thread.currentThread().getName()+y;
queue.putFirst(msg);
System.out.println("[first]生产数据"+msg);
}
}
,"MLDN生产者-"x).start();
}else
{
new Thread(()->
{
TimeUnit.SECONDS.sleep(2);
String msg=""+Thread.currentThread().getName()+y;
queue.putLast(msg);
System.out.println("last生产数据"+msg);
},"lastMLDN生产者-"x).start();
}
}
for(int x=0;x<2;x++)
{
new Thread(()->
{
int count=0;
while(true)
{
TimeUnit.SECONDS.sleep(2);//延迟操作
if(count%2==0)
{
System.err.println("FIRST取出"+queue.takeFirst());
}else
{
System.err.println("last取出"+queue.takeLast());
}
}
},"消费者线程-"+x).start();
}
}
本程序产生了20个生产者线程和2个消费者线程,20个生产者线程分两批各自队列首尾数据保存,2个消费者线程也依次进行首尾队列数据的取出。
21.7.3 延迟队列
在JUC中提供自动弹出数据的延迟队列DelayQueue,该类属于BlockingQueue接口子类,而对于延迟操作的计算则需要通过Delayed接口进行计算。
范例:使用延迟队列(模拟讨论会依次离开的场景)
public static void main(String[]args)throws Exception
{
BlockingQueue
queue.put(new Student("小李",2,TimeUnit.SECONDS));保存延迟队列信息
queue.put(new Student("小王",2,TimeUnit.SECONDS));
while(!queue.isEmpy())
{
Student stu=queue.take();
System.out.println(stu);
TimeUnit.SECONS.sleep(1);
}
}
class Student implements Delayed
{
//定义延迟计算
private String name;//姓名
private long expire;//离开时间
private long delay;//停留时间
public Student(String name,long delay,TimeUnit unit)
{
this.name=name;
this.delay=TimeUnit.MILLISECONDS.convert(delay,unit);//转换时间为毫秒
this.expire=System.currentTimeMills()+this.delay();//失效时间计算
}
public String toString()
{
return this.name+"同学已经达到了预计的停留时间"+TimeUnit.SECONDS.convert(this.delay,TimeUnit.MILLISECONDS)+"秒,已经离开了"
}
@Override//队列弹出计算
public int compareTo(Delayed obj)
{
return (int )(this.delay-this.getDelay(TimeUnit.MILLSECONDS));
}
@Override
public long getDelay(TimeUnit unit)
{
//延迟时间计算
return unit.convert(this.expire-System.currentTimeMills(),TimeUnit.MILLISECONDS);
}
}
本程序实现了延迟队列的操作逻辑,在队列中多保存的每一个元素内容,每当时间一到(compareTo()进行比较,getDelay()获取延迟时间),都会自动进行队列数据的弹出操作。
使用延迟队列的主要原因是他可以实现队列内容的定时清理操作,那么基于这样的自动清理机制就可以实现数据缓存的操作控制,这样的操作可以极大地提升项目的并发性能。
提示:关于数据缓存的作用
在实际开发中,如果是基于数据库的查询操作,那么在多线程并发量较高的情况下就有可能产生严重的性能问题(数据库的执行性能较低),例如,一个人们欣慰可能会有成千上万的访问量,这个时候采用直接数据的读取模式非常不理智。为了解决这个问题,可以采用缓存的模式,将一些重要的数据直接放到缓存里面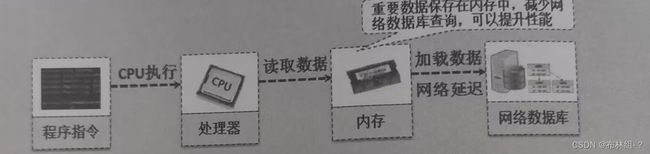
当不同的线程查询相同数据实现判断缓存中是否有指定内容,如果存在则直接进行读取,如果不存在则再进行数据库加载。对于缓存中的内容还需要考虑无效数据的清理问题,而有了延迟队列这种自动弹出的极值存在。这一操作的实现就会变得非常容易。
本次实现一个新闻数据的缓存操作,考虑到可能会保存多个数据,所以将通过Map集合实现存储。同时考虑到缓存数据的修改安全性问题,将使用ConcurrentHashMap子类,另外对于数据的弹出操作将通过守护线程进行处理。
范例:实现缓存操作
public static void main(String[]args)throws Exception
{
Cache
cache.put(1L,new News(1L,"AAA"));//向缓存保存数据
cache.put(1L,new News(2L,"AAA"));//向缓存保存数据
cache.put(1L,new News(3L,"AAA"));//向缓存保存数据
System.out.println(cache.get(1L));
System.out.println(cache.get(2L));//通过缓存获取数据
TimeUnit.SECONDS.sleep(5);//延迟获取
System.out.println(cache.get(1L));
}
class Cache
{
//定义一个缓存数据处理类
private static final TimeUnit TIME=TimeUnit.SECONDS;//时间工具类
private static final long DELAY_SECONDS=2;//缓存时间
private Map
private BlockingQueue
//启动守护线程
public Cache
{
Thread thread=new Thread(()->
{
while(true)
{
DelayedItem
if(item!=null)
{
//存在数据
Pair pair=item.getItem();//获取内容
Cache.this.cacheObjects.remove(pair.key,pair.value);//删除数据
}
}
});
thread.setDaemon(true);//设置后台线程
thread.start();//线程启动
}
public void put(K key,V value)throws Exception
{
V oldValue=this.cacheObjects.put(key,value);//数据保存
if(oldValue!=null)
{
this.queue.remove(oldValue);//删除已有的数据
}
this.queue.put(new DelayedItem
}
public V get(K key){return this.cacheObjects.get(key);}//Map查询
private class Pair
{
private K key;
private V value;//数据value
public Pair(K key,V value)
{
this.key=key;
this.value=value;
}
}
private class DelayedItem
{
//延迟数据保存项
private T item;//数据项
private long delay;//保存时间
private long expire;//失效时间
public DelayedItem(T item,long delay,TimeUnit unit)
{
this.item=item;
this.delay=TimeUnit.MILLISECONDS.convert(delay,unit);
this.expire=System.currentTimeMills()+this.delay;
}
@Override public int compareTo(Delayed obj){return (int)(this.delay-this.getDelay(TimeUnit.MILLISECONDS));}
@Override
public long getDelay(TimeUnit unit)
{
return unit.convert(this.expire-System.getDelay(TimeUnit.MILLISECONDS));
}
@Override
public long getDelay(TimeUnit unit)
{
return unit.convert(this.expire-System.currentTimeMillis(),TimeUnit.MILLSECONDS);
}
public T getItem(){return this.item;}
}
}
class News
{
//新闻数据
private long nid;
private String title;
public News(Long nid,String title){this.nid=nid;this.title=title;}
public String toString(){return ""+this.nid+this.title;}
}
本程序实现了一个数据缓存的处理操作,在程序中考虑到缓存数据的到时自动清除问题,所以使用了延迟队列保存所有的数据信息(同时还有一份数据信息保存在Map集合中)。为了保证延迟队列中的数据弹出后可以进行Map集合相应数据的删除,所以定义了一个守护线程接收延迟队列弹出的内容,由于本程序设定的缓存时间为两秒,这样当两秒一国数据就会自动删除。
21.8 线程池
多线程技术的出现大大提升了程序的处理性能,但是过多的线程一定会带来线程资源调度的损耗,例如,线程的创建与回收,这样就会导致程序的响应速度变慢。为了实现合理的线程操作,就需要提高线程的可管理型,并且降低资源损耗,所以在JUC中提供了线程池的概念。
Executors类能够创建的线程类一共有4中,其主要作用如下
缓存线程池(CachedThreadPool):线程池中的每个子线程都可以重用,白存了所有的用户线程,并且随着处理量的增加可以持续进行用户线程的创建。
固定大小线程池(FixedThreadPool):保存所有的内核线程,这些内核线程可以被不断重用,并且不保存任何的用户线程。
单线程池(SingleThreadPool):只维护一个内核线程,所有执行者依据顺醋排队获取线程资源。
定时调度池(ScheduledThreadPool):按照计划周期性地完成线程中的任务,包含内核线程与用户线程,可以提供许多的用户线程。
提示:关于用户线程与内核线程的区别
多线程的实现过程本身依赖于操作系统,但同时也依赖于所使用的平台。例如,JDK最初发展的时候只有单核CPU,所以当时一类与软件平台的实现。用户线程和内核线程的区别如下:
用户线程可以在不支持多线程的系统中存在,内核线程需要操作系统与硬件的支持。
在只有用户线程的系统中,CPU调度依然以进程为单位,处于运行进程中的多个线程是通过程序实现轮换执行;而有内核支持的多线程系统中,CPU调度以线程为单位,并由操作系统调度。
用户线程通过进程划分,一个进程系统只为其分配一个处理器,所以用户线程无法调用系统的多核处理器,而内核线程可以调度一个程序再多核处理器上执行,提高处理性能。
系统只能将导致其所属进程被中断,而内核线程执行系统指令调用时,只导致该线程被中断。
21.8.1 创建线程池
public static void main(String[]args)throws Exception
{
//缓存线程池
ExecutorService service=Executors.newCachedThreadPool();//缓存线程池
//创建1000个线程
for(int x=0;x<1000;x++)
{
//创建1000线程
for(int x=0;x<1000;x++)
{
service.submit(()->
{
System.out.println(Thread.currentThread().getId()+"-"+Thread.currentThread().getName());
});
}
service.shutdown();//关闭线程池
}
}
本程序创建了一个缓存线程池,由于没有设置其长度限制,所以只要线程池中的线程不够用,则会自动创建新的线程,而线程的数量最多不超过Interger.MAX_VALUE个。
提示:关于execute()与submit()方法
通过executors获取的线程池实际上都是Executor接口的实例,而在Executor接口中提供有一个execute()方法可以进行多线程保存。在本程序中使用submit()方法,submit()方法追加了执行任务是否为空的判断如果为空,会排除异常),最终调用execute方法执行。
而在线程池中实际上有3个核心的概念需要注意
task:表示真正要执行的线程任务,但是所有的线程任务在追加后并不会立刻执行。
worker:所有线程池中的任务都需要通过worker来执行,所有的worker数量受到线程池容量的限制(内核线程)
reject:拒绝策略,如果线程池中的线程已经满了,就可以选择离开或等待。
所有都需要等待分配线程后才会被真正执行,而当线程池容量已经达到上线后也会对新加入的线程采用核心的拒绝策略
范例:创建固定长度线程池
ExecutorService service=Executors.newSingleThreadExecutor();//单线程池
范例:设置单线程池
ecutorService service=Executors.newSingleThreadExecutor();
范例:设置线程调度池
public static void main(String[]args)throws Exception
{
//创建定时调度器,并且设置允许的内核线程数量为1
ScheduledExecutorService executorService=Executors.newScheduledThreadPool(1);
for(int x=0;x<10;x++)
{
int index=x;
//设置调度任务,操作单位为秒,3秒后开始执行,每2秒执行一次
executorService.scheduleAtFixedRate(new Runnable()
{
@Override
public void run(){System.out.println(Thread.curretThread().getName()+x+index);}
},3,2,TimeUnit.SECONDS);
}
}
本程序定义了一个大小的线程调度池,这样所有追加的线程每隔2秒就会执行一次调度,按顺序执行。如果在线程池中传入了一个Callable接口实例,那么也可以利用Future接口获取线程的返回结果,在ExecutorService接口中提供invokeAny与invokeAll两个方法可以实现一组Callable实例的执行。
范例:执行一组Callable实例
public static void main(String[]args)throws Exception
{
Set
//创建线程
for(int x=0;x<5;x++)
{
final int temp=x;
allThreads.add(()->
{
return Thread.currentThread().getId()+"-"+Thread.currentThread().getName()+"数量"+temp;
});
}
ExecutorService service=Executors.newFixedThreadPool(3);//创建定长线程池
List
for(Future
}
本程序通过Set集合保存了多个执行线程,由于只开辟了一个定长为3的线程池,这些集合中的线程将依次进行线程资源抢占并执行,程序通过invokeAll()方法同时执行接收了集合中线程的返回结果。
21.8.2 CompletgionService
CompletionService是一个异步处理模式,其主要的功能是可以异步获取线程池的返回结果。CompletionService将Executor(线程池)和BlocingQueue(阻塞队列)结合在一起,同事主要使用allable定义线程任务。整个操作中就是生产者不断地将Callable线程任务保存进阻塞队列,而后线程池作为消费者不断的把线程池中的任务取出,并且返回结果。
范例:使用CompletionService接口获取异步执行任务接口。
class ThreadItem implements Callable
{
//线程体
@Override
public String call()throws Exception
{
long timeMills=System.currentTimeMillis();//当前时间戳
System.out.println("start"+Thread.curretThread().getName());
Thread.sleep(1000);
System.out.println("end"+Thread.currentThread().getName());
return Thread.currentThread().getName()+timeMillis();
}
}
public class JUCDemo
{
public static void main(String[]args)throws Exception
{
//创建线程池
ExecutorService service=Executors.newCachedThreadPool();
//创建一个异步处理任务,并且该异步处理任务需要接收一个线程池实例
CompletionService
//信息生产者
for(int i=0;i<10;i++)
{
completion.submit(new ThreadItem());//提交线程
}
for(int i=0;i<10;i++){System.out.pritnln("获取数据"+completion.take().get());}
service.shutdown();
}
}
本程序通过CompletionService基于已有的线程池构建了一个异步任务,由于其内部会自动弹出一个阻塞队列,这样所有Callable任务执行完成后可以通过take()方法获取线程任务执行结果。
21.8.3 ThreadPoolExecutor
通过Executors类可以实现线程池的创建,而通过Executors类创建的所有线程池都是基于ThreadPoolExecutor类实现的创建。在一些特殊环境下开发者也可以直接利用Threaxecutor类结合阻塞队列与拒绝策略创建属于自己的线程池。
提示:Executors类创建线程池源代码分析
如果要想清楚Executors类与ThreadPoolExexutor类之间的关系,最好的方法就是查看Executors类中线程池创建操作的源代码。
| 缓存线程池 | public static ExecutorService newCachedThreadPool(){return new ThreadPoolExecutor(0,Integer.MAX_VALUE,60L,TimeUnit.SECONDS,new SynchronousQueue |
在线程池创建时会调用ThreadPoolExecutor类的构造方法,该构造方法定义如下
public ThreadPoolExecutor
(
int corePoolSize,//内核线程数量
int maxinumPoolSize,//线程池最大程度
long keepAliveTime,//每个线程的存活时间
TimeUnit unit,//存活时间单位
BlockingQueue
ThreadFactory threadFactory,//线程工厂
RejectedExecutionHandler handler//线程拒绝策略
)
由于线程池中的资源是有限的,所以对于超过线程池容量的部分任务线程将拒绝执行,为此定义了以下4种拒绝策略
ThreadPoolExecutor.AbortPolicy:当任务添加到线程池中被拒绝的时候,会抛出异常。
ThreadPoolExecutor.CallerRunsPolicy:当任务被拒绝的时候,会在线程池当前正在执行线程的worker里处理此线程(即加塞,现在已有一个线程在worker里正在执行,于是将这个线程踢走,还我执行)
ThreadPoolExecutor.DiscardOldestPolycy:当被拒绝的时候,线程池会放弃队列中等待最长的时间的任务,并且将被拒绝的任务添加到队列中。
ThreadPoolExecutor.DiscardPolicy:当任务添加被拒绝的时候,将直接丢弃该线程
范例:使用ThreadPoolExecutor创建线程池
publc static void main(String[]args)throws Exception
{
BlockingQUEUE
//通过ThreadPoolExecutor创建线程池,该线程池有2个内核线程,每个线程的存活时间为6秒
ThreadPoolExecutor executor=new ThreadPoolExecutor(2,2,6L,TimeUnit.SECONDS,queue,Executor.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());
for(int x=0;x<5;x++)
{
executor.submit(()->
{
System.out.println("before"+Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(2);
System.out.println("after"+Thread.currentThread().getName());
});
}
}
本程序采用手动的方式设置了一个线程池,同时设置了拒绝策略为AbortPolicy,这样当线程池中的执行线程已经被占满时将抛出异常。
21.9 ForkJoinPool
在JDK1.7之后为了充分利用多核CPU的性能优势,可以将一个复杂的业务进行拆分,交由多台CPU进行计算,这样就可以提高程序的执行性能。ForkJoinPool类可以看错一个特殊的Executor执行器,这个框架包括以下两个操作
分解操作:将一个大型业务拆分成若干个小人物在框架中执行。
合并操作:主任务将等待多个子任务完毕后进行结果合并
在ForkJoinPool中需要通过ForkJoinTask定义执行任务
范例:创建有返回值的分支任务
public static void main(String[]args)throws Exception
{
//创建分支任务
SumTask=new SumTask(0,100);//创建分支任务
FkJoinPool pool=new ForkJoinPool();//分支任务池
Future
System.out.println(future.get());
}
@SuppressWarnings("serial")
class SumTask extends RecursizeTask
{
//有返回结果
private int start;
private int end;
public SumTask(int start,int end)
{this.start=start;this.end=end;}
@Override
protexted Interger compute()
{
int sum=0;
if(this.end-this.start<100)
{
for(int x=this.start;x<=this.end;x++){sum+=x;}
}else
{
int middle=(start+end)/2;//计算中间值
SumTask leftTask=new SumTask(this.start,middle);
SumTask rightTask=new SumTask(middle+1,this.end);
leftTask.fork();
rightTask.fork();
sum=leftTask.join()+rightTask.join();
}
return sum;
}
}
本程序通过分支合并任务的处理模式开启了两个分支,这两个分支分别要进行各自的数学累加操作,由于RecursiveTask采用返回值的方式返回了计算结果,所以不同分支可以通过join()方法获取计算结果并完成最终的计算。