Linux的进程/线程/协程系列4:进程知识深入总结:上篇
Linux的进程/线程/协程系列4:进程/线程相关知识总结
- 前言
- 本篇摘要:
- 1. 进程基础知识
-
- 1.1 串行/并行与并发
- 1.2 临界资源与共享资源
- 1.3 同步/异步与互斥
- 1.4 进程控制原语
- 1.5 进程状态
- 2. 进程进阶知识
-
- 2.1 进程控制块
-
- 2.1.1 概念及组成
- 2.1.2 Linux进程控制块:task_struct
- 2.2 进程的虚拟存储器
-
- 2.2.1 虚拟存储器布局
- 2.2.2 如何评估内存占用
- 2.2.3 虚拟内存和物理内存
- 2.3 进程上下文切换
-
- 2.3.1 地址空间切换
- 2.3.2 处理器状态切换
- 2.4 用户模式与内核模式
- 3. 进程中断
-
- 3.1 中断流程
- 3.2 中断描述符表
- 3.3 中断分类:软中断与硬中断
-
- 3.3.1 软中断(异常)
- 3.3.2 硬中断
- 参考文献
前言
最近学习自动驾驶系统时,碰到协程的概念。进程和线程已经迷了,又来个协程,看了很多资料后决定作总结,概括三者联系和区别,最后归结到协程在自动驾驶中的应用。行文的目的,是对进程/线程/协程这一系列繁复的概念和知识点做一个全面的总结,同时尽量做到知识点讲精讲细讲全,甄别模糊概念,同时兼顾源码及编程实现。
本系列文章分九篇讲解:
- 《进程到协程的演化》:涉及进程发展的历史和计算机系统结构知识;
- 《进程/线程的系统命令》:总结进程/线程有关的系统命令,让大家有一个初步感性认识,而不只是生涩的文字;
- 《查看linux内核源码——vim+ctags/find+grep》:如何查看linux系统源码,源码第一手资料,重要性不言而喻;
- 《进程知识深入总结:上篇》:总结进程基础知识和进阶知识,最后详述进程中断。
- 《进程知识深入总结:下篇》:进程其它知识点讲解,包括进程调度、信号量机制、进程死锁、进程通信和进程常用函数。
- 《线程知识深入总结》:包括线程基本概念、内核线程和用户线程、线程上下文切换、线程池和线程常用函数。
- 《协程的发展复兴与实现现状》:看Conway Melvin如何总结出协同工作机制,协程蛰伏原因及发展复兴,详解协程的两个特性:有栈/无栈、对称/非对称,最后引出当前协程库现状。
- 《各协程库对比分析及libgo/tbox》:分析当前各协程库的优劣势,并给出我的推荐:libgo,并分析其源码目录,最后提引性能神器tbox。
- 《进程/线程/协程的性质辨析和实现对比》:列表分析三者的性质,同时根据源码,挑重点总结实现区别。
- 《全面弄懂进程/线程/协程的内存调度》:三者在内存中的调度,,带读者领略内存调度的魅力。
- 《libgo功能及源码详解》:分析libgo/tbox的原理和集成功能,给出源码简读和样例。
- 《Apollo中的协程概述》:协程在Apollo中的应用,展示及分析Apollo协程的源码及优缺点。
本篇摘要:
本篇总结进程相关的知识概念,与程序执行相关的知识点大部分都在进程中有所涉及,这些知识点同样也适用于线程和协程,所以这部分以进程为重点,相关概念也可以推广到线程和协程。与进程相关的知识点繁多复杂,限于篇幅,不再细讲,达到温故而知新的目的即可,而且前人之述备矣,其中不乏精品,所以讲不细的地方作者会推荐一些文章供读者参考。由于进程内容太多,所以分上下两篇讲述。上篇分3章讲解:第一章进程基础知识,包括串行/并行与并发、临界资源与共享资源、同步/异步与互斥、进程控制原语和进程状态;第二章进程进阶知识,包括进程控制块、虚拟存储器、上下文切换以及用户模式和内核模式;第三章详述进程中断,包括中断流程、描述符表详解和中断分类。1. 进程基础知识
本章讲解进程的基础知识,包括串行/并行与并发、临界资源与共享资源、同步/异步与互斥、进程控制原语与进程状态。懂的同学温故而知新,没学过的一定会有所收获。
1.1 串行/并行与并发
从最简单的串行讲起,对比并行与并发的区别:
- 串行:表示所有进程都一一按先后顺序进行,一次只能取得一个进程,并执行这个进程。
- 并行:是指多个进程指令同时在多个处理机上运行,是真正意义上的同时运行。 并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的。
- 并发:是指处理机上同一时刻只能有一条进程指令执行,同时采用分时轮转技术使多个指令快速轮换执行,使得在宏观上有多个进程被同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
串行在单处理器系统中最常见,并行在多处理器系统中存在,而并发可以在单处理器和多处理器系统中都存在,并发能够在单处理器系统中存在是因为并发是并行的假象,并行要求程序能够同时执行多个操作,而并发只是要求程序假装同时执行多个操作(每个小时间片执行一个操作,多个操作快速切换执行)。
1.2 临界资源与共享资源
计算机的资源是有限的,会不可避免的产生竞争,根据使用资源的不同方式,可以分为临界资源和共享资源:
- 临界资源:同一时刻只允许一个进程使用的资源称为临界资源,也称为独享资源。属于临界资源的有硬件打印机、磁带机等,软件有消息缓冲队列、变量、数组、缓冲区等。
- 共享资源:同一时刻允许进程间共享,即可交替使用,互相不受映像,所以称为共享资源,比如读取磁盘、内存等。
临界资源的使用应遵循下述四条准则:
- 空闲让进: 当无进程进入临界区时,相应的临界资源处于空闲状态,因而允许一个请求的进程立即进入自己的临界区。
- 忙则等待:当已有进程进入自己的临界区时,即相应的临界资源正被访问,因而其它试图进入临界区的进程必须等待,以保证进程互斥地访问临界资源。
- 有限等待:对要求访问临界资源的进程,应保证进程能在有限时间进入临界区,以免陷入“饥饿”状态,无限等待。
- 让权等待:当进程不能进入自己的临界区时,应立即释放处理机和已申请资源,以免进程陷入忙等。
1.3 同步/异步与互斥
这三个概念容易混淆,所以放在一起讲:
- 同步:是指一组并发进程因直接制约而互相发送消息进行合作、等待,当某进程得不到另一进程的资源或反馈时,必须阻塞等待,从而使得各进程必须按一定的顺序执行,这称为进程间同步关系。
- 异步:指进程间相互独立,某一进程在等待另一进程事件的过程中继续做自己的事,不需要等待这一事件完成后再工作,当第三方服务器返回时,再通过回调方式来通知服务器进行相应的处理,这称为进程间异步关系。更准确地讲,这里的独立并不是完全独立,而是有一定关联的独立,一般是父进程创建子进程或主线程调用副线程后,父进程或主线程不会因为等待子进程或副线程而产生阻塞。
- 互斥:指并发进程因访问某个临界资源而产生的竞争关系,也就是说互斥是为了保证临界资源在某一时刻只被一个进程访问,因此互斥描述的是资源间的竞争关系。
简单来说,同步是进程间的协作关系,异步是进程间无等待关系,而互斥描述的是资源间的竞争关系。
1.4 进程控制原语
内核是计算机硬件上的第一层扩充软件,常驻内存并在内核模式下运行,是OS的关键部分也是管理控制中心。内核通过执行原语操作来实现各种控制和管理功能,能够执行内核原语的进程/线程称为内核模式的进程/线程,关于内核模式见第二章内容。原语是一种特殊的广义指令,它的功能由系统通过一段不可分割的指令操作来完成,又称原子操作,显然,原语在内核模式下才能运行。进程控制操作大都为原语操作,包括创建原语(Create) 、撤消(Destroy)/ 终止原语(Termination)、阻塞原语(block)、 唤醒原语(wakeup) 、挂起原语(suspend)和激活原语(active)等。具体介绍如下:
- 创建原语(Create):一个进程可借助创建原语构造PCB的方式来创建一个新进程,该新进程是它的子进程。创建原语首先从系统的PCB表中索取一个空白的PCB表目,并获得其内部标识,然后将调用进程提供的参数:如外部名、正文段、数据段的首址、大小、所需资源、优先级等填入这张空白PCB表目中。并设置新进程状态为活动/静止的就绪态,把该PCB插入到就绪队列RQ中,此时新进程就可进入系统并发执行。
- 撤消原语(Destroy)/ 终止(Termination):对于树型层次结构的进程系统,撤消原语采用的策略是由父进程发出,撤消它的一个子进程及该子进程所有的子孙进程,被撤消进程的所有资源(主存、IO资源、PCB表目)全部释放归还系统,并将它们从所有的队列中移去。如撤消的进程正在运行,则调用进程调度程序将处理器分给其它进程。
- 阻塞原语(block):当前进程因请求某事件而不能执行时(例如请求IO而等待IO完成时),该进程主动调用阻塞原语阻塞自己,暂时放弃处理机。阻塞过程首先立即停止原来程序的执行,把PCB中的现行状态由运行态改为活动阻塞态,并将PCB插入到等待某事件的阻塞队列中,最后调用进程调度程序进行处理机的重新分配,切换进程上下文到新进程中。
- 唤醒原语(wakeup):当被阻塞的进程所期待的事件发生时(例如IO完成时),一般是由操作系统通过事件驱动的相关调度程序(例如IO设备处理程序或释放资源的进程等)的Pipe或Channel调用wakeup原语,将阻塞的进程唤醒。此时,把等待该事件的进程从阻塞队列移出,插入到就绪队列中,并将该进程PCB中的现行状态由活动/静止阻塞态改为活动/静止就绪态。
- 挂起原语(suspend):挂起时,进程的虚拟存储被换出到磁盘,调用挂起原语的进程只能挂起它自己或它的子孙,而不能挂起其它族系的进程。挂起原语的执行过程是:检查要被挂起进程PCB的现行状态,由活动就绪/阻塞态改为静止就绪/阻塞态;如过当前正在运行,则将它由运行态改为静止就绪态,并调用进程调度程序重新分配处理机。
- 激活原语(active):操作系统通过调用激活原语将被挂起的进程激活。激活原语执行过程是:检查被挂起进程PCB中的现行状态,由静止就绪/阻塞态改为活动就绪/阻塞态。
另一类常用原语是进程通信原语,我们将在进程通信章节讲解。
1.5 进程状态
进程有三个基本状态:运行态(Running)、就绪态(Ready)和阻塞态(Blocked),考虑到挂起(suspend)/活动(activity)时,又可以再细分为七个状态,进程通过调用进程控制原语在七个状态之间来回切换,限于篇幅,这里不再详细解释每一步的转换,请读者自行仔细区分。各状态转换关系如下图所示: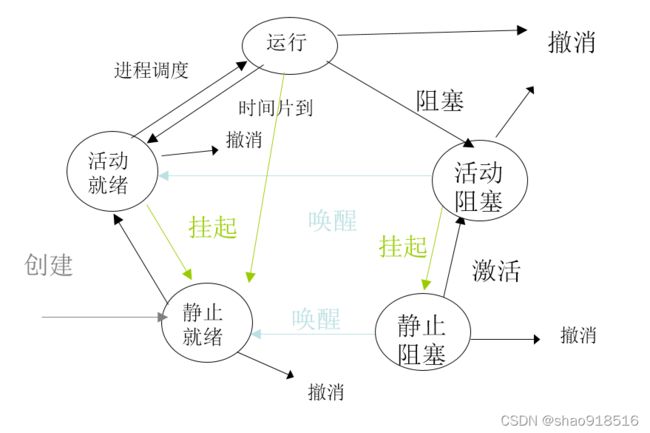 这里需要说明挂起和阻塞的区别:阻塞通常是进程等待某种事件资源而被迫让出处理机,由运行态转入阻塞状态,当满足其需求时就会被唤醒转入就绪状态,继续申请处理机;而挂起通常是进程因时间片用完或被系统管理员终止,由运行态转入静止态,此时进程虚拟存储器会由系统内存换出到磁盘中,当被激活时进入活动态,重新换入系统内存等待处理机调度。从本质上说,进程阻塞时,它等待的事件仍在运行,整个进程的进度仍在推进,而进程挂起时则处于停滞状态。
这里需要说明挂起和阻塞的区别:阻塞通常是进程等待某种事件资源而被迫让出处理机,由运行态转入阻塞状态,当满足其需求时就会被唤醒转入就绪状态,继续申请处理机;而挂起通常是进程因时间片用完或被系统管理员终止,由运行态转入静止态,此时进程虚拟存储器会由系统内存换出到磁盘中,当被激活时进入活动态,重新换入系统内存等待处理机调度。从本质上说,进程阻塞时,它等待的事件仍在运行,整个进程的进度仍在推进,而进程挂起时则处于停滞状态。
第一章总结相对简单些的进程知识,对于更复杂的内容,我们放在第二章讲解。
2. 进程进阶知识
本章介绍进程的进阶知识,包括进程控制块PCB、进程的虚拟存储器、上下文切换、用户模式/内核模式等。
2.1 进程控制块
本小节分两部分来讲,第一部分介绍进程控制块的概念及组成内容。第二部分以linux系统的进程控制块结构task_struct为例,管中窥豹,了解系统中的进程控制块是如何实现的。
2.1.1 概念及组成
类Unix系统中进程由三部分组成,分别是进程控制块、正文段和数据段,这三部分也称为进程映像(Process Image)。进程映像(Process Image)是某一时刻进程的内容及其执行状态集合,是内存级的物理实体,又称为进程的内存映像,os把进程映像部分或全部装载到进程的虚拟存储器中,运行后就产生了一个进程。其中的正文段和数据段是静态内容,而进程控制块(PCB: Process Control Block)是进程动态执行过程中,对进程所拥有的资源进行汇总抽象的结果,它是进程存在的唯一标志,用来管理控制进程运行所需要的全部信息集合。 类UNIX的PCB由proc和user两个结构组成:是PCB最基本和常用的信息,proc结构体管理着进程ID、进程状态、执行优先级等需要经常被内核访问信息,为了方便系统或父进程考察该进程的运行情况,proc需常驻系统内存;而user可根据需要换进换出,通常对应进程的虚拟存储内存。关于proc和user的详细信息请参考文献8。
Linux中PCB通常包含以下信息:
- 进程标识符pid:它用于唯一地标识一个进程。它有外部标识符(由字母组成,供用户使用)和内部标识符(由整数组成,为方便系统管理而设置)二种。
- 家族信息:它包括该进程的父、子进程标识符、进程的用户主等。
- 处理器状态信息:它由处理器各种寄存器(通用寄存器、程序计数器、程序状态字PSW、用户栈指针等上下文数据)所组成,该类信息使进程被中断后可以从断点处继续运行。
- 进程调度信息:它包括进程状态(running、ready、blacked)、队列(就绪、阻塞队列)、队列指针、调度参数(进程优先级、进程已执行时间、已等待时间、占用时间)等。
- 进程控制信息:它包括程序和数据的地址使用的内存信息(如页表)、共享库区域、IO资源清单(包括显式I/O请求、分配给进程的I/O设备、被解除使用的文件列表等)等,保证进程正常运行的同步和通信机制等。
因此,进程控制块包含描述进程状态以及控制进程运行所需要的全部信息,是操作系统用来感知进程存在的一个非常重要的数据结构。任何一个操作系统的实现都需要一个数据结构来描述进程,比如linux内核采用一个名为task_struct的结构体。注意:PCB在Linux中对应task_struct结构,也称为PD结构;PCB在Unix中对应于proc和user结构,Linux作为对Unix的扩展,两者实现思想上的差异很小,这里我们只详细介绍下task_struct。
2.1.2 Linux进程控制块:task_struct
Linux中,每个进程主要通过一个称为进程描述符(process descriptor)的结构来描述,其结构类型定义为task_struct,包含了一个进程的所有信息:标识进程的PID、指向用户栈的指针、可执行目标文件的文件名、程序计数值PC(Program Counter)等。
所有进程通过一个双向循环链表实现的任务列表(task list)来管理,任务列表中每个元素是一个进程描述符。

如图,task结构中有一个指针指向mm结构,mm结构描述对应进程虚拟空间的当前状态,其中有两个重要字段:1.字段pgd,对应进程第一级页表(页目录表)的首地址,当处理器运行对应进程时,内核会将其送到CR3控制寄存器;2.字段mmap,指向一个由vm_area结构组成的链表表头,每个vm_area结构了对应进程虚拟空间中的一个区域。包括指向区域开始位置和结束位置的vm_start和vm_end,描述区域包含的所有页面的访问权限的vm_prot,描述区域包含的页面是否和其它进程共享的vm_flags,以及指向下一个链表结点的vm_next。
由此可见,Linux是以task_struct中的链表管理内存,内核不需要记录所有内存,通过task结构、task结构指向的mm结构、mm结构指向的vm_area结构进行内存管理,从而记录进程相关内容,想进一步了解的同学可参考文献10。那么进程的PCB在计算机中是如何存储的呢?它藏在进程的虚拟存储器的内核部分,下面我们来学习进程的虚拟存储器。
2.2 进程的虚拟存储器
2.2.1 虚拟存储器布局
进程提供给应用程序两个关键的抽象:独立的逻辑控制流(“独占”使用处理器的基础,进程调度)和独立的私有地址空间(“独占”使用内存系统的基础,虚拟内存)。启动应用程序时,系统会为该应用程序创建进程 ,进程为应用程序提供专用的虚拟地址空间和专用的句柄表,用于存储和控制 。由于应用程序的虚拟地址空间为专用空间,因此一个应用程序无法更改属于其他应用程序的数据。这里我们了解下进程虚拟内存的具体内容。
Linux将用户空间对应的进程虚拟空间组织成若干区域(area)的集合,这些区域是指在虚拟存储空间中的连续片,而且是已分配页,这就是进程的虚拟存储器。一个单独的Linux系统进程虚拟存储器分为:内核虚拟存储器和进程独占虚拟存储器。内核虚拟存储器保存在系统内,是用户代码不可见的数据,包括内核代码和数据、物理内存和与进程相关的数据结构(比如页表、task_struct结构、内核栈等)。进程独占虚拟存储器对于每个进程都不一样,保存的是用户代码可以操作的数据,包括文本段、初始化数据段、未初始化数据段、堆、共享库映射区域、用户栈等。进程虚拟存储器分布图如下: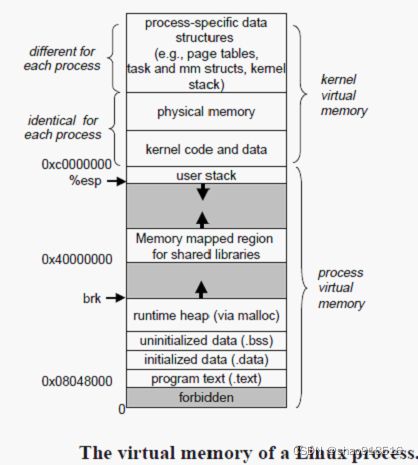 从低地址到高地址,分别包括:
从低地址到高地址,分别包括:
- 禁用段(forbidden):顾名思义,就是目前未启用部分。
- 文本段(text):也叫程序文件,是对象文件或内存中程序的一部分,其中包含代码、可执行指令等。通常文本段是共享的,对于经常执行的程序,只有一个副本需要存储在内存中。另外,文本段是只读的,以防止其它程序修改指令。
- 初始化的数据段(initialized data):是程序虚拟地址空间中的一部分,它包含程序员初始化的全局变量和静态变量,可以进一步划分为只读区域和读写区域。例如,main(例如全局)之外C中的char=“hello world”的全局字符串,以及static int debug=1这样C语句的静态变量。
- 未初始化的数据段(uninitialized data):通常称为bss段,这个段的数据在程序开始之前由内核初始化为0,包含所有初始化为0和没有显式初始化的全局变量和静态变量。
- 堆(heap):堆是动态内存分配通常用到的部分,由程序员自行分配(malloc,kmalloc等),堆区域由所有共享库和进程中动态加载的模块共享。
- 共享库的存储区映射区域(shared libraries):在堆和栈之间,是共享库的存储器映射区域,存放共享库有关的信息。
- 栈(stack):存放临时变量以及每次调用函数时的调用栈(也称为栈帧)。每当调用一个函数时,在栈上分配栈帧,返回地址、函数参数和局部变量等信息会被保存在栈中。
- 内核代码和数据结构:是每个进程共享的内核代码和数据结构,对每个进程都一样;
- 物理存储器:是一组连续的虚拟页面映射到相应的物理页面的物理存储器,大小同主存一样大,提供很方便访问物理页面的任何位置。
- 与进程相关的数据结构:包括每个进程不同的页表、task_struct(mm)结构、内核栈等等。
关于进程的虚拟存储器深层知识请参考文献3。
2.2.2 如何评估内存占用
当要评估一个进程的内存占用时,就是要把以上几个段的内存占用一一加起来。Linux系统中我们可以使用下面两种方法统计进程占用内存:
- /proc/[pid]/status中,VmPeak/VmSize(最大/当前进程正在占用的内存总大小)包含:①申请但实际上未使用的内存(malloc一段地址空间,但不使用它);②共享库使用的代码段地址空间,会被多个进程的VmSize同时统计,即存在重复统计的问题。所以VmPeak/VmSize存在夸大的情况。VmHWM/VmRss(最大/当前应用程序正在使用的物理内存的大小),它不包含被交换到swap的内存,是相对理想的内存评估依据。
- 另外,将/proc/[pid]/smap中的所有Private_Clean(未改写的私有页面)和Private_Dirty(已改写的私有页面)累加起来,也是很好的评估方案。
2.2.3 虚拟内存和物理内存
另外,我们还需要区分虚拟内存和物理内存的概念。进程的虚拟存储器和进程的虚拟内存是两个不同的概念,虚拟内存涉及到操作系统中,虚拟内存如何对应到物理内存进行存储,这有利于有限内存进行扩展。进程得到的虚拟内存一般是一个连续的地址空间,而实际上,它通常是被分隔成多个物理内存碎片,还有一部分存储在外部磁盘存储器上,在需要时进行数据交换。
当每个进程创建的时候,内核会为进程分配4G的虚拟内存,当进程还没有开始运行时,这只是一个内存布局。实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射)。这个时候数据和代码还是在磁盘上的。当运行到对应的程序时,进程去寻找页表,发现页表中地址没有存放在物理内存上,而是在磁盘上,于是发生缺页异常,将磁盘上的数据拷贝到物理内存中。
关于这部分内容,也是很复杂的,老火不再细讲,因为讲起来文章就写不完了,这里提示只是为了让大家对概念有所区分,希望学习的读者请参考文献11。既然知道了进程的存储,下面就来看一下进程如何进行上下文的切换。
2.3 进程上下文切换
当运行的进程发生中断,操作系统进入内核模式,需要调度新进程进入处理器运行时,就产生进程上下文切换。所谓的进程上下文:是指程序执行活动全过程的静态描述,由程序正确运行所需的状态组成。具体说,进程上下文包括系统中与执行该进程有关的各种寄存器(例如:通用寄存器、程序计数器PC、程序状态寄存器PS等)的值、内核堆栈及PCB等内核空间资源,还有程序段在经编译之后形成的机器指令代码集(或称文本段)、数据集、共享库映射区域、各种堆与栈等用户空间的虚拟存储器的内容。
有的资料把进程的上下文可以分为三个部分:用户级上下文、系统级上下文和寄存器上下文,也有些资料将进程的上下文划分为进程的虚拟存储器和处理器状态。其实用户级上下文和系统级上下文对应进程虚拟存储器的进程独占部分和内核部分,可统称为进程存储器,而寄存器上下文则对应处理器状态,同一个意思。但实际的切换中,虚拟存储器只切换了很小的一部分,所以才可以达到这么快的速度,所以这两者的划分并不准确。另外,我们把切换的部分称之为进程的地址空间(可能你觉得这命名有点儿扯,老火也没有办法,为了和其它资料一致,只能暂且这样命名,我总不能总是自己搞创造吧)。
这里,我们将进程上下文切换分为进程地址空间切换和处理器状态切换两部分,总体代码如下:
__schedule // kernel/sched/core.c
->context_switch
->switch_mm_irqs_off //进程地址空间切换
->switch_to //处理器状态切换
下面分别讲述switch_mm_irqs_off和switch_to。
2.3.1 地址空间切换
进程地址空间内有进程运行的指令和数据,因此调度器从其他进程切换到当前进程必须切换地址空间。实际上,Linux中进程地址空间使用mm_struct结构体来描述,这个结构体被嵌入到进程描述符(我们通常所说的进程控制块PCB)task_struct中,mm_struct结构体将各个vma组织起来进行管理,其中有一个成员pgd至关重要,地址空间切换中最重要的是pgd的设置。在上文中有提到pgd,它保存了进程的全局页目录的虚拟地址(虚拟内存的概念请参考文献11),那么pgd的值是何时被设置的呢?答案是如果是创建进程fork的时候,此时需要分配设置mm_struct,其中会分配进程全局页目录所在的页,然后将首地址赋值给pgd。
我们来看看进程地址空间究竟是如何切换的,本代码基于arm64架构处理器,代码路径如下:
context_switch // kernel/sched/core.c
->switch_mm_irqs_off
->switch_mm
->__switch_mm
->check_and_switch_context
->cpu_switch_mm
->cpu_do_switch_mm(virt_to_phys(pgd),mm) //arch/arm64/include/asm/mmu_context.h
arch/arm64/mm/proc.S
158 /*
159 * cpu_do_switch_mm(pgd_phys, tsk)
161 * Set the translation table base pointer to be pgd_phys.
163 * - pgd_phys - physical address of new TTB
164 */
165 ENTRY(cpu_do_switch_mm)
166 mrs x2, ttbr1_el1
167 mmid x1, x1 // get mm->context.id
168 phys_to_ttbr x3, x0
169
170 alternative_if ARM64_HAS_CNP
171 cbz x1, 1f // skip CNP for reserved ASID,暂且不考虑asid机制,可参考文献12
172 orr x3, x3, #TTBR_CNP_BIT
173 1:
174 alternative_else_nop_endif
175 #ifdef CONFIG_ARM64_SW_TTBR0_PAN
176 bfi x3, x1, #48, #16 // set the ASID field in TTBR0
177 #endif
178 bfi x2, x1, #48, #16 // set the ASID
179 msr ttbr1_el1, x2 // in TTBR1 (since TCR.A1 is set)
180 isb
181 msr ttbr0_el1, x3 // now update TTBR0
182 isb
183 b post_ttbr_update_workaround // Back to C code...
184 ENDPROC(cpu_do_switch_mm)
代码中最核心的为181行,最终将进程的pgd虚拟地址转化为物理地址存放在ttbr0_el1中(ttbr1_el1是内核空间的页表基址寄存器,访问内核空间地址时使用,所有进程共享,不需要切换),这是用户空间的页表基址寄存器,当访问用户空间地址的时候,mmu会通过这个寄存器来做遍历页表获得物理地址。完成了这一步,将所要执行的进程的全局页目录的物理地址设置到页表基址寄存器,也就完成了进程的地址空间切换,确切的说是进程的虚拟地址空间切换。
为什么这就完成了地址空间切换呢?试想如果进程想要访问一个用户空间虚拟地址,cpu的mmu所做的工作,就是从页表基址寄存器拿到页全局目录的物理基地址,然后和虚拟地址配合来查查找页表,最终找到物理地址进行访问(当然如果tlb命中就不需要遍历页表)。不考虑内核空间共享和共享内存情况下,每次用户虚拟地址访问时,由于页表基地址寄存器内存放的是当前执行进程的页全局目录的物理地址,所以访问自己的一套页表,拿到的是属于自己的物理地址,就不会访问其他进程的指令和数据,这也是为何多个进程可以访问相同的虚拟地址而不会出现差错的原因,而且做到的各个地址空间的隔离互不影响。
还需要注意的是仅仅切换用户地址空间,内核地址空间由于是共享的不需要切换,也就是为何切换到内核线程不需要也没有地址空间切换的原因。如下为进程地址空间切换示例图:
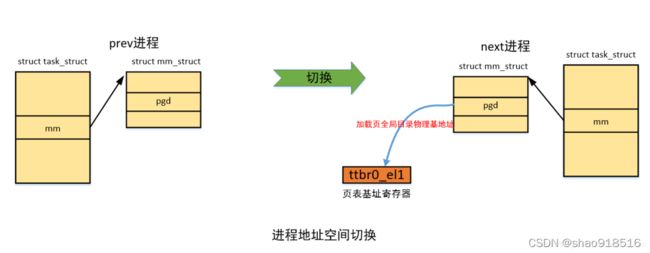 另外,补充说一下,当做线程切换时,内核地址空间切换的时候需要根据进程描述符的mm_struct结构的成员mm做判断,是否是同一进程的线程,从而判断是否需要做切换,具体如下:
另外,补充说一下,当做线程切换时,内核地址空间切换的时候需要根据进程描述符的mm_struct结构的成员mm做判断,是否是同一进程的线程,从而判断是否需要做切换,具体如下:
- 如果mm为NULL,则表示即将切换的是内核线程,不需要切换地址空间(所有任务共享内核地址空间)。
- 内核线程会借用前一个用户进程的mm,赋值到自己的active_mm(本身的mm为空),进程切换的时候就会比较前一个进程的active_mm和当前进程的mm,如果两者具有相同的mm成员,也就是共享地址空间的线程,则也不需要切换地址空间。
因此有如下结论:a.对于普通的用户进程之间进行切换需要切换地址空间;b.同一个线程组中的线程之间切换不需要切换地址空间,因为他们共享相同的地址空间; c.内核线程在上下文切换的时候不需要切换地址空间,仅仅是借用上一个进程mm_struct结构。
下面我们来看看处理器状态的切换。
2.3.2 处理器状态切换
前面进行了地址空间切换,只是保证了进程访问指令数据时访问的是自己的地址空间(当然上下文切换的时候处于内核空间,执行的是内核地址数据,当返回用户空间的时候才有机会执行用户空间指令数据,地址空间切换为进程访问自己用户空间做好了准备),但是进程执行的内核栈还是前一个进程的,当前执行流也还是前一个进程的,需要做切换。所有的进程线程之间进行切换都需要切换处理器状态。
处理器状态切换又称寄存器上下文切换、模式切换、硬件上下文切换。进程处理器状态包含了当前cpu的一组寄存器的集合,linux中使用task_struct结构成员thread的字段cpu_context来描述,包括x19-x28、sp、pc等。处理器状态存放示例图如下:

Linux中切换代码如下:
switch_to
->__switch_to
... //浮点寄存器等的切换
->cpu_switch_to(prev, next)
arch/arm64/kernel/entry.S:
1032 /*
1033 * Register switch for AArch64. The callee-saved registers need to be saved
1034 * and restored. On entry:
1035 * x0 = previous task_struct (must be preserved across the switch)
1036 * x1 = next task_struct
1037 * Previous and next are guaranteed not to be the same.
1038 *
1039 */
1040 ENTRY(cpu_switch_to)
1041 mov x10, #THREAD_CPU_CONTEXT
1042 add x8, x0, x10
1043 mov x9, sp
1044 stp x19, x20, [x8], #16 // store callee-saved registers
1045 stp x21, x22, [x8], #16
1046 stp x23, x24, [x8], #16
1047 stp x25, x26, [x8], #16
1048 stp x27, x28, [x8], #16
1049 stp x29, x9, [x8], #16
1050 str lr, [x8]
1051 add x8, x1, x10
1052 ldp x19, x20, [x8], #16 // restore callee-saved registers
1053 ldp x21, x22, [x8], #16
1054 ldp x23, x24, [x8], #16
1055 ldp x25, x26, [x8], #16
1056 ldp x27, x28, [x8], #16
1057 ldp x29, x9, [x8], #16
1058 ldr lr, [x8]
1059 mov sp, x9
1060 msr sp_el0, x1
1061 ret
1062 ENDPROC(cpu_switch_to)
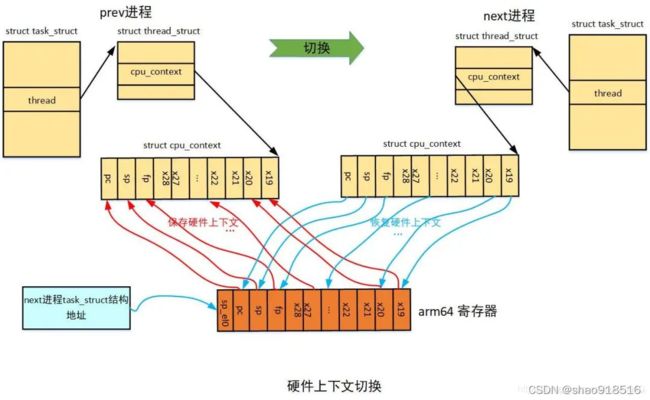
其中x19-x28是arm64架构规定需要调用保存的寄存器,可以看到处理器状态切换的时候,将前一个进程(prev)的x19-x28、fp、sp和pc保存(store)到了进程描述符的cpu_contex中,然后将即将执行的进程(next)描述符的cpu_contex的x19-x28、fp、sp和pc恢复(restore)到相应寄存器中,而且将next进程的进程描述符task_struct地址存放在sp_el0中,用于通过current找到当前进程,这样就完成了处理器的状态切换。
实际上,处理器状态切换就是将前一个进程的sp、pc等寄存器的值保存到一块内存上,然后将即将执行的进程的sp、pc等寄存器的值从另一块内存中恢复到相应寄存器中,恢复sp完成了进程内核栈(用pt_regs结构描述)的切换,恢复pc完成了指令执行流的切换。其中保存/恢复所用到的那块内存需要被进程所标识,这块内存这就是cpu_contex这个结构的位置,需要注意的是,处理器状态切换都是在内核空间完成。
由于用户空间通过中断进入内核空间的时候都需要保存现场,也就是保存所有通用寄存器的值,内核会把“现场”保存到每个进程特有的进程内核栈中,然后处理中断程序。当中断处理完成之后会返回用户空间,返回之前会恢复之前保存的“现场”,用户程序继续执行。如下为硬件上下文切换示例图:
总结:进程管理中最重要的一步要进行进程上下文切换,其中主要有两大步骤:地址空间切换和处理器状态切换(硬件上下文切换),前者保证了进程回到用户空间之后能够访问到自己的指令和数据(其中包括减小tlb清空的ASID机制),后者保证了进程内核栈和执行流的切换,有了这两步的切换过程保证了进程运行的有条不紊,当然切换的过程是在内核空间完成,这对于进程来说是透明的。
上下文切换过程中,进程通过系统调用从用户模式切换到内核模式执行,下面我们就来讲述用户模式和内核模式。
2.4 用户模式与内核模式
为了防止用户应用程序访问或更改重要的操作系统数据,需要限制应用程序可以执行的指令以及可以访问的地址范围,因此Windows与UNIX均采用了两种处理器执行模式:内核模式(又称内核态、核心态、管态、特权态、系统态)和用户模式(又称目态、普通态):
-
用户模式:用户模式不允许程序执行特权指令,如果是x86处理器则在Ring3中运行。Ring3指x86处理器的保护层级,x86处理器提供4种保护层级: 0、1、2和3。实际上,只用0级(内核)和3级(用户程序)被使用到了。
根据处理器上运行的代码的类型,处理器在两个模式之间切换。 应用程序在用户模式下运行,核心操作系统组件在内核模式下运行。虽然许多驱动程序以内核模式运行,但某些驱动程序可能以用户模式运行。启动用户模式应用程序时,系统会为应用程序创建进程,由于进程的虚拟地址空间独立,所以每个应用程序都隔离运行,如果一个应用程序发生故障,则故障仅局限于该应用程序, 其他应用程序和操作系统不会受该故障的影响,这就是用户模式的意义所在。 -
内核模式:此时进程可以执行指令集中的任何指令,访问系统所有存储器的位置,如果是x86处理器则在Ring0运行,有最高权限。进程从用户模式转变为内核模式的唯一方法是通过异常诸如中断、故障、陷阱、终结等触发系统自陷/访管指令。
当程序要调用系统服务时,系统自陷/访管指令通过处理器设置某个控制寄存器中的一个模式位来实现这一功能。当设置了模式位后,进程就运行在内核模式,此时操作系统接管控制,然后根据该指令及有关参数,执行用户的请求服务。在服务完成后将处理器模式切换回用户模式,并将控制返回用户线程。因此用户线程有时在用户模式下运行一般代码,有时在内核模式下调用操作系统有关功能模块的代码。在内核模式下运行的所有代码都共享单个虚拟地址空间。 这意味着内核模式驱动程序不会与其他驱动程序和操作系统本身隔离。 如果内核模式驱动程序意外写入错误的虚拟地址,则属于操作系统或其他驱动程序的数据可能会受到安全威胁。 如果内核模式驱动程序发生故障,整个操作系统就会发生故障。
需要补充的是,操作系统没有单独的内核进程,内核中的代码必须由某个进程因为异常而切换到内核模式后才被执行的。实现机制也非常直观,操作系统内核是常驻内存的,其中包括内核的代码、数据和栈,只有某个进程切换到内核模式时才能执行其中内核的代码、数据和栈。由此不难看出,操作系统内核本质上就是一个状态机。另外,有的人称运行在内核模式的线程为内核线程,作者认为概念上容易产生歧义,还是称其运行在用户模式/内核模式较为准确。
关于用户线程和内核线程及其映射关系,将在线程篇中介绍,下面我们开始讲述引起用户模式到内核模式切换的事件:中断。
3. 进程中断
关于中断,网上很多资料描述并不准确,还和异常混淆起来,包括著名的经典《深入理解计算机系统》。老火查阅了大量资料后做了比较准确的划分,并甄别一些易混淆的概念,比如硬中断、软中断、同步中断、异步中断以及异常的分类等,不过水平有限,有需要更正的地方请留言讨论。本章主要包括中断流程、中断描述符表和中断分类的讲解。
3.1 中断流程
在系统结构中,CPU的工作模式有两种:一种是中断,由各种设备发起;一种是轮询,由CPU主动发起。因为本篇以进程为核心讲解,此外所有的linux操作系统都是基于中断驱动的,所以这里主要讲与进程相关的中断。
中断(Interrupt,简称INTR)其实就是由硬件或软件所发送的一种称为中断请求(Interrupt Request,简称IRQ)的信号。处理中断的流程为:IO设备(如键盘,串口卡,并口等设备)或软件(如调用、异常等)请求使用CPU时,把IRQ信号发送给中断控制器(比如8259A可编程中断控制器芯片),中断控制器根据中断向量表(Interrupt Description Table,简称IDT,它位于内存的某固定地址)将IRQ转换为中断向量发送给CPU。CPU根据中断优先级判断是否接受中断向量,一旦CPU接收了中断向量,CPU就会暂停正在运行的程序,并且调用一个称为中断服务程序(interrupt service routine,有的也叫中断处理器)的特定程序进行中断处理,CPU处理完中断后会恢复之前被中断的程序。
在linux的机器上,可以通过文件/proc/interrupts查看关于哪些中断正在被使用和每个处理器各被中断了多少次的信息,这部分请参考文献7。
3.2 中断描述符表
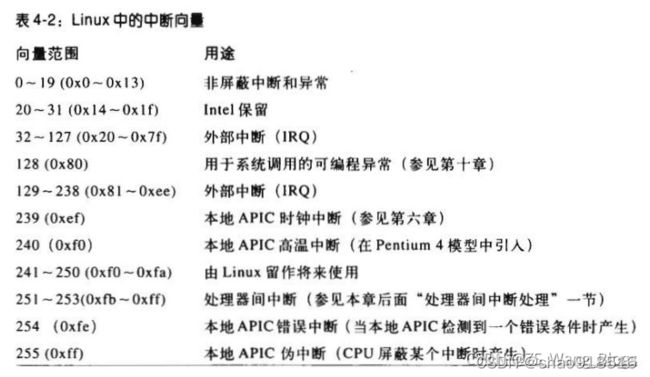
中断描述符表(Interrupt Descriptor Table IDT)是一个系统表,它与每一个中断向量相关联,每一个向量在表中有相应的中断处理程序的入口地址。 每个描述符8个字节,共256项,占用2KB空间 。内核启动中断前,必须初始化IDT,然后把IDT的基地址装载到idtr(中断描述符表寄存器)中,以便后续的中断控制器查询使用。
由于中断向量为3的int3汇编指令允许用户进程发出一个中断信号,其值可以是0——255之间的任意一个向量 。所以为了防止用户利用int3指令非法模拟中断和异常,所以初始化IDT时要谨慎设置特权级。除了3、4、5和128的中断向量,其余都是intel提供给系统使用的中断,所以可以通过把系统中断向量的特权级字段DPL(Descriptor of Privilege Level)设置成0来屏蔽用户进程。然而用户进程有时必须要能发出一个编程异常,为了做到这一点,需要把编号为3、4、5和128的中断向量的特权级设置成3,
Intel根据特权级和用途的不同,提供了三种类型的中断描述符:
- 中断门:用户态的进程不能访问,特权级为0,所有的中断都通过中断门激活,并全部在内核态。
- 陷阱门:用户态的进程不能访问,特权级为0,大部分linux异常处理程序通过陷阱门激活。
- 系统门:用户态的进程可以访问,特权级为3,通过系统门来激活4个linux异常处理程序,它们的向量是3、4、5和128。因此,在用户态下可以发布int3、into、bound和int $0x80四条汇编指令。也有资料将int3称为系统中断门,这里归为系统门,不再单独划分。
简单说,Linux利用中断门处理中断,利用陷阱门处理异常,利用系统门给用户提供系统调用。
IDT中的中断向量范围及用途如下图所示:
3.3 中断分类:软中断与硬中断
Linux中通常将中断分为同步中断和异步中断:
同步中断:是当指令执行时由 CPU 控制单元产生,之所以称为同步,是因为只有在一条指令执行完毕后 CPU 才会发出中断,而不是发生在代码指令执行期间,比如系统调用。由于一般是软件发出的,所以又称为软中断或异常。(exception)。
异步中断:是指由其他硬件设备依照 CPU 时钟信号随机产生,即意味着中断能够在指令之间发生,例如键盘、网络适配器、磁盘控制器和定时器芯片。这里中断是异步发生的,一般来自硬件,又称为硬中断。
在intel处理器手册中,也把同步中断和异步中断称为异常(exception)和中断(interrupt),老火认为容易引起歧义,所以老火将中断分为软中断(异常)和硬中断。下文中术语“中断信号”代指这两种类型(同步及异步)。
对于中断描述符表中的中断向量,Intel公司使用0-31号中断向量作为软中断(异常)处理,剩下32-255号中断向量共224个中断向量,除了128号向量0x80 (SYSCALL_VECTOR)用作系统调用总入口之外,其他都用在外部硬件中断源上。下面详细讲解这两种中断。
3.3.1 软中断(异常)
软中断也称为异常,为方便叙述,下文统称为异常。Intel公司保留0-31号中断向量用来处理异常事件:当产生一个异常时,处理机就会自动把控制转移到相应处理程序的入口,异常的处理程序通常由操作系统提供。 异常通常在CPU执行指令时,由CPU自身产生。例如,数字除以0会产生一个divide-by-zero的异常,从而导致计算机取消计算并提示错误信息。
Intel的80x86系列的CPU指令集使用0-31号中断向量作为异常处理,但只发布了大约20中不同的异常,剩余10个中断信号作为保留未用。内核必须为每种异常提供一个专门的处理程序,它通常把一个Unix信号Signal发送到引起异常的进程。异常处理信号如下图所示(其中2号NMI为非屏蔽中断):
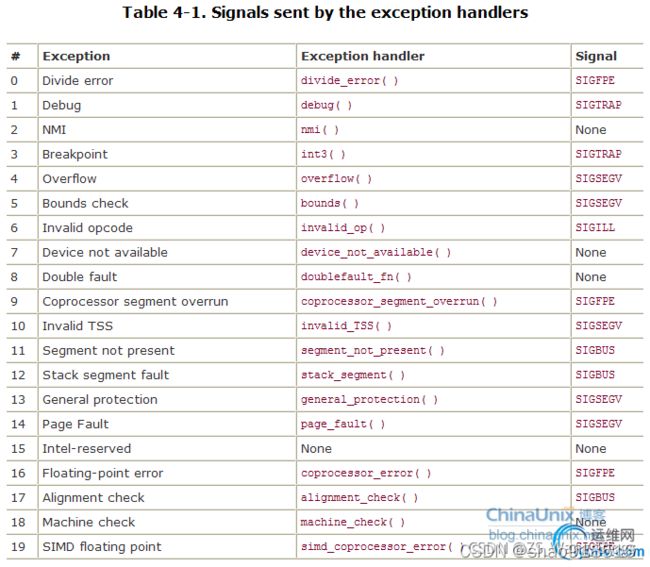 根据异常时保存在内核堆栈中的eip的值,可以将异常进一步分为:
根据异常时保存在内核堆栈中的eip的值,可以将异常进一步分为:
- 故障(fault):eip=引起故障的指令的地址,故障由错误情况引起,它可能被故障处理程序修正:如果错误被修正,它就将控制返回到引起故障的指令,从而重新执行它;否则,处理程序返回到内核中的abort例程,中止(并转储内存)引起故障的应用程序。一个经典的故障示例是缺页异常。
- 陷阱(trap):eip=随后要执行的指令的地址。是有意的异常,是执行一条指令的结果,是同步发生的。它最重要的用途是在用户程序和内核之间提供一个像过程一样的接口,叫做系统调用。
- 中止(abort):eip=???,此时eip值无效,发生严重的错误,只有强制终止受影响的进程。中止通常是一些硬件错误。例如DRAM或者SRAM位被损坏时发生的奇偶错误。终止处理程序从不将控制返回给应用程序。在Linux中,除零、浮点异常或者内存访问违例(访问只读文本段)都会导致应用程序故障和终止。
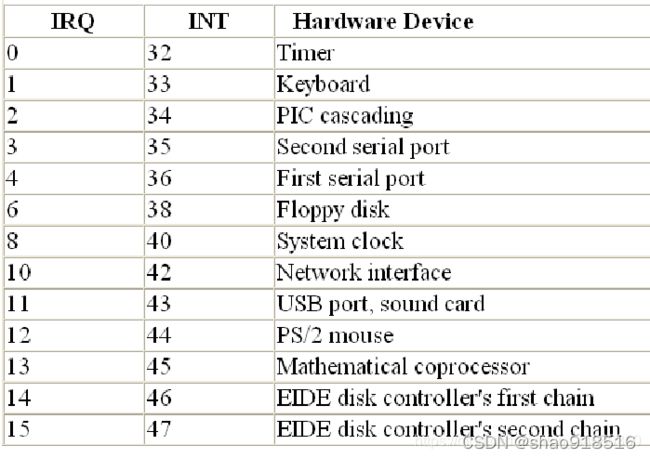
3.3.2 硬中断
除了异常,IDT中还剩下32-255号中断向量共224个中断向量可以使用。这224个中断向量的分配方式即除了128号向量0x80 (SYSCALL_VECTOR)用作系统调用总入口之外,其他都用在外部硬件中断源上,也就是所谓的硬中断,包括可编程中断控制器8259A的15个irq(如下图所示);事实上,当没有定义CONFIG_X86_IO_APIC(I/O高级可编程控制器:I/O Advanced Programmable InterruptController APIC)时,其他223(除0x80外)个中断向量,只利用了从32号开始的15个,其它208个空着未用。 硬中断IRQ与中断向量对照表如下图所示:
 另外,硬中断主要分为两种类别:
另外,硬中断主要分为两种类别:
a. 非屏蔽中断(Non-maskable interrupts,即NMI):就像这种中断类型的字面意思一样,这种中断是不可能被CPU忽略或取消的。NMI是在单独的中断线路上进行发送的,它通常被用于关键性硬件发生的错误,如内存错误,风扇故障,温度传感器故障等。
b. 可屏蔽中断(Maskable interrupts):这些中断是可以被CPU忽略或延迟处理的。当缓存控制器的外部针脚被触发的时候就会产生这种类型的中断,而中断屏蔽寄存器就会将这样的中断屏蔽掉。我们可以将一个比特位设置为0,来禁用在此针脚触发的中断。
另外需要补充说明的是:中断处理与过程调用是不同的。比如:中断从用户程序转移到内核,所有上下文都会被压到内核栈中,而不是用户栈;而且根据中断类型的不同,中断处理程序的返回地址可能是当前指令(当事件发生时正在执行的指令),也可能是下一条指令,过程调用总是下一条指令;最后,中断处理程序自身运行在内核模式下。
本章讲解了中断的基本概念,包括中断流程、中断描述符表和中断的基本分类,想了解更多中断知识的读者可参考文献6。既然产生了中断,CPU就需要重新调度进程,CPU根据哪些调度算法挑选进程呢?这正是下篇的起始。
本打算行文尽量简洁,但达不到讲精讲细的目的,所以我对本系列文章的定位是复杂知识点详细总结,在此基础上做到尽量简练。由于查阅了大量资料,耗费了很多精力,虽然谈不上尽善尽美,但也希望各位支持作者一下,来个一键四联(点赞、收藏、评论、转发),希望帮助到不断探索的你。
由于老火最近有其他事情,本系列文章会暂停更新,本文提到剩余的相关资料,感兴趣的小伙伴可以私信老火索取。
参考文献
- 从根上理解高性能、高并发(七):深入操作系统,一文读懂进程、线程、协程
- 深入理解操作系统原理之进程管理
- 深入理解计算机系统》| 虚拟存储器
- 【CPU】用户模式和内核模式(用户层和内核层)
- Linux中的中断与异常分析
- linux内核学习10:中断和异常
- linux下的中断(interrupt)IRQ以及IRQ绑核小结
- UNIX v6的进程控制块proc结构体和user结构体
- 操作系统-进程(1)进程与进程调度
- 浅析Linux下的task_struct结构体
- Linux 进程虚拟内存
- Linux内核进程上下文切换深入理解