引用、动态内存分配、函数、结构体
引用
定义和初始化
**数据类型 &引用名 = 目标名;**
引用和目标共用同一片空间(相当于对一片空间取别名)。
引用的底层实现:数据类型 * const p; ------> 常指针
int const *p; -----> 修饰 *p
const int *p; -----> 修饰 *p
int *const p; -----> 修饰 p
const int *const p; -----> 修饰 *p 和 p
& 的使用
1、取变量的地址
2、位与运算符
3、&& 逻辑与
4、定义引用(如果 & 前面有数据类型,就说明是在定义引用)
常引用
const <数据类型> &<变量名> = 常数;
<数据类型> const &<变量名> = 常数;
e.g. const int &num = 15;
作用:保护目标不能通过引用修改。
#include 

引用的性质
1、定义引用时必须初始化(不能初始化为 NULL);
2、访问引用相当于访问目标;
3、引用的目标一旦指定,不能修改;
4、引用和目标占用同一片空间(引用不会额外开辟空间);
#include 
5、将变量的引用的地址赋值给一个指针,此时指针指向的还是原来的变量;
#include 6、可以对指针建立引用。
#include 引用和指针的区别
1、引用定义必须初始化,指针定义可以不初始化(野指针);
2、指针可以指向 NULL,引用的目标不可以为空;
3、可以改变指针的指向,不能改变引用的目标;
4、存在指针数组,但是不存在引用数组;
5、指针会额外开辟空间,引用不会额外开辟空间;
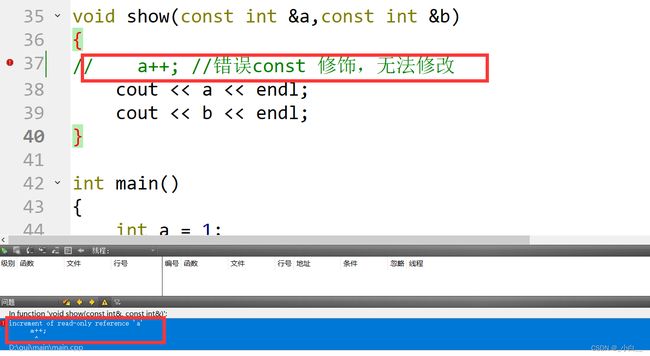
6、有多级指针,没有多级引用;
指针、数组的引用
指针的引用
数据类型 *(&引用名) = 指针名;
数组的引用
数据类型 (&引用名)[数组长度] = 数组名;
#include 
引用实现数组传参
利用引用实现数组的传参,并冒泡排序。
#include 引用作为函数的形参
优点:
1、不需要额外开辟空间;
2、不涉及到值传递和地址传递的问题,传到函数内部的就是实参本身。
#include 
引用作为参数进行定义的时候,是不会产生副本的,这样会提高代码的运行效率,因此在正常编程中,建议使用引用进行传递参数。
在 引用形参 不参与计算的情况下,建议使用 const 修饰引用形参,以达到引用的安全性。
引用作为函数的返回值
类比:指针函数
以指针作为函数的返回值,返回长生命周期的变量的地址。
1、全局变量(静态区)的地址;
2、static 修饰的局部变量(静态区)的地址;
3、申请的堆区空间的地址;
4、常量区空间的地址;
5、实参传递过去的地址。
推理:引用作为函数的返回值
和指针函数一样,将引用作为函数的返回值,需要返回长生命周期的变量的引用。
引用作为函数的返回值,是一个左值(因为返回引用就是返回变量本身),可被赋值和自增自减运算。
#include 
动态内存分配
C 中的动态内存分配:malloc 和 free 在 C++ 中可以继续使用。
new
单个内存空间的申请
申请
数据类型 *指针名 = new 数据类型;
// new 会按照数据类型申请空间
申请并初始化
数据类型 *指针名 = new 数据类型(初始数据);
// 申请到空间中的初始值就是 () 内的数据
多个内存空间的申请
数据类型 *指针名 = new 数据类型[size]{若干初始数据};
// 使用 new 申请多个空间,仍然可以使用不完全初始化的方式 // ,未初始化的部分默认为 0
delete
单个内存空间的释放
delete 指针名;
多个内存空间的释放
delete [] 指针名;
#include 
C++ 中不推荐使用 malloc 和 free:
malloc / free 不会自动调用 构造函数 / 析构函数;
new / delete 会自动调用 构造函数 / 析构函数。
new/delete 和 malloc/free 的区别
1、malloc 和 free 是库函数,new 和 delete 是关键字;
2、 使用 malloc 申请空间时,需要强转,还需要计算申请空间的大小;
使用 new 不需要强转,也不需要求大小;
3、malloc 按字节申请空间,new 按数据类型申请空间;
4、malloc 申请时不能执行初始化操作,new 可以申请的同时初始化;
5、delete 在释放空间时,需要考虑是单个空间还是多个空间,free 不需要考虑空间问题;
6、malloc 不会调用构造函数,new 会调用构造函数;
7、free 不会调用析构函数,delete 会调用析构函数。
函数
函数重载
概念
实现一名多用,解决同一功能的函数因为参数类型或个数不同,需要多次定义不同名函数的问题。
函数重载属于静态多态的一种。
定义要求
1、函数名相同;
2、形参不同(可以是个数不同,也可以是类型不同,还可以是顺序不同);
3、作用域相同;
4、若函数仅有返回类型不同,然而不满足前三条,则不构成重载;
5、若函数的参数列表中有参数被 const 修饰,然而不满足前三条,则不构成重载;
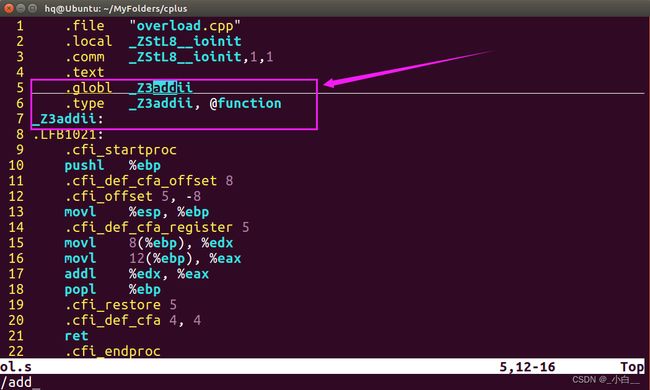
#include 运行结果如下:

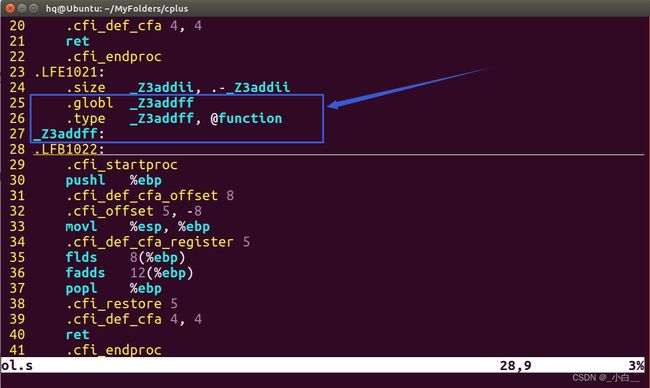
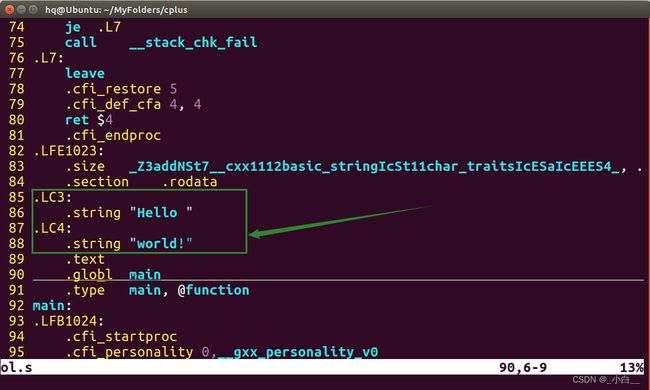
可以通过 g++ -S xxx.cpp -o xxx.s ----->查看 xxx.s 可以看到
函数的默认参数
C 函数参数的获取方式:在函数被调用时,获取传递过来的实参(都是从主调函数处获取的)。
C++中支持函数的默认参数:
在定义函数时,可以给某一些形参添加默认值,
调用函数时,如果默认参数处有实参传过来,则使用实参的值;
调用函数时,如果没有给默认参数传参,则该参数使用默认值。
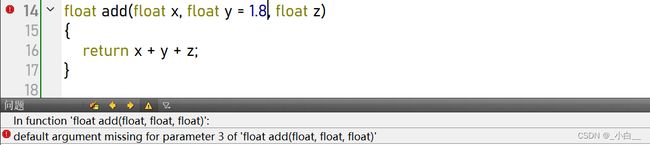
#include 默认参数必须遵循靠右原则:
若某一个参数有默认参数,则该参数右侧的所有参数一定有默认参数。因为函数传参时遵循靠左原则。
// 错误示范
float add(float x, float y = 1.8, float z) // 报错
{
return x + y + z;
}
避免函数重载和默认参数同时出现:
#include 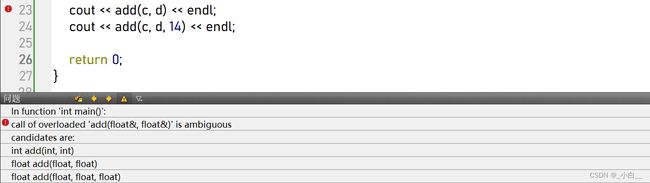
默认参数尽量写在函数声明处
如果函数的定义和声明是分开的,默认参数只能出现在一个位置。
#include 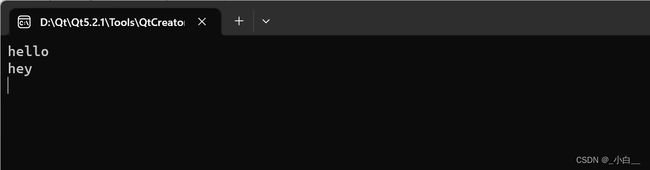
哑元
在函数的参数列表中,某个参数只有数据类型而没有变量名,则称此参数为“哑元”。
虽然在函数内获取不到哑元参数,但在调用函数时,仍要对其传参。
#include 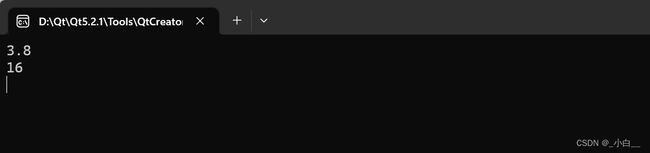
哑元的使用场合:
1、保证代码的向下兼容
对大型的程序的某个功能进行更新,且需要保证代码的向下兼容(前面版本的代码仍然可以使用)时,就可以将某些参数设定为哑元。
2、运算符重载时,自增自减运算符的重载。
3、用来区分函数重载
#include 
内联函数(inline)
内联函数用于取代 C 语言中宏定义的函数,正确使用内联函数可以提升程序的执行效率。内联函数在编译时候,直接把函数体展开到主函数中编译,在运行期间可以减少调用的开销。(以空间换时间)
通常具有以下性质的函数可以写为内联函数:
● 代码长度5行以内
● 不包含复杂的控制语句
● 频繁被调用
inline 函数类型 函数名(参数列表);
把函数体在调用处展开。(函数调用 ——> 顺序执行)
优缺点:
可以提高运行效率(函数调用时没有压栈和出栈的过程),但可能会造成代码膨胀。
适用条件:
函数被频繁调用,函数体尽量小。
是否展开成内联函数?
手动添加的 inline 关键字只是给编译器的一个建议,
如果加了 inline 关键字,但是编译器认为效率不会提高,函数就不会被展开成内联函数;
如果编译器认为展开为内联函数会提高效率,则无论是否加 inline 都会将函数展开为内联函数。
结构体
C++ 中的结构体 和 C 中结构体 的区别
1、C++ 中定义结构体变量,不需要加 struct;
2、C++ 中结构体内,可以定义函数;
3、C++ 中结构体内,可以给结构体成员初始化;
4、C++ 中结构体内,可以定义另一个结构体类型;
5、C++ 中结构体成员,可以设置访问权限(默认为 public);
6、C++ 中的结构体可以继承;
7、当 C++ 结构体中有引用成员时,有两种初始化方法:
① 给结构体中的引用成员一个初始值;
② 定义结构体变量时,给引用成员初始化。
#include 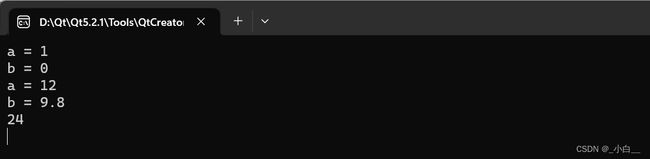
字节对齐的规则:
每一个结构体中成员都在其本身偏移量的整数倍上,
自身偏移量 = 操作系统对齐数 < 自身所占字节数 ? 操作系统对齐数 : 自身所占字节;
结构体本身的大小:最大成员偏移量的整数倍。
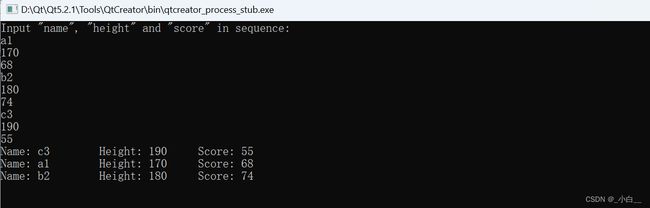
结构体练习 1
定义一个学生的结构体,包含私有的(private)成员变量:姓名、身高,
公有的(public)成员变量:成绩。
对于私有的成员变量,提供公有的接口(方法),实现对身高和姓名的赋值,输出身高、姓名和成绩,
再实现一个函数完成对成绩的修改。定义结构体变量,在主函数内对封装的函数进行测试。
#include 
字节对齐练习
结构体练习 2
定义一个结构体数组,给结构体数组中的各成员中的每个成员变量赋值,并对结构体数组中所有成员的成绩进行排序。
#include 运行结果如下: