Redis——redis的java客户端+(Jedis和SpringDataRedis)
客户端对比
一个Spring Data Redis底层可以兼容前两个

Jedis快速入门
直接使用命令名作为方法名就是Jedis好学的原因
第一步 :
创建一个maven项目并导入如下依赖,除了redis的以来还有一个junit5的依赖
redis.clients
jedis
5.0.0-alpha2
org.junit.jupiter
junit-jupiter
5.9.2
test
第二步:
在测试类中调试,先进行数据库连接,使用到一个注解@BeforeEach,这个方法又junit5提供,可以在每个@Test方法执行前先执行一遍
@BeforeEach
void setup(){
//1.建立连接,端口号默认为6379,不过我是容器部署,要看你具体映射到外面哪个端口号
jedis=new Jedis("XXX.XX.XXX.XXX",6379);
//2.设置密码
jedis.auth("XXXXXX");
//3.选择库
jedis.select(X);
}第三步:
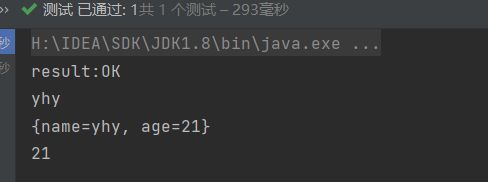
进行增加数据并查询数据测试,使用到junit5提供的@Test注解
@Test
void test(){
//存入数据
String result=jedis.set("name","yhy");
System.out.println("result:"+result);
//获取并打印数据
System.out.println(jedis.get("name"));
//存入hash数据
jedis.hset("user:1","name","yhy");
jedis.hset("user:1","age","21");
//获取hash数据,这里默认封装成了map类型
Map mp=jedis.hgetAll("user:1");
String str=jedis.hget("user:1","age");
System.out.println(mp);
System.out.println(str);
} 第三步:
关闭数据库连接,使用到@AfterEach注解,可以在所有@Test方法执行后执行
@AfterEach
void tearDown(){
if(jedis!=null){
jedis.close();
}
}运行测试成功如下
让我回想起初学jdbc的日子
Jedis的连接池
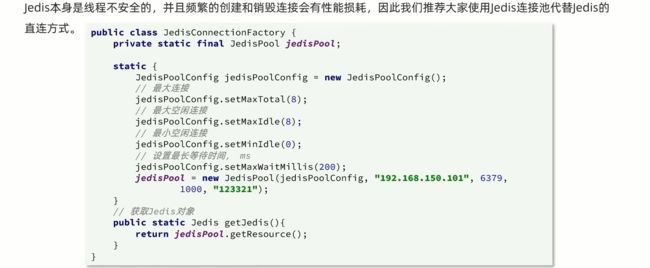
第一步:创建一个连接池配置类
这里将其作为静态全局变量,使用静态代码块进行初始化
public class JedisConnectionFactory {
private static final JedisPool jedisPool;
static{
//配置连接池
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//最大连接数
jedisPoolConfig.setMaxTotal(8);
//最大空闲连接
jedisPoolConfig.setMaxIdle(8);
//最小空闲连接
jedisPoolConfig.setMinIdle(0);
//最长等待时间
jedisPoolConfig.setMaxWaitMillis(1000);
//创建连接池对象
jedisPool=new JedisPool(jedisPoolConfig,
"xxx.xx.xxx.xxx",6379,1000,"xxxx");
}
public static Jedis getJedis(){
return jedisPool.getResource();
}
}第二步:从线程池获取连接
就只是在上面那个的初始化代码里面改了改而已
@BeforeEach
void setup(){
//1.建立连接
jedis= JedisConnectionFactory.getJedis();
//2.选择库,如果不选,默认选择0库
jedis.select(0)
}成功运行输出
认识SpringDataRedis
springdata封装了对许多数据库操作的模块,而SpringDataRedis底层就整合了lettuce和jedis客户端
redis底层存的都是字符串或者字节数组,所以存数据时需要手动转换成字符串或者字节数组。

然后 springdataredis就支持数据序列化和反序列化。
SpringDataRedis快速入门
第一步:创建一个springboot项目并导入相关依赖
这里创建的是psingboot2.x版本,jdk用的8,然后添加下面两个依赖
然后再增加一个连接池依赖
org.apache.commons
commons-pool2
第二步:在配置文件配置连接信息
在这里配置连接池时有两个选项,一个是jedis一个是lettuce,默认选择lettuce-core,选jedis的话还需要添加jedis连接池的依赖。
spring:
redis:
host: xxx.xx.xxx.xxx
port: 6379
password: xxxxxx
database: 0
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 100ms
第三步:在测试类中调试运行
@SpringBootTest
class SdrDemo1ApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
//写入一条String数据
redisTemplate.opsForValue().set("name","北岭山脚鼠鼠");
//获取String数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name="+name);
}
}
输出如下

虽然但是,在图形化界面却看见没有修改成功,但是获取时确实获取了正确数据。
在图形化界面可以看见有两个name的key
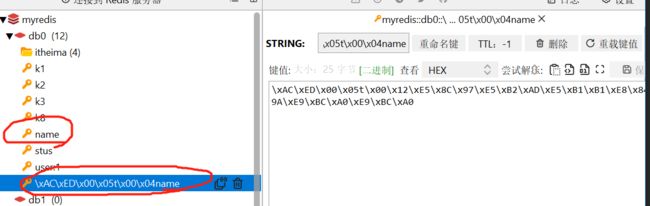
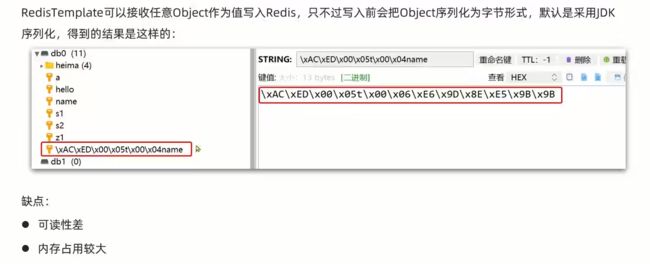
实际上这一长串的\xAC\xED\x00\x05t\x00\x12\xE5\x8C\x97\xE5\xB2\xAD\xE5\xB1\xB1\xE8\x84\x9A\xE9\xBC\xA0\xE9\xBC\xA0
就是上面修改的北岭山脚鼠鼠。
原因是set方法应该接受的是一个object,而不是一个字符串。springdataRedis的一个功能就是接受任何类型的对象,然后转成redis可以处理的字节。
传进去的字符串都被用序列化工具处理了。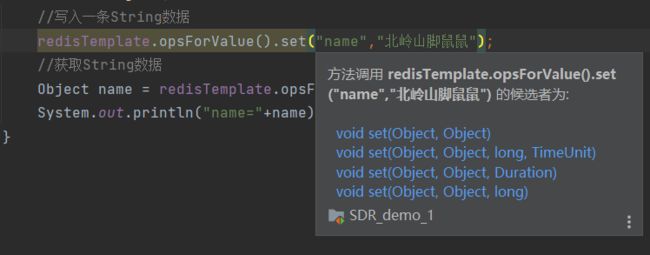
如下针对的不同的数据类型有不同的序列化方法处理
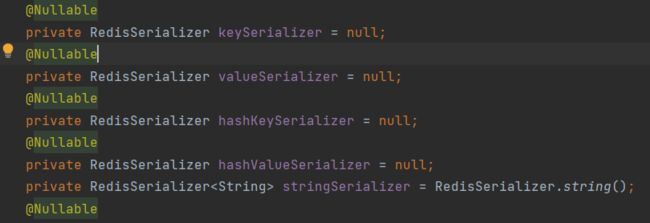
在源码底层有这么一个处理,将对象转换成流

 这样有一个更大的缺陷,用的java客户端存时,如果用别的客户端取出来时没有反序列化工具转换回去的话别人就无法使用这些数据。
这样有一个更大的缺陷,用的java客户端存时,如果用别的客户端取出来时没有反序列化工具转换回去的话别人就无法使用这些数据。
故这里不能使用RedisTemplate默认的序列化方法了
故查看提供的别的一些方法有如下两个可以使用
 一个是StringRedisSerializer,直接就是getBytes(),在key和hashkey都是字符串的情况下使用,string序列化类型。
一个是StringRedisSerializer,直接就是getBytes(),在key和hashkey都是字符串的情况下使用,string序列化类型。
在value有可能是对象时使用GenericJack2JsonRedisSerializer,转json序列化类型
修改序列化方式
 还需要引入一个jackson的依赖,如果是有引入了springmvc的话就会带有这个依赖了
还需要引入一个jackson的依赖,如果是有引入了springmvc的话就会带有这个依赖了
com.fasterxml.jackson.core
jackson-databind
2.14.2
在配置类注册一个Bean对象如下,然后就可以注册到IOC容器实现自动装配了
@Configuration
public class RedisConfig {
//连接工厂由spring自动创建并注入进来
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
//创建RedisTemplate对象
RedisTemplate template = new RedisTemplate<>();
//设置连接工厂
template.setConnectionFactory(redisConnectionFactory);
//设置JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//设置key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
//设置value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
//返回
return template;
}
} 然后修改上面测试类中的代码,指定参数类型
@SpringBootTest
class SdrDemo1ApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
//写入一条String数据
redisTemplate.opsForValue().set("name","北岭山脚鼠鼠");
//获取String数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name="+name);
}
} 运行测试输出


这一次成功修改。
对象的序列化
在pojo层添加一个实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String User;
private Integer age;
}新增测试方法
@Test
void testOUser(){
//写入数据
redisTemplate.opsForValue().set("user:100",new User("yhy",21));
//获取数据并强转数据
User user = (User) redisTemplate.opsForValue().get("user:100");
System.out.println("user:"+user);
}控制台输出如下

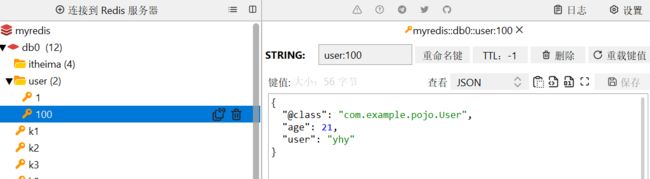
图形化界面查看有如下json风格的结果,获取结果的自动化反序列成上面的User对象,正是因为有"@class": "com.example.pojo.User",这个属性,在反序列时才能读取到User类并自动反序列化.
反射创建对象,设置属性值。
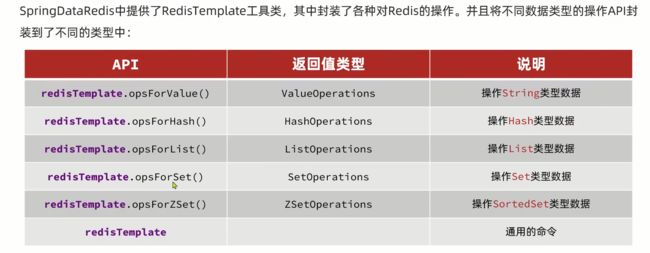
springRedisTemplate
多出的字节码会导致内存空间占用大。
因此不会使用json的序列化器处理value,而是统一使用string的序列化器处理value。
string的序列化器要求只能处理字符串。
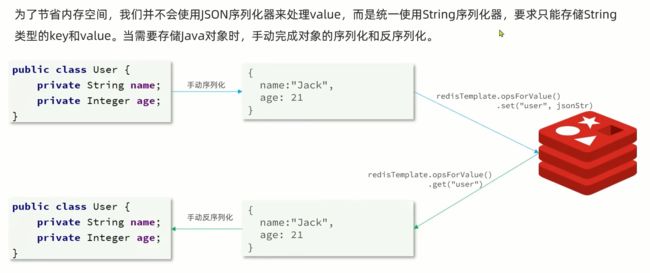
spring提供了一个springRedisTemplate ,其中key和value的序列化方式吗,默认就是string序列化方式。
但是对象还是要我们手动转成json字符串,这里有两个选择,一个是用fast json,要自己导依赖一个是使用ObjectMapper,这个是json里面默认提供的json序列化处理工具。
代码修改如下。
将来可以封装成一个工具类进行处理。
@SpringBootTest
class SdrDemo1ApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
private static final ObjectMapper mapper=new ObjectMapper();
@Test
void testString() {
//写入一条String数据
stringRedisTemplate.opsForValue().set("name","北岭山脚鼠鼠");
//获取String数据
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name="+name);
}
@Test
void testOUser() throws JsonProcessingException {
//创建对象
User user=new User("yhy",21);
//手动序列化
String json = mapper.writeValueAsString(user);
//写入数据
stringRedisTemplate.opsForValue().set("user:100",json);
//获取数据并强转数据
String jsonUser=stringRedisTemplate.opsForValue().get("user:100");
//手动反序列化,需要提供实体类的字节码
User user1=mapper.readValue(jsonUser,User.class);
System.out.println("user:"+user1);
}
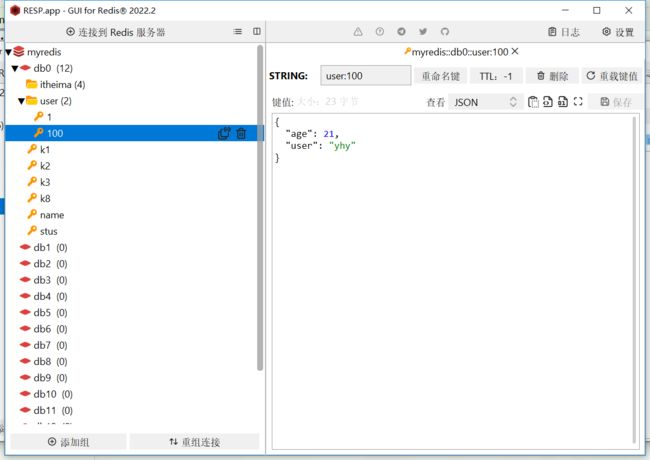
}控制台和图形化界面都没问题,没有多余的字节码存入数据库了。

小结

补充
RedisTemplate类型处理Hash类型
@SpringBootTest
class SdrDemo1ApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void TestHash(){
Map map=new HashMap<>();
map.put("weight","140");
map.put("high","172");
//存入数据,可以一个个存,也可以直接存个map
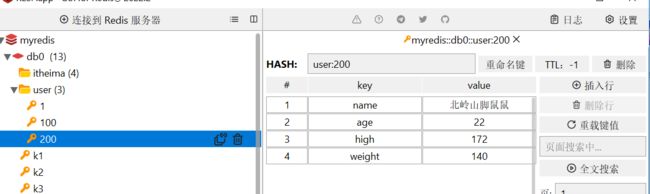
stringRedisTemplate.opsForHash().put("user:200","name","北岭山脚鼠鼠");
stringRedisTemplate.opsForHash().put("user:200","age","22");
stringRedisTemplate.opsForHash().putAll("user:200",map);
//取出对象,可以取一个,也可以取多个
stringRedisTemplate.opsForHash().get("user:200","name");
Map entries = stringRedisTemplate.opsForHash().entries("user:200");
System.out.println("entries="+entries);
}
} 输出如下
![]()