spark 输出结果压缩(gz)
如果不想往下看,可以直接看结果:maxCallRdd.repartition(3).saveAsTextFile(path,GzipCodec.class); 恩,没错。就只这么一行简单的代码实现了gz压缩,但是为什么网上一直没找到呢,这个我不太清楚, 可能是他们没碰到吧。
最近项目的需求,其实很简单,就是将输出结果以.gz的格式压缩,每个压缩包的大小不能超过100M,而且压缩包的名称也有要求,就是要以时间来命名,如下:
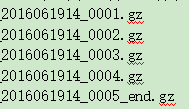
如 果一个文件大小超过400m,小于500m,则分成5个.gz文件来压缩,如果这个是用java平常的项目和apache的压缩工具api来弄,是一件非 常easy的事情,但是,需求一波三折,最终的最终要求是spark计算完,结果落地的时候,把数据压缩好保存到hdfs中。恩,领导的想法总是对的,我 一向这样认为。需求定下来,剩下的事情就是实现了。
1)首先把结果压缩落地
其实spark是支持结果压缩落地的,具体api是void org.apache.spark.api.java.AbstractJavaRDDLike.saveAsTextFile(String path, Class codec)
跟saveAsTextFile(String path)相比只是多了一个参数,这个参数就是指定压缩算法的。这里有个问题,就是压缩算法类必须是CompressionCodec接口的实现类Class,那么就要看看CompressionCodec是什么以及有哪些实现类了。其实这里有个坑,如果不查看源代码的话,说不定你会一直在哪里问为什么,而且一直死循环。下面说说这个坑,说完了再说具体实现。先上图:
可 以看到这个接口在hadoop和spark-core都有。但是具体用的是那个呢?毫无疑问,当然是用spark自带的了,但是如果真的这样想也不怪你, 因为自身带有的肯定是最好的,就好像帮亲不帮理一样。首先看看spark自身带的是什么形式的,直接上代码:想详细了解这个类的,可以从头看一遍,不想看 的可以直接略过代码,直接看我啰嗦几句,其实就是定义了一个叫CompressionCodec,然后在里面定义了一些实现类, 如:LZFCompressionCodec(conf: SparkConf) extends CompressionCodec,class LZ4CompressionCodec(conf: SparkConf) extends CompressionCodec,然后你会想:既然已经有了实现类了,那么我直接在maxCallRdd.saveAsTextFile(path, SnappyCompressionCodec.class)就完事收工了,嘻嘻,如果真的是这样,那我还写这篇东东干嘛,你会看到下面的情况:
看 到没,如果你使用spark-core自带的CompressionCodec的实现类是错误的,错误的,错误的。重要的事情说三遍,然后肯定会想打死 spark的开发人员,什么玩意啊,自己写的方法,居然不兼容自己的实现类。这个就是坑了,不知道是我说明还没到家还是怎么样,反正我觉得吧,你自己框架 的方法参数居然不是自己的实现类。找打是吧,也有一个可能是因为我是用java写的api,所以用的不是spark的实现类,因为我查了网上的很多文章都 是用spark的CompressionCodec 实现了,而且用的很欢,一点问题也没有。好,说完了坑了,说说怎么填吧,轻轻跳过下面的代码。
包名是package org.apache.spark.io
@DeveloperApi
trait CompressionCodec {
def compressedOutputStream(s: OutputStream): OutputStream
def compressedInputStream(s: InputStream): InputStream
}
private[spark] object CompressionCodec {
private val configKey = "spark.io.compression.codec"
private[spark] def supportsConcatenationOfSerializedStreams(codec: CompressionCodec): Boolean = {
(codec.isInstanceOf[SnappyCompressionCodec] || codec.isInstanceOf[LZFCompressionCodec]
|| codec.isInstanceOf[LZ4CompressionCodec])
}
private val shortCompressionCodecNames = Map(
"lz4" -> classOf[LZ4CompressionCodec].getName,
"lzf" -> classOf[LZFCompressionCodec].getName,
"snappy" -> classOf[SnappyCompressionCodec].getName)
def getCodecName(conf: SparkConf): String = {
conf.get(configKey, DEFAULT_COMPRESSION_CODEC)
}
def createCodec(conf: SparkConf): CompressionCodec = {
createCodec(conf, getCodecName(conf))
}
def createCodec(conf: SparkConf, codecName: String): CompressionCodec = {
val codecClass = shortCompressionCodecNames.getOrElse(codecName.toLowerCase, codecName)
val codec = try {
val ctor = Utils.classForName(codecClass).getConstructor(classOf[SparkConf])
Some(ctor.newInstance(conf).asInstanceOf[CompressionCodec])
} catch {
case e: ClassNotFoundException => None
case e: IllegalArgumentException => None
}
codec.getOrElse(throw new IllegalArgumentException(s"Codec [$codecName] is not available. " +
s"Consider setting $configKey=$FALLBACK_COMPRESSION_CODEC"))
}
/**
* Return the short version of the given codec name.
* If it is already a short name, just return it.
*/
def getShortName(codecName: String): String = {
if (shortCompressionCodecNames.contains(codecName)) {
codecName
} else {
shortCompressionCodecNames
.collectFirst { case (k, v) if v == codecName => k }
.getOrElse { throw new IllegalArgumentException(s"No short name for codec $codecName.") }
}
}
val FALLBACK_COMPRESSION_CODEC = "snappy"
val DEFAULT_COMPRESSION_CODEC = "lz4"
val ALL_COMPRESSION_CODECS = shortCompressionCodecNames.values.toSeq
}
/**
* :: DeveloperApi ::
* LZ4 implementation of [[org.apache.spark.io.CompressionCodec]].
* Block size can be configured by `spark.io.compression.lz4.blockSize`.
*
* Note: The wire protocol for this codec is not guaranteed to be compatible across versions
* of Spark. This is intended for use as an internal compression utility within a single Spark
* application.
*/
@DeveloperApi
class LZ4CompressionCodec(conf: SparkConf) extends CompressionCodec {
override def compressedOutputStream(s: OutputStream): OutputStream = {
val blockSize = conf.getSizeAsBytes("spark.io.compression.lz4.blockSize", "32k").toInt
new LZ4BlockOutputStream(s, blockSize)
}
override def compressedInputStream(s: InputStream): InputStream = new LZ4BlockInputStream(s)
}
/**
* :: DeveloperApi ::
* LZF implementation of [[org.apache.spark.io.CompressionCodec]].
*
* Note: The wire protocol for this codec is not guaranteed to be compatible across versions
* of Spark. This is intended for use as an internal compression utility within a single Spark
* application.
*/
@DeveloperApi
class LZFCompressionCodec(conf: SparkConf) extends CompressionCodec {
override def compressedOutputStream(s: OutputStream): OutputStream = {
new LZFOutputStream(s).setFinishBlockOnFlush(true)
}
override def compressedInputStream(s: InputStream): InputStream = new LZFInputStream(s)
}
/**
* :: DeveloperApi ::
* Snappy implementation of [[org.apache.spark.io.CompressionCodec]].
* Block size can be configured by `spark.io.compression.snappy.blockSize`.
*
* Note: The wire protocol for this codec is not guaranteed to be compatible across versions
* of Spark. This is intended for use as an internal compression utility within a single Spark
* application.
*/
@DeveloperApi
class SnappyCompressionCodec(conf: SparkConf) extends CompressionCodec {
val version = SnappyCompressionCodec.version
override def compressedOutputStream(s: OutputStream): OutputStream = {
val blockSize = conf.getSizeAsBytes("spark.io.compression.snappy.blockSize", "32k").toInt
new SnappyOutputStreamWrapper(new SnappyOutputStream(s, blockSize))
}
override def compressedInputStream(s: InputStream): InputStream = new SnappyInputStream(s)
}
/**
* Object guards against memory leak bug in snappy-java library:
* (https://github.com/xerial/snappy-java/issues/131).
* Before a new version of the library, we only call the method once and cache the result.
*/
private final object SnappyCompressionCodec {
private lazy val version: String = try {
Snappy.getNativeLibraryVersion
} catch {
case e: Error => throw new IllegalArgumentException(e)
}
}
/**
* Wrapper over [[SnappyOutputStream]] which guards against write-after-close and double-close
* issues. See SPARK-7660 for more details. This wrapping can be removed if we upgrade to a version
* of snappy-java that contains the fix for https://github.com/xerial/snappy-java/issues/107.
*/
private final class SnappyOutputStreamWrapper(os: SnappyOutputStream) extends OutputStream {
private[this] var closed: Boolean = false
override def write(b: Int): Unit = {
if (closed) {
throw new IOException("Stream is closed")
}
os.write(b)
}
override def write(b: Array[Byte]): Unit = {
if (closed) {
throw new IOException("Stream is closed")
}
os.write(b)
}
override def write(b: Array[Byte], off: Int, len: Int): Unit = {
if (closed) {
throw new IOException("Stream is closed")
}
os.write(b, off, len)
}
override def flush(): Unit = {
if (closed) {
throw new IOException("Stream is closed")
}
os.flush()
}
override def close(): Unit = {
if (!closed) {
closed = true
os.close()
}
}
}
生活就是从一个坑跳出来,正要准备大笑两声以抒怀的时候发现自己又跳进了另外一个更大的坑,这时只想说一个字,***。嗯,跑题了。。。。。直接看hadoop包里面的接口和实现:
public interface CompressionCodec
{
public abstract CompressionOutputStream createOutputStream(OutputStream outputstream)
throws IOException;
public abstract CompressionOutputStream createOutputStream(OutputStream outputstream, Compressor compressor)
throws IOException;
public abstract Class getCompressorType();
public abstract Compressor createCompressor();
public abstract CompressionInputStream createInputStream(InputStream inputstream)
throws IOException;
public abstract CompressionInputStream createInputStream(InputStream inputstream, Decompressor decompressor)
throws IOException;
public abstract Class getDecompressorType();
public abstract Decompressor createDecompressor();
public abstract String getDefaultExtension();
}
实现类有:
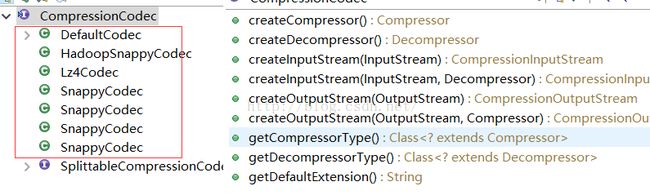
可以看到是没有GzipCodec实现的,所以这个真的只能靠经验啊,不然不会知道GzipCodec的存在的
2)重命名
其实一开始接触spark的时候,就觉得输出内容以park-00001命名就觉得丑,想自定义,但是却发现无从下手。所以只能另辟捷径了,使用hadoop自带的api来操作
FileStatus[] listStatus = fileSystem.listStatus(new Path(path));
for(......)
fileSystem.rename(fileStatus.getPath(), new Path(path+"/"+fileName));
ok,搞定。