【深度学习笔记】03 微积分与自动微分
03 微积分与自动微分
-
- 导数和微分
- 导数解释的可视化
- 偏导数
- 梯度
- 链式法则
- 自动微分
- 非标量变量的反向传播
- 分离计算
导数和微分
假设我们有一个函数 f : R → R f: \mathbb{R} \rightarrow \mathbb{R} f:R→R,其输入和输出都是标量。
如果 f f f的导数存在,这个极限被定义为
f ′ ( x ) = lim h → 0 f ( x + h ) − f ( x ) h . f'(x) = \lim_{h \rightarrow 0} \frac{f(x+h) - f(x)}{h}. f′(x)=h→0limhf(x+h)−f(x).
如果 f ′ ( a ) f'(a) f′(a)存在,则称 f f f在 a a a处是可微(differentiable)的。
如果 f f f在一个区间内的每个数上都是可微的,则此函数在此区间中是可微的。
我们可以将导数 f ′ ( x ) f'(x) f′(x)解释为 f ( x ) f(x) f(x)相对于 x x x的瞬时(instantaneous)变化率。
所谓的瞬时变化率是基于 x x x中的变化 h h h,且 h h h接近 0 0 0。
给定 y = f ( x ) y=f(x) y=f(x),其中 x x x和 y y y分别是函数 f f f的自变量和因变量。以下表达式是等价的:
f ′ ( x ) = y ′ = d y d x = d f d x = d d x f ( x ) = D f ( x ) = D x f ( x ) , f'(x) = y' = \frac{dy}{dx} = \frac{df}{dx} = \frac{d}{dx} f(x) = Df(x) = D_x f(x), f′(x)=y′=dxdy=dxdf=dxdf(x)=Df(x)=Dxf(x),
其中符号 d d x \frac{d}{dx} dxd和 D D D是微分运算符,表示微分操作。
可以使用以下规则来对常见函数求微分:
- D C = 0 DC = 0 DC=0( C C C是一个常数)
- D x n = n x n − 1 Dx^n = nx^{n-1} Dxn=nxn−1(幂律(power rule), n n n是任意实数)
- D e x = e x De^x = e^x Dex=ex
- D ln ( x ) = 1 / x D\ln(x) = 1/x Dln(x)=1/x
假设函数 f f f和 g g g都是可微的, C C C是一个常数,则:
常数相乘法则
d d x [ C f ( x ) ] = C d d x f ( x ) , \frac{d}{dx} [Cf(x)] = C \frac{d}{dx} f(x), dxd[Cf(x)]=Cdxdf(x),
加法法则
d d x [ f ( x ) + g ( x ) ] = d d x f ( x ) + d d x g ( x ) , \frac{d}{dx} [f(x) + g(x)] = \frac{d}{dx} f(x) + \frac{d}{dx} g(x), dxd[f(x)+g(x)]=dxdf(x)+dxdg(x),
乘法法则
d d x [ f ( x ) g ( x ) ] = f ( x ) d d x [ g ( x ) ] + g ( x ) d d x [ f ( x ) ] , \frac{d}{dx} [f(x)g(x)] = f(x) \frac{d}{dx} [g(x)] + g(x) \frac{d}{dx} [f(x)], dxd[f(x)g(x)]=f(x)dxd[g(x)]+g(x)dxd[f(x)],
除法法则
d d x [ f ( x ) g ( x ) ] = g ( x ) d d x [ f ( x ) ] − f ( x ) d d x [ g ( x ) ] [ g ( x ) ] 2 . \frac{d}{dx} \left[\frac{f(x)}{g(x)}\right] = \frac{g(x) \frac{d}{dx} [f(x)] - f(x) \frac{d}{dx} [g(x)]}{[g(x)]^2}. dxd[g(x)f(x)]=[g(x)]2g(x)dxd[f(x)]−f(x)dxd[g(x)].
导数解释的可视化
import numpy as np
from matplotlib_inline import backend_inline
from d2l import torch as d2l
def f(x):
return 3 * x ** 2 - 4 * x
def use_svg_display(): #@save
"""使用svg格式在Jupyter中显示绘图"""
backend_inline.set_matplotlib_formats('svg')
定义set_figsize函数来设置图表大小
def set_figsize(figsize=(3.5, 2.5)): #@save
"""设置matplotlib的图表大小"""
use_svg_display()
d2l.plt.rcParams['figure.figsize'] = figsize
set_axes函数用于设置由matplotlib生成图表的轴的属性
#@save
def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):
"""设置matplotlib的轴"""
axes.set_xlabel(xlabel)
axes.set_ylabel(ylabel)
axes.set_xscale(xscale)
axes.set_yscale(yscale)
axes.set_xlim(xlim)
axes.set_ylim(ylim)
if legend:
axes.legend(legend)
axes.grid()
通过这三个用于图形配置的函数,定义一个plot函数来简洁地绘制多条曲线。
#@save
def plot(X, Y=None, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), figsize=(3.5, 2.5), axes=None):
"""绘制数据点"""
if legend is None:
legend = []
set_figsize(figsize)
axes = axes if axes else d2l.plt.gca()
# 如果X有一个轴,输出True
def has_one_axis(X):
return (hasattr(X, "ndim") and X.ndim == 1 or isinstance(X, list)
and not hasattr(X[0], "__len__"))
if has_one_axis(X):
X = [X]
if Y is None:
X, Y = [[]] * len(X), X
elif has_one_axis(Y):
Y = [Y]
if len(X) != len(Y):
X = X * len(Y)
axes.cla()
for x, y, fmt in zip(X, Y, fmts):
if len(x):
axes.plot(x, y, fmt)
else:
axes.plot(y, fmt)
set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
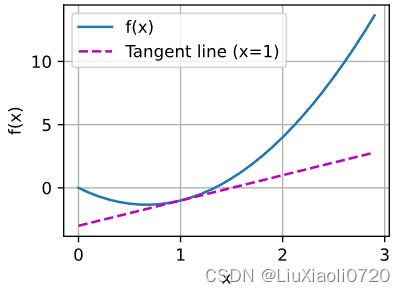
绘制函数 u = f ( x ) u=f(x) u=f(x)及其在 x = 1 x=1 x=1处的切线 y = 2 x − 3 y=2x-3 y=2x−3,其中系数 2 2 2是切线的斜率
x = np.arange(0, 3, 0.1)
plot(x, [f(x), 2 * x - 3], 'x', 'f(x)', legend=['f(x)', 'Tangent line (x=1)'])
偏导数
设 y = f ( x 1 , x 2 , … , x n ) y = f(x_1, x_2, \ldots, x_n) y=f(x1,x2,…,xn)是一个具有 n n n个变量的函数。
y y y关于第 i i i个参数 x i x_i xi的偏导数(partial derivative)为:
∂ y ∂ x i = lim h → 0 f ( x 1 , … , x i − 1 , x i + h , x i + 1 , … , x n ) − f ( x 1 , … , x i , … , x n ) h . \frac{\partial y}{\partial x_i} = \lim_{h \rightarrow 0} \frac{f(x_1, \ldots, x_{i-1}, x_i+h, x_{i+1}, \ldots, x_n) - f(x_1, \ldots, x_i, \ldots, x_n)}{h}. ∂xi∂y=h→0limhf(x1,…,xi−1,xi+h,xi+1,…,xn)−f(x1,…,xi,…,xn).
为了计算 ∂ y ∂ x i \frac{\partial y}{\partial x_i} ∂xi∂y,
可以将 x 1 , … , x i − 1 , x i + 1 , … , x n x_1, \ldots, x_{i-1}, x_{i+1}, \ldots, x_n x1,…,xi−1,xi+1,…,xn看作常数,
并计算 y y y关于 x i x_i xi的导数。
对于偏导数的表示,以下是等价的:
∂ y ∂ x i = ∂ f ∂ x i = f x i = f i = D i f = D x i f . \frac{\partial y}{\partial x_i} = \frac{\partial f}{\partial x_i} = f_{x_i} = f_i = D_i f = D_{x_i} f. ∂xi∂y=∂xi∂f=fxi=fi=Dif=Dxif.
梯度
可以连结一个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。
设函数 f : R n → R f:\mathbb{R}^n\rightarrow\mathbb{R} f:Rn→R的输入是
一个 n n n维向量 x = [ x 1 , x 2 , … , x n ] ⊤ \mathbf{x}=[x_1,x_2,\ldots,x_n]^\top x=[x1,x2,…,xn]⊤,并且输出是一个标量。
函数 f ( x ) f(\mathbf{x}) f(x)相对于 x \mathbf{x} x的梯度是一个包含 n n n个偏导数的向量:
∇ x f ( x ) = [ ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , … , ∂ f ( x ) ∂ x n ] ⊤ , \nabla_{\mathbf{x}} f(\mathbf{x}) = \bigg[\frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \ldots, \frac{\partial f(\mathbf{x})}{\partial x_n}\bigg]^\top, ∇xf(x)=[∂x1∂f(x),∂x2∂f(x),…,∂xn∂f(x)]⊤,
其中 ∇ x f ( x ) \nabla_{\mathbf{x}} f(\mathbf{x}) ∇xf(x)通常在没有歧义时被 ∇ f ( x ) \nabla f(\mathbf{x}) ∇f(x)取代。
假设 x \mathbf{x} x为 n n n维向量,在微分多元函数时经常使用以下规则:
- 对于所有 A ∈ R m × n \mathbf{A} \in \mathbb{R}^{m \times n} A∈Rm×n,都有 ∇ x A x = A ⊤ \nabla_{\mathbf{x}} \mathbf{A} \mathbf{x} = \mathbf{A}^\top ∇xAx=A⊤
- 对于所有 A ∈ R n × m \mathbf{A} \in \mathbb{R}^{n \times m} A∈Rn×m,都有 ∇ x x ⊤ A = A \nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{A} = \mathbf{A} ∇xx⊤A=A
- 对于所有 A ∈ R n × n \mathbf{A} \in \mathbb{R}^{n \times n} A∈Rn×n,都有 ∇ x x ⊤ A x = ( A + A ⊤ ) x \nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{A} \mathbf{x} = (\mathbf{A} + \mathbf{A}^\top)\mathbf{x} ∇xx⊤Ax=(A+A⊤)x
- ∇ x ∥ x ∥ 2 = ∇ x x ⊤ x = 2 x \nabla_{\mathbf{x}} \|\mathbf{x} \|^2 = \nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{x} = 2\mathbf{x} ∇x∥x∥2=∇xx⊤x=2x
同样,对于任何矩阵 X \mathbf{X} X,都有 ∇ X ∥ X ∥ F 2 = 2 X \nabla_{\mathbf{X}} \|\mathbf{X} \|_F^2 = 2\mathbf{X} ∇X∥X∥F2=2X。
链式法则
链式法则可以被用来微分复合函数。
假设函数 y = f ( u ) y=f(u) y=f(u)和 u = g ( x ) u=g(x) u=g(x)都是可微的,根据链式法则:
d y d x = d y d u d u d x . \frac{dy}{dx} = \frac{dy}{du} \frac{du}{dx}. dxdy=dudydxdu.
现在考虑一个更一般的场景,即函数具有任意数量的变量的情况。
假设可微分函数 y y y有变量 u 1 , u 2 , … , u m u_1, u_2, \ldots, u_m u1,u2,…,um,其中每个可微分函数 u i u_i ui都有变量 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn。
注意, y y y是 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1,x2,…,xn的函数。
对于任意 i = 1 , 2 , … , n i = 1, 2, \ldots, n i=1,2,…,n,链式法则给出:
∂ y ∂ x i = ∂ y ∂ u 1 ∂ u 1 ∂ x i + ∂ y ∂ u 2 ∂ u 2 ∂ x i + ⋯ + ∂ y ∂ u m ∂ u m ∂ x i \frac{\partial y}{\partial x_i} = \frac{\partial y}{\partial u_1} \frac{\partial u_1}{\partial x_i} + \frac{\partial y}{\partial u_2} \frac{\partial u_2}{\partial x_i} + \cdots + \frac{\partial y}{\partial u_m} \frac{\partial u_m}{\partial x_i} ∂xi∂y=∂u1∂y∂xi∂u1+∂u2∂y∂xi∂u2+⋯+∂um∂y∂xi∂um
自动微分
深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导。
实际中,根据设计好的模型,系统会构建一个计算图(computational graph),
来跟踪计算是哪些数据通过哪些操作组合起来产生输出。
自动微分使系统能够随后反向传播梯度。
这里,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
例如对函数 y = 2 x T x y=2x^{T}x y=2xTx关于列向量 x x x求导
首先创建变量 x x x并为其分配一个初始值
import torch
x = torch.arange(4.0)
x
tensor([0., 1., 2., 3.])
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None
# 计算y
y = 2 * torch.dot(x, x)
y
tensor(28., grad_fn=)
通过调用反向传播函数来自动计算 y y y关于 x x x每个分量的梯度
y.backward()
x.grad
tensor([ 0., 4., 8., 12.])
验证梯度计算是否正确
x.grad == 4 * x
tensor([True, True, True, True])
计算 x x x的另一个函数
# 在默认情况下,PyTorch会累计梯度,需要清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
tensor([1., 1., 1., 1.])
非标量变量的反向传播
# 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
# 本例只想求偏导数的和,所以传递一个1的梯度是合适的
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
tensor([0., 2., 4., 6.])
分离计算
有时希望将某些计算移动到记录的计算图之外。例如,加入 y y y是作为 x x x的函数计算的,而 z z z则是作为 y y y和 x x x的函数计算的。此时想计算 z z z关于 x x x的梯度,但由于某种原因,希望将 y y y视为一个常熟,并且只考虑到 x x x在 y y y被计算之后发挥的作用。
这里可以分离 y y y来返回一个新变量 u u u,该变量与 y y y具有相同的值,但丢弃计算图中如何计算 y y y的任何信息,即梯度不会向后流经 u u u到 x x x。
因此,反向传播函数计算 z = u ∗ x z=u*x z=u∗x关于 x x x的偏导数,同时将 u u u作为常数处理,而不是 z = x ∗ x ∗ x z=x*x*x z=x∗x∗x关于 x x x的偏导数。
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
tensor([True, True, True, True])
由于记录了 y y y的计算结果,我们随后可以在 y y y上调用反向传播,得到 y = x ∗ x y=x*x y=x∗x关于 x x x的导数,即 2 ∗ x 2*x 2∗x
x.grad.zero_()
y.sum().backward()
x.grad == 2 * x
tensor([True, True, True, True])