SpringCloud全家桶主要组件及通信协议剖析
SpringCloud的组件剖析
- 1.SpringCloud基本概念
- 2.SpringCloud常用组件
-
- 2.1.Netflix Eureka
-
- Eureka的工作原理
- Eureka自我保护
- 使用IP进行注册
- 2.2.Netflix Ribbon\Feign : 客户端负载均衡
-
- Ribbon
- Feign
- 2.3.Netflix Hystrix :断路器
-
- 设计原则
- Hystrix的功能
-
- 资源隔离
- 服务熔断
- 降级机制
- 缓存
- Hystrix工作机制
- 2.4.Netflix Zuul : 服务网关
-
- Zuul工作角色
- 自定义zuul的Filter
-
- zuul的工作原理
- 实现自定义zuul的Filter
- 2.5.Spring Cloud Config :分布式配置
-
- 配置中心工作流程
- 2.6.Spring Cloud Bus : 消息总线
-
- 消息总线自动刷新
- 2.7.Spring Cloud sleuth :微服务链路追踪
-
- ZipKin工作架构
- 2.8.SpringCloud的版本
- 3.服务通信协议
-
- 3.1.RPC
- 3.2.Http
- 4.SpringCloud与Dubbo
-
- 4.1.Dubbo简介
- 4.2.SpringCloud与Dubbo的区别
1.SpringCloud基本概念
Spring cloud是一个基于Spring Boot实现的服务治理工具包,用于微服务架构中管理和协调服务的。Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。有了SpringCloud之后,让微服务架构的落地变得更简单。
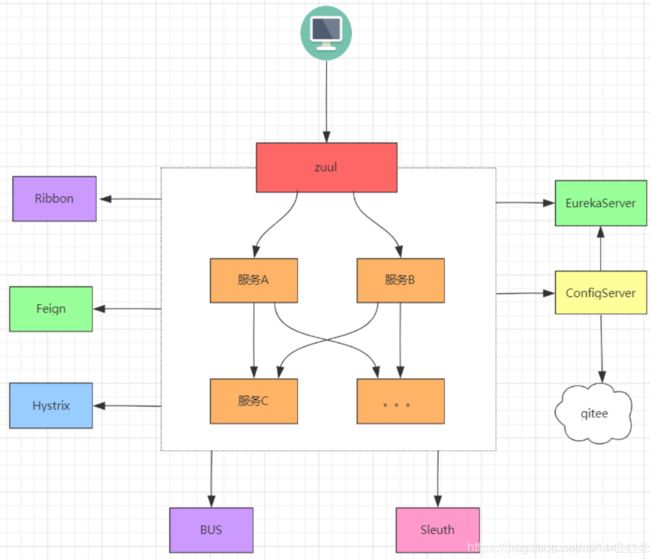
2.SpringCloud常用组件
当我们的项目采用微服务架构之后就会引发一些列的难题需要去解决,如众多微服务的通信地址应该如何管理,微服务之间应该使用何种方式发起调用,微服务故障该如何处理,众多微服务的配置文件如何集中管理等等,SpringCloud为这一系列的难题提供了相应的组件来解决,下面我们简单来理解一下SpringCloud最核心的几大组件如如下:
2.1.Netflix Eureka
当我们的微服务过多的时候,管理服务的通信地址是一个非常麻烦的事情,Eureka就是用来管理微服务的通信地址清单的,有了Eureka之后我们通过服务的名字就能实现服务的调用。
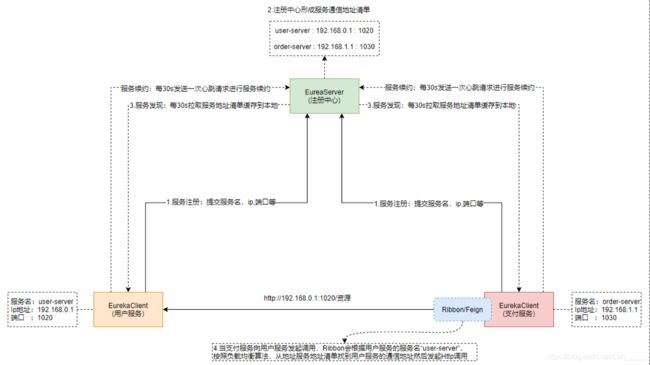
Eureka是一个服务注册与发现组件,简单说就是用来统一管理微服务的通信地址的组件,它包含了EurekaServer 服务端(也叫注册中心)和EurekaClient客户端两部分组成,EurekaServer是独立的服务,而EurekaClient需要集成到每个微服务中。
Eureka的工作原理
服务注册
微服务(EurekaClient)在启动的时候会向EurekaServer提交自己的服务信息(通信地址如:服务名,ip,端口等),在 EurekaServer会形成一个微服务的通信地址列表存储起来。 — 这叫服务注册
服务发现
微服务(EurekaClient)会定期(RegistryFetchIntervalSeconds:默认30s)的从EurekaServer拉取一份微服务通信地址列表缓存到本地。当一个微服务在向另一个微服务发起调用的时候会根据目标服务的服务名找到其通信地址,然后基于HTTP协议向目标服务发起请求。—这叫服务发现
服务续约
另外,微服务(EurekaClient)采用定时(LeaseRenewalIntervalInSeconds:默认30s)发送“心跳”请求向EurekaServer发请求进行服务续约,其实就是定时向 EurekaServer发请求报告自己的健康状况,告诉EurekaServer自己还活着,不要把自己从服务地址清单中剔除掉,那么当微服务(EurekaClient)宕机未向EurekaServer续约,或者续约请求超时(默认请求三次90s),注册中心就会从服务地址清单中剔除该续约失败的服务。
服务下线
微服务(EurekaClient)关闭服务前向注册中心发送下线请求,注册中心(EurekaServer)接受到下线请求负责将该服务实例从注册列表剔除
工作流程
Eureka自我保护
默认情况下,当EurekaServer接收到服务续约的心跳失败比例在15分钟之内低于85%,EurekaServer会把这些服务保护起来,即不会把该服务从服务注册地址清单中剔除掉,但是在此种情况下有可能会出现服务下线,那么消费者就会拿到一个无效的服务,请求会失败,那我们需要对消费者服务做一些重试,或在熔断策略。
当EurekaServer开启自我保护时,监控主界面会出现红色警告信息,我们可以使用eureka.server.enable-self-preservation=false来关闭EurekaServer的保护机制,这样可以确保注册中心中不可用的实例被及时的剔除,但是不推荐
使用IP进行注册
默认情况下EurekaClient使用hostname进行注册到EurekaServer,我们希望使用ip进行注册,可以通过配置eureka.instance.prefer-ip-address=true来指定,同时为了方便区分和管理服务实例,我们指定服务的实例ID,通过eureka.instance.instance-id为user-serer:1020来指定
2.2.Netflix Ribbon\Feign : 客户端负载均衡
Ribbon和Feign都是客户端负载均衡器,它的作用是在服务发生调用的时候帮我们将请求按照某种规则分发到多个目标服务器上,简单理解就是用来解决微服务之间的通信问题
Ribbon
Ribbon的使用相对比较简单,配合RestTemplate使用注解@LoadBalanced即可完成负载均衡配置,但是我们需要手动去拼接目标服务的URL,以及参数
Ribbon的工作机制
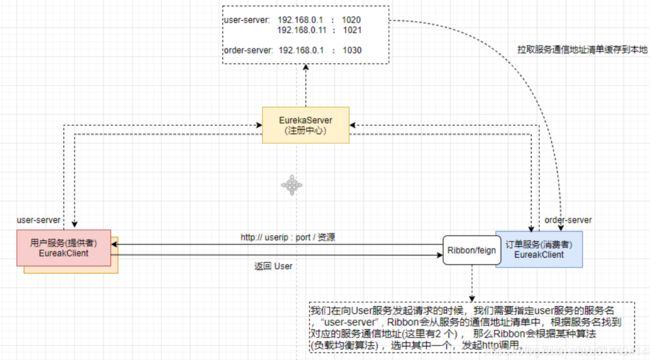
我们将user-server(用户服务)做集群处理,增加到2个节点(注意:两个user-server(用户服务)的服务名要一样,ip和端口不一样),在注册中心的服务通信地址清单中user-server(用户服务)这个服务下面会挂载两个通信地址 。 order-server(订单服务)会定时把服务通信地址清单拉取到本地进行缓存, 那么当order-server(订单服务)在向user-server(用户服务)发起调用时,需要指定服务名为 user-server(用户服务);那么这个时候,ribbon会根据user-server(用户服务)这个服务名找到两个order-server的通信地址 , 然后ribbon会按照负载均衡算法(默认轮询)选择其中的某一个通信地址,发起http请求实现服务的调用,如下图:
Ribbon内置算法

Ribbon调优配置
☆超时配置
使用Ribbon进行服务通信时为了防止网络波动造成服务调用超时,我们可以针对Ribbon配置超时时间以及重试机制
ribbon:
ReadTimeout: 3000 #读取超时时间
ConnectTimeout: 3000 #链接超时时间
MaxAutoRetries: 1 #重试机制:同一台实例最大重试次数
MaxAutoRetriesNextServer: 1 #重试负载均衡其他的实例最大重试次数
OkToRetryOnAllOperations: false #是否所有操作都重试,因为针对post请求如果没做幂等处理可能会造成数据多次添加/修改
☆饥饿加载
我们在启动服务使用Ribbon发起服务调用的时候往往会出现找不到目标服务的情况,这是因为Ribbon在进行客户端负载均衡的时候并不是启动时就创建好的,而是在实际请求的时候才会去创建,所以往往我们在发起第一次调用的时候会出现超时导致服务调用失败,我们可以通过设置Ribbon的饥饿加载来改善此情况,即在服务启动时就把Ribbon相关内容创建好。
ribbon:
eager-load:
enabled: true #开启饥饿加载
clients: user-server #针对于哪些服务需要饥饿加载
Feign
它基于Ribbon进行了封装,把一些负责的url和参数处理细节屏蔽起来,我们只需要简单编写Fiegn的客户端接口就可以像调用本地service去调用远程微服务。Feign整合了Ribbon和SpringMvc注解,这让Feign的客户端接口看起来就像一个Controller。Feign提供了HTTP请求的模板,通过编写简单的接口和插入注解,就可以定义好HTTP请求的参数、格式、地址等信息。而Feign则会完全代理HTTP请求,我们只需要像调用方法一样调用它就可以完成服务请求及相关处理。同时Feign整合了Hystrix,可以很容易的实现服务熔断和降级
Feign 的工作原理
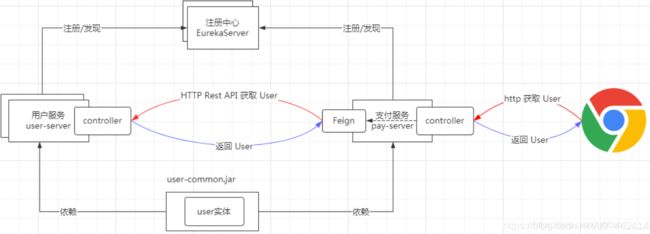
要使用Feign,我们除了导入依赖之外,需要主配置类通过@EnableFeignClients(value=“”)注解开启Feign,也可以通过value属性指定了Feign的扫描包。同时我们需要为Feign编写客户端接口,接口上需要注解@FeignClient标签。 当程序启动,注解了@FeignClient的接口将会被扫描到然后交给Spring管理。
当请求发起,会使用jdk的动态代理方式代理接口,生成相应的RequestTemplate,Feign会为每个方法生成一个RequestTemplate同时封装好http信息,如:url,请求参数等等
最终RequestTemplate生成request请求,交给Http客户端(UrlConnection ,HttpClient,OkHttp)。然后Http客户端会交给LoadBalancerClient,使用Ribbon的负载均衡发起调用
Feign 的工作机制
Feign的参数配置
☆负载均衡配置
Feign已经集成了Ribbon,所以它的负载均衡配置基于Ribbon配置即可,这里使用xml简单配置负载均衡策略如下
user-server:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
☆Feign的超时配置
ribbon:
ConnectTimeout: 3000
ReadTimeout: 6000
如果服务调用出现“com.netflix.hystrix.exception.HystrixRuntimeException:… timed - out and no fallback available” 错误日志,是因为Hystrix超时,默认Feign集成了Hystrix,但是高版本是关闭了Hystrix,我们可以配置Hystrix超时时间:
feign:
hystrix:
enabled: true #开启熔断支持
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 6000 #hystrix超时时间
Feign开启日志调试
☆配置Feign日志打印内容
有的时候我们需要看到Feign的调用过程中的参数及相应,我们可以对Feign的日志进行配置,Feign支持如下几种日志模式来决定日志记录内容多少:
· NONE,不记录(DEFAULT)
· 仅记录请求方法和URL以及响应状态代码和执行时间
· 记录基本信息以及请求和响应标头
· 记录请求和响应的标题,正文和元数据
☆创建Feign配置类
@Configuration
public class FeignConfiguration {
@Bean
Logger.Level feignLoggerLevel() {
return Logger.Level.FULL; //打印Feign的所有日志
}
}
☆配置日志打印级别
配置UserFeignClient的日志打印级别,上面的配置打印Feign的那些内容,下面这个是配置日志框架打印日志的级别,不修改可能打印不出来日志,DEBUG打印日志调试信息。
logging:
level:
cn.shixiong.springboot.feignclient.UserFeignClient: debug
2.3.Netflix Hystrix :断路器
Hystrix是处理依赖隔离的框架,将出现故障的服务通过熔断、降级等手段隔离开来,这样不影响整个系统的主业务,同时也是可以帮我们做服务的治理和监控。
设计原则
☆防止单个服务异常导致整个微服务故障
☆快速失败,如果服务出现故障,服务的请求快速失败,线程不会等待
☆服务降级,请求故障可以返回设定好的二手方案数据(兜底数据)
☆熔断机制,防止故障的扩散,导致整个服务瘫痪
☆服务监控,提供了Hystrix Bashboard仪表盘,实时监控熔断器状态
Hystrix的功能
资源隔离
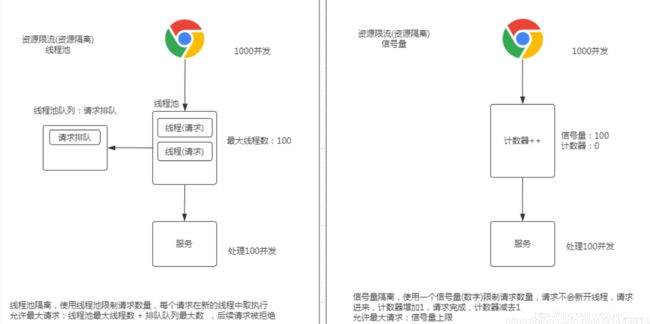
资源隔离包括线程池隔离和信号量隔离,作用是限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用 ,这里可以简单的理解为资源隔离就是限制请求的数量
☆线程池隔离
使用一个线程池来存储当前请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求先入线程池队列。这种方式要为每个依赖服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
☆信号量隔离
使用一个原子计数器(或信号量)记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃该类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
☆线程池和信号量对比

服务熔断
熔断机制是对服务链路的保护机制,如果链路上的某个服务不可访问,调用超时,发生异常等,服务会触发降级返回托底数据,然后熔断服务的调用(失败率达到某个阀值服务标记为短路状态),当检查到该节点能正常使用时服务会快速恢复。
简单理解就是当服务不可访问了或者服务器报错了或者服务调用超过一定时间没返回结果,就立马触发熔断机制配合降级返回预先准备的兜底数据返回,不至于长时间的等待服务的相应造成大量的请求阻塞,也不至于返回一些错误信息给客户端,而是返回一些兜底数据。
降级机制
超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。
简单理解就是服务降级就是当服务因为网络故障,服务器故障,读取超时等原因造成服务不可达的情况下返回一些预先准备好的数据给客户端。
缓存
提供了请求缓存、请求合并实现 , 在高并发的场景之下,Hystrix请求缓存可以方便地开启和使用请求缓存来优化系统,达到减轻高并发时请求线程的消耗、降低请求响应时间的效果。
Hystrix工作机制
正常情况下,断路器处于关闭状态(Closed),如果调用持续出错或者超时达到设定阈值,电路被打开进入熔断状态(Open),这时请求这个服务会触发快速失败(立马返回兜底数据不要让线程死等),后续一段时间内的所有调用都会被拒绝(Fail Fast),一段时间以后(withCircuitBreakerSleepWindowInMilliseconds=5s),保护器会尝试进入半熔断状态(Half-Open),允许少量请求进来尝试,如果调用仍然失败,则回到熔断状态,如果调用成功,则回到电路闭合状态
2.4.Netflix Zuul : 服务网关
Zuul 是netflix开源的一个API Gateway 服务器, 本质上是一个web servlet(filter)应用。Zuul 在云平台上提供动态路由(请求分发),监控,弹性,安全等边缘服务的框架。Zuul 相当于是设备和 Netflix 流应用的 Web 网站后端所有请求的前门,也要注册入Eureka,我们可以把zuul看做是微服务的大门,所有的请求都需要通过zuul将请求分发到其他微服务,根据这一特性我们就可以在zuul做统一的登录检查,下游的微服务不再处理登录检查逻辑。
Zuul工作角色
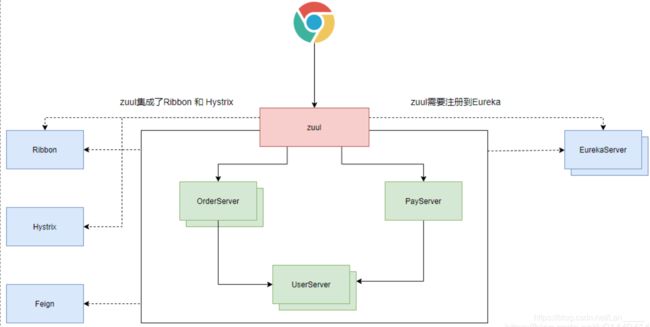
zuul本身是一个独立的服务,默认集成了Ribbon,zuul通过Ribbon将客户端的请求分发到下游的微服务,所以zuul需要通过Eureka做服务发行,同时zuul也集成了Hystrix。
我们需要建立独立的工程去搭建Zuul服务,同时需要把Zuul注册到EurekaServer,因为当请求过来时,zuul需要通过EurekaServer获取下游的微服务通信地址,使用Ribbon发起调用
自定义zuul的Filter
zuul的工作原理
zuul的底层是通过各种Filter来实现的,zuul中的filter按照执行顺序分为了“pre”前置(”custom”自定义一般是前置),“routing”路由,“post”后置,以及“error”异常Filter组成,当各种Filter出现了异常,请求会跳转到“error filter”,然后再经过“post filter” 最后返回结果,下面是Filter的执行流程图:
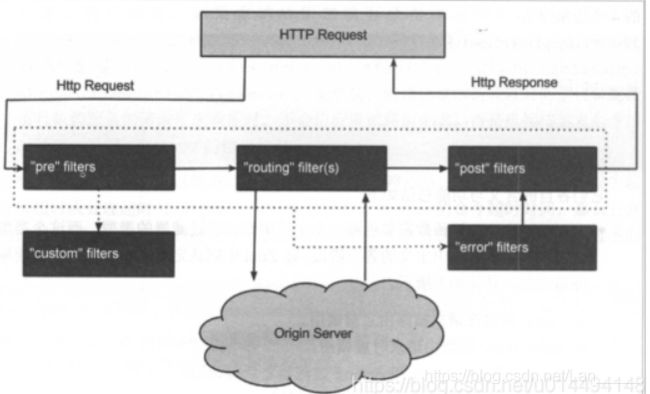
正常流程
请求到达首先会经过pre类型过滤器,而后到达routing类型,进行路由,请求就到达真正的服务提供者,执行请求,返回结果后,会到达post过滤器。而后返回响应
异常流程
☆整个过程中,pre或者routing过滤器出现异常,都会直接进入error过滤器,再error处理完毕后,会将请求交给POST过滤器,最后返回给用户
☆如果是error过滤器自己出现异常,最终也会进入POST过滤器,而后返回
☆如果是POST过滤器出现异常,会跳转到error过滤器,但是与pre和routing不同的时,请求不会再到达POST过滤器了
实现自定义zuul的Filter
Zuul提供了一个抽象的Filter:ZuulFilter我们可以通过该抽象类来自定义Filter,该Filter有四个核心方法,如下:
public abstract class ZuulFilter implements IZuulFilter{
abstract public String filterType();
abstract public int filterOrder();
//下面两个方法是 IZuulFilter 提供的
boolean shouldFilter();
Object run() throws ZuulException;
}
☆filterType :是用来指定filter的类型的(类型见常量类:FilterConstants),我们返回“pre”前置filter的常量,让他成为前置filter(登录检查需要在请求的最前面来做)
☆filterOrder :是filter的执行顺序,越小越先执行,返回的顺序值是 1
☆shouldFilter :是其父接口IZuulFilter的方法,通过判断请求的url来决定是否需要做登录检查,决定run方法是否要被执行,返回true就是要做,然后才会执行run方法
☆run :是其父接口IZuulFilter的方法,该方法是Filter的核心业务方法,通过获取请求头中的token判断是否登录,如果没登录就返回错误信息,阻止继续执行
☆RequestContext.getCurrentContext() 是一个Zuul提供的请求上下文对象
2.5.Spring Cloud Config :分布式配置
在分布式系统中,由于服务数量很多,为了方便服务配置文件统一管理我们需要用到置中心组件。在Spring Cloud中,分布式配置中心组件spring cloud config 它可以帮我们集中管理配置文件,修改配置无需重启服务 等,它支持配置文件放在配置服务的本地,也支持放在远程如Git仓库中集中管理。在spring cloud config 分为了服务端 config server和客户端config client 两个角色。
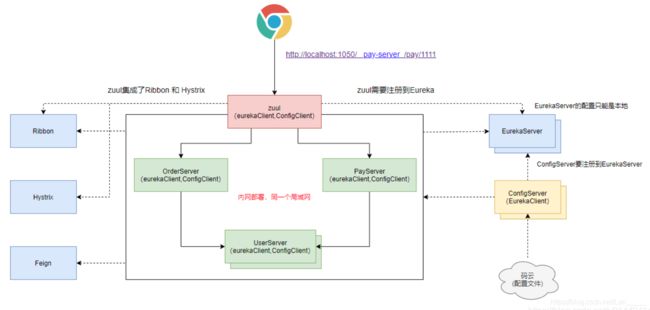
配置中心工作流程
微服务通过ConfigClient的bootstrap.yml配置文件,向配置中心ConfigServer发起请求获取配置文件,配置中心从GIT仓库获取配置,然后再一路返回给微服务
2.6.Spring Cloud Bus : 消息总线
在微服务架构中,为了更方便的向微服务实例广播消息,我们通常会构建一个消息中心,让所有的服务实例都连接上来,而该消息中心所发布的消息都会被微服务实例监听和消费,我们把这种机制叫做消息总线(SpringCloud Bus),在总线上的每个服务实例都可以去广播一些让其他服务知道的消息,消息总线可以为微服务做监控,或实现应用之间的通信,和其他的一些管理工作,目前提供了两种类型的消息队列中间件支持:RabbitMQ与Kafka
消息总线自动刷新
配置中心实现了配置的统一管理,但是如果有很多个微服务实例,当更改配置时,需要重启多个微服务实例,会非常麻烦。SpringCloud Bus 就能让这个过程变得非常简单,当我们Git仓库中的配置更改后,只需要某个微服务实例发送一个POST请求,通过消息组件通知其他微服务实例重新获取配置文件,以达到配置的自动刷新效果。实现原理如下:
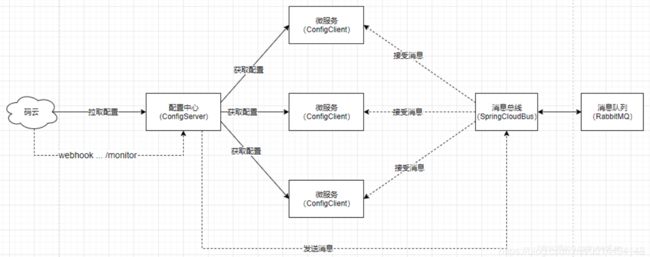
☆当Git仓库内容发生改变,webhook自动触发Post请求到 /monitor 地址,Spring Cloud Config Monitor的目的是提供了对Git webhook的支持
☆Spring Cloud Config配置中心需要集成 Monitor ,配置中心收到/monitor请求,触发配置刷新,向消息总线发送刷新消息
☆微服务(监听了消息总线的所有服务)监听消息总线,并从消息总线收到配置刷新消息
☆微服务收到消息知道了要刷新配置,请求配置中心重新获取配置文件
☆配置中心从码云重新拉取配置文件返回给微服务
2.7.Spring Cloud sleuth :微服务链路追踪
当我们的应用采用微服务架构之后,后台可能有几十个甚至几百个服务在支撑,一个请求请求可能需要多次的服务调用最后才能完成;当请求变慢或者不可用时,我们无法得知是哪个后台服务引起的,这时就需要解决如何快速定位服务故障点,并且服务之间的调用链关系,服务之间通信时间等等都需要去监控,Zipkin分布式跟踪系统就能很好的解决这样的问题,在SpringCloud中Spring Cloud Sleuth 组件基于Zipkin进行封装,让链路追踪实现起来更为简单
ZipKin工作架构
ZipKin可以分为两部分,一部分是zipkin server,用来作为数据的采集存储、数据分析与展示;第二部分是zipkin client,是基于不同的语言及框架封装的一些列客户端工具,这些工具完成了追踪数据的生成与上报功能,架构如下:
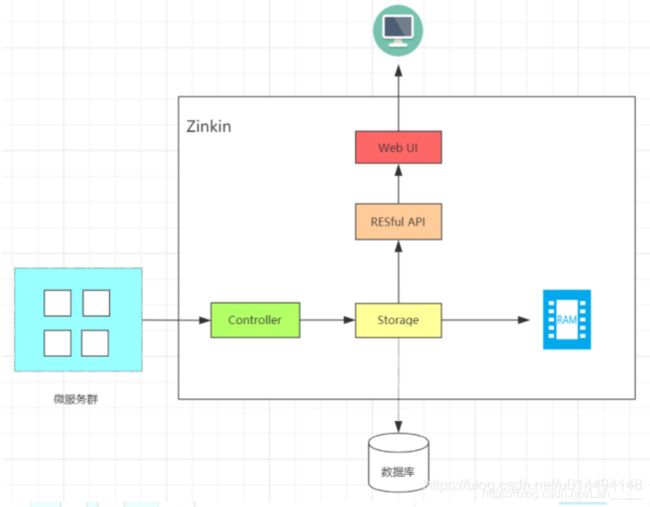
☆Collector:收集器组件,它主要用于处理从外部系统(要链路追踪的微服务)发送过来的跟踪信息,将这些信息转换为Zipkin内部处理的Span格式,以支持后续的存储、分析、展示等功能
☆Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中
☆RESTful API:API组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等
☆Web UI:UI组件,基于API组件实现的上层应用。通过UI组件用户可以方便而有直观地查询和分析跟踪信息
2.8.SpringCloud的版本
SpringCloud是基于SpringBoot的,所以两者的jar包都需要导入,需要注意的是SprinbCloud的版本需要和SpringBoot的版本兼容,下面是版本兼容图:

3.服务通信协议
3.1.RPC
RPC(Remote Produce Call)远程过程调用,类似的还有RMI。自定义数据格式,基于原生TCP通信,速度快,效率高。早期的webservice,现在热门的dubbo,都是RPC的典型
3.2.Http
Http其实是一种网络传输协议,基于TCP,规定了数据传输的格式。现在客户端浏览器与服务端通信基本都是采用Http协议。也可以用来进行远程服务调用。缺点是消息封装臃肿。 现在热门的Rest风格,就可以通过http协议来实现
我们可以认为SpringCloud就是基于Http协议实现服务之间的通信。在Java中发起一个Http请求的方式很多,比如 Apache的HttpClient , OKHttp等等 。Spring为我们封装了一个基于Restful的使用非常简单的Http客户端工具 RestTemplate

示例:
//订单服务
@RestController
public class OrderController {
//需要配置成Bean
@Autowired
private RestTemplate restTemplate ;
//浏览器调用该方法
@RequestMapping(value = "/order/{id}",method = RequestMethod.GET)
public User getById(@PathVariable("id")Long id){
//发送http请求调用 user的服务,获取user对象 : RestTemplate
//目标资源路径:user的ip,user的端口,user的Controller路径
String url = "http://localhost:1020/user/"+id;
//发送http请求
return restTemplate.getForObject(url, User.class);
}
}
4.SpringCloud与Dubbo
4.1.Dubbo简介
Dubbo最早是有阿里巴巴提供的一个服务治理和服务调用框架,现在已经成为Apache的顶级项目,Dubbo跟SpringCloud最显著的区别是Dubbo的定位只是一个RPC框架,相比SpringCloud来说它缺少很多功能模块,如:网关,链路追踪等,所以往往在使用Dubbo作为微服务开发框架的时候,还需要去配合其他的框架一起使用,如:加入zookeeper作为注册中心。
4.2.SpringCloud与Dubbo的区别
早期在国内做分布式(微服务)应用Dubbo是比较热门的框架,被许多互联网公司所采用,并产生了许多衍生版本,如网易,京东,新浪,当当等等,奈何在2014年10月Dubbo停止维护,在Dubbo停更的时间里Spring Cloud快速追赶上。在2017年9月,阿里宣布重启Dubbo项目,计划对Dubbo进行持续更新维护。2018.2月,阿里将Dubbo捐献给Apache基金会,Dubbo成为Apache孵化器项目。
所以当前微服务架构,Dubbo和SpringCloud比较火,另外还有Thrift、gRPC等等 。很多人把SpringCloud 和Dubbo进行对比,其实两个框架并没有太大的可比性,因为他们的定位不同。Spring Cloud是一个完整的微服务解决方案,它提供了微服务各问题的解决方案集合,而Dubbo是一个高性能的RPC框架,它有着很多功能的缺失。
定位不一样
SpringCloud为了微服务的落地提供了一套完整的组件,而Dubbo只是一个RPC框架,缺失的功能很多。
通信协议不一样
Dubbo的通信方式是RPC,基于原生的TCP协议,性能较好,而SpringCloud的通信方式基于Http协议,虽然底层基于tcp,但是Http的封装过于臃肿,但是使用Http好处在于互相通信的两个服务可以使用不同的变成语言去编写,只要他们都支持Http通信即可互相调用,而Dubbo只支持Java,当然Dubbo交给Apache维护之后做了升级,Dubbo在以后不仅仅支持Java。
背景都很强大
Dubbo背靠阿里和Apache,淘宝就是使用的Dubbo来开发经理过双“11”期间的高并发大流量检验,可以说是非常的稳定和成熟,SpringCloud是Spring家族的成员,严格遵循Martin Fowler提出的微服务规范,可以认为SpringCloud是微服务架构的标准,总之两者背景都很强大,文档完善,社区活跃,所以不管作何选择,都是很有前途的。
开发风格
从开发风格上来讲,Dubbo官方推荐倾向于使用Spring xml配置方式,SpringCloud是基于SpringBoot的开发风格,即采用注解的方式进行配置,从开发速度上来说,SpringCloud具有更高的开发和部署速度。
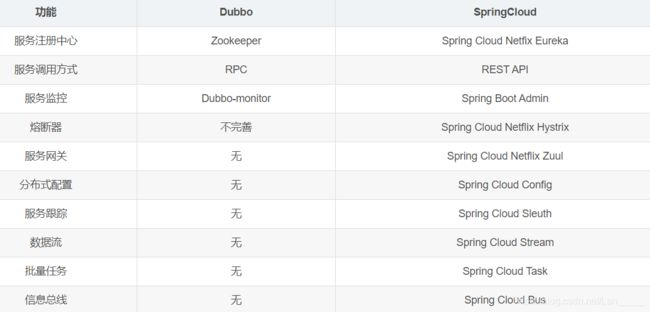
下面是网上比较流行的Dubbo和Spring Cloud功能对比图: