【LLM】chatglm3的agent应用和微调实践
note
- 知识库和微调并不是冲突的,它们是两种相辅相成的行业解决方案。开发者可以同时使用两种方案来优化模型。例如:
- 使用微调的技术微调ChatGLM3-6B大模型模拟客服的回答的语气和基础的客服思维。
- 接着,外挂知识库将最新的问答数据外挂给ChatGLM3-6B,不断更新客服回答的内容信息。
- chatglm3的对话格式中,
<|role|>部分使用 special token 表示,无法从文本形式被 tokenizer 编码以防止注入。metadata 部分采用纯文本表示,为可选内容。
关于glm3的微调:
- 与此前的做法不同,chatglm3-6b 推荐使用多轮对话格式进行微调
- 即将多个不同角色的对话内容直接拼接进行 teacher-forcing
- Special token 的加入使得多轮训练变得容易
- 不再特殊区别 prompt 和 response
- 需正确配置
loss_mask,即哪些 token 的预测需要模型学习 - loss_mask 的配置依据是推理时的行为
- 模型自己生成的 token 需要计算 loss
- 推理系统插入的 token 无需计算 loss
关于微调:
- 微调后模型的分布发生变化,通用能力和泛化性可能会减弱
- 加入通用数据(如 ShareGPT)进行混合训练可能缓解通用能力的衰减
- 若对 Base 模型进行微调,可自行设计生成格式,无需遵循前述格式
文章目录
- note
- 一、chatglm3-6b的agent应用
-
- 1. chatglm3的特点
- 2. ChatGLM3 对话格式
-
- (1)对话格式规定
-
- 整体结构
- 对话头
- (2)样例场景
-
- 多轮对话
- 工具调用
- 代码执行
- 二、微调chatglm3
-
- 1. 为什么需要微调
-
- 微调适用的场景
- 微调 VS 知识库
- 2. 如何微调
-
- 数据格式
- 3. 开始微调
-
- 快速微调
- 微调过程中
- 微调参数解释
- 训练的轮次
- 使用微调后的模型
- 三、glm3的更多介绍
- Reference
一、chatglm3-6b的agent应用
1. chatglm3的特点
特点:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 全新的 Agent 智能体能力:
ChatGLM3 本次集成了自研的 AgentTuning 技术,激活了模型智能体能力,尤其在智能规划和执行方面,相比于ChatGLM二代提升 1000% ;开启国产大模型原生支持工具调用、代码执行、游戏、数据库操作、知识图谱搜索与推理、操作系统等复杂场景。 - 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM-6B-Base、长文本对话模型 ChatGLM3-6B-32K。

2. ChatGLM3 对话格式
为了避免用户输入的注入攻击,以及统一 Code Interpreter,Tool & Agent 等任务的输入,ChatGLM3 采用了全新的对话格式。
(1)对话格式规定
整体结构
ChatGLM3 对话的格式由若干对话组成,其中每个对话包含对话头和内容,一个典型的多轮对话结构如下
<|system|>
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
<|user|>
Hello
<|assistant|>
Hello, I'm ChatGLM3. What can I assist you today?
对话头
对话头占完整的一行,格式为
<|role|>{metadata}
其中 <|role|> 部分使用 special token 表示,无法从文本形式被 tokenizer 编码以防止注入。metadata 部分采用纯文本表示,为可选内容。
<|system|>:系统信息,设计上可穿插于对话中,但目前规定仅可以出现在开头<|user|>:用户- 不会连续出现多个来自
<|user|>的信息
- 不会连续出现多个来自
<|assistant|>:AI 助手- 在出现之前必须有一个来自
<|user|>的信息
- 在出现之前必须有一个来自
<|observation|>:外部的返回结果- 必须在
<|assistant|>的信息之后
- 必须在
(2)样例场景
多轮对话
- 有且仅有
<|user|>、<|assistant|>、<|system|>三种 role
<|system|>
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
<|user|>
Hello
<|assistant|>
Hello, I'm ChatGLM3. What can I assist you today?
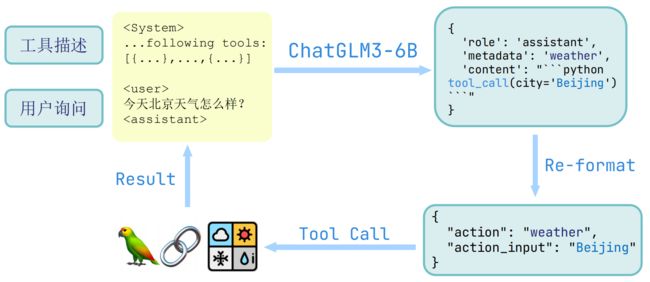
工具调用
- <|assistant|>{metadata}:
- 工具调用:{metadata} 为调用的工具名
- 例如 <|assistant|>test_tool 表示模型希望调用 test_tool 工具
<|system|>
Answer the following questions as best as you can. You have access to the following tools:
[
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string"},
},
"required": ["location"],
},
}
]
<|user|>
今天北京的天气怎么样?
<|assistant|>
好的,让我们来查看今天的天气
<|assistant|>get_current_weather
```python
tool_call(location="beijing", unit="celsius")
```
<|observation|>
{"temperature": 22}
<|assistant|>
根据查询结果,今天北京的气温为 22 摄氏度。
-
tool_registry 模式在 tool_registry.py 中定义工具

-
除了正常使用 <|assistant|> 进行对话外,模型在感到需要调用工具时会生成
<|assistant|>{metadata},其中 metadata 为调用的工具名 -
对话内容为 Python 代码,最终调用 tool_call 函数传参数
-
例如:(增加了额外换行以提升可读性)

-
工具调用结果通过 <|observation|> 返回给模型。例如:

-
模型调用工具时给出 <|observation|> 作为结束 token。因此,需要检查 <|user|> 与 <|observation|> 两种终止token 并作不同处理。如:


代码执行
- 有
<|user|>、<|assistant|>、<|system|>、<|observation|>四种 role。其中<|assistant|>的 metadata 只有 interpreter。
- Code Interpreter: 固定为 <|assistant|>interpreter
<|system|>
你是一位智能AI助手,你叫ChatGLM3,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
<|user|>
#File: /mnt/data/metadata.jsonl
#Size: 35380
#File uploaded
文件中是否存在缺失值或异常值?
<|assistant|>
首先,我将读取您提供的文件,并查看其内容以确定是否存在缺失值或异常值。
我们从加载文件开始:
<|assistant|>interpreter
```python
import json
# Load the uploaded file
data = []
with open("/mnt/data/metadata.jsonl", 'r') as file:
for line in file:
data.append(json.loads(line))
# Display the first few records to get a sense of the data
data[:5]
```
<|observation|>
```result
[{'file_name': 'aceinthehole.png',
'name': 'Ace in the Hole',
'type': 'survivor',
'description': 'Lady Luck always seems to be throwing something good your way.'},
{'file_name': 'adrenaline.png',
'name': 'Adrenaline',
'type': 'survivor',
'description': 'You are fuelled by unexpected energy when on the verge of escape.'},
{'file_name': 'aftercare.png',
'name': 'Aftercare',
'type': 'survivor',
'description': "Unlocks potential in one's aura reading ability."},
{'file_name': 'agitation.png',
'name': 'Agitation',
'type': 'killer',
'description': 'You get excited in anticipation of hooking your prey.'},
{'file_name': 'alert.png',
'name': 'Alert',
'type': 'survivor',
'description': 'Your acute senses are on high alert.'}]
```
<|assistant|>
该文件看起来包含有关某些条目的元数据,每个条目有以下字段:
- `file_name`: 文件名称
- `name`: 名称
- `type`: 类型(例如 "survivor" 或 "killer")
- `description`: 描述
接下来,我将检查这些字段是否存在缺失值。
<|assistant|>interpreter
```python
# Check for missing values in each column
missing_values = {key: sum(1 for item in data if key not in item) for key in data[0].keys()}
missing_values
```
<|observation|>
```result
{'file_name': 0, 'name': 0, 'type': 0, 'description': 0}
```
<|assistant|>
每个字段都没有缺失值。这意味着每个条目都完整。
接下来,我们可以检查是否存在任何潜在的异常值。这通常需要更深入的分析和对数据的了解,但我可以从一些基本的统计和分布开始进行检查。为了这样做,我们可以查看“type”字段的值分布,看看是否有任何意外的类别。
<|assistant|>interpreter
```python
# Check the distribution of values in the 'type' column
type_distribution = {key: sum(1 for item in data if item['type'] == key) for key in set(item['type'] for item in data)}
type_distribution
```
<|observation|>
```result
{'survivor': 116, 'killer': 103}
```
<|assistant|>
“type”字段有两个值:“survivor”和“killer”。其中,“survivor”有116个条目,而“killer”有103个条目。
从这个初步的检查中,我们没有发现任何明显的异常值。
如果您有任何特定的标准或其他字段需要检查,我可以为您提供更详细的分析。您还希望我检查什么呢?
<|user|>
帮我画一个爱心
<|assistant|>interpreter
```python
import numpy as np
import matplotlib.pyplot as plt
# 爱心形状的参数方程
def heart(t):
x = 16 * np.sin(t) ** 3
y = 13 * np.cos(t) - 5 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(4 * t)
return x, y
t = np.linspace(0, 2 * np.pi, 1000)
x, y = heart(t)
plt.figure(figsize=(6, 6))
plt.plot(x, y, color='red')
plt.axis('equal')
plt.axis('off')
plt.show()
```
<|observation|>
```result
【image】
```
<|assistant|>
这是一个爱心形状。我使用了参数方程来描述这个形状,并使用matplotlib进行了绘制。如果您有任何其他需求或问题,请随时告诉我。
<|user|> # End
二、微调chatglm3
关于glm3的微调:
- 与此前的做法不同,chatglm3-6b 推荐使用多轮对话格式进行微调
- 即将多个不同角色的对话内容直接拼接进行 teacher-forcing
- Special token 的加入使得多轮训练变得容易
- 不再特殊区别 prompt 和 response
- 需正确配置
loss_mask,即哪些 token 的预测需要模型学习 - loss_mask 的配置依据是推理时的行为
- 模型自己生成的 token 需要计算 loss
- 推理系统插入的 token 无需计算 loss
1. 为什么需要微调
微调适用的场景
通常来说,适合微调的场景主要分为行业场景和通用场景。对于行业场景:
- 例如客服助手,智能写作辅导等需要专门的回答范式和预期的场景
- 例如智慧医生,智慧律师等需要更专业的行业知识和思考能力的场景
对于通用场景: - NL2SQL等输出为指定范式的
- 支持可调整参数的工具调用等原生模型不具备的能力的
微调 VS 知识库
- 微调是一种让预先训练好的模型适应特定任务或数据集的低成本方案。这种情况下,模型会学习开发者提供的微调数据。
- 知识库是使用向量数据库(或者其他数据库)存储的数据局,可以外挂,作为LLM的行业信息提供方。微调相当于让大模型去学习了新的一门学科,在回答的时候完成闭卷考试。知识库相当于为大模型提供了新学科的课本,回答的时候为开卷考试。
- 知识库和微调并不是冲突的,它们是两种相辅相成的行业解决方案。开发者可以同时使用两种方案来优化模型。例如:
- 使用微调的技术微调ChatGLM3-6B大模型模拟客服的回答的语气和基础的客服思维。
- 接着,外挂知识库将最新的问答数据外挂给ChatGLM3-6B,不断更新客服回答的内容信息。
2. 如何微调
包括全量微调和 P-Tuning v2两种方案。
格式上,提供多轮对话微调样例和输入输出格式微调样例。
【环境和模型】
运行示例需要 python>=3.9,除基础的 torch 依赖外,示例代码运行还需要依赖。
pip install transformers==4.30.2 accelerate sentencepiece astunparse deepspeed
数据格式
多轮对话微调示例采用 ChatGLM3 对话格式约定,对不同角色添加不同 loss_mask 从而在一遍计算中为多轮回复计算 loss。

对于数据文件,样例采用如下格式
[
{
"tools": [
// available tools, format is not restricted
],
"conversations": [
{
"role": "system",
"content": ""
},
{
"role": "user",
"content": "" ,
},
{
"role": "assistant",
"content": ""
},
{
"role": "tool",
"name": ",
"parameters": {
"" : ""
},
"observation": "" // don't have to be string
}
]
}
// ...
]
- 关于工具描述的 system prompt 无需手动插入,预处理时会将 tools 字段使用
json.dumps(..., ensure_ascii=False)格式化后插入为首条 system prompt。 - 每种角色可以附带一个 bool 类型的 loss 字段,表示该字段所预测的内容是否参与 loss 计算。若没有该字段,样例实现中默认对 system, user 不计算 loss,其余角色则计算 loss。
- tool 并不是 ChatGLM3 中的原生角色,这里的 tool 在预处理阶段将被自动转化为一个具有工具调用 metadata 的 assistant 角色(默认计算 loss)和一个表示工具返回值的 observation 角色(不计算 loss)。
栗子如下:高亮部分为需要计算loss的token,<|assistant|> 后的内容和角色 token 都需要计算 loss。

3. 开始微调
快速微调
使用 ToolAlpaca 数据集来进行微调。首先,克隆 ToolAlpaca 数据集,并使用
./scripts/format_tool_alpaca.py --path "ToolAlpaca/data/train_data.json"
接着,仅需一键执行脚本,即可开始微调
./scripts/finetune_ds_multiturn.sh # 全量微调
./scripts/finetune_pt_multiturn.sh # P-Tuning v2 微调
微调过程中
- 微调代码在开始训练前,会先打印首条训练数据的预处理信息,显示为
Sanity Check >>>>>>>>>>>>>
'[gMASK]': 64790 -> -100
'sop': 64792 -> -100
'<|system|>': 64794 -> -100
'': 30910 -> -100
'\n': 13 -> -100
'Answer': 20115 -> -100
'the': 267 -> -100
'following': 1762 -> -100
...
'know': 683 -> -100
'the': 267 -> -100
'response': 3010 -> -100
'details': 3296 -> -100
'.': 30930 -> -100
'<|assistant|>': 64796 -> -100
'': 30910 -> 30910
'\n': 13 -> 13
'I': 307 -> 307
'need': 720 -> 720
'to': 289 -> 289
'use': 792 -> 792
...
<<<<<<<<<<<<< Sanity Check
字样,每行依次表示一个 detokenized string, token_id 和 target_id。可在日志中查看这部分的 loss_mask 是否符合预期。若不符合,可能需要调整代码或数据。
2. 参考显存用量
- P-Tuning V2 PRE_SEQ_LEN=128, DEV_BATCH_SIZE=1, GRAD_ACCUMULARION_STEPS=16, MAX_SEQ_LEN=2048 配置下约需要 21GB 显存。
- 全量微调时,./scripts/finetune_ds_multiturn.sh 中的配置(MAX_SEQ_LEN=2048, DEV_BATCH_SIZE=16, GRAD_ACCUMULARION_STEPS=1)恰好用满 4 * 80GB 显存。
- 若尝试后发现显存不足,可以考虑
- 尝试降低 DEV_BATCH_SIZE 并提升 GRAD_ACCUMULARION_STEPS
- 尝试添加 --quantization_bit 8 或 --quantization_bit 4。
- PRE_SEQ_LEN=128, DEV_BATCH_SIZE=1, GRAD_ACCUMULARION_STEPS=16, MAX_SEQ_LEN=1024 配置下,–quantization_bit 8 约需 12GB 显存,–quantization_bit 4 约需 7.6GB 显存。
微调参数解释
(1)针对fintune_demo/scripts中的参数进行解释:
finetune_ds.sh
使用deepspeed加速进行多卡的全参微调, 这些参数的意义如下:
- LR:这是学习率,表示在微调模型时参数更新的速度。一般较小的学习率会使训练过程更稳定,但可能需要更多的时间才能收敛。
- NUM_GPUS:使用的 GPU 数量。
- MAX_SOURCE_LEN 和 MAX_TARGET_LEN :这两个参数控制输入和输出序列的最大长度。
- DEV_BATCH_SIZE:这是开发集(验证集)的批次大小。在每个批次中,模型会同时处理多个样本。
- GRAD_ACCUMULARION_STEPS:梯度累计步数,表示模型在更新参数前要处理的批次数量,有助于在最小化 GPU 内存使用的同时,增大有效的批次大小。
- MAX_STEP:训练的最大步数。
- SAVE_INTERVAL:模型保存的间隔步数。
- RUN_NAME:用来给这次运行命名。
- BASE_MODEL_PATH:预训练模型的位置。
- DATASET_PATH:用来训练模型的数据集位置。
- OUTPUT_DIR:模型的输出目录和训练日志。
- MASTER_PORT:分布式训练的主节点端口。
(2)之后,使用torch来执行。
torchrun 是 PyTorch 的一个命令行工具,用于在多 GPU 或者多节点环境中启动分布式训练。–standalone、–nnodes和–nproc_per_node等参数都用于配置分布式训练。
(3)最后,finetune.py 是微调的主脚本,其使用了一些命令行参数(如 --train_format,–train_file,–model_name_or_path 等)来控制微调过程。这些参数的具体含义可能需要参考该脚本的源代码或者相关的文档。
finetune_pt.sh
使用 Pytorch 进行 P-Tuning 微调,其参数的设定与全参微调具有一定的区别。因此,参数的默认值也做了一定的调整:
- PRE_SEQ_LEN:这是新添加的一个参数,可能代表预处理序列的长度。具体的意义需要参考你的 finetune.py 训练脚本。
- LR:这是学习率。学习率控制了模型学习的速度。更高的学习率意味着模型的权重在优化过程中更新得更快。这个值从之前的 1e-4 提升到了 2e-2。
- NUM_GPUS:这是在训练过程中要使用的 GPU 的数量。这个值从之前的 4 降低到了 1,可能会对训练速度有所影响。
- MAX_SOURCE_LEN 和 MAX_TARGET_LEN:这两个参数分别定义了输入和输出序列的最大长度。
- DEV_BATCH_SIZE:这是每个批次的大小,即每个优化步骤使用的示例数量。从之前的 4 降低到 1,这会让模型在每一次更新时用到更少的样本。
- GRAD_ACCUMULARION_STEPS:这是在进行一次参数更新之前,梯度积累的步数。这个值从 1 增加到了 32,这意味着模型会在进行 32 次前向和后向传播后才进行一次参数更新。
- MAX_STEP:这是训练过程执行的最大步数,这个值从 500 增加到了 1000。
- SAVE_INTERVAL:这是每隔一定数量的步数保存模型的参数,这个值仍然是 500。
- RUN_NAME:这是运行的名称(advertise_gen_pt),用于标识和区分不同的训练运行。
- BASE_MODEL_PATH:这是预训练模型的路径,仍然是 THUDM/chatglm3-6b。
- DATASET_PATH:这是训练数据集的路径,仍然是 formatted_data/advertise_gen.jsonl。
- OUTPUT_DIR:这是保存模型输出以及训练日志的文件夹路径。
训练的轮次
- 推荐开发者按照以下表格,结合自己的数据量来设置轮次
| 数据量 | 轮次 |
|---|---|
| 100 | 15 |
| 1000 | 10 |
| 10000 | 2 |
使用微调后的模型
使用 ChatGLM3 的 Demo 就以部署微调后的模型 checkpoint。
对于全量微调,可以使用以下方式进行部署
cd ../composite_demo
MODEL_PATH="path to finetuned model checkpoint" TOKENIZER_PATH="THUDM/chatglm3-6b" streamlit run main.py
对于 P-Tuning v2 微调,可以使用以下方式进行部署
cd ../composite_demo
MODEL_PATH="THUDM/chatglm3-6b" PT_PATH="path to p-tuning checkpoint" streamlit run main.py
三、glm3的更多介绍
-
更强大的性能:今年以来,这是我们第三次对ChatGLM基座模型进行了深度优化。我们采用了独创的多阶段增强预训练方法,更丰富的训练数据和更优的训练方案,使训练更为充分。
评测显示,与 ChatGLM 二代模型相比,在44个中英文公开数据集测试中,ChatGLM3在国内同尺寸模型中排名首位。其中,MMLU提升36%、CEval提升33%、GSM8K提升179% 、BBH提升126%。 -
瞄向GPT-4V的技术升级:瞄向GPT-4V,ChatGLM3 本次实现了若干全新功能的迭代升级,包括:
多模态理解能力的CogVLM,看图识语义,在10余个国际标准图文评测数据集上取得SOTA;
代码增强模块 Code Interpreter 根据用户需求生成代码并执行,自动完成数据分析、文件处理等复杂任务;
网络搜索增强WebGLM,接入搜索增强,能自动根据问题在互联网上查找相关资料并在回答时提供参考相关文献或文章链接。
ChatGLM3的语义能力与逻辑能力大大增强。 -
全新的 Agent 智能体能力:
ChatGLM3 本次集成了自研的 AgentTuning 技术,激活了模型智能体能力,尤其在智能规划和执行方面,相比于ChatGLM二代提升 1000% ;开启国产大模型原生支持工具调用、代码执行、游戏、数据库操作、知识图谱搜索与推理、操作系统等复杂场景。 -
Edge端侧模型:
ChatGLM3 本次推出可手机部署的端测模型 ChatGLM3-1.5B 和 ChatGLM3-3B,支持包括Vivo、小米、三星在内的多种手机以及车载平台,甚至支持移动平台上 CPU 芯片的推理,速度可达20 tokens/s。精度方面 ChatGLM3-1.5B 和 ChatGLM3-3B 在公开 Benchmark 上与 ChatGLM2-6B 模型性能接近。 -
更高效推理/降本增效:
基于最新的高效动态推理和显存优化技术,我们当前的推理框架在相同硬件、模型条件下,相较于目前最佳的开源实现,包括伯克利大学推出的 vLLM 以及 Hugging Face TGI 的最新版本,推理速度提升了2-3倍,推理成本降低一倍,每千 tokens 仅0.5分,成本最低。
Reference
[1] chatglm3.0发布,对应的权重,部署代码管上:
模型:https://huggingface.co/THUDM/chatglm3-6b-base
模型:https://huggingface.co/THUDM/chatglm3-6b
[2] chatglm 32k版本:https://huggingface.co/THUDM/chatglm3-6b-32k
[3] 低成本部署:https://github.com/THUDM/ChatGLM3/blob/main/DEPLOYMENT.md
工具调用:https://github.com/THUDM/ChatGLM3/blob/main/tool_using/README.md
github:https://github.com/THUDM/ChatGLM3
[4] 智谱AI推出第三代基座大模型
[5] https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary
[6] LLaMA-Factory 实现了ChatGLM3-6B的微调,包括全参,Lora,P-tuning等方案。用户可以使用他们的微调方式。
在使用上述框架时,我们推荐将Lora模型合并到模型中,以方便Demo更好的读入微调后的模型。
[7] https://github.com/THUDM/ChatGLM3/tree/main/finetune_demo
[8] 使用docker运行chatglm3对外的http服务,使用python代码执行函数调用,查询北京天气