机器学习---贝叶斯网络与朴素贝叶斯
1. 贝叶斯法则
如何判定一个人是好人还是坏人?
当你无法准确的熟悉一个事物的本质时,你可以依靠与事物特定本质相关的事件出现的次数来判断
其本质属性的概率。如果你看到一个人总是做一些好事,那这个人就越可能是一个好人。
数学语言表达就是:支持某项属性的事件发生得越多,则该属性成立的可能性就越大。
贝叶斯法则来源于英国数学家贝叶斯(Thomas Bayes)在1763年发表的著作《论有关机遇问题
的求解》。
贝叶斯法则最初是一种用于概率论基础理论的归纳推理方法,但随后被一些统计学学者发展为一种
系统的统计推断方法,运用到统计决策、统计推断、统计估算等诸多领域。
贝叶斯公式:定义一:假定某个过程有若干可能的前提条件 ,则
,则 表示人们事先对
表示人们事先对
前提条件Xi出现的可能性大小的估计,即先验概率。
定义二:假定某个过程得到了结果A,则 表示在出现结果A的前提下,对前提条件Xi出现
表示在出现结果A的前提下,对前提条件Xi出现
的可能性大小的估计,即后验概率。

2. 贝叶斯法则算例
全垄断市场条件下,只有一家企业M提供产品和服务。企业K考虑是否进入该市场。同时,企
业M为阻止K进入该市场采取了相应的投资行为,而K能否进入该市场完全取决于M为阻止其进入所
花费的成本大小。假设K并不知道原垄断者M是属于高阻挠成本类型还是低阻挠成本类型,但能确
定,如果M属于高阻挠成本类型,K进入市场时M进行阻挠的概率是20%;如果M属于低阻挠成本
类型,K进入市场时M进行阻挠的概率是100%。现设K认为M属于高阻挠成本企业的概率为70%,
而在K进入市场后,M确实进行了商业阻挠。试以企业K角度,判断企业M为高阻挠成本类型概率。
利用贝叶斯公式建模:
前提条件:设M是高阻挠成本类型为X1,低阻挠成本类型为X2;
结果:M对K进行阻挠为A;
所求概率即为在已知结果 A的情况下,推断条件为X1的后验概率 ;
;
已知 为0.2,
为0.2,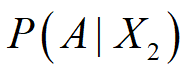 为1,P(X1)为0.7,P(X2)为0.3。
为1,P(X1)为0.7,P(X2)为0.3。
根据贝叶斯公式可计算:

即,根据实际市场的运作情况,企业K可判断企业M为高阻挠成本类型的概率为0.32,换句话说,
企业M更可能属于低阻挠成本类型。
3. 贝叶斯网络
贝叶斯网络又称为信度网络,是基于概率推理的图形化网络。它是贝叶斯法则的扩展,而贝叶斯公
式则是这个概率网络的基础。贝叶斯网络适用于表达和分析不确定性和概率性事件,应用于有条件
地依赖多种控制因素的决策过程,可以从不完全、不精确或不确定的知识或信息中做出推理。
贝叶斯网络由Judea Pearl于1988年提出,最初主要用于处理人工智能中的不确定信息。
符号B(D,G)表示一个贝叶斯网络,包括两个部分:
一个有向无环图(Directed Acyclic Graph, DAG)。它由代表变量的节点及连接这些节点的有向
边构成。其中,节点代表随机变量,可以是任何问题的抽象,如:测试值、观测现象、意见征询
等;节点间的有向边代表了节点间的互相关系(由父节点指向其后代节点)。

一个节点与节点之间的条件概率表(Conditional Probability Table, CPT)。如果节点没有任何
父节点,则该节点概率为先验概率。否则,该节点概率为其在父节点条件下的后验概率。
数学定义:贝叶斯网络B(D,P),D表示一个有向无环图,
是条件概率分布的集合,其中![]() 是D中节点Xi的父节点集合。在一个贝叶斯网络中,节点集合
是D中节点Xi的父节点集合。在一个贝叶斯网络中,节点集合
 ,则其联合概率分布P(X)是此贝叶斯网络中所有条件分布的乘积:
,则其联合概率分布P(X)是此贝叶斯网络中所有条件分布的乘积:
 。
。

这是一个最简单的包含3个节点的贝叶斯网络。其中, 是节点A的概率分布(先验概率)
是节点A的概率分布(先验概率)
 与
与 为节点B,C的概率分布(后验概率)。
为节点B,C的概率分布(后验概率)。
贝叶斯网络的特性:
贝叶斯网络本身是一种不定性因果关联模型,它将多元知识图解可视化,贴切的蕴含了网络节点变
量之间的因果关系及条件相关关系;
贝叶斯网络具有强大的不确定性问题的处理能力,它用条件概率表达各个信息要素之间的相关关
系,能在有限的、不完整的、不确定的信息条件下进行知识学习和推理;
贝叶斯网络能有效的进行多源信息表达与融合,可将故障诊断与维修决策相关的各种信息纳入到网
络结构中,并按节点的方式统一进行处理与信息融合。
贝叶斯网络的缺陷:
研究如何根据数据和专家知识高效、准确的建立贝叶斯网络,是十多年来研究的热点之一,也是贝
叶斯网络更加广泛、有效地用于实际问题领域的关键和焦点之一。
目前对于这一类学习问题,主要有基于打分—搜索的学习方法和基于依赖分析的学习方法,但前者
存在搜索空间巨大,可能收敛于局部最优解等问题,后者则存在节点之间的独立性或条件独立性判
断困难,高阶条件独立性检验的结果不够可靠等问题。
贝叶斯网络与马尔科夫链:
马尔科夫链蒙特卡罗(Markov Chain Monte Carlo,MCMC)方法是源于统计物理学和生物学的一
类重要的随机抽样方法,该方法广泛应用于机器学习、统计和决策分析等领域的高维问题的推理和
求积运算。
MHS(Metropolis-Hasting Sampler)抽样算法作为MCMC方法中常用的抽样方法之一,通过构建
一条马尔科夫链,模拟一个收敛于Boltzmann分布的系统。将MHS抽样算法引入贝叶斯网络,能够
较好的解决进化学习方法中由于个体趋同而产生的早熟问题,保证算法的学习精度。
此外,针对其计算精度低、收敛速度较慢的不足,随机拟MCMC方法也具有一定的优越性。
不过,该算法存在的收敛速度慢和收敛性判断困难等问题仍未能得到有效解决。因此,如何更有效
地将MCMC方法用于贝叶斯网络的结构学习与推理学习成为近年来重要的研究方向之一。
4. 朴素贝叶斯

贝叶斯分类器是用于分类的贝叶斯网络。该网络中通常包含类节点C,其取值来自类集合
 ;还包含一组节点
;还包含一组节点 ,表示用于进行分类的特征属性。对于贝叶斯网络分类器,若某一待分类的样本D,其分类特征值为
,表示用于进行分类的特征属性。对于贝叶斯网络分类器,若某一待分类的样本D,其分类特征值为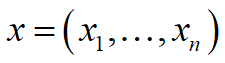 ,则样本D属于类别Ci的概
,则样本D属于类别Ci的概
率 , 应满足:![]() 。
。
由贝叶斯公式可以得到:

其中, 可由领域专家的经验获得,而
可由领域专家的经验获得,而 和
和 的计算较为困难。
的计算较为困难。
贝叶斯网络分类器进行分类的两个阶段:
阶段一:贝叶斯网络分类器的学习(结构学习和CPT学习)
阶段二:贝叶斯网络分类器的推理(计算类节点的条件概率,对数据进行分类)
两个阶段的时间复杂度均取决于特征值间的依赖程度。
5. 贝叶斯分类器
根据对特征值间不同关联程度的假设,可以得出各种贝叶斯分类器,其中较典型、研究较深入的贝
叶斯分类器主要有四种,分别是:
–NB( Naïve Bayes )–TAN( Tree Augmented Naïve-Bayes )
–BAN (BN Augmented Naïve-Bayes )–GBN(Global Bayesian Networks)
朴素贝叶斯(Naïve Bayes)算法是贝叶斯分类器中研究较多,使用较广的一种,在许多场合,朴
素贝叶斯的分类算法可以与决策树和神经网络分类算法相媲美。朴素贝叶斯分类器的基础:假设一
个指定类别中各个属性的取值是相互独立的,即在给定目标值的情况下,观察到联合的
 的概率正好是对每个单独属性的概率乘积。
的概率正好是对每个单独属性的概率乘积。

贝叶斯分类器: 
朴素贝叶斯简化: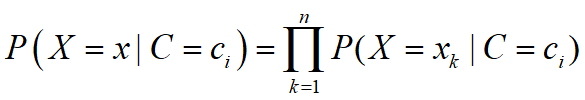
考虑到 是一个取max的过程,则
是一个取max的过程,则 对于结果不产生影响,故可以看作系数
对于结果不产生影响,故可以看作系数
a。则 ,原公式可以简化。
,原公式可以简化。
朴素贝叶斯分类器由Duda和Hart于1937年提出,它是一个简单有效而且在实际使用中比较成功的
分类器。现在,被广泛的运用在数据挖掘、模式识别、故障诊断等众多领域。
朴素贝叶斯算法有很多优点:
应用范围广泛;可以很好的扩展到超大规模问题,并且不需要通过搜索来寻找最大后验概率的朴素
贝叶斯假设;可以轻松地应付有噪声的训练数据,并在适当的时候给出概率预测。
朴素贝叶斯分类器假设一个指定类别中各属性的取值是相互独立的。这一假设可以帮助有效减少在
构造贝叶斯分类器时所需要进行的计算量。不过,实际的应用领域中,各个属性相互独立的假设很
难成立,这也从很大程度上影响了朴素贝叶斯分类器的分类能力。当前,半朴素贝叶斯分类器、相
关属性删除、概率值条件、贝叶斯树以及懒惰贝叶斯规则方法,都是对朴素贝叶斯算法的改进与推
广,并在不同的领域取得了显著的成果。
6. 系统控制的应用
在信息技术迅速发展及其在军事领域广泛应用的条件下,防空作战环境变得愈加复杂,也给现代防
空作战中的空情探测带来了严峻的挑战。由于受到自身性能、电子干扰等因素的影响,不同的空情
雷达对同一空中目标的探测的准确度不同,从而影响了防控侦察预警信息的准确性,应用贝叶斯网
络算法探讨计算不同雷达在探测同一目标的可信度,通过数据融合推断出空中目标的类型,是贝叶
斯网络算法在系统可靠性领域的重要应用之一。
例子:假设两个空情雷达探测同一目标,目标可能的类型:A.大型战机、B.小型机密集编队、C.
小型战机、D.巡航导弹。在时刻t,一号空情雷达报告的条件概率表如表所示。

根据战前分析,假定权威人员预测战场中在某个作战阶段各种空袭兵器运用的概率为:

那么在一号空情雷达报告信息中,报告目标类型大型战机、小型机密集编队、小型战机、巡航导弹
的概率分别为:P(A)、P(B)、P(C)、P(D)。

根据贝叶斯公式,则一号空情雷达报告目标类型为A的条件下,实际目标类型为A、B、C、D的条
件概率分别为:

![]() 表示传感器报告目标为类型A的条件下,实际目标为A的概率;
表示传感器报告目标为类型A的条件下,实际目标为A的概率; ![]() 表示实际目标类
表示实际目标类
型为A的条件下,传感器报告目标类型为A的概率;P(A)表示存在类型为A的目标的先验概率;
 表示所有传感器报告目标类型为A的概率之和,即
表示所有传感器报告目标类型为A的概率之和,即 。
。
同样可以计算出一号空情雷达报告类型分别为B、C、D的条件下,实际目标类型的条件概率,如下
表所示:

于是,一号空情雷达报告假设目标类型为A的可信度为:

同理可以得到第一号传感器报告假设目标类型为B、C、D的可信度,即 :

为了提高探测的准确性,一般要设置一个可信度阈值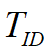 ,将计算出的可信度值与可信度阈值 比
,将计算出的可信度值与可信度阈值 比
较,看目标识别的可信度是否达到要求。假设 ,则以上的可信度值没有一个达到要求,因
,则以上的可信度值没有一个达到要求,因
此需要重新进行识别,将以上计算的可信度值作为下一次计算的先验概率。
现略去计算步骤,可得到基于两个传感器报告的目标类型为A、B、C、D的可信度为:
![]() 。同样假设
。同样假设 ,则可以知道B的可信度大
,则可以知道B的可信度大
于阈值,则可判定,空中目标类型为B。
7. 信息检索中的应用
贝叶斯网络检索模型可以计算术语与术语,术语与文档之间的条件概率。下图给出了一种贝叶斯网
络检索模型,利用同义词对查询术语进行扩展,用于信息检索领域。

假设有文档集合d表示为 ;这些文档的索引术语集合r表示为
;这些文档的索引术语集合r表示为![]() 。右图即为贝叶斯网络模型扩展的拓扑结构,其中Q被定义为查询术语节点,
。右图即为贝叶斯网络模型扩展的拓扑结构,其中Q被定义为查询术语节点,![]() 定义为文档节点,
定义为文档节点,![]() 定义为索引术语节点,
定义为索引术语节点,![]() 有一条指向被它索引的文档
有一条指向被它索引的文档![]() 的弧。
的弧。
用两个术语层来挖掘文档索引术语之间的关系,完全复制初始术语节点层r,得到另一个属于节点
层t。对于查询术语Q,在索引术语层t查找他的同义词![]() ,则从Q 到
,则从Q 到![]() 有一条弧;从
有一条弧;从 指向
指向
![]() 的弧,就是从
的弧,就是从 指向
指向![]() ,其中总有从
,其中总有从![]() 指向
指向![]() 的弧,
的弧, 是在一定衡量方法
是在一定衡量方法
下与![]() 最相关的术语集合。
最相关的术语集合。
在确定了贝叶斯网络模型之后,通过计算索引术语与术语之间、索引术语与文档之间的条件概率与
文档节点的后验概率,就能够获得全部文档节点的概率,并根据概率大小排序获得与查询节点最匹
配的检索结果。
考虑一种更简单的情况,即在查询节点和文档节点以外,只有一层术语节点的简单贝叶斯网络检索
模型,如下图所示。
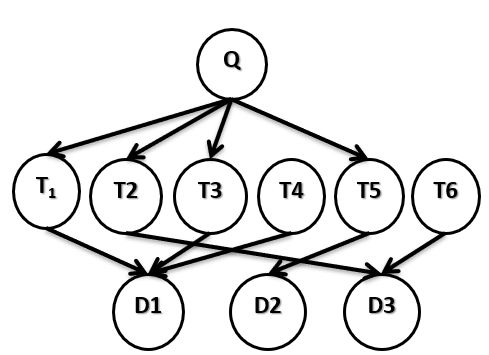
假设查询节点为Q,术语节点集合为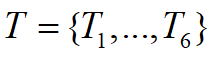 ,文档节点集合为
,文档节点集合为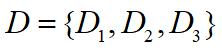 。根据图中
。根据图中
弧线所对应的关系,计算查询节点Q更接近于文档节点集合中的哪一个?
要求查询节点更接近哪一个文档节点,即分别求 ,选择其中概率值最大文档节点为所求。
,选择其中概率值最大文档节点为所求。
根据朴素贝叶斯算法的原则,所有术语节点相互独立。且由图可知,除去查询节点层,所有术语节
点均为根节点。所以定义每一个术语![]() 相关的先验概率
相关的先验概率 ,则不相关的概率
,则不相关的概率 ,
,
其中M为集合中术语的数目(本例中M=6)。一般情况下,任意根术语节点相关的先验概率很小,
且与索引术语节点集合的规模成反比。
对于文档节点可知,任意文档节点![]() 的父节点集合由该文档的所有索引术语节点组成,即
的父节点集合由该文档的所有索引术语节点组成,即
 。令
。令 为
为 中每个术语变量取值(相关或不相关)后的一个
中每个术语变量取值(相关或不相关)后的一个
组合,利用一般正则模型概率函数,定义文档![]() 相关的条件概率为
相关的条件概率为
其中,![]() 为文档
为文档 的索引术语
的索引术语 的权重,
的权重, ,且
,且 。这意味
。这意味
着 中相关术语越多,
中相关术语越多,  的相关概率值就越大。关于权重
的相关概率值就越大。关于权重![]() 的计算,给出相应数值如
的计算,给出相应数值如
下表:
| T1 |
T2 |
T3 |
T4 |
T5 |
T6 |
|
| D1 |
0.2 |
0.15 |
0.05 |
0.1 |
0.35 |
0.15 |
| D2 |
0.3 |
0.05 |
0.15 |
0.2 |
0.15 |
0.15 |
| D3 |
0.05 |
0.35 |
0.2 |
0.05 |
0.15 |
0.2 |
所以根据贝叶斯公式,可以得到下式:

由于术语节点相互独立,根据条件独立性得:如果 ,则
,则 。否则,
。否则,
 。那么,上式可化简为:
。那么,上式可化简为:

则,代入数值得:

同理: 

可见: ,即查询节点Q更接近文档节点 D3。
,即查询节点Q更接近文档节点 D3。