【理解ARM架构】 散列文件 | 重定位
作者:一只大喵咪1201
专栏:《理解ARM架构》
格言:你只管努力,剩下的交给时间!

目录
- 引出重定位
- 散列文件
- 可读可写数据段重定位
- 清除BSS段
- 代码段重定位
-
- 相对跳转
- 实现代码段重定位
- 纯C函数实现重定位
- 总结
书接上文中的:
问题:为什么每个函数中都得创建一个uart1结构体局部变量,而不是创建全局变量供这些函数使用呢?
引出重定位

继续看这张图,为什么只有被const修饰的ConstChar变量能正常输出,其他三个变量输出的就是乱码的呢?

如上图,本喵为了方便看汇编代码,将C代码只保留打印变量部分。
打印g_Char这个没有被const修饰的全局变量时,可以看到,使用汇编指令LDR r0,[pc,#80]从0x20000000地址处读取值,赋给寄存器R0。
打印g_ConstChar这个被const修饰的全局变量时,可以看到,使用汇编指令MOVVS r0,#0x42,直接将B的ASCII码值赋给了寄存器R0。
都是在R0拿到数值以后才调用putchar函数来输出R0中的值,这里R0是用来传参的。
但是此时g_Char全局变量所在地址0x20000000并没有值,因为整个代码中只有读取这个地址的指令,并没有给这个地址赋值的指令,所以CPU读取g_Char地址处读取到的就是乱码。
而g_ConstChar是直接拿到的立即数,这个立即数是存放在Flash中的,是在烧录的时候写入的。
加载地址和链接地址:
我们将程序写好编译链接完成以后,将其烧录到开发板中,此时程序保存在Flash中,而对应Flash中的地址被叫做加载地址。
而编译器在链接时,会给变量分配一个地址,这个地址叫做链接地址,对应于RAM中的地址。
加载地址可以理解为真实物理地址,而链接地址可以理解为虚拟地址,CPU在执行代码时,使用的是虚拟地址,也就是链接地址。

如上图,要想程序正常运行,就需要在执行mymain函数之前,将Flash中的A复制到RAM的数据段处,让CPU能在链接地址处找到相应的值。
- 保存在ROM上的全局变量的值,在使用前要复制到内存,这就是数据段重定位
- 把代码移动到其他位置,这就是代码重定位。
程序运行时,应该位于它的链接地址处,因为:
- 使用函数地址时用的是"函数的链接地址",所以代码段应该位于链接地址处
- 去访问全局变量、静态变量时,用的是"变量的链接地址",所以数据段应该位于链接地址处
但是: 程序一开始时可能并没有位于它的"链接地址":
- 比如对于STM32F103,程序被烧录器烧写在Flash上,这个地址称为"加载地址"
- 比如对于IMX6ULL/STM32MP157,片内ROM根据头部信息把程序读入内存,这个地址称为“加载地址”
当加载地址 != 链接地址时,就需要重定位。
谁来做重定位?
- 程序本身:它把自己复制到链接地址去
- 一开始,程序可能并不位于它的链接地址上,它自己都不在链接地址,为什么它可以执行重定位的操作?
- 因为重定位的代码是使用“位置无关码”写的。
- 什么叫位置无关码:这段代码扔在任何位置都可以运行,跟它所在的位置无关
- 怎么写出位置无关码:
- 跳转:使用相对跳转指令,不能使用绝对跳转指令。
- 只能使用branch指令(比如
BL mymain),不能给PC直接赋值,比如LDR pc, =mymain
- 只能使用branch指令(比如
- 不要访问全局变量、静态变量。
- 不使用字符串。
- 跳转:使用相对跳转指令,不能使用绝对跳转指令。
散列文件
怎么做重定位和清除BSS段?
- 核心操作:复制。
复制的三要素:源、目的、长度
- 怎么知道代码段/数据段保存在哪?(加载地址)
- 怎么知道代码段/数据段要被复制到哪?(链接地址)
- 怎么知道代码段/数据段的长度?
对于BSS段,怎么知道BSS段的地址范围:起始地址、长度?
这一切信息都在keil中使用散列文件(Scatter File)来描述。
顾名思义,散列就是分散排列的意思,在STM32F103这类资源紧缺的单片机芯片中:
- 代码段保存在Flash上,直接在Flash上运行(当然也可以重定位到内存里)
- 数据段保存在Flash上,使用前被复制到内存里
从Keil5的帮助中找到Arm® Compiler for Embedded Reference Guide.pdf文件,里面有散列文件的详细介绍,本喵这里大致讲解一下。

如上图,一个散列文件由一个或多个Load region(加载域)组成,加载域中含有一个或多个Execution region(可执行域),可执行域中含义一个或多个input section(输入段)。
-
加载域描述了Flash中一块区域的位置,包括该区域中有什么内容及位置(加载地址),而且还可以控制这些内容放置在哪里(加载地址)。
-
可执行域描述了RAM中程序运行时,该区域包含的内容(输入段),并且可以控制区域所在的位置(链接地址)。
-
输入部分描述了可执行域中包含哪些数据类型。
这样来看,对于不同域的作用还是一头雾水,下面直接看本喵写的代码中生成的散列文件。
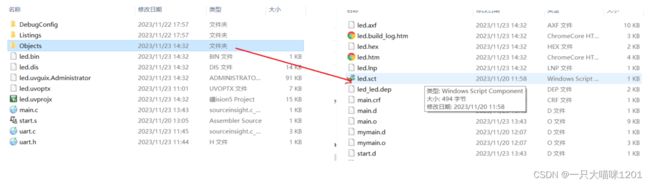
如上图所示,在当前工程文件中的Objects目录下,有一个后缀为.sct的文件,这个就是散列文件。

如上图就是散列文件里的内容,LR_IROM1是加载域的名称,0x08000000是加载域的加载地址,也就是Flash中代码存放的起始地址,后面是加载域的大小。
第一个可执行域:
加载域中有两个可执行域,ER_IROM1是第一个可执行域的名称,起始地址是0x08000000(链接地址),里面包含多个输入段信息,该地址和加载地址重合,所以这个可执行域不用重定位。
- *.o :所有objects文件,就是链接之前的二进制目标文件。
- *:所有objects文件和库,在一个散列文件中只能使用一个*。
- .ANY:等同于*,优先级比*低;在一个散列文件的多个可执行域中可以有多个
.ANY。
*.o (RESET, +First)表示将所有objects文件中的RESET域放在可执行的起始(+First)位置。

如上图所示启动文件中的汇编代码,其中 AREA RESET规定了绿色框中的汇编代码是RESET域,所以散列文件中第一个可执行域中首先放置绿色框中的代码。
- 板子一上电以后,就从
__Vectors处的DCD开始执行代码,这部分也恰好是该可执行域中RESET域的代码。- 然后才会调用跳转到
Rset_Handler处开始执行。
*(InRoot$$Sections)是如果我们写了main函数,编译器自己会执行的一套东西,这里本喵写的是mymain函数,为的就是避开这个东西,所以这里不用管它是什么。
.ANY (+RO)表示所有objects文件和库中的只读数据段放在这个可执行域中,挨着前面的输入段放置,和我们前面分析的一样,只读数据段并不需要重定位。
.ANY (+XO)并没有涉及到,也不用管它。
第二个可执行域:
RW_IRAM1是第二个可执行域的名称,起始地址是0x20000000(链接地址),位于RAM中,里面包含一个输入段信息,这个执行域需要进行重定位。
.ANY (+RW +ZI)表示所有objects文件和库中读写数据段和BSS或者ZI段,放在这个可执行域中。
- 可执行域的起始地址就是链接地址。
可以看到,不同数据段所处的位置是由散列文件通过可执行域中的输入段决定的,而且从散列文件中可以得到重定位需要的三要素源,目的,长度了。
可读可写数据段重定位
在调用mymain函数使用数据段前,将可读可写数据段的初始值从加载地址复制到链接地址。

如上图所示,定义一个复制函数mymemcpy,传入目的地址,起始地址,以及数据长度,将数据从起始地址复制到目的地址。
在启动文件的汇编代码中,在使用BL mymain之前,使用BL mymemcpy调用该函数实现数据段重定位。
我们知道,汇编代码调用C函数时,通过r0~r3寄存器来实现传参的,但是在调用时,我们怎么知道起始地址和目的地址以及长度呢?
不用去散列文件里查找具体的地址值,keil5的帮助手册中,提供了获取这几个参数的方式:

如上图所示是加载地址的符号,只需要将region_name替换成我们要操作的域即可,如Load$$RW_IRAM1$$Base表示的就是RW_IRAM1可执行域的加载地址,也就是我们需要的源地址。

如上图所示是获取可执行域的起始地址,同样进行部分替换即可得到目的地址(链接地址)。
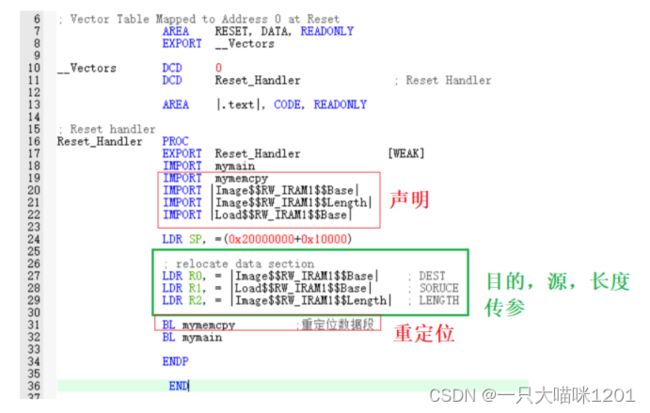
如上图,在启动文件的汇编代码中,声明拷贝函数,链接地址,数据个数,加载地址,然后将其赋值给R0~R2进行传参,再调用mymemcpy进行数据段的拷贝,最后再带调用mymain打印四个变量。

如上图,此时g_Char也成功的打印出了值,说明此时该地址并是乱码了,而是A的ASCII码,说明我们的数据段重定位成功了。
清除BSS段

如上图,初始值为0的全局变量g_A和无初始值的全局变量g_B也并不是乱码了,而且空,'0'输出的结果是空,说明此时这两个变量的链接地址处也有值。
奇怪了,我们只是进行了可读可写数据段的重定位,为什么BSS段也被清零了呢?这是因为编译器进行了优化,BSS段的数据只有两个,太少了,没有必要专门去清除BSS段,直接把它两归为可读可写数据段一并处理了。

如上图,将BSS段的这两个变量改成数组,此时编译器就不会优化了,可以看到,输出的数组第一个元素的值是乱码,说明BSS段地址处存放的就是乱码,需要我们进行清零操作。

如上图所示是获得BSS段(ZI段)的链接地址(基地址)、长度的符号,同样需要进行部分替换。

如上图,定义一个mymemset清除函数,传入目的地址,要设置的值,以及长度,就将这部分数据设置成对应的值。

如上图所示汇编代码,在红色框声明ZI段的起始地址以及长度,然后在蓝色框中使用R0~R2传参,给R1赋值0,再使用BL mymemset调用清除函数,将BSS段清零0。

如上图,此时打印出的就是空,说明BSS段存放的是0,也说明我们清除BSS段成功了。
代码段重定位

如上图,在默认散列文件中,代码段的load address = execution address,
也就是加载地址和执行地址(链接地址)一致,所以无需重定位。
有时候,我们需要把程序复制到内存里运行,比如:
- 想让程序执行得更快:需要把代码段复制到内存里。
- 程序很大,保存在片外SPI Flash中,SPI Flash上的代码无法直接执行,需要复制到内存里。
这时候,需要修改散列文件,把代码段的可执行域放在内存里,那么程序运行时,就需要尽快把代码段重定位到内存。

如上图,对我们的散列文件进行修改:
- 可执行域
ER_IROM1- 加载地址为0x08000000,可执行地址为0x20000000,两者不相等。
- 可执行域
RW_IRAM1,地址只有+0- 加载地址:紧跟着ER_IROM1的加载地址。
- 可执行地址:紧跟着ER_IROM1的可执行地址。
相对跳转
此时散列文件已经被修改了,让代码段的链接地址不等于加载地址,我们在启动文件中先不进行代码段重定位,直接让板子去执行:

如上图,这是编译后的反汇编文件,可以看到Reset_Handler的起始地址是0x20000008,说明代码段的起始地址就是这个,但是这是将散列文件中代码段可执行区域的链接地址改成0x20000000的结果。
说明Reset_Handler距离代码段起始地址的偏移量是8,那么我们将编译好的程序烧录到开发板中以后,它的加载地址是从0x08000000开始的,所以Reset_Handler的加载地址就是0x08000008。

如上图,在程序一上电开始执行__Vectors处的第二个DCD位置,将Reset_Handler改成0x08000009,让程序从加载地址开始执行。
- 为什么是
0x08000009而不是0x08000008呢?因为最低位bit0要为1,表示从这里开始使用的是Thumb指令集。
- 程序上电后,必须从加载地址开始执行,否则无法进行重定位等操作。
- 所以不能直接使用
Reset_Handler,因为它此时的链接地址是0x20000008。
然后其他代码不变,仍然使用BL mymain调用mymain函数,将程序烧录到开饭板中:

如上图,此时程序仍然可以正常运行。程序的链接地址不在散列文件中修改了吗?意味着mymain的链接地址也变了啊,此时RAM中并没有代码,为什么还能正常执行呢?
- 能正常调用
mymain的原因是使用了BL相对跳转指令。

如上图,代码被烧录到开发板中后位于Flash中,而此时程序又是从0x08000008处开始执行的,mymain函数距离这个位置的偏移量是固定的,所以使用BL相对跳转指令可以直接跳转到mymain函数中。
- 相对跳转指令只看当前位置和目标位置的偏移量。
而数据段和BSS段都已经处理好了,所以程序可以正常执行,只是在Flash中执行,和我们预期在RAM中执行不符。
实现代码段重定位

如上图所示,使用绝对跳转的方式去调用mymain函数,先获取mymain函数的地址到R0寄存器中,此时获取到的是链接地址,然后再使用BLX跳转到链接地址处。
- 使用
BLX中的X表示Thumb指令集。

如上图,此时就不会有任何现象了,因为mymain函数的链接地址处并没有代码。
所以此时就需要实现代码段的重定位了:
IMPORT |Image$$ER_IROM1$$Base|
IMPORT |Image$$ER_IROM1$$Length|
IMPORT |Load$$ER_IROM1$$Base|
同样使用这几个符号来确定代码段的加载地址和链接地址,此时要将名字都替换成ER_IROM1,表示这是代码段,而不是数据段RW_IRAM1。

如上图所示,在汇编代码中,声明代码段的源地址,目的地址,长度,然后使用R0~R2进行传参,然后也是调用mymemcpy,将Flash中的代码赋值到RAM中的链接地址处。

如上图,此时就可以正常执行了,可以输出对应的数据,说明代码段重定位成功了。
纯C函数实现重定位
在汇编中实现重定位需要使用寄存器来传参目的,源,长度三要素,有没有办法只调用一个C函数就能实现呢?有的。
使用C函数实现重定位的难点在于怎么得到各个域的加载地址(源)、链接地址(目的)、长度。
在C函数中可以直接使用汇编中表示地址的符号:
- 方法1:声明为外部变量,使用时需要使用取址符
extern int Image$$ER_IROM1$$Base;
extern int Load$$ER_IROM1$$Base;
extern int Image$$ER_IROM1$$Length;
mymemcpy(&Image$$ER_IROM1$$Base, &Image$$ER_IROM1$$Length, &Load$$ER_IROM1$$Base);
- 方法2:声明为外部数组,使用时不需要使用取址符
extern char Image$$ER_IROM1$$Base[];
extern char Load$$ER_IROM1$$Base[];
extern int Image$$ER_IROM1$$Length;
mymemcpy(Image$$ER_IROM1$$Base, Image$$ER_IROM1$$Length, &Load$$ER_IROM1$$Base);
为什么声明了就可以用了呢?
对于int g_A这样的变量,在编译的时候会生成一个符号表,里面包含变量名和变量地址,这个变量是我们定义的。
而表示加载地址,链接地址,长度的符号,是keil5的散列文件定义的变量,所以我们在使用前使用extern声明一下,在编译的时候就会和我们自己的变量共同组成符号表:
| Name | Address |
|---|---|
| g_a | xxxxxxxx |
| Image$$ER_IROM1$$Base | yyyyyyyy |
由于符号表中存放的是变量名和其地址,所以我们在访问自己定义的变量int g_A时,需要&g_A拿到它的地址,然后在解引用的时候,就访问到了内存中的值。
- 对于
extern int Image$$ER_IROM1$$Base变量,要得到符号表中的地址,也是使用&Image$$ER_IROM1$$Base。 - 对于
extern char Image$$ER_IROM1$$Base[]变量,要得到符号表中的地址,直接使用Image$$ER_IROM1$$Base,不需要加&。- 因为此时
mage\$\$ER_IROM1$$Base本身就表示地址。
- 因为此时

如上图所示,定义系统重定位函数SystemInit,在函数体内部使用extern声明我们所需要的加载地址,链接地址以及长度等要素变量。
在使用mymemcpy等函数进行重定位时,传参extern声明的这几个变量都需要取地址&。

如上图,也可以将这些变量声明为数组,数组名的本质就是一个地址,所以在调用mymemcpy等函数重定位时,传参时不需要取地址。

如上图,在汇编函数中,声明一下系统重定位函数,然后设置好栈,因为会用到栈,再调用SystemInit进行代码段,可读可写数据段的重定位和ZI段的清0。

如上图,此时仍然可以正常运行,说明纯C方式的重定位成功。
既然使用到的是extern变量的地址,那么直接声明成指针类型行不行呢?

如上图,直接使用extern声明为int*类型,经过本喵实验证明,在调用mymemcpy等函数时,直接传入声明的指针变量是不可以的,必须再对声明的指针取地址再传参。
因为这里使用的是这几个变量本身的值,如果声明为指针类型的话,它虽然是一个指针,但是它表示的地址数值却是我们需要的,如果直接对指针解引用访问到的并不是我们需要的这个值。
所以需要再对指针变量取地址,让其成为一个二级指针,此时解引用二级指针得到的一级指针的值才是我们需要的地址,才能直接使用。
总结
平时使用CubeMX或者直接移植固件库时,并不会注意到需要重定位,而实现重定位,在keil5中主要依赖散列文件,它描述了不同可执行域的加载地址和链接地址,给重定位提供了三要素。