Elasticsearch应用四:搜索详解(搜索API、Query DSL)
一、搜索API
1. 搜索API 端点地址
从索引tweet里面搜索字段user为kimchy的记录
GET /twitter/_search?q=user:kimchy从索引tweet,user里面搜索字段user为kimchy的记录
GET /twitter/tweet,user/_search?q=user:kimchy
GET /kimchy,elasticsearch/_search?q=tag:wow从所有索引里面搜索字段tag为wow的记录
GET /_all/_search?q=tag:wow
GET /_search?q=tag:wow说明:搜索的端点地址可以是多索引多mapping type的。搜索的参数可作为URI请求参数给出,也可用 request body 给出
2. URI Search
URI 搜索方式通过URI参数来指定查询相关参数。让我们可以快速做一个查询。
GET /twitter/_search?q=user:kimchy可用的参数请参考: https://www.elastic.co/guide/en/elasticsearch/reference/current/search-uri-request.html
3. 查询结果说明

5. 特殊的查询参数用法
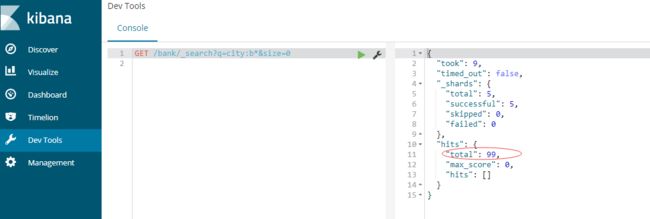
如果我们只想知道有多少文档匹配某个查询,可以这样用参数:
GET /bank/_search?q=city:b*&size=0
如果我们只想知道有没有文档匹配某个查询,可以这样用参数:
GET /bank/_search?q=city:b*&size=0&terminate_after=1 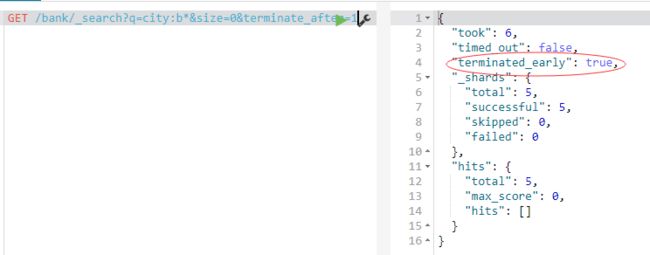
比较两个查询的结果可以知道第一个查询返回所有的命中文档数,第二个查询由于只需要知道有没有文档,所以只要有文档就立即返回
6. Request body Search
Request body 搜索方式以JSON格式在请求体中定义查询 query。请求方式可以是 GET 、POST 。
GET /twitter/_search
{
"query" : {
"term" : { "user" : "kimchy" }
}
}可用的参数:
timeout:请求超时时长,限定在指定时长内响应(即使没查完);
from: 分页的起始行,默认0;
size:分页大小;
request_cache:是否缓存请求结果,默认true。
terminate_after:限定每个分片取几个文档。如果设置,则响应将有一个布尔型字段terminated_early来指示查询执行是否实际已经terminate_early。缺省为no terminate_after;
search_type:查询的执行方式,可选值dfs_query_then_fetch or query_then_fetch ,默认: query_then_fetch ;
batched_reduce_size:一次在协调节点上应该减少的分片结果的数量。如果请求中的潜在分片数量可能很大,则应将此值用作保护机制以减少每个搜索请求的内存开销。
6.1 query 元素定义查询
query 元素用Query DSL 来定义查询。
GET /_search
{
"query" : {
"term" : { "user" : "kimchy" }
}
}6.2 指定返回哪些内容
6.2.1 source filter 对_source字段进行选择
GET /_search
{
"_source": false,
"query" : {
"term" : { "user" : "kimchy" }
}
}
通配符查询
GET /_search
{
"_source": [ "obj1.*", "obj2.*" ],
"query" : {
"term" : { "user" : "kimchy" }
}
}
GET /_search
{
"_source": "obj.*",
"query" : {
"term" : { "user" : "kimchy" }
}
}
包含什么不包含什么
GET /_search
{
"_source": {
"includes": [ "obj1.*", "obj2.*" ],
"excludes": [ "*.description" ]
},
"query" : {
"term" : { "user" : "kimchy" }
}
}
6.2.2 stored_fields 来指定返回哪些stored字段
GET /_search
{
"stored_fields" : ["user", "postDate"],
"query" : {
"term" : { "user" : "kimchy" }
}
}
说明:* 可用来指定返回所有存储字段
6.2.3 docValue Field 返回存储了docValue的字段值
GET /_search
{
"query" : {
"match_all": {}
},
"docvalue_fields" : ["test1", "test2"]
}
6.2.4 version 来指定返回文档的版本字段
GET /_search
{
"version": true,
"query" : {
"term" : { "user" : "kimchy" }
}
}
6.2.5 explain 返回文档的评分解释
GET /_search
{
"explain": true,
"query" : {
"term" : { "user" : "kimchy" }
}
}
6.2.6 Script Field 用脚本来对命中的每个文档的字段进行运算后返回
GET /bank/_search
{
"query": {
"match_all": {}
},
"script_fields": {
"test1": {
"script": {
"lang": "painless",
"source": "doc['balance'].value * 2"
}
},
"test2": {
"script": {
"lang": "painless",
"source": "doc['age'].value * params.factor",
"params": {
"factor": 2
}
}
} }}
搜索结果:
 View Code
View Code
GET /bank/_search
{
"query": {
"match_all": {}
},
"script_fields": {
"ffx": {
"script": {
"lang": "painless",
"source": "doc['age'].value * doc['balance'].value"
}
},
"balance*2": {
"script": {
"lang": "painless",
"source": "params['_source'].balance*2"
}
}
}
}
说明:
params _source 取 _source字段值
官方推荐使用doc,理由是用doc效率比取_source 高
搜索结果:
View Code
6.2.7 min_score 限制最低评分得分
GET /_search
{
"min_score": 0.5,
"query" : {
"term" : { "user" : "kimchy" }
}
}
6.2.8 post_filter 后置过滤:在查询命中文档、完成聚合后,再对命中的文档进行过滤。
如:要在一次查询中查询品牌为gucci且颜色为红色的shirts,同时还要得到gucci品牌各颜色的shirts的分面统计。
创建索引并指定mappping:
PUT /shirts
{
"mappings": {
"_doc": {
"properties": {
"brand": { "type": "keyword"},
"color": { "type": "keyword"},
"model": { "type": "keyword"}
}
}
}
}
往索引里面放入文档即类似数据库里面的向表插入一行数据,并立即刷新
PUT /shirts/_doc/1?refresh
{
"brand": "gucci",
"color": "red",
"model": "slim"
}
PUT /shirts/_doc/2?refresh
{
"brand": "gucci",
"color": "green",
"model": "seec"
}
执行查询:
GET /shirts/_search
{
"query": {
"bool": {
"filter": {
"term": { "brand": "gucci" }
}
}
},
"aggs": {
"colors": {
"terms": { "field": "color" }
}
},
"post_filter": {
"term": { "color": "red" }
}
}
查询结果
{
"took": 109,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0,
"hits": [
{
"_index": "shirts",
"_type": "_doc",
"_id": "1",
"_score": 0,
"_source": {
"brand": "gucci",
"color": "red",
"model": "slim"
}
}
]
},
"aggregations": {
"colors": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "green",
"doc_count": 1
},
{
"key": "red",
"doc_count": 1
}
]
}
}
}
6.2.9 sort 排序
可以指定按一个或多个字段排序。也可通过_score指定按评分值排序,_doc 按索引顺序排序。默认是按相关性评分从高到低排序。
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
} },
{
"balance": {
"order": "asc"
} },
"_score"
]
}
说明:
order 值:asc、desc。如果不给定,默认是asc,_score默认是desc
查询结果:
View Code
结果中每个文档会有排序字段值给出
"hits": {
"total": 1000,
"max_score": null,
"hits": [
{
"_index": "bank",
"_type": "_doc",
"_id": "549",
"_score": 1,
"_source": {
"account_number": 549,
"balance": 1932, "age": 40, "state": "OR"
},
"sort": [
40,
1932,
1
] }
多值字段排序
对于值是数组或多值的字段,也可进行排序,通过mode参数指定按多值的:

PUT /my_index/_doc/1?refresh
{
"product": "chocolate",
"price": [20, 4]
}
POST /_search
{
"query" : {
"term" : { "product" : "chocolate" }
},
"sort" : [
{"price" : {"order" : "asc", "mode" : "avg"}}
]
}
Missing values 缺失该字段的文档
missing 的值可以是 _last, _first
GET /_search
{
"sort" : [
{ "price" : {"missing" : "_last"} }
],
"query" : {
"term" : { "product" : "chocolate" }
}
}
地理空间距离排序
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-sort.html#geo-sorting
GET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : [-70, 40],
"order" : "asc",
"unit" : "km",
"mode" : "min",
"distance_type" : "arc"
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
参数说明:
_geo_distance 距离排序关键字
pin.location是 geo_point 类型的字段
distance_type:距离计算方式 arc球面 、plane 平面。
unit: 距离单位 km 、m 默认m
Script Based Sorting 基于脚本计算的排序
GET /_search
{
"query" : {
"term" : { "user" : "kimchy" }
},
"sort" : {
"_script" : {
"type" : "number",
"script" : {
"lang": "painless",
"source": "doc['field_name'].value * params.factor",
"params" : {
"factor" : 1.1
}
},
"order" : "asc"
}
}
}
6.3.0 折叠
用 collapse指定根据某个字段对命中结果进行折叠
GET /bank/_search
{
"query": {
"match_all": {}
},
"collapse" : {
"field" : "age"
},
"sort": ["balance"]
}
查询结果:
View Code
高级折叠
GET /bank/_search
{
"query": {
"match_all": {}
},
"collapse" : {
"field" : "age" ,
"inner_hits": {
"name": "details",
"size": 5,
"sort": [{ "balance": "asc" }]
},
"max_concurrent_group_searches": 4
},
"sort": ["balance"]
}
查询结果:
View Code
在inner_hits 中返回多个角度的组内topN
GET /twitter/_search
{
"query": {
"match": {
"message": "elasticsearch"
}
},
"collapse" : {
"field" : "user",
"inner_hits": [
{
"name": "most_liked",
"size": 3,
"sort": ["likes"]
},
{
"name": "most_recent",
"size": 3,
"sort": [{ "date": "asc" }]
}
]
},
"sort": ["likes"]
}
说明:
most_liked:最像
most_recent:最近一段时间的
6.3.1 分页
from and size
GET /_search
{
"from" : 0, "size" : 10,
"query" : {
"term" : { "user" : "kimchy" }
}
}
注意:搜索请求耗用的堆内存和时间与 from + size 大小成正比。分页越深耗用越大,为了不因分页导致OOM或严重影响性能,ES中规定from + size 不能大于索引setting参数 index.max_result_window 的值,默认值为 10,000。
需要深度分页, 不受index.max_result_window 限制,怎么办?
Search after 在指定文档后取文档, 可用于深度分页
首次查询第一页
GET twitter/_search
{
"size": 10,
"query": {
"match" : {
"title" : "elasticsearch"
}
},
"sort": [
{"date": "asc"},
{"_id": "desc"}
]
}
后续页的查询
GET twitter/_search
{
"size": 10,
"query": {
"match" : {
"title" : "elasticsearch"
}
},
"search_after": [1463538857, "654323"],
"sort": [
{"date": "asc"},
{"_id": "desc"}
]
}
注意:使用search_after,要求查询必须指定排序,并且这个排序组合值每个文档唯一(最好排序中包含_id字段)。 search_after的值用的就是这个排序值。 用search_after时 from 只能为0、-1。
6.3.2 高亮
准备数据:
PUT /hl_test/_doc/1
{
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}查询高亮数据
GET /hl_test/_search
{
"query": {
"match": {
"title": "lucene"
}
},
"highlight": {
"fields": {
"title": {},
"content": {}
}
}
}
查询结果:
{
"took": 113,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "hl_test",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
},
"highlight": {
"title": [
"lucene solr and elasticsearch"
]
}
}
]
}
}
多字段高亮
GET /hl_test/_search
{
"query": {
"match": {
"title": "lucene"
}
},
"highlight": {
"require_field_match": false,
"fields": {
"title": {},
"content": {}
}
}
}
查询结果:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "hl_test",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
},
"highlight": {
"title": [
"lucene solr and elasticsearch"
],
"content": [
"lucene solr and elasticsearch for search"
]
}
}
]
}
}
说明:
高亮结果在返回的每个文档中以hightlight节点给出
指定高亮标签
GET /hl_test/_search
{
"query": {
"match": {
"title": "lucene"
}
},
"highlight": {
"require_field_match": false,
"fields": {
"title": {
"pre_tags":[""],
"post_tags": [""]
},
"content": {}
}
}
}
查询结果:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "hl_test",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
},
"highlight": {
"title": [
"lucene solr and elasticsearch"
],
"content": [
"lucene solr and elasticsearch for search"
]
}
}
]
}
}
高亮的详细设置请参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-highlighting.html
6.3.3 Profile 为了调试、优化
对于执行缓慢的查询,我们很想知道它为什么慢,时间都耗在哪了,可以在查询上加入上 profile 来获得详细的执行步骤、耗时信息。
GET /twitter/_search
{
"profile": true,
"query" : {
"match" : { "message" : "some number" }
}
}
信息的说明请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-profile.html
7. count api 查询数量
PUT /twitter/_doc/1?refresh
{
"user": "kimchy"
}
GET /twitter/_doc/_count?q=user:kimchy
GET /twitter/_doc/_count
{
"query" : {
"term" : { "user" : "kimchy" }
}
}
结果说明:
{
"count" : 1,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
}
}
8. validate api
用来检查我们的查询是否正确,以及查看底层生成查询是怎样的
GET twitter/_validate/query?q=user:foo8.1 校验查询
GET twitter/_doc/_validate/query
{
"query": {
"query_string": {
"query": "post_date:foo",
"lenient": false
}
}
}
查询结果:
{
"valid": true,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
}
}
8.2 获得查询解释
GET twitter/_doc/_validate/query?explain=true
{
"query": {
"query_string": {
"query": "post_date:foo",
"lenient": false
}
}
}
查询结果
{
"valid": true,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"explanations": [
{
"index": "twitter",
"valid": true,
"explanation": """+MatchNoDocsQuery("unmapped field [post_date]") #MatchNoDocsQuery("Type list does not contain the index type")"""
}
]
}
8.3 用rewrite获得比explain 更详细的解释
GET twitter/_doc/_validate/query?rewrite=true
{
"query": {
"more_like_this": {
"like": {
"_id": "2"
},
"boost_terms": 1
}
}
}
查询结果:
{
"valid": true,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"explanations": [
{
"index": "twitter",
"valid": true,
"explanation": """+(MatchNoDocsQuery("empty BooleanQuery") -ConstantScore(MatchNoDocsQuery("empty BooleanQuery"))) #MatchNoDocsQuery("Type list does not contain the index type")"""
}
]
}
8.4 获得所有分片上的查询解释
GET twitter/_doc/_validate/query?rewrite=true&all_shards=true
{
"query": {
"match": {
"user": {
"query": "kimchy",
"fuzziness": "auto"
}
}
}
}
查询结果:
{
"valid": true,
"_shards": {
"total": 3,
"successful": 3,
"failed": 0
},
"explanations": [
{
"index": "twitter",
"shard": 0,
"valid": true,
"explanation": """MatchNoDocsQuery("unmapped field [user]")"""
},
{
"index": "twitter",
"shard": 1,
"valid": true,
"explanation": """MatchNoDocsQuery("unmapped field [user]")"""
},
{
"index": "twitter",
"shard": 2,
"valid": true,
"explanation": """MatchNoDocsQuery("unmapped field [user]")"""
}
]
}
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-validate.html
9. Explain api
获得某个查询的评分解释,及某个文档是否被这个查询命中
GET /twitter/_doc/0/_explain
{
"query" : {
"match" : { "message" : "elasticsearch" }
}
}官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-explain.html
10. Search Shards API
让我们可以了解可执行查询的索引分片节点情况
GET /twitter/_search_shards查询结果:
View Code
想知道指定routing值的查询将在哪些分片节点上执行
GET /twitter/_search_shards?routing=foo,baz查询结果:
{
"nodes": {
"qkmtovyLRPWjXcfDTryNwA": {
"name": "qkmtovy",
"ephemeral_id": "sxgsvzsORraAnN7PIlMYpg",
"transport_address": "127.0.0.1:9300",
"attributes": {}
}
},
"indices": {
"twitter": {}
},
"shards": [
[
{
"state": "STARTED",
"primary": true,
"node": "qkmtovyLRPWjXcfDTryNwA",
"relocating_node": null,
"shard": 1,
"index": "twitter",
"allocation_id": {
"id": "8S88pnUkSSy8kiCcwBgb9Q"
}
}
]
]
}
11. Search Template 查询模板
注册一个模板
POST _scripts/
{
"script": {
"lang": "mustache",
"source": {
"query": {
"match": {
"title": "{{query_string}}"
}
}
}
}
}
使用模板进行查询
GET _search/template
{
"id": "",
"params": {
"query_string": "search for these words"
}
}
查询结果:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 38,
"successful": 38,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
详细了解请参考官网:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-template.html
二、Query DSL
官网介绍链接:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
Query DSL 介绍
1. DSL是什么?
Domain Specific Language:领域特定语言
Elasticsearch基于JSON提供完整的查询DSL来定义查询。
一个查询可由两部分字句构成:
Leaf query clauses 叶子查询字句
Leaf query clauses 在指定的字段上查询指定的值, 如:match, term or range queries. 叶子字句可以单独使用.
Compound query clauses 复合查询字句
以逻辑方式组合多个叶子、复合查询为一个查询
2. Query and filter context
一个查询字句的行为取决于它是用在query context 还是 filter context 中 。
Query context 查询上下文
用在查询上下文中的字句回答“这个文档有多匹配这个查询?”。除了决定文档是否匹配,字句匹配的文档还会计算一个字句评分,来评定文档有多匹配。查询上下文由 query 元素表示。
Filter context 过滤上下文
过滤上下文由 filter 元素或 bool 中的 must not 表示。用在过滤上下文中的字句回答“这个文档是否匹配这个查询?”,不参与相关性评分。
被频繁使用的过滤器将被ES自动缓存,来提高查询性能。
示例:
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
说明:查询和过滤都是对所有文档进行查询,最后两个结果取交集
提示:在查询上下文中使用查询子句来表示影响匹配文档得分的条件,并在过滤上下文中使用所有其他查询子句。
查询分类介绍

1. Match all query 查询所有
GET /_search
{
"query": {
"match_all": {}
}
}相反,什么都不查
GET /_search
{
"query": {
"match_none": {}
}
}2. Full text querys
全文查询,用于对分词的字段进行搜索。会用查询字段的分词器对查询的文本进行分词生成查询。可用于短语查询、模糊查询、前缀查询、临近查询等查询场景
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html
3. match query
全文查询的标准查询,它可以对一个字段进行模糊、短语查询。 match queries 接收 text/numerics/dates, 对它们进行分词分析, 再组织成一个boolean查询。可通过operator 指定bool组合操作(or、and 默认是 or ), 以及minimum_should_match 指定至少需多少个should(or)字句需满足。还可用ananlyzer指定查询用的特殊分析器。
GET /_search
{
"query": {
"match" : {
"message" : "this is a test"
}
}
}
说明:message是字段名
官网链接:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query.html
示例:
构造索引和数据:
PUT /ftq/_doc/1
{
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
PUT /ftq/_doc/2
{
"title": "java spring boot",
"content": "lucene is writerd by java"
}
执行查询1
GET ftq/_doc/_validate/query?rewrite=true
{
"query": {
"match": {
"title": "lucene java"
}
}
}
查询结果1:
{
"valid": true,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"explanations": [
{
"index": "ftq",
"valid": true,
"explanation": "title:lucene title:java"
}
]
}
执行查询2:
GET ftq/_search
{
"query": {
"match": {
"title": "lucene java"
}
}
}
查询结果2:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.2876821,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "2",
"_score": 0.2876821,
"_source": {
"title": "java spring boot",
"content": "lucene is writerd by java"
}
},
{
"_index": "ftq",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
}
]
}
}
执行查询3:指定操作符
GET ftq/_search
{
"query": {
"match": {
"title": {
"query": "lucene java",
"operator": "and"
}
}
}
}
查询结果3:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
模糊查询,最大编辑数为2
GET ftq/_search
{
"query": {
"match": {
"title": {
"query": "ucen elatic",
"fuzziness": 2
}
}
}
}
模糊查询结果:
{
"took": 280,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.14384104,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "1",
"_score": 0.14384104,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
}
]
}
}
指定最少需满足两个词匹配
GET ftq/_search
{
"query": {
"match": {
"content": {
"query": "ucen elatic java",
"fuzziness": 2,
"minimum_should_match": 2
}
}
}
}
查询结果:
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.43152314,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "2",
"_score": 0.43152314,
"_source": {
"title": "java spring boot",
"content": "lucene is writerd by java"
}
}
]
}
}
可用max_expansions 指定模糊匹配的最大词项数,默认是50。比如:反向索引中有 100 个词项与 ucen 模糊匹配,只选用前50 个。
4. match phrase query
match_phrase 查询用来对一个字段进行短语查询,可以指定 analyzer、slop移动因子。
对字段进行短语查询1:
GET ftq/_search
{
"query": {
"match_phrase": {
"title": "lucene solr"
}
}
}
结果1:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "1",
"_score": 0.5753642,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
}
]
}
}
对字段进行短语查询2:
GET ftq/_search
{
"query": {
"match_phrase": {
"title": "lucene elasticsearch"
}
}
}
结果2:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
对查询指定移动因子:
GET ftq/_search
{
"query": {
"match_phrase": {
"title": {
"query": "lucene elasticsearch",
"slop": 2
}
}
}
}
查询结果:
{
"took": 2174,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.27517417,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "1",
"_score": 0.27517417,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
}
]
}
}
5. match phrase prefix query
match_phrase_prefix 在 match_phrase 的基础上支持对短语的最后一个词进行前缀匹配
GET /_search
{
"query": {
"match_phrase_prefix" : {
"message" : "quick brown f"
}
}
}
指定前缀匹配选用的最大词项数量
GET /_search
{
"query": {
"match_phrase_prefix" : {
"message" : {
"query" : "quick brown f",
"max_expansions" : 10
}
}
}
}
6. Multi match query
如果你需要在多个字段上进行文本搜索,可用multi_match 。 multi_match在 match的基础上支持对多个字段进行文本查询。
查询1:
GET ftq/_search
{
"query": {
"multi_match" : {
"query": "lucene java",
"fields": [ "title", "content" ]
}
}
}
结果1:
{
"took": 1973,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.5753642,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "2",
"_score": 0.5753642,
"_source": {
"title": "java spring boot",
"content": "lucene is writerd by java"
}
},
{
"_index": "ftq",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
}
]
}
}
查询2:字段通配符查询
GET ftq/_search
{
"query": {
"multi_match" : {
"query": "lucene java",
"fields": [ "title", "cont*" ]
}
}
}
结果2:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.5753642,
"hits": [
{
"_index": "ftq",
"_type": "_doc",
"_id": "2",
"_score": 0.5753642,
"_source": {
"title": "java spring boot",
"content": "lucene is writerd by java"
}
},
{
"_index": "ftq",
"_type": "_doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "lucene solr and elasticsearch",
"content": "lucene solr and elasticsearch for search"
}
}
]
}
}
查询3:给字段的相关性评分加权重
GET ftq/_search?explain=true
{
"query": {
"multi_match" : {
"query": "lucene elastic",
"fields": [ "title^5", "content" ]
}
}
}
结果3:
View Code
7. Common terms query
common 常用词查询
问1、什么是停用词?索引时做停用词处理的目的是什么?
不再使用的词,做停用词处理的目的是提高索引的效率,去掉不需要的索引操作,即停用词不需要索引
问2、如果在索引时应用停用词处理,下面的两个查询会查询什么词项?
the brown fox—— brown fox
not happy——happy
问3、索引时应用停用词处理对搜索精度是否有影响?如果不做停用词处理又会有什么影响?如何协调这两个问题?如何保证搜索的精确度又兼顾搜索性能?
索引时应用停用词处理对搜索精度有影响,不做停用词处理又会影响索引的效率,要协调这两个问题就必须要使用tf-idf 相关性计算模型
7.1 tf-idf 相关性计算模型简介
tf:term frequency 词频 :指一个词在一篇文档中出现的频率。
如“世界杯”在文档A中出现3次,那么可以定义“世界杯”在文档A中的词频为3。请问在一篇3000字的文章中出现“世界杯”3次和一篇150字的文章中出现3词,哪篇文章更是与“世界杯”有关的。也就是说,简单用出现次数作为频率不够准确。那就用占比来表示:

问:tf值越大是否就一定说明这个词更相关?
不是,出现太多了说明不重要
说明:tf的计算不一定非是这样的,可以定义不同的计算方式。
df:document frequency 词的文档频率 :指包含某个词的文档数(有多少文档中包含这个词)。 df越大的词越常见,哪些词会是高频词?
问1:词的df值越大说明这个词在这个文档集中是越重要还是越不重要?
越不重要
问2:词t的tf高,在文档集中的重要性也高,是否说明文档与该词越相关?举例:整个文档集中只有3篇文档中有“世界杯”,文档A中就出现了“世界杯”好几次。
不能说明文档与该词越相关
问3:如何用数值体现词t在文档集中的重要性?df可以吗?
不可以
idf:inverse document frequency 词的逆文档频率 :用来表示词在文档集中的重要性。文档总数/ df ,df越小,词越重要,这个值会很大,那就对它取个自然对数,将值映射到一个较小的取值范围。

说明: +1 是为了避免除0(即词t在文档集中未出现的情况)
tf-idf 相关性性计算模型:tf-idf t = tf t,d * idf t
说明: tf-idf 相关性性计算模型的值为词频( tf t,d)乘以词的逆文档频率(idf t)
7.2 Common terms query
common 区分常用(高频)词查询让我们可以通过cutoff_frequency来指定一个分界文档频率值,将搜索文本中的词分为高频词和低频词,低频词的重要性高于高频词,先对低频词进行搜索并计算所有匹配文档相关性得分;然后再搜索和高频词匹配的文档,这会搜到很多文档,但只对和低频词重叠的文档进行相关性得分计算(这可保证搜索精确度,同时大大提高搜索性能),和低频词累加作为文档得分。实际执行的搜索是 必须包含低频词 + 或包含高频词。
思考:这样处理下,如果用户输入的都是高频词如 “to be or not to be”结果会是怎样的?你希望是怎样的?
优化:如果都是高频词,那就对这些词进行and 查询。
进一步优化:让用户可以自己定对高频词做and/or 操作,自己定对低频词进行and/or 操作;或指定最少得多少个同时匹配
示例1:
GET /_search
{
"query": {
"common": {
"message": {
"query": "this is bonsai cool",
"cutoff_frequency": 0.001
}
}
}
}
说明:
cutoff_frequency : 值大于1表示文档数,0-1.0表示占比。 此处界定 文档频率大于 0.1%的词为高频词。
示例2:
GET /_search
{
"query": {
"common": {
"body": {
"query": "nelly the elephant as a cartoon",
"cutoff_frequency": 0.001,
"low_freq_operator": "and"
}
}
}
}
说明:low_freq_operator指定对低频词做与操作
可用参数:minimum_should_match (high_freq, low_freq), low_freq_operator (default “or”) and high_freq_operator (default “or”)、 boost and analyzer
示例3:
GET /_search
{
"query": {
"common": {
"body": {
"query": "nelly the elephant as a cartoon",
"cutoff_frequency": 0.001,
"minimum_should_match": 2
}
}
}
}
示例4:
GET /_search
{
"query": {
"common": {
"body": {
"query": "nelly the elephant not as a cartoon",
"cutoff_frequency": 0.001,
"minimum_should_match": {
"low_freq" : 2,
"high_freq" : 3
}
}
}
}
}
示例5:

8. Query string query
query_string 查询,让我们可以直接用lucene查询语法写一个查询串进行查询,ES中接到请求后,通过查询解析器解析查询串生成对应的查询。使用它要求掌握lucene的查询语法。
示例1:指定单个字段查询
GET /_search
{
"query": {
"query_string" : {
"default_field" : "content",
"query" : "this AND that OR thus"
}
}
}
示例2:指定多字段通配符查询
GET /_search
{
"query": {
"query_string" : {
"fields" : ["content", "name.*^5"],
"query" : "this AND that OR thus"
}
}
}
可与query同用的参数,如 default_field、fields,及query 串的语法请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html
9. 查询描述规则语法(查询解析语法)
Term 词项:
单个词项的表示: 电脑
短语的表示: "联想笔记本电脑"
Field 字段:
字段名:
示例: name:“联想笔记本电脑” AND type:电脑
如果name是默认字段,则可写成: “联想笔记本电脑” AND type:电脑
如果查询串是:type:电脑 计算机 手机
注意:只有第一个是type的值,后两个则是使用默认字段。
Term Modifiers 词项修饰符:




10. Simple Query string query
simple_query_string 查同 query_string 查询一样用lucene查询语法写查询串,较query_string不同的地方:更小的语法集;查询串有错误,它会忽略错误的部分,不抛出错误。更适合给用户使用。
示例:
GET /_search
{
"query": {
"simple_query_string" : {
"query": "\"fried eggs\" +(eggplant | potato) -frittata",
"fields": ["title^5", "body"],
"default_operator": "and"
}
}
}
语法请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-simple-query-string-query.html
11. Term level querys
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/term-level-queries.html
11.1 Term query
term 查询用于查询指定字段包含某个词项的文档。
示例1:
POST _search
{
"query": {
"term" : { "user" : "Kimchy" }
}
}示例2:加权重
GET _search
{
"query": {
"bool": {
"should": [
{
"term": {
"status": {
"value": "urgent",
"boost": 2
}
}
},
{
"term": {
"status": "normal"
}
}
]
}
}
}
11.2 Terms query
terms 查询用于查询指定字段包含某些词项的文档。
GET /_search
{
"query": {
"terms" : { "user" : ["kimchy", "elasticsearch"]}
}
}Terms 查询支持嵌套查询的方式来获得查询词项,相当于 in (select term from other)
示例1:Terms query 嵌套查询示例
PUT /users/_doc/2
{
"followers" : ["1", "3"]
}
PUT /tweets/_doc/1
{
"user" : "1"
}
GET /tweets/_search
{
"query": {
"terms": {
"user": {
"index": "users",
"type": "_doc",
"id": "2",
"path": "followers"
}
}
}
}
查询结果:
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "tweets",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"user": "1"
}
}
]
}
}
嵌套查询可用参数说明:

11.3 range query
范围查询示例1:
GET _search
{
"query": {
"range" : {
"age" : {
"gte" : 10,
"lte" : 20,
"boost" : 2.0
}
}
}
}
范围查询示例2:
GET _search
{
"query": {
"range" : {
"date" : {
"gte" : "now-1d/d",
"lt" : "now/d"
}
}
}
}
范围查询示例3:
GET _search
{
"query": {
"range" : {
"born" : {
"gte": "01/01/2012",
"lte": "2013",
"format": "dd/MM/yyyy||yyyy"
}
}
}
}
范围查询参数说明:

范围查询时间舍入 ||说明:

时间数学计算规则请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/common-options.html#date-math
11.4 exists query
查询指定字段值不为空的文档。相当 SQL 中的 column is not null
GET /_search
{
"query": {
"exists" : { "field" : "user" }
}
}查询指定字段值为空的文档
GET /_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "user"
}
}
}
}
}
11.5 prefix query 词项前缀查询
示例1:
GET /_search
{ "query": {
"prefix" : { "user" : "ki" }
}
}示例2:加权
GET /_search
{ "query": {
"prefix" : { "user" : { "value" : "ki", "boost" : 2.0 } }
}
}11.6 wildcard query 通配符查询: ? *
示例1:
GET /_search
{
"query": {
"wildcard" : { "user" : "ki*y" }
}
}示例2:加权
GET /_search
{
"query": {
"wildcard": {
"user": {
"value": "ki*y",
"boost": 2
}
}
}}
11.7 regexp query 正则查询
示例1:
GET /_search
{
"query": {
"regexp":{
"name.first": "s.*y"
}
}
}
示例2:加权
GET /_search
{
"query": {
"regexp":{
"name.first":{
"value":"s.*y",
"boost":1.2
}
}
}
}
正则语法请参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html#regexp-syntax
11.8 fuzzy query 模糊查询
示例1:
GET /_search
{
"query": {
"fuzzy" : { "user" : "ki" }
}
}示例2:
GET /_search
{
"query": {
"fuzzy" : {
"user" : {
"value": "ki",
"boost": 1.0,
"fuzziness": 2,
"prefix_length": 0,
"max_expansions": 100
}
}
}
}
11.9 type query mapping type 查询
GET /_search
{
"query": {
"type" : {
"value" : "_doc"
}
}
}
11.10 ids query 根据文档id查询
GET /_search
{
"query": {
"ids" : {
"type" : "_doc",
"values" : ["1", "4", "100"]
}
}
}
12. Compound querys 复合查询

官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/compound-queries.html
12.1 Constant Score query
用来包装另一个查询,将查询匹配的文档的评分设为一个常值。
GET /_search
{
"query": {
"constant_score" : {
"filter" : {
"term" : { "user" : "kimchy"}
},
"boost" : 1.2
}
}
}
12.2 Bool query
Bool 查询用bool操作来组合多个查询字句为一个查询。 可用的关键字:

示例:
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tag" : "wow" } },
{ "term" : { "tag" : "elasticsearch" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
说明:should满足一个或者两个或者都不满足