如何在中后台领域玩转BFF架构
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
2021年08月14日,平台前端在「前端早早聊」分享了哈啰出行在BFF领域的实践,以下是由平台前端赵存分享的主题
哈啰出行平台前端:Allan91(作者授权转载)
链接:https://juejin.cn/post/6997250621627858957
分享大纲
本次分享主要从业务背景、BFF 核心架构、基于 Serverless 的 BFF 改造、总结四个部分组成。

业务背景
我们的供应链场景有很多供应商,每个供应商都有物流、资产、仓储等多个域,而这些域我们的后端都基于 DDD 领域模型做了微服务化,此时前端在开发面向这些供应商使用的中后台应用时,遇到了以下问题:
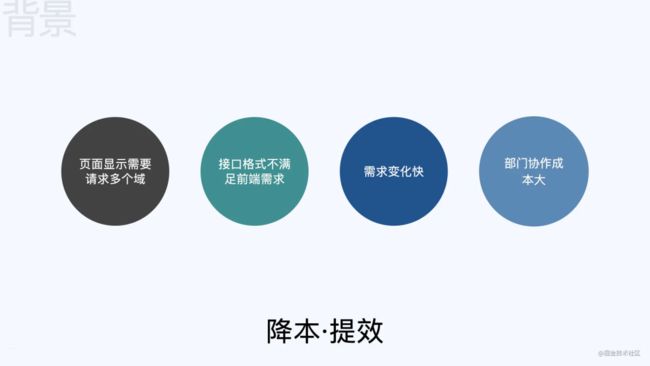
页面显示需要请求多个域:比如一个商家的详情页,可能既需要请求仓储数据,还需要请求资产数据,才能将一个页面显示出来。
接口格式不满足前端需求:后端微服务化后,是面向多项目,通用性的,其接口格式不一定能满足前端需求,前端需要自己做转换,比如单位转换,字段裁减。
需求变化快:业务在快速迭代,需要接口的大量支持,而我们的后端域是面向多项目的,更改成本较大,需要投入更多的测试,此时如果在前端和后端中间存在一个中间层,来做这些事情,那么效率会有比较好的提高。
部门协作成本大:有些需求需要其它部门的后端同学支持,而其它部门的同学因为自己部门的需求紧张,排期较满,导致我们的需求迟迟无法排期,此时如果存在一个中间层,在中间层去请求其它部门提供的领域服务来组合数据提供给前端,此时就可以在其它部门同学不参与的情况下,前端自己完成需求开发,部门之间的协作成本会大大降低。
基于以上背景,前端这边引入了 BFF 架构,BFF 架构能做哪些事情:
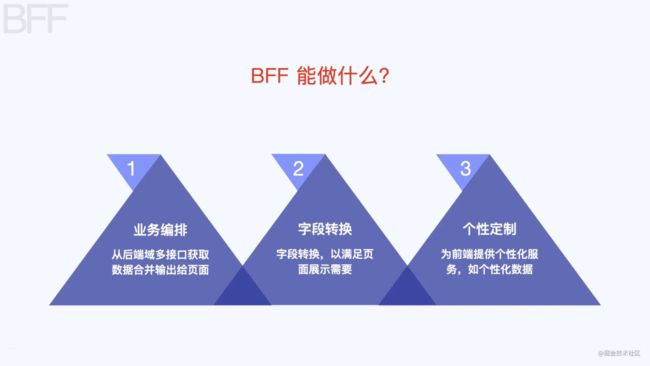
业务编排:从后端域多接口获取数据合并输出给页面。比如一个商家详情页即需要仓储数据,也需要资产数据,此时我们在 BFF 层将仓储和资产数据请求回来组装吐给前端。
字段转换:字段过滤、数据格式化等工作。比如资产域的商户名字段叫 businessName,而仓储域的商户名字段叫 shopName,此时可以在BFF层统一掉,这样前端就不需要做判断了。
个性化数据:为前端提供个性化服务,如数据压缩,单位转换等。
BFF 核心架构
核心架构

以上是 BFF 的核心架构图,前端即中后台应用,后端域即后端服务,右侧的工具支撑是公司的一些基础公共服务,中间的就是 BFF 核心实现,我们从上往下看:
业务:可以在这一层做业务编排,字段转换,个性定制等业务逻辑,同时提供了一个 node-auth 包,可以利用该包做用户鉴权。
基础框架:基础框架这层,主要封装了 node-soa 这个 npm 包,node-soa 里面包含了 node-log 日志工具、node-hook 代码规则校验工具、node-zk 集群链接工具等。
Node框架:Node 框架这块选型的是 Koa2。
调用链路
核心架构讲完后,再看下整个 BFF 架构的调用链路:
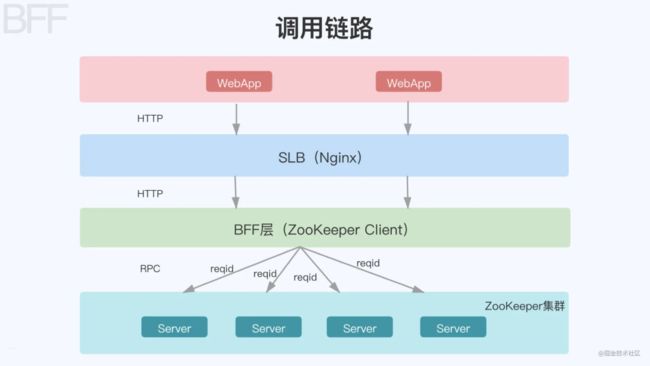
调用链路从上往下,我们的中后台应用通过 HTTP 请求到 Nginx 服务器上,Nginx 转发到 BFF 层,BFF 层通过 RPC 调用后端域的微服务,完成整个调用过程。这里有两个概念需要说明下:
ZooKeeper:可简单理解为服务注册中心,后端的各个微服务都统一注册到这个注册中心,然后 BFF 层充当 ZooKeeper Client 去连接这个注册中心,连接后,就可以枚举到注册中心每个服务的 Host 和 Port,拿到 Host 和 Port 就可以发起 RPC 调用了。RPC:远程过程调用,也就是说两台服务器 A、B,一个部署在 A 服务器上的应用需要访问 B 服务器上的一个应用的某个方法,由于不在一个内存空间,因此需要通过网络来表达调用的语义和传达的数据,可以简单理解为 A 服务器上部署了我们的 BFF 应用,B 服务器上部署了我们的微服务。RPC 通信协议可基于 HTTP 或者 TCP 协议,我们采用的是 gRPC,即使用 HTTP/2 的一种 RPC 调用方式。
以上介绍了 BFF 的核心架构和整个调用链路,下面来看看 node-soa 的具体实现细节。
服务初始化
通过调用 node-soa 提供的 init 方法来完成服务的初始化,其中 dep 即为各后端域的微服务。

我们再看看 init 的具体实现:

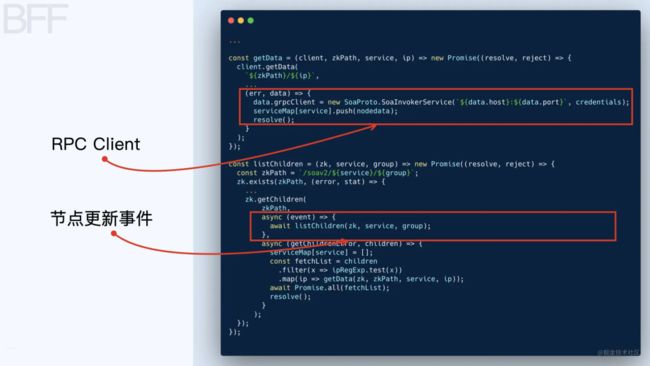
首先创建了一个 ZooKeeper Client 去连接 ZooKeeper 集群,连接上以后通过 listChildren 方法枚举 ZooKeeper 集群的所有子节点,拿到子节点的Host 和 Port 后创建了一个 grpcClient,之后就可以通过这个grpcClient 发起 RPC 调用了。
服务调用
服务初始化后就可以发起 RPC 调用了,node-soa 提供了request 方法,通过这个方法即可发起 RPC 调用,其中 service 就是后端域,method 即为 java 侧提供的方法。

我们在看看 request 里面的具体实现:

通过服务初始时创建的 grpcClient 发起 RPC 调用,拿到数据后 resolve 回去,即完成一次 RPC 调用,在整个 RPC 调用过程中利用 Jaeger + OpenTracing 做了调用链路的追踪,利用 node-log 做了请求日志的落盘。以上即为我们第一代BFF架构的核心内容,这套架构在当时的业务背景下是一个比较好的解决方案,但随着业务的快速发展,这个架构也遇到了一些问题:
运维成本增大:随着 BFF 应用的增多,需要更多的机器来部署BFF应用。
发布流程长:新增一个 BFF 的接口,需要走完编译,构建,部署一整套流程,无法做到秒级部署。
域名不收敛:每个 BFF 都有各自独立的域名,增加记忆成本。
鉴于这些痛点,我们引入了 SFF(Serverless For Frontend)架构,通过将 BFF 构建于 Serverless 之上,用云函数的方式取代传统基于 NodeJS 的 BFF 层。
基于 Serverless 的BFF改造
SFF 架构

上图是改造后的BFF架构,相比于一代的 BFF 架构,这里主要多了两块内容,一块是 FaaS 层,另外一块是开发者平台。
开发者平台是在线编写云函数的,主要提供了函数管理、发布管理等功能,发布的每个函数都会保存在数据库中。
FaaS 层主要就是一个个 Function,一个 BFF 接口请求过来,首先会去数据库获取对应的函数,然后执行该函数。
实现方案选型
目前主流的方案主要是基于容器和基于进程两种方式。

容器方案:基本实现是利用K8s + Docker,每个云函数执行的时候都启动一个容器去执行,执行完后容器销毁,整个容器的管理、并发处理、扩缩容都是用K8s来管理。
进程方案:每个云函数的执行都启动一个新的进程去执行,执行完后进程销毁。
对于实现方案的选型,我们需要考虑以下几个方面:
业务场景复杂性:高并发采用容器方案更好;并发少,选用进程更轻量,也更容易实现。
基建&运维能力:容器方案对基建和运维能力有更高的要求,要考虑公司的运维能不能 Cover 住。
团队人力/能力:基于容器方案技术上的要求会更高一些,实现难度也会更大一点,要考虑团队的小伙伴这方面的经验有没有,团队的人手够不够。
我们的业务并不复杂,中后台应用几乎没有高并发,目前公司对于容器的使用还没有大推,团队人手也不是很够,加上缺少容器这方面的实战经验,最终采用了基于进程的方式来实现。
实现
基本的实现如下:

用户发起 HTTP 请求,Node 主进程去数据库读取该请求的函数实现,拿到函数实现后会 Fork 一个子进程执行函数,函数执行完后子进程销毁。这里需要注意的一点是控制子进程的执行时间,防止因为函数执行异常,导致子进程无法销毁。我们在看下执行函数的具体实现:

通过 VM2 模块来执行我们的云函数,从而保证子进程和主进程之间的 Context 隔离,如果不进行隔离,有可能出现的一种情况是,子进程里面如果调用了 process.exit(),此时我们的 Node 主进程就会被退出去。
做了进程的 Context 隔离还不够,我们可以利用进程池来优化每次 Fork 子进程的时间,利用 CGroup 来限制子进程的 CPU 使用率、内存占用、磁盘IO等。CGroup 是 Linux 内核中的一个核心能力,提供了将不同进程按分组进行管理的能力,并且能对不同的分组限制其所使用的计算资源(CPU、内存、磁盘IO等),我们可以通过限制用来执行函数的子进程所能消耗的最大内存、磁盘及网络带宽,同时控制进程所能使用的最大 CPU 占用率等方式来保证系统的稳定性。最终的实现如下:
 以上就是基于 Serverless 的 BFF 改造的核心内容,相比于一代的 BFF 架构,基于 Serverless 的BFF改造有以下几点优势:
以上就是基于 Serverless 的 BFF 改造的核心内容,相比于一代的 BFF 架构,基于 Serverless 的BFF改造有以下几点优势:
效率提升:独立云函数,动态编写,秒级部署。
降本:应用收敛,有效降低运维、机器成本。
总结
以上就是平台前端本次分享的主要内容,我们做下总结:
后端领域微服务化后,需要一套能提供业务编排、字段转换、个性定制的机制来保证业务的快速迭代。BFF 架构能够有效的做到业务编排、字段转换、个性定制,且让前端进入全栈领域。构建于 Serverless 之上的 BFF 进一步的降低了运维、机器成本,提高了人效。
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。

“分享、点赞、在看” 支持一波 