机器学习 聚类
聚类
在“无监督学习”任务中研究最多、应用最广。
聚类目标:将数据集中的样本划分为若干个通常不相交的子集(“簇”,cluster):
聚类既可以作为一个单独过程(用于找寻数据内在的分布结构),也可作为分类等其他学习任务的前驱过程
一、聚类的目的
聚类(Clustering)是一种发现数据中的相似群(聚类,clusters)的技术。聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程。一个聚类就是一些数据实例的集合,这个集合中的元素彼此相似;与其他聚类中的元素不同。
二、聚类性能的度量
我们希望“物以类聚” ,即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的“簇内相似度”( i n t r a intra intra- c l u s t e r s i m i l a r i t y cluster similarity clustersimilarity)高,且“簇间相似度”( i n t e r inter inter- c l u s t e r s i m i l a r i t y cluster similarity clustersimilarity)低,这样的聚类效果较好。聚类的性能度量与其他不太一样,分为外部指标和内部指标。
- 外部指标:将聚类结果与某个“参考模型”(reference model) 进行比较。
 !
!
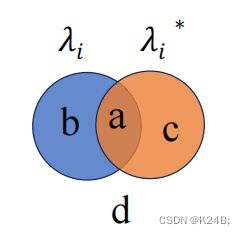
在此基础上定义了几个指标:
Jaccard系数(Jaccard Coefficient, JC):
J C = a a + b + c JC= \frac {a}{a+b+c} JC=a+b+ca
FM指数(Fowlkes and Mallows Index, FMI):
F M I = a a + b ⋅ a a + c FMI=\sqrt{\frac{a}{a+b}\cdot \frac{a}{a+c}} FMI=a+ba⋅a+ca
Rand指数(Rand Index, RI):
R I = a + d a + b + c + d = a + d m ( m − 1 ) / 2 = 2 ( a + d ) m ( m − 1 ) m 为样本的个数 RI=\frac {a+d}{a+b+c+d} = \frac {a+d}{m(m-1)/2} = \frac {2(a+d)}{m(m-1)}\\ \\ m为样本的个数 RI=a+b+c+da+d=m(m−1)/2a+d=m(m−1)2(a+d)m为样本的个数
-
内部指标:考虑聚类结果的簇划分 C = { C 1 , C 2 , ⋅ ⋅ ⋅ C k } C=\left\{ C_1,C_2,\cdot \cdot \cdot C_k \right\} C={C1,C2,⋅⋅⋅Ck} 定义:
簇C内样本间的平均距离:
a v g ( C ) = 2 ∣ C ∣ ( ∣ C ∣ − 1 ) max 1 < = i < = j < = ∣ C ∣ d i s t ( x i , x j ) avg(C)= \frac {2}{|C|(|C|-1)} \underset{1<=i<=j<=|C|}{\max}dist( x_ {i} , x_ {j} ) avg(C)=∣C∣(∣C∣−1)21<=i<=j<=∣C∣maxdist(xi,xj)
簇C内样本间的最远距离:
d i a m ( C ) = max 1 < = i < = j < = ∣ C ∣ d i s t ( x i , x j ) 。 diam(C) =\underset{1<=i<=j<=|C|}{\max}dist( x_ {i} , x_ {j} )。 diam(C)=1<=i<=j<=∣C∣maxdist(xi,xj)。
簇 C i C_i Ci 与簇 C j C_j Cj最近样本间的距离:
d min ( C ) = min x i ϵ C i , x j ϵ C j d i s t ( x i , x j ) d_{\min}\left( C \right) =\underset{x_i\epsilon C_i,x_j\epsilon C_j}{\min}dist\left( x_i,x_j \right) dmin(C)=xiϵCi,xjϵCjmindist(xi,xj)
簇 C i C_i Ci 与簇 C j C_j Cj中心点间的距离:
d c e n ( C ) = d i s t ( μ i , μ j ) d_ {cen} (C)=dist( \mu _ {i} , \mu _ {j} ) dcen(C)=dist(μi,μj)
D B DB DB指数 ( D a v i e s − B o u l d i n I n d e x , D B I ) (Davies-Bouldin Index, DBI) (Davies−BouldinIndex,DBI):
D B I = 1 k ∑ i = 1 k a v g ( C i ) + a v g ( C j ) d c e n ( μ i , μ j ) DBI= \frac {1}{k} \sum _ {i=1}^ {k} \frac {avg(C_ {i})+avg(C_ {j})}{d_ {cen}(\mu _ {i},\mu _ {j})} DBI=k1i=1∑kdcen(μi,μj)avg(Ci)+avg(Cj)
D u n n Dunn Dunn指数 ( D u n n I n d e x , D I ) (Dunn Index, DI) (DunnIndex,DI):
D I = min 1 < = i < = j { min j ! = 1 ( d min ( C i , C j ) max 1 < = l < = k d i a m ( C l ) ) } DI=\underset{1<=i<=j}{\min}\left\{ \underset{j!=1}{\min}\left( \frac{d_{\min}\left( C_i,C_j \right)}{\underset{1<=l<=k}{\max}diam\left( C_l \right)} \right) \right\} DI=1<=i<=jmin⎩ ⎨ ⎧j!=1min 1<=l<=kmaxdiam(Cl)dmin(Ci,Cj) ⎭ ⎬ ⎫
分析公式可得, D B DB DB指数越小越好,而Dunn指数越大越好。 -
距离计算
闵可夫斯基距离:
d i s t ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ p ) 1 p dist( x_ {i} , x_ {j} )=( \sum _ {u=1}^ {n} |x_ {iu} - x_ {ju} |^p)^\frac{1}{p} dist(xi,xj)=(u=1∑n∣xiu−xju∣p)p1
当 p=1时,曼哈顿距离,当p=2时,欧式距离。
三.原型聚类
3.1 K均值聚类算法K-Means Clustering Algorithm
3.1.1快速理解:
- 有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的居民,于是每个居民到离自己家最近的布道点去听课。
- 听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的居民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。
- 牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个居民又去了离自己最近的布道点.…就这样,牧师每个礼拜更新自己的位置,居民根据自己的情况选择布道点,最终稳定了下来。
3.1.2基本思想
通过迭代把数据集划分为不同的类别(或称簇),使得评价聚类性能的准则函数达到最优,使得每个聚类类内紧凑,类间独立。
3.1.3 K-Means 算法实现步骤:
- 先定义总共有多少个类/簇(cluster) (这就是 K 均值聚类中的 K ,有几个类 K 就是多少)。
- 将每个簇心 (cluster centers)随机定在一个点上。
- 将每个数据点关联到最近簇中心所属的簇上。
- 对于每一个簇找到其所有关联点的中心点(取每一个点坐标的平均值)。
- 将上述点变为新的簇心。
- 不停重复,直到每个簇所拥有的点不变。
3.1.4评价聚类性能的准则函数
平方误差和准则函数SSE(sum of the squared error)
S S E = ∑ i = 1 k ∑ p ϵ C i ∥ p − m i ∥ 2 SSE=\sum_{i=1}^k{\sum_{p\epsilon C_i}{\lVert p-m_i \rVert ^2}} SSE=i=1∑kpϵCi∑∥p−mi∥2
一共有 k k k个划分的簇,即有 k k k个中心点, p p p为属于第 i i i个簇的样本, m i \ m_i mi为簇 C i C_i Ci的中心点。
这个准则函数使得生成的簇尽可能的紧凑和独立。
3.1.5算法实现伪代码

3.1.6 simple example

3.1.7 影响 聚类效果的因素
- 初始样本点的选择
- k值的选择
- 评价聚类性能的准则函数的选择(一般采用欧氏距离、曼哈顿距离或者明考斯基距离的一种,作为样本间的相似性度量)
3.1.8 K-均值算法有哪些不足之处
- k-means算法只有在簇的平均值被定义的情况下才能使用。
- k-means算法的不足之处在于它要多次扫描数据,效率低。
- k-means算法只能找出球形的类,而不能发现任意形状的类。
- 初始质心的选择对聚类结果有较大的影响。
- k-means算法对于噪声和孤立点数据是敏感的,少量的该类数据能够对平均值产生极大的影响
3.2 模糊C均值聚类 (fuzzy c-means)
3.2.1思路:
将聚类问题中的类定义为模糊集合,用模糊集的隶属度函数定量描述样本点与类之间的从属关系,并通过寻找使目标函数最小化的隶属度函数,实现聚类。
3.2.2定义

3.2.3 目标函数


3.2.4 具体步骤

3.3 K-中心点聚类算法( K K K - M e d o i d e Medoide Medoide )
3.3.1 PAM (Partitioning Around Medoide )
与K-均值算法的联系和区别
K-中心点算法也是一种常用的聚类算法,K-中心点聚类的基本思想和 K-means 的思想相同,实质上是对 K-means 算法的优化和改进。在 K-means 中,一些极值点对距离的计算影响比较大。在 K-means 算法执行过程中,可以通过随机的方式选择初始质心,也只有初始时通过随机方式产生的质心才是实际需要聚簇集合的中心点,而后面通过不断迭代产生的新的质心很可能并不是在聚簇中的点。如果某些异常点距离质心相对较大时,很可能导致重新计算得到的质心偏离了聚簇的真实中心。
PAM算法和K-Means不同的点就在,重新获得新的类聚中心这一步,K-Means 是通过计算类簇的均值来获得新的中心点,PAM是通过让类簇的每个点替代该类簇的中心点获得新的中心点的组合,然后计算代价,代价小显然就更加优秀,代价大显然就该舍弃。
PAM 算法实现步骤
-
确定聚类的个数 K。
-
在所有数据集合中选择 K 个点作为各个聚簇的中心点。
-
计算其余所有点到 K 个中心点的距离,并把每个点到 K 个中心点最短的聚簇作为自己所属的聚簇。
-
在每个聚簇中按照顺序依次选取点,计算该点到当前聚簇中所有点距离之和,最终距离之和最小的点,则视为新的中心点。
-
重复2,3步骤,直到各个聚簇的中心点不再改变。
PAM 算法的评价
PAM算法的时间复杂度是O( N 2 N^2 N2),所以对于大数据量是不可接受的,但是PAM算法的精确度是相当的高,因为PAM算法从某种意义上来讲是类似穷举法的,是从所有的数据点中,计算大部分的点的组合来获得最优的代价。
PAM算法可以得到更加稳定和可靠的聚类结果,但是处理大规模数据集时会比较耗时。
3.3.2 CLARA (Clustering LARge Applications)
与PAM 算法的联系和区别
该算法就是在PAM的基础上提出的进行大规模数据的聚类的算法。该算法的思想就是通过在大规模数据中进行随机抽样,然后对每个抽样的样本使用PAM算法,最后在每个样本聚类出的最佳中心点中寻找一个代价最小的聚类中心作为当前的大数据样本的最佳聚类。
CLARA算法实现步骤
- 对数据集中进行多次随机采样,得到多个子集(采样的子集分布最好能够与原始数据集分布相似)
- 对每个子集进行PAM算法,选取中心,即每一个子集中都有k个中心点;
- 用每一个子集中的k个中心点对大数据样本进行聚类,选择最好的一组中心点,作为大样本数据的中心点。
伪代码

3.3.2.3 CLARA算法的评价
CLARA算法的时间复杂度是O( N l o g N NlogN NlogN),缺点是无法找出最优解。
3.3.3 CLARANS (Clustering Large Applications based on Randomized Search)
与 CLARA算法和PAM算法的联系和区别
该算法就是在CLARA算法的基础上提出的,目的就是为了克服CLARA算法在采样上面的缺陷,使得能够找出最优解。该算法其实和PAM算法类似,但是通过两个阀值来对PAM两层循环进行控制,从而可以控制速度和精度。
CLARANS 算法的特点
- CLARANS 在结果空间动态采样
- 一个结果就是一个 k个中心集合
- 结果空间共包含 C n k C_{n}^{k} Cnk 个组合
- 结果空间可以用一个图来表示,图上的一个节点表示一个可能的结果,即一个结点有k个中心点
CLARANS 算法的理解
-
图上每一个节点都是一个可能的结果,而每一个结果就是一个k个中心集合
-
每一个节点都有一个聚类误差(即总的类内距离和)
-
每一个相邻的节点定义为:节点中k个中心点中只有一个不同
-
每个节点都有k(n-k)个相邻的节点

CLARANS 算法的步骤
- 从图上随机选一个节点,即随机选一组k个中心点,然后检测m次邻居节点;
- 如果当前邻居节点的k个中心聚类效果比现有节点好,则转移到当前邻居节点,并重复上述过程直至m次;否则返回当前节点作为局部最优节点;
- 从图上再选择其他节点,重复上述过程h次;
- 当h个局部最优解发现后,返回其中最好的解。
CLARANS 算法的伪代码

CLARANS 算法的评价
优点: C L A R A N S CLARANS CLARANS比 P A M PAM PAM和 C L A R A CLARA CLARA效率要高主要是因为在结果空间上进行采样,而且可以处理离群点
缺点:聚类的质量依赖于采样方法
3.4 学习向量量化( L e a r n i n g V e c t o r Q u a n t i z a t i o n , L V Q Learning Vector Quantization, LVQ LearningVectorQuantization,LVQ)
3.4.1 L V Q LVQ LVQ 的思想
L V Q LVQ LVQ 是一种有监督学习的聚类方法,和其他的原型聚类的思想一样,可以用于多类别分类问题上,就是将数据映射到一个离散的输出空间上面,通过计算欧几里得距离或者是余弦相似度来作为度量样本向量到原型向量(即前文提到的中心点)的距离,并根据距离分配标签,即样本标签就是离它距离最近的原型向量的标签。
给定样本集: { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x m , y m ) } \{(x_1,y_1),(x_2,y_2),\cdots,(x_m,y_m) \} {(x1,y1),(x2,y2),⋯,(xm,ym)},m个样本
L V Q LVQ LVQ 的目标就是学的一组q维向量 { p 1 , p 2 , ⋯ , p q } \{p_1,p_2,\cdots,p_q \} {p1,p2,⋯,pq},每个原型向量代表一个聚类簇, y i y_i yi有多少种取值, q q q就为多少。
3.4.2 L V Q LVQ LVQ 的伪代码

算法的理解,算法的关键在与第6-10行
可以看到当前向量的标签如果与离它最近的原型向量的标签一致则,
p ’ = p i ∗ + η ⋅ ( x j − p i ∗ ) p’=p_{i*}+\eta \cdot \left( x_j-p_{i*} \right) p’=pi∗+η⋅(xj−pi∗)
中心点更新为p’之后,他们之间的距离变为
∣ p ′ − x j ∣ = ∣ ( 1 − η ) ( p i ∗ − x j ) ∣ |p'-x_j|=|(1-\eta)(p_{i*}-x_j)| ∣p′−xj∣=∣(1−η)(pi∗−xj)∣
令学习率 η ∈ ( 0 , 1 ) \eta∈(0,1) η∈(0,1),则原型向量 p i ∗ p_{i*} pi∗在更新为 p ′ p' p′之后更接近心 x j , x_j, xj,他们之间的距离比之前要更小。
当前向量的标签与它最近的原型向量的标签不一致时,则同理,更新之后的 p ′ p' p′,他们之间的距离更远了。
四.密度聚类(DBSCAN )
将类看作数据空间中由低密度区域分隔开的高密度对象区域。
这是基于密度的聚类方法的主要策略。
4.1什么是密度聚类
一张图带你看明白密度聚类

上面分别是采用K-Means,Gaussian Mixture ,DBSCAN(密度聚类)的方式来对样本进行分类的结果。
可以直观看到,密度聚类的优势在于能够发现任何形状的类。
4.2密度聚类的一些基本的概念
-
核心对象(Core object):一个对象的 ε − ε- ε−邻域至少包含最小数目 M i n P t s MinPts MinPts 个对象。( M i n P t s MinPts MinPts 是人为规定的)。
-
噪声:不属于任何类的对象为噪声。
-
边界对象:对于空间中的一个对象,如果它在给定半径-的邻域中的对象个数大于密度阀值 M i n P t s MinPts MinPts ,则该对象被称为核心对象,否则称为边界对象。
-
密度直达(Directly density reachable,.DDR ):给定对象集合 D D D,如果 p p p是在 q q q的 ε − ε- ε−邻域内,而 q q q是核心对象,我们说对象p是从对象q密度直达的(如果q是一个核心对象, p p p属于 q q q的邻域,那么称 p p p密度直达 q q q)。
-
密度可达(density reachable):存在一个从 p p p到 q q q的 D D R DDR DDR对象链(如果存在一条链 < p l , p 2 , ⋯ , p i >
-
密度相连:如果存在 o o o, o o o密度可达 q q q和 p p p,则称 p p p和 q q q是密度连通的。
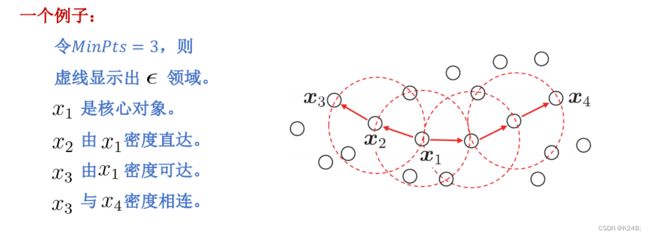
4.3、密度聚类的步骤
-
DBSCAN通过检查数据集中每个对象的ε邻域来寻找聚类。
-
如果一个点p的ε邻域包含多于MinPts个对象,则创建一个p作为核心对象的新类C。
-
然后,DBSCAN从C中寻找未被处理对象q的ε邻域,如果q的ε邻域包含多与MinPts个对象,则还未包含在C中的q的邻点被加入到类中,并且这些点的ε邻域将在下一步中进行检测。这个过程反复执行,当没有新的点可以被添加到任何类时,该过程结束。具体如下:
4.4、密度聚类的伪代码

4.4密度聚类的特点
优点:
- 能克服基于距离的算法只能发现“类圆形”类的缺点,可发现任意形状的聚类有效地处理数据集中的噪声数据,数据输入顺序不敏感
缺点:
-
输入参数敏感.确定参数ε,MinPts困难,若选取不当,将造成聚类质量下降.
-
由于在DBSCAN算法中,变量MinPts是全居唯一的,当空间聚类的密度不均匀、聚类间距离相差很大时,聚类质量较差。
-
计算密度单元的计算复杂度大,需要建立空间索引来降低计算量,且对数据维数的伸缩性较差。这类方法需要扫描整个数据库,每个数据对象都可能引起一次查询,因此当数据量大时会造成频繁的/O操作。
如下图:
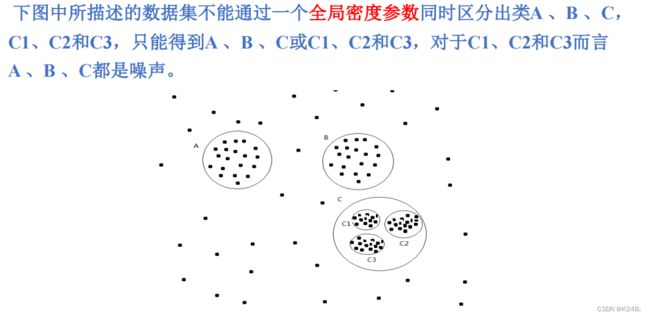
对参数的选择很敏感举例

五.层次聚类
5.1 什么是层次聚类
层次聚类试图在不同层次对数据集进行划分,从而形成树形的聚类结构。数据集划分既可采用“自底向上”的聚合策略,也可采用“自顶向下”的分拆策略。
AGNES算法(agglomerative nesting,自底向上的层次聚类算法)是比较常用的一种层次聚类算法。
首先,将样本中的每一个样本看做一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并,该过程不断重复,直到达到预设的聚类簇的个数。
5.2两个聚类簇之间的距离的衡量方式
最小距离: $ d_ {\min } ( C_ {i} , C_ {j} )=\underset{x\epsilon C_i\ y\epsilon C_j}{\min}dist\left( x,y \right)$ .
最大距离:$ d_ {\max } ( C_ {i} , C_ {j} )=\underset{x\epsilon C_i\ y\epsilon C_j}{\max}dist\left( x,y \right)$ .
平均距离: d a v g ( C i , C j ) = 1 ∣ C i ∣ ∣ C j ∣ ∑ x ϵ C i ∑ y ϵ C j d i s t ( x , y ) d_ {avg } ( C_ {i} , C_ {j} )=\frac{1}{\left| C_i \right|\left| C_j \right|}\sum_{x\epsilon C_i}{\sum_{y\epsilon C_j}{dist\left( x,y \right)}} davg(Ci,Cj)=∣Ci∣∣Cj∣1∑xϵCi∑yϵCjdist(x,y)
5.3 AGNES算法

伪代码实现

5.4.层次聚类的评价
优点:
- 可以处理不同类型的数据集
- 可以处理大型的数据集
缺点:
- 对于大量数据,计算成本很高;
- 对于具有不同大小、密度和形状的簇,效果不佳;
- 对于噪声和异常值敏感;
- 算法的结果高度依赖于所选的相似性度量和聚类算法;
- 无法处理非凸簇。