一.概述
Object类是java中所有类的父类,所有类默认(而非显式)继承Object。这也就意味着,Object类中的所有公有方法也将被任何类所继承。如果,整个java类体系是一颗树,那么Object类毫无疑问就是整棵树的根,因此值得我们仔细研读(以下代码基于jdk1.6)。
Object类中的方法如下:
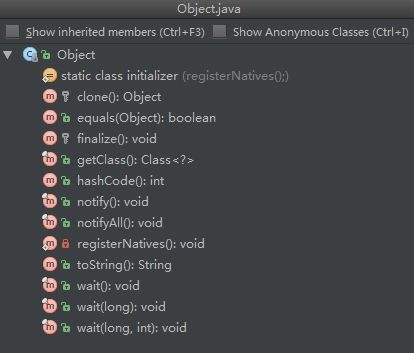
下面我们逐一介绍。
二.核心方法
1.equals方法
默认的实现是:

可以看出默认情况下equals进行对象比较时只判断了对象是否是其自身,当我们有特殊的“相等”逻辑时,则需要覆盖equals方法。
equals方法的通用约定:
自反性:对于任何非null的引用值x,x.equals(x)必须返回true。
对称性:对于任何非null的引用值x和y,当且仅当y.equals(x)返回true时,x.equals(y)必须返回true。
传递性:对于任何非null的引用值x、y、z,如果x.equals(y)返回true,并且y.equals(z)返回true,那么x.equals(z)也必须返回ture。
一致性:对于任何非null的引用值x和y,只要equals的比较操作在对象中所用的信息没有被修改,多次调用x.equals(y)就会一致的返回ture,或者一致的返回false。
非空性:对于任何非null的引用值x,x.equals(null)必须返回false。
当我们在类继承尤其要注意实现的equals方法是否满足约定。一个不满足约定的例子:
我们有一个水果类:

还有一个苹果类:

如果我们执行一下比较:
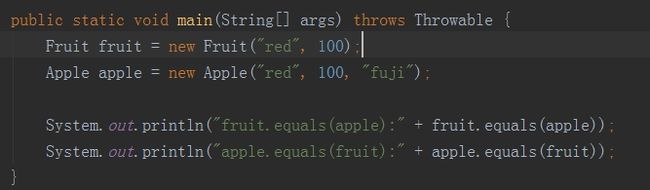
则会得到如下结果:
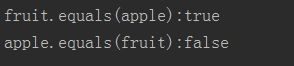
很显然,这并不符合对称性。
事实上:我们无法在扩展可实例化的类的同时,既增加新的值组件,同时又保留equals的约定,除非愿意放弃面向对象的抽象所带来的优势。
那这个问题该如何解决呢:
方法一:
不要拿Friut和Apple去比,这依赖于我们的主观自觉,虽然可以既利用继承带来的优势,但总归还要取决于人,有一定风险。
方法二:
将继承转为组合。
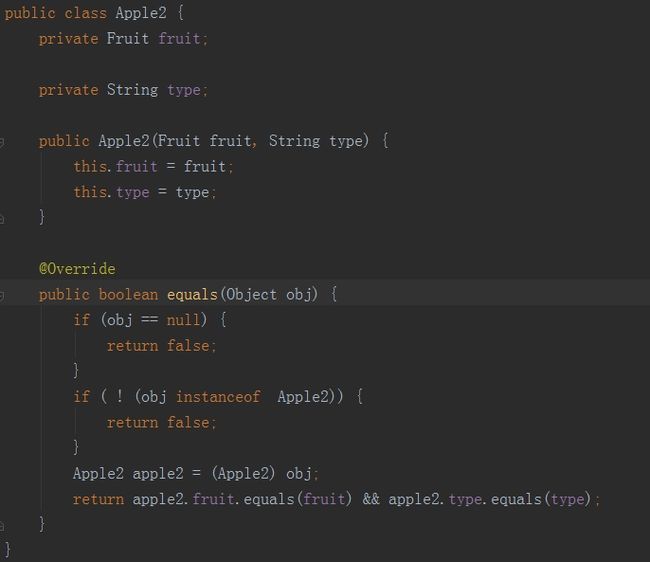
这时,再进行比较:

此时,结果是满足equals约定的:

2.hashCode方法
当我们覆盖了equals方法时,一定不能忘记覆盖hashCode方法。
hashCode方法的约定:
(1)在应用程序执行期间,只要对象的equals方法的比较操作所用到的信息没有被修改,那么对这同一个对象调用多次,hashCode方法都必须始终如一的返回同一个整数。在同一个应用程序的多次执行过程中,每次执行所返回的整数可以不一致。
(2)如果两个对象根据equals(Object)方法比较是相等的,那么调用这两个对象中任意一个对象的hashCode方法都必须产生同样的整数结果。
(3)如果两个对象根据equals(Object)方法比较是不相等的,那么调用这两个对象中任意一个对象的hashCode方法,则不一定要产生不同的整数结果。(尽管如此,理想的hashCode方法对不相等的对象,应当提供不同的hashCode值,这样当我们将对象作为Map的key时,可以提高散列表的性能)
如果我们覆盖了equals方法,但是没有覆盖hashCode方法,就会违反上述第2条约定。我们可以用代码来验证一下:

执行结果如下:

这会带来什么后果呢?如果我们把fruit1放到HashMap中,随后试图用一个“相等”的水果来找回时,就会出问题。如下:

执行程序,得到如下结果:

如何覆盖hashCode方法
一个好的散列函数通常倾向于“为不相等的对象产生不相等的散列码”。理想情况下,散列函数应该把集合中不相等的实例均匀的分布到所有可能的散列值上。
《effective java》一书中提到了一种简单的解决办法:
(1)把某个非零的常数值,比如17,保存在一个名为result的int类型的变量中。
(2)对于对象中的每个关键域f(equals方法中涉及的每个域,如果equals方法中没有涉及,则一定要排除在外),完成如下步骤:
a.为该域计算int类型的散列码c:
i.如果该域是boolean类型,则计算(f?1:0)。
ii.如果该域是byte、char、short或者int类型,则计算(int)f。
iii.如果该域是long类型,则计算(int)(f^(f>>>32))。
iv.如果该域是float类型,则计算Float.floatToIntBits(f)。
v.如果该域是double类型,则计算Double.doubleToLongBits(f),然后按照步骤iii中所述,为得到的long类型值计算散列值。
vi.如果该域是一个对象引用,并且该类的equals方法通过递归的调用equals的方式来比较这个域,则同样为这个域递归的调用hashCode。如果这个域的值为null,则返回0。
vii.如果该域是一个数组,则要把每一个元素当作单独的域来处理,也就是说,递归地应用上述规则,对每个重要元素计算一个散列码,然后根据步骤2.b中的做法把这些散列值组合起来。也可以使用Arrays.hashCode方法。
b.按照下面的公式,把步骤(2)a中计算得到的散列码c合并到result中:
result = 31 * result + c。
(3)返回result。
如果对我们之前提到的Fruit类重写hashCode方法,代码如下:

3.clone方法
通用约定:
clone方法将创建和返回该对象的一个拷贝。这个“拷贝”的精确含义取决于该对象的类。一般的含义是,对于任何对象x,表达式x.clone() != x 将会是true,并且,表达式x.clone().getClass() == x.getClass()将会是true。并且通常情况下,表达式x.clone().equals(x)将会是true。
一个标准的clone实现需要做到以下两点:
(1)调用super.clone()方法
(2)对于对象中的所有引用类型,均需要实现Cloneable接口,并重写clone方法,然后对每个引用执行clone方法。
示例代码:

使用clone方法的优点:
(1)速度快。clone方法最终会调用Object.clone()方法,这是一个native方法,本质是内存块复制,所以在速度上比使用new创建对象要快。
(2)灵活。可以在运行时动态的获取对象的类型以及状态,从而创建一个对象。
当然,使用clone方法创建对象的缺点同样非常明显:
(1)实现深拷贝较为困难,需要整个类继承系列的所有类都很好的实现clone方法。
(2)需要处理CloneNotSupportedException异常。Object类中的clone方法被声明为可能会抛出CloneNotSupportedException,因此在子类中,需要对这一异常进行处理。
因此,我们如果想使用clone方法的话,需要非常谨慎。事实上,《Effective Java》的作者Joshua Bloch建议我们不应该实现Cloneable接口,而应该使用拷贝构造器或者拷贝工厂。
4.toString方法
Object类提供了默认的toString方法实现:

从代码中我们可以看出,默认的toString方法仅仅返回类名+当前实例hashCode值的十六进制串,这非常不便于阅读,且没有包含实例中属性的值。
通过重写toString方法,我们可以输出需要的实例信息,例如可以对实例属性值进行格式化显示等等。如下所示:

除了手工编写格式化方式,我们还可以借助于一些第三方类库来实现实例的格式化,例如使用Apache Commons Lang工具包中的ToStringBuilder类。

三.其他方法
1.registerNatives方法
该方法被声明为是一个private static native方法,该方法的调用执行是在接下来声明的static块中:

由于是native方法,因此源代码我们不能直接看到,而在相关的C++代码中。该方法主要是为了服务于JNI(Java Native Interface)的,它主要是提供了java类中的方法与对应C++代码中的方法的映射,方便jvm查找调用C++中的方法。
2.getClass方法
该方法被声明为public final native方法,这说明该方法无法被重写,且是一个本地方法,通过API文档,我们可以了解到:该方法将返回对象的运行时类。例如:

运行结果如下:

获得运行时类信息后,我们接下来就可以做更多的事情:
(1)生成类的实例
(2)获取类中的方法、属性
(3)获取类的注解
(4)获取类所在的包
……
有关Class类,我们后续还会专门学习。
3.wait、notify、notifyAll方法
这三个方法都是public final native的。不可以被子类重写,且都是本地方法。这三个方法提供了java线程间等待、挂起等协同机制,是java多线程的基础,也留待后续深入学习。
4.finalize方法
根据java api中的说法:
“当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法”。
“finalize方法可以采取任何操作,其中包括再次使此对象对其他线程可用;不过,finalize的主要目的是在不可撤消地丢弃对象之前执行清除操作”。
“Java 编程语言不保证哪个线程将调用某个给定对象的finalize方法”。
“对于任何给定对象,Java 虚拟机最多只调用一次finalize方法”。
尽管finalize在某些时候是有用的,但是在大部分情况下,还是不建议使用,基于以下几点:
(1)不保证会被jvm执行,且不知道何时才会执行。这就给程序执行带来了很大不确定性。
(2)不同的jvm垃圾回收算法不一致,在一个jvm上工作良好,可能在另一个jvm上未必有效。
(2)性能。根据Joshua Bloch在《Effective Java》中的描述,增加了finalize后,对象的创建和销毁时间慢了430倍。
参考资料:
1.《effective java》
2. http://techbook.blog.163.com/blog/static/304885102012235613945/
3. http://www.cnblogs.com/zuoxiaolong/p/pattern24.html
链接:https://www.jianshu.com/p/4791207253a0