【redis】Stream、String、Scan 超详细介绍
文章目录
- 一、Stream
-
- 1.1 写入数据
-
- XADD
- 条目 ID 的格式
- 1.2 获取数据
-
- XRANGE 和 XREVRANGE
- XREAD 监听新条目
-
- 非阻塞形式
- 阻塞形式
- 1.3 消费者组
-
- XGROUP 创建消费者组
- XREADGROUP 通过消费者组消费
- XACK 确认消息
- 消费者组示例
- 1.4 XPENDING 和 XCLAIM 认领 其他消费者 的待处理消息
-
- XPENDING
- XCLAIM
- 1.5 XINFO STREAM 做可观察性
- 1.6 和 Kafka 的差别
- 1.7 MAXLEN 设置最多消息条数
- 1.8 XDEL 删除数据
- 1.9 允许存在零长度 Stream
- 1.10 示例
- 二、String
-
- MGET
- 三、运维
-
- 3.1 内存
- 3.2 批量操作
-
- 3.2.1 批量删除
- 四、Command
-
- 4.1 Scan
- 五、golang sdk

redis 使用手册 ebook
一、Stream
redis 5.0 版本引入了 Stream 数据类型,Stream 是只支持追加,并从 Kafka 引入了「消费者组」的概念,允许一组 client 互相配合消费同一个 Stream 的不同部分的消息。
官网 redis stream
官网 redis stream 中文翻译
1.1 写入数据
XADD
向指定的 Stream 追加一个新条目。条目不是一个简单的字符串,而是一个或多个键值对
- 命令的第一个参数是key的名称mystream
- 第二个参数是用于唯一确认Stream中每个条目的条目ID。然而,在这个例子中,我们传入的参数值是*,因为我们希望由Redis服务器为我们自动生成一个新的ID。每一个新的ID都会单调增长,简单来讲就是,每次新添加的条目都会拥有一个比其它所有条目更大的ID。由服务器自动生成ID几乎总是我们所想要的,需要显式指定ID的情况非常少见
- 在key和ID后面的参数是组成我们的Stream条目的键值对。
## 调用了XADD命令往名为 mystream 的 Stream 中添加了一个条目 sensor-id: 123, temperature: 19.8
> XADD mystream * sensor-id 1234 temperature 19.8
"1680166855767-0"
> XLEN mystream
(integer) 1
条目 ID 的格式
条目 ID 是
- 其第一部分是 redis server 的当前毫秒时间戳
- 设计理念:因
XRANGE支持按 ID 做范围查询,而用时间戳做 ID 的话即可支持按时间戳的范围查询
- 设计理念:因
- 其第二部分是 序列号,共 64 位足够标识同一毫秒内的各重复数据
XADD 时也可指定条目 ID,但必须单调递增,如下所示:
> XADD somestream 0-1 field value
0-1
> XADD somestream 0-2 foo bar
0-2
> XADD somestream 2-5 a b
2-5
> XADD somestream 0-4 c d # 不接受等于或小于前一个ID的ID
(error) ERR The ID specified in XADD is equal or smaller than the target stream top item
> XADD somestream 1-1 e f # 不接受等于或小于前一个ID的ID
(error) ERR The ID specified in XADD is equal or smaller than the target stream top item
> XADD somestream 2-3 g h # 不接受等于或小于前一个ID的ID
(error) ERR The ID specified in XADD is equal or smaller than the target stream top item
> XADD somestream 2-6 m n
2-6
1.2 获取数据
XRANGE 和 XREVRANGE
可以用 - 表示最小 ID,+ 表示最大 ID 查询:
# 添加第一个元素
127.0.0.1:6379[15]> xrange mystream - +
(empty array)
127.0.0.1:6379[15]> xadd mystream * sensor-id 1234 temperature 19.8
"1680182283373-0"
127.0.0.1:6379[15]> xrange mystream - +
1) 1) "1680182283373-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
# 添加第二个元素
127.0.0.1:6379[15]> xadd mystream * sensor-id 9999 temperature 18.2
"1680182368438-0"
127.0.0.1:6379[15]> xrange mystream - +
1) 1) "1680182283373-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
2) 1) "1680182368438-0"
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
也更常用时间戳查询(可以省略 ID 的序列号部分,仅用时间戳):
127.0.0.1:6379[15]> xrange mystream 1680182283373 1680182368438
1) 1) "1680182283373-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
2) 1) "1680182368438-0"
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
通常,同一个时间戳也可能有很多消息,可通过可选的 count 表示只取几个。应用拿到返回的 ID 后,可再将ID的序列号加1, 并持续拿完所有数据(类似关系数据库的 Limit 和 Offset 分页查询)。XRANGE 查询时间复杂度是 O(log(N)),当 count 较小时速度很快:
# 拿第一条:
127.0.0.1:6379[15]> xrange mystream - + count 1
1) 1) "1680182283373-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
# 将第一条的序列号(1680182368438-0)加一(得到1680182368438-1),并再拿下一条:
127.0.0.1:6379[15]> xrange mystream 1680182283373-1 + count 1
1) 1) "1680182368438-0"
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
# 一次拿完全部的两条:
127.0.0.1:6379[15]> xrange mystream - + count 2
1) 1) "1680182283373-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
2) 1) "1680182368438-0"
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
# 一次拿完全部的三条:
127.0.0.1:6379[15]> xrange mystream - + count 3
1) 1) "1680182283373-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
2) 1) "1680182368438-0"
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
XREVRANGE 是按 XRANGE 的逆序输出,一般用来查 Stream 的最后一项,注意 XREVRANGE 是先 end 再start:
# 查最后一条数据:
127.0.0.1:6379[15]> XREVRANGE mystream + - count 1
1) 1) "1680182368438-0"
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
XREAD 监听新条目
如果不希望查 Stream 中某范围的数据,常见的需求是用 XREAD 订阅到达 Stream 的新项目:
- 一个Stream可以拥有多个客户端(消费者)在等待数据。每一个新项目,都会被分发到等待给定Stream的数据的「每一个」消费者。
- 所有的消息都被无限期地附加到Stream中(除非用户明确地要求删除这些条目):不同的消费者通过记住收到的最后一条消息的ID,从其角度知道什么是新消息。
- Streams 消费者组提供了一种Pub/Sub或者阻塞列表都不能实现的控制级别:同一个Stream不同的群组,显式地确认已经处理的项目,检查待处理的项目的能力,申明未处理的消息,以及每个消费者拥有连贯历史可见性,单个客户端只能查看自己过去的消息历史记录。
非阻塞形式
# XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
# 下文写了STREAMS mystream 0,所以我们想要流 mystream中所有ID大于0-0的消息:
127.0.0.1:6379[15]> xread count 2 streams mystream 0
1) 1) "mystream"
2) 1) 1) "1680182283373-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
2) 1) "1680182368438-0"
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
可以同时消费多个 Stream 的数据:
# 同时从 mystream 的 ID = 0 消费,和otherstream 的 ID = 0 消费
127.0.0.1:6379[15]> XREAD count 2 streams mystream otherstream 0 0
1) 1) "mystream"
2) 1) 1) "1680182283373-0"
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "19.8"
2) 1) "1680182368438-0"
2) 1) "sensor-id"
2) "9999"
3) "temperature"
4) "18.2"
阻塞形式
通过 BLOCK 可变为阻塞模式
- 其中 milliseconds 意为阻塞多少毫秒(0视为永不超时)
XREAD中,$这个特殊的ID 意为 Stream 中已存储的最大ID
# XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
# 因为指定 ID 为 $, 即 Stream 中已存储的最大的 ID, 故含义为仅接收从我们开始监听时间以后的最新消息, 这在某种程度上相似于Unix命令tail -f, 输入后即会阻塞住:
XREAD BLOCK 0 STREAMS mystream $
# 然后用 XADD 写入数据
127.0.0.1:6379[15]> XADD mystream * a a1 b b1
"1680244537654-0"
# 然后刚才阻塞的 XREAD BLOCK 即会输出最新的消息:
127.0.0.1:6379[15]>XREAD BLOCK 0 STREAMS mystream $
1) 1) "mystream"
2) 1) 1) "1680244537654-0"
2) 1) "a"
2) "a1"
3) "b"
4) "b1"
XREAD的阻塞形式同样可以监听多个Stream,只需要指定多个键名即可。如果请求可以同步提供,因为至少有一个流的元素大于我们指定的相应ID,则返回结果。否则,该命令将阻塞并将返回获取新数据的第一个流的项目(根据提供的ID)。
1.3 消费者组
当手头的任务是从不同的客户端消费同一个Stream,那么XREAD已经提供了一种方式可以扇形分发到N个客户端,还可以使用从节点来提供更多的读取可伸缩性。然而,在某些问题中,我们想要做的不是向许多客户端提供相同的消息流,而是从同一流向许多客户端提供不同的消息子集。这很有用的一个明显的例子是处理消息的速度很慢:能够让N个不同的客户端接收流的不同部分,通过将不同的消息路由到准备做更多工作的不同客户端来扩展消息处理工作。
实际上,假如我们想象有三个消费者C1,C2,C3,以及一个包含了消息1, 2, 3, 4, 5, 6, 7 的 Stream,我们想要按如下图表的方式处理消息:
1 -> C1
2 -> C2
3 -> C3
4 -> C1
5 -> C2
6 -> C3
7 -> C1
为了获得这个效果,Redis使用了一个名为消费者组的概念。非常重要的一点是,从实现的角度来看,Redis的消费者组与Kafka ™ 消费者组没有任何关系,它们只是从实施的概念上来看比较相似,所以我决定不改变最初普及这种想法的软件产品已有的术语。
消费者组就像一个伪消费者,从流中获取数据,实际上为多个消费者提供服务,提供某些保证:
- 每条消息都提供给不同的消费者,因此不可能将相同的消息传递给多个消费者。
- 消费者在消费者组中通过名称来识别,该名称是实施消费者的客户必须选择的区分大小写的字符串。这意味着即便断开连接过后,消费者组仍然保留了所有的状态,因为客户端会重新申请成为相同的消费者。 然而,这也意味着由客户端提供唯一的标识符。
- 每一个消费者组都有一个第一个ID永远不会被消费的概念,这样一来,当消费者请求新消息时,它能提供以前从未传递过的消息。
- 消费消息需要使用特定的命令进行显式确认,表示:这条消息已经被正确处理了,所以可以从消费者组中逐出。
- 消费者组跟踪所有当前所有待处理的消息,也就是,消息被传递到消费者组的一些消费者,但是还没有被确认为已处理。由于这个特性,当访问一个Stream的历史消息的时候,每个消费者将只能看到传递给它的消息。
在某种程度上,消费者组可以被想象为关于Stream的一些状态:
| consumer_group_name: mygroup |
| consumer_group_stream: somekey |
| last_delivered_id: 1292309234234-92 |
| |
| consumers: |
| "consumer-1" with pending messages |
| 1292309234234-4 |
| 1292309234232-8 |
| "consumer-42" with pending messages |
| ... (and so forth) |
如果你从这个视角来看,很容易理解一个消费者组能做什么,如何做到向给消费者提供他们的历史待处理消息,以及当消费者请求新消息的时候,是如何做到只发送ID大于last_delivered_id的消息的。同时,如果你把消费者组看成Redis Stream的辅助数据结构,很明显单个Stream可以拥有多个消费者组,每个消费者组都有一组消费者。实际上,同一个Stream甚至可以通过XREAD让客户端在没有消费者组的情况下读取,同时有客户端通过XREADGROUP在不同的消费者组中读取
现在是时候放大来查看基本的消费者组命令了,具体如下:
- XGROUP 用于创建,摧毁或者管理消费者组
- XREADGROUP 用于通过消费者组从一个Stream中读取
- XACK 是允许消费者将待处理消息标记为已正确处理的命令
XGROUP 创建消费者组
# XGROUP[CREATE key groupname ID|$ [MKSTREAM]] [SETID key groupname ID|$] [DESTROY key groupname] [CREATECONSUMER key groupname consumername] [DELCONSUMER key groupname consumername]
# 假设我已经存在类型流的 mystream,为了创建消费者组,我只需要做:
# 请注意:目前还不能为不存在的Stream创建消费者组,但有可能在不久的将来我们会给XGROUP命令增加一个选项,以便在这种场景下可以创建一个空的Stream。
> XGROUP CREATE mystream mygroup $
OK
如你所看到的上面这个命令,当创建一个 group 的时候,我们必须指定一个ID,在这个例子中ID是 $。这是必要的,因为 group 在其他状态中必须知道在第一个 consumer 连接时接下来要服务的消息,即 group 创建完成时的最后消息ID是什么?
- 如果我们就像上面例子一样,提供一个 $,那么只有从现在开始到达 Stream 的新消息才会被传递到 group 中的 consumer。
- 如果我们指定的消息 ID 是 0,那么 group 将会开始消费这个 Stream 中的所有历史消息。
- 当然你也可以指定任意其他有效的ID。
- 你所知道的是,group 将开始传递 ID 大于你所指定的ID的消息。因为
$表示 Stream 中当前最大ID的意思,指定 $ 会有只消费新消息的效果。
XREADGROUP 通过消费者组消费
现在消费者组创建好了,我们可以使用XREADGROUP命令立即开始尝试通过消费者组读取消息。我们会从消费者那里读到,假设指定消费者分别是Alice和Bob,来看看系统会怎样返回不同消息给Alice和Bob。
# 首先建流和消费者组:
> XADD mystream * a a1 b b1
OK
> XADD mystream * message abc # 这些在 XGROUP CREATE 之前的消息,mygroup 是消费不到的(无论是XREADGROUP GROUP mygroup Alice COUNT 1 STREAMS mystream > 还是 XREADGROUP GROUP mygroup Alice STREAMS mystream)
OK
> XADD mystream * message abc # 同上:这些在 XGROUP CREATE 之前的消息,mygroup 是消费不到的
OK
> XGROUP CREATE mystream mygroup $ # 同上:这些在 XGROUP CREATE 之前的消息,mygroup 是消费不到的
OK
# 首先写入一些测试数据:
> XADD mystream * message apple
"1680245733808-0"
> XADD mystream * message orange
"1680245739245-0"
> XADD mystream * message strawberry
"1680245743318-0"
> XADD mystream * message apricot
"1680245750800-0"
> XADD mystream * message banana
"1680245754555-0"
插入数据后效果如下:
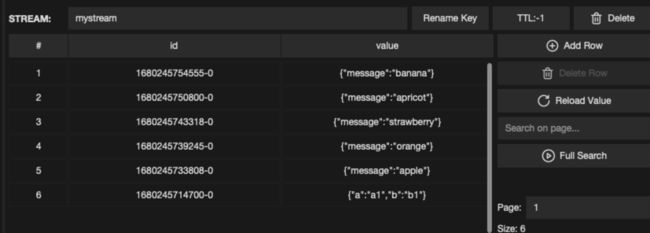
然后用 XREADGROUP 消费数据,多个 consumer 可以共同分摊 group 内的数据,示例如下:
- consumer 是在他们第一次被提及的时候自动创建的,不需要显式创建。
- 即使使用 XREADGROUP,你也可以同时从多个key中读取,但是要让其工作,你需要给每一个Stream创建一个名称相同的消费者组。这并不是一个常见的需求,但是需要说明的是,这个功能在技术上是可以实现的。
- XREADGROUP 命令是一个
写命令,因为当它从Stream中读取消息时,消费者组被修改了,所以这个命令只能在master节点调用。
# XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...]
# 从前向后消费一条数据,即消费到了最早的 {"message": "apple"} 数据
# 指定了名为 mygroup 的 GOURP,指定了名为 Alice 的 consumer,指定了只消费一行,制定了名为 mystream 的流,指定了值为 > 的 ID。
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Alice COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1680246997777-0"
2) 1) "message"
2) "apple"
# 从前向后再消费一条数据,即消费到了次早的 {"message": "orange"} 数据
# 指定了名为 mygroup 的 GOURP,指定了名为 Bob 的 consumer,其他同上,说明 Alice 和 Bob 共同分摊了 mygroup 内的各消息
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Alice COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1680247001033-0"
2) 1) "message"
2) "orange"
# 同样的可以继续消费剩余的数据,直到消费不到数据为止
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Alice COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1680250399517-0"
2) 1) "message"
2) "strawberry"
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Alice COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1680250404185-0"
2) 1) "message"
2) "apricot"
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Bob COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) "1680250407535-0"
2) 1) "message"
2) "banana"
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Bob COUNT 1 STREAMS mystream >
(nil)
从上述代码可看出:> 这个特殊的ID 只在消费者组的上下文中有效,其意思是:消息到目前为止从未传递给其他消费者。
- 这是最常用的。但有副作用:就是会更新消费者组的最后ID。
如果ID是任意其他有效的数字ID,那么将会访问「历史待处理消息」:即传递给这个指定 consumer 的,且到目前为止从未使用XACK进行确认的,消息集。
- 例如指定 ID 为 0,不带任何 COUNT 选项:我们只会看到唯一的待处理消息,即关于apples的消息,示例如下:
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Alice STREAMS mystream 0
1) 1) "mystream"
2) 1) 1) "1680246997777-0"
2) 1) "message"
2) "apple"
2) 1) "1680247001033-0"
2) 1) "message"
2) "orange"
3) 1) "1680247232306-0"
2) 1) "message"
2) "strawberry"
4) 1) "1680247239159-0"
2) 1) "message"
2) "apricot"
5) 1) "1680247243017-0"
2) 1) "message"
2) "banana"
XACK 确认消息
接上文的示例数据,如果通过 XACK 确认此消息,则它将不再是此 group 的「历史待处理消息」。
# XACK key group ID [ID ...]
# 若输入无效的 ID,则会返回 0 表示失败
127.0.0.1:6379[15]> XACK mystream mygroup 3-99
(integer) 0
# 若输入有效的 ID(1680246997777-0 即上文的 {"message": "apple"} 对应的 ID),则会返回 1 表示成功
127.0.0.1:6379[15]> XACK mystream mygroup 1680246997777-0
(integer) 1
# 再查询,即得到尚未 ACK 的剩余四条数据(即没有上文已 ACK 的 {"message": "apple"})
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Alice STREAMS mystream 0
1) 1) "mystream"
2) 1) 1) "1680247001033-0"
2) 1) "message"
2) "orange"
2) 1) "1680247232306-0"
2) 1) "message"
2) "strawberry"
3) 1) "1680247239159-0"
2) 1) "message"
2) "apricot"
4) 1) "1680247243017-0"
2) 1) "message"
2) "banana"
消费者组示例
# ruby 示例:
# 消费历史消息,即我们的待处理消息列表
# 在重新启动时,我们想要重新读取那些已经传递给我们但还没有确认的消息
# 消耗历史消息后,我们将得到一个空的消息列表,我们可以切换到 > ,使用特殊ID来消费新消息。
require 'redis'
if ARGV.length == 0
puts "Please specify a consumer name"
exit 1
end
ConsumerName = ARGV[0]
GroupName = "mygroup"
r = Redis.new
def process_message(id,msg)
puts "[#{ConsumerName}] #{id} = #{msg.inspect}"
end
$lastid = '0-0'
puts "Consumer #{ConsumerName} starting..."
check_backlog = true
while true
# Pick the ID based on the iteration: the first time we want to
# read our pending messages, in case we crashed and are recovering.
# Once we consumer our history, we can start getting new messages.
if check_backlog
myid = $lastid
else
myid = '>'
end
items = r.xreadgroup('GROUP',GroupName,ConsumerName,'BLOCK','2000','COUNT','10','STREAMS',:my_stream_key,myid)
if items == nil
puts "Timeout!"
next
end
# If we receive an empty reply, it means we were consuming our history
# and that the history is now empty. Let's start to consume new messages.
check_backlog = false if items[0][1].length == 0
items[0][1].each{|i|
id,fields = i
# Process the message
process_message(id,fields)
# Acknowledge the message as processed
r.xack(:my_stream_key,GroupName,id)
$lastid = id
}
end
1.4 XPENDING 和 XCLAIM 认领 其他消费者 的待处理消息
上面的例子允许我们编写多个消费者参与同一个消费者组,每个消费者获取消息的一个子集进行处理,并且在故障恢复时重新读取各自的待处理消息。
然而在现实世界中,消费者有可能永久地失败并且永远无法恢复。由于任何原因停止后,消费者的待处理消息会发生什么呢?
Redis的消费者组提供了一个专门针对这种场景的特性,用以认领给定消费者的待处理消息,这样一来,这些消息就会改变他们的所有者,并且被重新分配给其他消费者。这个特性是非常明确的,消费者必须检查待处理消息列表,并且必须使用特殊命令来认领特定的消息,否则服务器将把待处理的消息永久分配给旧消费者,这样不同的应用程序就可以选择是否使用这样的特性,以及使用它的方式。
XPENDING
这个过程的第一步是使用一个叫做XPENDING的命令,这个命令提供 group 中待处理条目的可观察性。这是一个只读命令,它总是可以安全地调用,不会改变任何消息的所有者。
- 在最简单的形式中,调用这个命令只需要两个参数,即 Stream 的名称和 group 的名称。当以这种方式调用的时候,命令只会输出给定group 的待处理消息总数(在本例中是两条消息),所有待处理消息中的最小和最大的ID,最后是消费者列表和每个消费者的待处理消息数量。我们只有Bob有两条待处理消息,因为Alice请求的唯一一条消息已使用XACK确认了
# XPENDING key group [[IDLE min-idle-time] start end count [consumer]]
# 首先查看已有的数据:
127.0.0.1:6379[15]> XREADGROUP GROUP mygroup Alice STREAMS mystream 0
1) 1) "mystream"
2) 1) 1) "1680250658661-0"
2) 1) "message"
2) "apple"
2) 1) "1680250661799-0"
2) 1) "message"
2) "orange"
3) 1) "1680250666057-0"
2) 1) "message"
2) "strawberry"
4) 1) "1680250669555-0"
2) 1) "message"
2) "apricot"
5) 1) "1680250673185-0"
2) 1) "message"
2) "banana"
# 用 XPENDING:结果返回了 第一条待处理消息"1680250658661-0"(即最小 ID 的待处理消息) 和 最后一条消息"1680250673185-0"(即最大 ID 的待处理消息),和待处理消息的总数
127.0.0.1:6379[15]> XPENDING mystream mygroup
1) (integer) 5
2) "1680250658661-0"
3) "1680250673185-0"
4) 1) 1) "Alice" # 意为我们只有 Alice 有 5 条待处理消息,因为测试数据中 Bob 的消息都已 XACK 了
2) "5"
- 也可以用 - 表示 开始 ID,+ 表示 结束 ID,和一个返回信息的数量,示例如下:
# 下例查出了每条消息的详细信息:消息ID,消费者名称,空闲时间(单位是毫秒,意思是:自上次将消息传递给某个消费者以来经过了多少毫秒),以及每一条给定的消息被传递了多少次。我们有来自Alice的五条消息,它们空闲了2813853毫秒,大概46min。
127.0.0.1:6379[15]> XPENDING mystream mygroup - + 10
1) 1) "1680250658661-0"
2) "Alice"
3) (integer) 2813853
4) (integer) 2
2) 1) "1680250661799-0"
2) "Alice"
3) (integer) 2813853
4) (integer) 2
3) 1) "1680250666057-0"
2) "Alice"
3) (integer) 2813853
4) (integer) 2
4) 1) "1680250669555-0"
2) "Alice"
3) (integer) 2813853
4) (integer) 2
5) 1) "1680250673185-0"
2) "Alice"
3) (integer) 2813853
4) (integer) 2
XCLAIM
现在我们有了一些想法,Bob 可能会根据过了 46min 仍然没有处理这些消息,来判断 Alice 可能无法及时恢复,所以现在是时候认领这些消息,并继续代替 Alice 处理了。为了做到这一点,我们使用 XCLAIM 命令。
# XCLAIM ...
基本上我们说,对于这个特定的Stream和消费者组,我希望指定的ID的这些消息可以改变他们的所有者,并将被分配到指定的消费者。
但是,我们还提供了最小空闲时间,因此只有在上述消息的空闲时间大于指定的空闲时间时,操作才会起作用。这很有用,因为有可能两个客户端会同时尝试认领一条消息:
Client 1: XCLAIM mystream mygroup Alice 3600000 1526569498055-0
Clinet 2: XCLAIM mystream mygroup Lora 3600000 1526569498055-0
然而认领一条消息的副作用是会重置它的闲置时间!并将增加其传递次数的计数器,所以上面第二个客户端的认领会失败。通过这种方式,我们可以避免对消息进行简单的重新处理(即使是在一般情况下,你仍然不能获得准确的一次处理)。下面是命令执行的结果:
> XCLAIM mystream mygroup Alice 3600000 1526569498055-0
1) 1) 1526569498055-0
2) 1) "message"
2) "orange"
Alice成功认领了该消息,现在可以处理并确认消息,尽管原来的消费者还没有恢复,也能往前推动。
从上面的例子很明显能看到,作为成功认领了指定消息的副作用,XCLAIM命令也返回了消息数据本身。但这不是强制性的。可以使用JUSTID选项,以便仅返回成功认领的消息的ID。如果你想减少客户端和服务器之间的带宽使用量的话,以及考虑命令的性能,这会很有用,并且你不会对消息感兴趣,因为稍后你的消费者的实现方式将不时地重新扫描历史待处理消息。
认领也可以通过一个独立的进程来实现:这个进程只负责检查待处理消息列表,并将空闲的消息分配给看似活跃的消费者。可以通过Redis Stream的可观察特性获得活跃的消费者。
1.5 XINFO STREAM 做可观察性
Redis Stream和消费者组都有不同的方式来观察正在发生的事情。我们已经介绍了XPENDING,它允许我们检查在给定时刻正在处理的消息列表,以及它们的空闲时间和传递次数。
但是,我们可能希望做更多的事情,XINFO命令是一个可观察性接口,可以与子命令一起使用,以获取有关Stream或消费者组的信息。这个命令使用子命令来显示有关Stream和消费者组的状态的不同信息,比如使用 XINFO STREAM 可以报告关于Stream本身的信息。
# 输出显示了有关如何在内部编码Stream的信息,以及显示了Stream的第一条和最后一条消息。
127.0.0.1:6379[15]> XINFO STREAM mystream
1) "length"
2) (integer) 7
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "last-generated-id"
8) "1680250673185-0"
9) "groups"
10) (integer) 1
11) "first-entry"
12) 1) "1680250640641-0"
2) 1) "a"
2) "a1"
3) "b"
4) "b1"
13) "last-entry"
14) 1) "1680250673185-0"
2) 1) "message"
2) "banana"
# 输出 group 的信息
> XINFO GROUPS mystream
1) 1) name
2) "mygroup"
3) consumers
4) (integer) 2
5) pending
6) (integer) 2
2) 1) name
2) "some-other-group"
3) consumers
4) (integer) 1
5) pending
6) (integer) 0
# 输出 consumer 的信息
127.0.0.1:6379[15]> XINFO CONSUMERS mystream mygroup
1) 1) name
2) "Alice"
3) pending
4) (integer) 5
5) "idle"
6) (integer) 4018739
2) 1) name
2) "Bob"
3) pending
4) (integer) 1
5) idle
6) (integer) 83841983
# 记不住命令的话,可以看帮助文档
127.0.0.1:6379[15]> XINFO HELP
1) XINFO <subcommand> [<arg> [value] [opt] ...]. Subcommands are:
2) CONSUMERS <key> <groupname>
3) Show consumers of <groupname>.
4) GROUPS <key>
5) Show the stream consumer groups.
6) STREAM <key> [FULL [COUNT <count>]
7) Show information about the stream.
8) HELP
9) Prints this help.
1.6 和 Kafka 的差别
Redis Stream的消费者组可能类似于基于Kafka(TM)分区的消费者组,但是要注意Redis Stream实际上非常不同。分区仅仅是逻辑的,并且消息只是放在一个Redis键中,因此不同客户端的服务方式取决于谁准备处理新消息,而不是从哪个分区客户端读取。例如,如果消费者C3在某一点永久故障,Redis会继续服务C1和C2,将新消息送达,就像现在只有两个逻辑分区一样。
类似地,如果一个给定的消费者在处理消息方面比其他消费者快很多,那么这个消费者在相同单位时间内按比例会接收更多的消息。这是有可能的,因为Redis显式地追踪所有未确认的消息,并且记住了谁接收了哪些消息,以及第一条消息的ID从未传递给任何消费者。
但是,这也意味着在Redis中,如果你真的想把同一个Stream的消息分区到不同的Redis实例中,你必须使用多个key和一些分区系统,比如Redis集群或者特定应用程序的分区系统。单个Redis Stream不会自动分区到多个实例上。
我们可以说,以下是正确的:
- 如果你使用一个Stream对应一个消费者,则消息是按顺序处理的。
- 如果你使用N个Stream对应N个消费者,那么只有给定的消费者hits N个Stream的子集,你可以扩展上面的模型来实现。
- 如果你使用一个Stream对应多个消费者,则对N个消费者进行负载平衡,但是在那种情况下,有关同一逻辑项的消息可能会无序消耗,因为给定的消费者处理消息3可能比另一个消费者处理消息4要快。
所以基本上Kafka分区更像是使用了N个不同的Redis键。而Redis消费者组是一个将给定Stream的消息负载均衡到N个不同消费者的服务端负载均衡系统。
1.7 MAXLEN 设置最多消息条数
许多应用并不希望将数据永久收集到一个Stream。有时在Stream中指定一个最大项目数很有用,之后一旦达到给定的大小,将数据从Redis中移到不那么快的非内存存储是有用的,适合用来记录未来几十年的历史数据。Redis Stream对此有一定的支持。
当Stream的达到指定长度后,老的条目会自动被驱逐,因此Stream的大小是恒定的。
# 第一次设置:
127.0.0.1:6379[15]> XADD mystream MAXLEN 2 * a b
"1680255617283-0"
127.0.0.1:6379[15]> XLEN mystream
(integer) 1
127.0.0.1:6379[15]> XRANGE mystream - +
1) 1) "1680255617283-0"
2) 1) "a"
2) "b"
# 第二次设置:
127.0.0.1:6379[15]> XADD mystream MAXLEN 2 * c d
"1680255655998-0"
127.0.0.1:6379[15]> XLEN mystream
(integer) 2
127.0.0.1:6379[15]> XRANGE mystream - +
1) 1) "1680255617283-0"
2) 1) "a"
2) "b"
2) 1) "1680255655998-0"
2) 1) "c"
2) "d"
# 第三次设置: 当Stream的达到指定长度后,老的条目会自动被驱逐,因此Stream的大小是恒定的。
127.0.0.1:6379[15]> XADD mystream MAXLEN 2 * e f
"1680255693466-0"
127.0.0.1:6379[15]> XLEN mystream
(integer) 2
127.0.0.1:6379[15]> XRANGE mystream - +
1) 1) "1680255655998-0"
2) 1) "c"
2) "d"
2) 1) "1680255693466-0"
2) 1) "e"
2) "f"
也可以修改 MAXLEN,但为了省内存,内部是用 radix tree 实现的,所以时间复杂度较高:因为 Stream由宏节点表示为 radix tree,以便非常节省内存。改变由几十个元素组成的单个宏节点不是最佳的。因此可以使用以下特殊形式提供命令:
~的意思是,我不是真的需要精确的1000个项目。它可以是1000或者1010或者1030,只要保证至少保存1000个项目就行。通过使用这个参数,仅当我们移除整个节点的时候才执行修整。这使得命令更高效,而且这也是我们通常想要的。
127.0.0.1:6379[15]> xadd mystream maxlen ~ 1000 * x y
"1680256763146-0"
127.0.0.1:6379[15]> XLEN mystream
(integer) 3
127.0.0.1:6379[15]> XRANGE mystream - +
1) 1) "1680255655998-0"
2) 1) "c"
2) "d"
2) 1) "1680255693466-0"
2) 1) "e"
2) "f"
3) 1) "1680256763146-0"
2) 1) "x"
2) "y"
- XTRIM 效果一样:
# XTRIM key MAXLEN|MINID [=|~] threshold [LIMIT count]
127.0.0.1:6379[15]> xtrim mystream maxlen 10
(integer) 0
127.0.0.1:6379[15]> xtrim mystream maxlen ~ 10 # 和上一个命令效果一样
(integer) 0
1.8 XDEL 删除数据
一般来讲,对于一个只附加的数据结构来说,这也许看起来是一个奇怪的特征,但实际上它对于涉及例如隐私法规的应用程序是有用的。
但是在当前的实现中,在宏节点完全为空之前,内存并没有真正回收,所以你不应该滥用这个特性。
# XDEL key ID [ID ...]
127.0.0.1:6379[15]> XRANGE mystream - +
1) 1) "1680255655998-0"
2) 1) "c"
2) "d"
2) 1) "1680255693466-0"
2) 1) "e"
2) "f"
3) 1) "1680256763146-0"
2) 1) "x"
2) "y"
127.0.0.1:6379[15]> XDEL mystream 1680255693466-0
(integer) 1
127.0.0.1:6379[15]> XRANGE mystream - +
1) 1) "1680255655998-0"
2) 1) "c"
2) "d"
2) 1) "1680256763146-0"
2) 1) "x"
2) "y"
1.9 允许存在零长度 Stream
Stream与其他Redis数据结构有一个不同的地方在于
- 当其他数据结构没有元素的时候,调用删除元素的命令会把key本身删掉。举例来说就是,当调用ZREM命令将有序集合中的最后一个元素删除时,这个有序集合会被彻底删除。
- 但Stream允许在没有元素的时候仍然存在,不管是因为使用 MAXLEN 选项的时候指定了count为零(在XADD和XTRIM命令中),或者因为调用了 XDEL 命令。
存在这种不对称性的原因是因为,Stream可能具有相关联的消费者组,以及我们不希望因为Stream中没有项目而丢失消费者组定义的状态。当前,即使没有相关联的消费者组,Stream也不会被删除,但这在将来有可能会发生变化。
1.10 示例
同时操作多个 Stream 是互不干扰的,示例如下:
# 用法
XADD 或 XGROUP MKSTREAM 或 # 生产者 生产
XGROUP CREATE stream1 mygroup $ # pimpst 创建 group
XREADGROUP group mygroup c STREAMS stream1 # pimpst 用 group 的方式消费
# 示例
# stream1
127.0.0.1:6379[15]> XADD stream1 * a b c d # 生产者 生产
127.0.0.1:6379[15]> XRANGE stream1 - + # 观察一下
1) 1) "1680258376129-0"
2) 1) "a"
2) "b"
3) "c"
4) "d"
127.0.0.1:6379[15]> XGROUP CREATE stream1 g $ # 创建消费者组
OK
127.0.0.1:6379[15]> XREADGROUP group g c STREAMS stream1 > # 消费,没消费到(因为只消费建组后的数据)
(nil)
127.0.0.1:6379[15]> XADD stream1 * e f g h # 生产者 生产
127.0.0.1:6379[15]> XRANGE stream1 - + # 观察一下
1) 1) "1680258376129-0"
2) 1) "a"
2) "b"
3) "c"
4) "d"
2) 1) "1680258824369-0"
2) 1) "e"
2) "f"
3) "g"
4) "h"
127.0.0.1:6379[15]> XREADGROUP group g c STREAMS stream1 > # 消费,消费到了
1) 1) "stream1"
2) 1) 1) "1680258824369-0"
2) 1) "e"
2) "f"
3) "g"
4) "h"
# stream2
127.0.0.1:6379[15]> XADD stream2 * aa bb cc dd
127.0.0.1:6379[15]> XRANGE stream2 - +
1) 1) "1680258995649-0"
2) 1) "aa"
2) "bb"
3) "cc"
4) "dd"
127.0.0.1:6379[15]> XGROUP CREATE stream2 g2 $
OK
127.0.0.1:6379[15]> XREADGROUP group g2 c2 STREAMS stream2 >
(nil)
127.0.0.1:6379[15]> XADD stream2 * ee ff gg hh
"1680259151776-0"
127.0.0.1:6379[15]> XRANGE stream2 - +
1) 1) "1680258995649-0"
2) 1) "aa"
2) "bb"
3) "cc"
4) "dd"
2) 1) "1680259109424-0"
2) 1) "aa"
2) "bb"
3) "cc"
4) "dd"
3) 1) "1680259151776-0"
2) 1) "ee"
2) "ff"
3) "gg"
4) "hh"
127.0.0.1:6379[15]> XREADGROUP group g2 c2 STREAMS stream2 >
1) 1) "stream2"
2) 1) 1) "1680259151776-0"
2) 1) "ee"
2) "ff"
3) "gg"
4) "hh"
二、String
MGET
MGET 就是多键版本的 GET 命令,其接受一个或多个字符串键作为参数,并返回这些字符串键的值。因为执行多个命令只需通信一次,故提升了性能。
MGET key [key ..]
MGET 结果是保序的(即和执行命令的键的顺序一致):例如结果的第一项对应第一个键,结果的第二项对应对应第二个键,示例如下:
127.0.0.1:6379[3]> SET message hi
OK
127.0.0.1:6379[3]> SET number 99
OK
127.0.0.1:6379[3]> SET homepage http://google.com
OK
127.0.0.1:6379[3]> MGET message number homepage
1) "hi"
2) "99"
3) "http://google.com"
查询不存在的 key 时,会返回 nil
127.0.0.1:6379[3]> MGET not-exists-key
1) (nil)
三、运维
redis-cli -h 127.0.0.1 -p 6379 -a mypass
127.0.0.1:6379> auth mypass
127.0.0.1:6379> select 0 # 选第 0 个库
127.0.0.1:6379> keys * # 查所有的键
3.1 内存
- WARNING:The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
编辑/etc/sysctl.conf文件,添加net.core.somaxconn = 1024
然后执行sysctl -p命令查看是否添加成功,之后重启Redis服务即可
若redis重启失败,则rm /home/satafs/dump.rdb, 再重启redis
3.2 批量操作
3.2.1 批量删除
./redis-cli -a mypass -n 3 keys "mykeys*" | xargs ./redis-cli -a mypass -n 3 del
四、Command
4.1 Scan
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
和 Scan 相关的还有如下:
- SCAN:iterates the set of keys in the currently selected Redis database.
- SSCAN:iterates elements of Sets types.
- HSCAN:iterates fields of Hash types and their associated values.
- ZSCAN:iterates elements of Sorted Set types and their associated scores.
因为 Scan 是迭代式获取数据,不像 KEYS 或 SMEMBERS 可能会使单线程的 Redis 阻塞,所以在生产环境可以放心使用。
参数:因为 Scan 获取的是整个 DB 的各 keys,所以不需要任何参数。
返回值:第一个返回值是 cursor(一个数字),第二个返回值是元素数组。
默认值:默认 COUNT 是 10
## 例1: 只写入了 5 个元素,而默认 count 是 10, 则返回 5 个元素
127.0.0.1:6379[5]> MSET k1 1 k2 1 k3 1 k4 1 k5 1
OK
127.0.0.1:6379[5]> KEYS *
1) "k5"
2) "k2"
3) "k1"
4) "k3"
5) "k4"
127.0.0.1:6379[5]> SCAN 0
1) "0"
2) 1) "k5"
2) "k1"
3) "k2"
4) "k3"
5) "k4"
## 例2: 写入了 23 个元素,而默认 count 是 10, 则分三次迭代可返回所有元素(先 10 个、再 10 个、再 3 个)
127.0.0.1:6379[5]> FLUSHDB
127.0.0.1:6379[5]> MSET k1 1 k2 1 k3 1 k4 1 k5 1 k6 1 k7 1 k8 1 k9 1 k10 1 k11 1 k12 1 k13 1 k14 1 k15 1 k16 1 k17 1 k18 1 k19 1 k20 1 k21 1 k22 1 k23 1
OK
127.0.0.1:6379[5]> KEYS *
1) "k5"
2) "k16"
3) "k17"
4) "k20"
5) "k6"
6) "k3"
7) "k13"
8) "k8"
9) "k4"
10) "k12"
11) "k15"
12) "k10"
13) "k14"
14) "k22"
15) "k19"
16) "k18"
17) "k11"
18) "k7"
19) "k2"
20) "k21"
21) "k9"
22) "k23"
23) "k1"
127.0.0.1:6379[5]> SCAN 0
1) "6" # 因为第一次返回了 cursor=6
2) 1) "k5" # PS: 神奇的没有按默认值返回了 11 条
2) "k14"
3) "k20"
4) "k6"
5) "k15"
6) "k23"
7) "k1"
8) "k16"
9) "k12"
10) "k7"
11) "k2"
127.0.0.1:6379[5]> SCAN 6 # 所以第二次从 cursor = 6 继续拿
1) "7" # 因为第二次返回了 cursor=7
2) 1) "k8"
2) "k10"
3) "k22"
4) "k19"
5) "k11"
6) "k3"
7) "k13"
8) "k17"
9) "k18"
10) "k21"
11) "k9"
127.0.0.1:6379[5]> SCAN 7 # 所以第二次从 cursor = 7 继续拿
1) "0" # 因为第三次返回了 cursor=0, 说明拿完了
2) 1) "k4"
# 例3: 手动指定 COUNT
127.0.0.1:6379[5]> FLUSHDB
127.0.0.1:6379[5]> MSET k1 1 k2 1 k3 1 k4 1 k5 1 k6 1 k7 1 k8 1 k9 1 k10 1 k11 1 k12 1 k13 1 k14 1 k15 1 k16 1 k17 1 k18 1 k19 1 k20 1 k21 1 k22 1 k23 1
127.0.0.1:6379[5]> SCAN 0 COUNT 20
1) "11"
2) 1) "k5"
2) "k14"
3) "k20"
4) "k6"
5) "k15"
6) "k23"
7) "k1"
8) "k16"
9) "k12"
10) "k7"
11) "k2"
12) "k8"
13) "k10"
14) "k22"
15) "k19"
16) "k11"
17) "k3"
18) "k13"
19) "k17"
20) "k18"
127.0.0.1:6379[5]> SCAN 11 COUNT 20
1) "0"
2) 1) "k21"
2) "k9"
3) "k4"
# 例4: 手动指定 MATCH 用于模糊匹配
127.0.0.1:6379[5]> FLUSHDB
127.0.0.1:6379[5]> MSET k1 1 k2 1 k3 1 k4 1 k5 1 k6 1 k7 1 k8 1 k9 1 k10 1 k11 1 k12 1 k13 1 k14 1 k15 1 k16 1 k17 1 k18 1 k19 1 k20 1 k21 1 k22 1 k23 1
127.0.0.1:6379[5]> SCAN 0 MATCH k1* COUNT 20
1) "11"
2) 1) "k14"
2) "k15"
3) "k1"
4) "k16"
5) "k12"
6) "k10"
7) "k19"
8) "k11"
9) "k13"
10) "k17"
11) "k18"
五、golang sdk
go-redis
cli := redis.NewClient()
values, err := cli.MGET(keys...)
ans := make([]int, 0)
for _, v := range values {
vStr, ok := v.(string) // interface{} 转 string
if !ok {continue}
vInt, err := strconv.ParseInt(vStr, 10, 64) // string 转 int
ans = append(ans, vInt)
}