Redis-进阶版-2
Redis-进阶版-2
Redis 与MySQL数据双写一致性工程落地案例
一个问题:如何在MySQL有记录改动了(增删改操作),立刻同步反映到redis?
binglog能够记录MySQL的变更
有一种技术方案,能够监听到mysql的变动且能够通知给redis,类似中介

1、Canal
1.1、canal是什么
Home · alibaba/canal Wiki · GitHubGitHub地址
阿里巴巴 MySQL binlog 增量订阅&消费组件
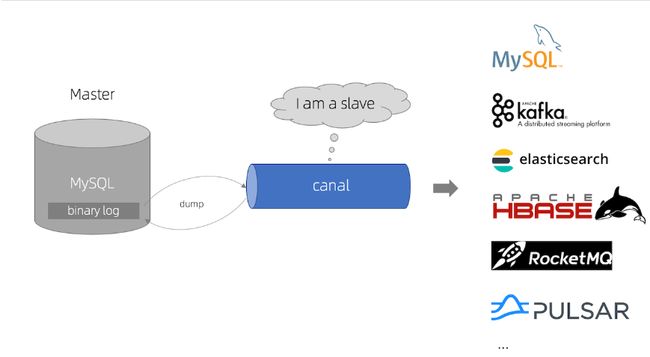
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
1.2、能干什么
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务cache刷新
- 带业务逻辑的增量数据处理
1.3、下载
地址:Release v1.1.6 · alibaba/canal · GitHub
1.4、工作原理
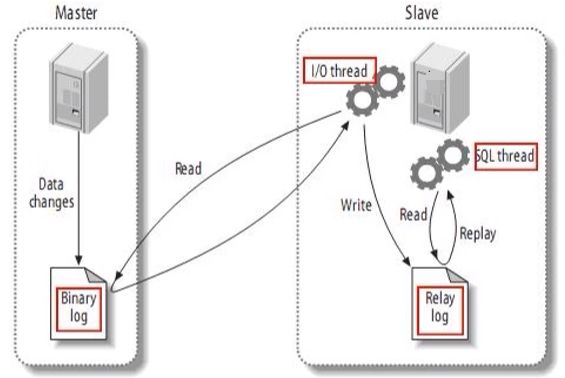
先看一下传统的MySQL主从复制工作原理
步骤详解
- 当master主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
- salve 从服务器会在一定时间间隔内对 master主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到master主服务器的二进制事件日志发生了改变,则开起一个I/O Thread 请求master二进制事件日志;
- 同时 master主服务器为每个IO Thread启动一个dump Thread,用于向其发送二进制事件日志;
- slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
- salve 从服务器将启动SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
canal工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
2、mysql-canal-redis双写一致性Coding
ClientExample · alibaba/canal Wiki · GitHubcanal.exxample
2.1、MySQL
查看一下数据库的主机二进制日志
SHOW MASTER STATUS;

查看当前主机的binlog是否让人查看,默认是关着的
SHOW VARIABLES LIKE 'log_bin';

打开MySQL的安装文件夹,找到my.ini文件,打开添加以下三行
log-bin=mysql-bin #开启
binlogbinlog-format=ROW#选择ROW模式
server_id=1 #配置MySQL replaction需要定义,不要和canal的slaveId重复
ROW模式除了记录sq悟句之外,还会记录每个字段的变化情况,能够清楚的记录每行数据的变化历史,但会占用较多的空间
STATEMENT模式只记录了sql语句,但是没有记录上下文信息,在进行数据恢复的时候可能会导致数据的丢失情况;
MIX模式比较灵活的记录,理论上说当遇到了表结构变更的时候,就会记录为statement模式。当遇到了数据更新或者删除情况下就会变为row模式;
重启MySQL
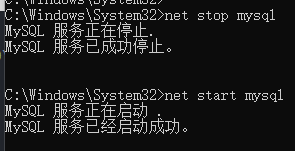
再次查看binlog是否打开让访问
![]()
授权canal连接MySQL账号
mysql默认的用户在mysql库的user表里
SELECT * FROM mysql.`user`;

默认没有canal账户,此处新建+授权
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal';
FLUSH PRIVILEGES;

2.2、canal服务端
下载并解压
下载的是1.1.6的版本
canal.deployer-1.1.6.tar.gz (github.com)
去虚拟机使用wget下载到/mycanal目录下

配置
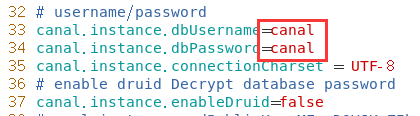
修改/mycanal/conf/example路径下instance.properties文件

instance.properties
-
换成自己的mysql主机master的IP地址

确保能ping的通

-
换成自己的在mysql新建的canal账户
默认的就是canal
启动
在/mycanal/bin下有启动的脚本


查看
在/root/mycanal/logs/canal下有canal.log,使用cat查看一下看是否已经运行

在/mycanal/logs/example下还有example.log查看有成功启动的信息

两个日志文件都显示成功就代表canal客户端启动成功了
2.3、canal客户端(Java编写业务程序)
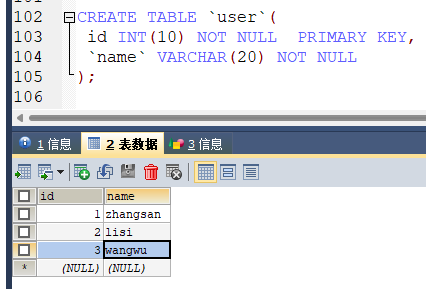
随便找个数据库新建user表
CREATE TABLE `user`(
id INT(10) NOT NULL PRIMARY KEY,
`name` VARCHAR(20) NOT NULL
);
创建一个maven项目(在原来的redis项目上新建的maven模块)
添加canal依赖
<dependency>
<groupId>com.alibaba.ottergroupId>
<artifactId>canal.clientartifactId>
<version>1.1.0version>
dependency>
其他的依赖也想要,数据库、Lombok、德鲁伊等等
创建application.properties
server.port=5555
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/user?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.druid.test-while-idle=false
业务类
RedisUtils
public class RedisUtils {
public static final String REDIS_IP_ADDR= "192.168.111.26";
public static final String REDIS_pwd = "123456";
public static JedisPool jedisPool;
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPool = new JedisPool(jedisPoolConfig, REDIS_IP_ADDR, 6379, 1000, REDIS_pwd);
}
public static Jedis getJedis() throws Exception {
if (jedisPool != null){
return jedisPool.getResource();
}
throw new Exception("Jedispool is ERRO!");
}
}
RediscanalClientExample
public class RediscanalClientExample {
public static final String REDIS_IP_ADDR= "192.168.111.26";
public static final Integer _60SECONDS = 60;
private static void redisInsert(List<CanalEntry.Column> columns){
JSONObject jsonObject = new JSONObject();
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + ":" + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(),column.getValue());
}
if (columns.size() > 0){
try (Jedis jedis = RedisUtils.getJedis()){
jedis.set(columns.get(0).getValue(), jsonObject.toJSONString());
}catch (Exception e){
e.printStackTrace();
}
}
}
private static void redisDelete(List<CanalEntry.Column> columns){
JSONObject jsonObject = new JSONObject();
for (CanalEntry.Column column : columns) {
jsonObject.put(column.getName(),column.getValue());
}
if (columns.size() > 0){
try (Jedis jedis = RedisUtils.getJedis()){
jedis.del(columns.get(0).getValue());
} catch (Exception e) {
e.printStackTrace();
}
}
}
private static void redisUpdate(List<CanalEntry.Column> columns){
JSONObject jsonObject = new JSONObject();
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + ":" + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(),column.getValue());
}
try (Jedis jedis = RedisUtils.getJedis()){
jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());
System.out.println("---------update after:"+jedis.get(columns.get(0).getValue()));
} catch (Exception e) {
e.printStackTrace();
}
}
private static void printEntry(List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys){
//如果这个事件是事务的开始或者事物的结束就continue
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN){
continue;
}
CanalEntry.RowChange rowChange = null;
try {
//获取变更的row数据
rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
//获取变动类型
CanalEntry.EventType eventType = rowChange.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (CanalEntry.RowData rowData : rowChange.getRowDatasList()){
if (eventType == CanalEntry.EventType.INSERT){//增
redisInsert(rowData.getAfterColumnsList());
}else if (eventType == CanalEntry.EventType.DELETE){//删
redisDelete(rowData.getBeforeColumnsList());
}else {//就是改
redisUpdate(rowData.getAfterColumnsList());
}
}
}
}
public static void main(String[] args) {
System.out.println("-------------------o(0_0)o-initCanal()main方法启动------------");
//获取连接创建连接对象,不是redis的ip,而是canal服务的ip。不是随意的端口,而是canal服务的端口,默认是11111
//用户名和密码就是canal配置文件instance.properties中默认的canal,它会去自动读取这里不需要再写
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(REDIS_IP_ADDR, 11111),
"example",
"",
"");
int batchSize = 1000;
//空闲空转计数器
int emptyCount = 0;
System.out.println("-------------------canal init OK,开始监听MySQL变化------------");
try {
connector.connect();
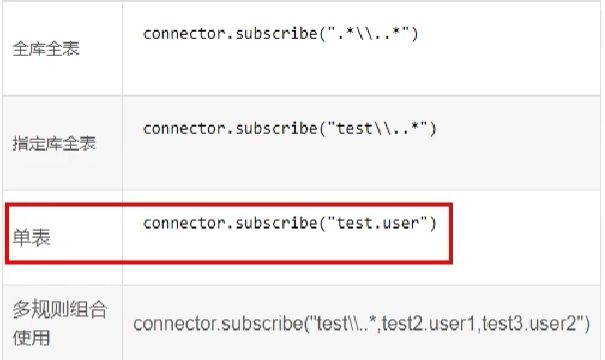
//connector.subscribe(".*\\..*");这个是默认的订阅所有的库表,这里不搞那么多
connector.subscribe("huanyuan.user");
connector.rollback();
int totalEmptyCount = 10 * _60SECONDS;//10分钟的监听
while (emptyCount < totalEmptyCount){
System.out.println("我是canal,每秒一次正在监听(流水号):"+ UUID.randomUUID().toString());
//获取指定数量的数据
Message message = connector.getWithoutAck(batchSize);
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0){//没有变动
emptyCount++;
try {
TimeUnit.SECONDS.sleep(1);
}catch (InterruptedException e){e.printStackTrace();}
}else {
//只要MySQL有变动了,代表batchid不等于-1 size也不是0,那就把计数器重置
emptyCount = 0;
printEntry(message.getEntries());
}
//提交确认
connector.ack(batchId);
//处理失败,回滚数据
//connector.rollback(batchId);
}
System.out.println("已经监听了"+totalEmptyCount+"秒,无任何消息,请重启重试.......");
}finally {
connector.disconnect();
}
}
}
启动

就行增删改查操作,到redis中查看效果




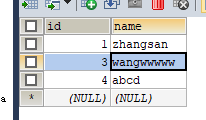
案例落地实战bitmap/hyperloglog/GEO
1、面试题,需求
- 抖音电商直播,主播介绍的商品有评论,1个商品对应了1系列的评论,排序+展现+取前10条记录
- 用户在手机App上的签到打卡信息:1天对应1系列用户的签到记录,新浪微博、钉钉打卡签到,来没来如何统计?
- 应用网站上的网页访问信息∶1个网页对应1系列的访问点击,淘宝网首页,每天有多少人浏览首页?
- 你们公司系统上线后,说一下UV、PV、DAU分别是多少?
亿级数据的收集+清洗+统计+展现
2、统计的类型有哪些
亿级系统中常见的四种统计
聚合统计
统计多个集合元素的聚合结果,就是之前的交差并等集合统计
命令:
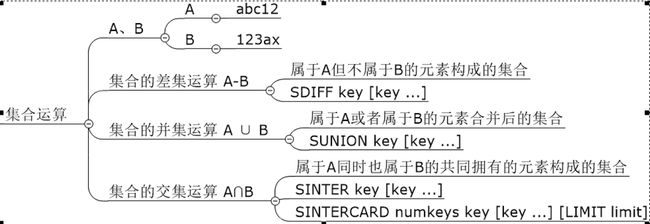
应用:qq中可能认识的人,好友的推广
排序统计
抖音短视频最新评论留言的场景,请你设计一个展现列表。考察你的数据结构和设计思路
能够排序+分页显示的redis数据结构是什么合适?
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议使用ZSet

二值统计
0 和1 bitmap
集合元素的取值就只有0和1两种。在钉钉上班签到打卡的场景中,我们只用记录有签到⑴或没签到0)
基数统计
去重统计
3、HyPerLogLog
名词
-
UV
Unique Visitor,独立访客,一般理解为客户端IP ,需要去重考虑
-
PV
Page View,页面浏览量
不用去重 -
DAU
Daily Active User
日活跃用户量
登录或者使用了某个产品的用户数(去重复登录的用户)
常用于反映网站、互联网应用或者网络游戏的运营情况
-
MAV
Monthly Active User
月活跃用户量
看需求:
很多计数类场景,比如每日注册IP数、每日访问IP数、页面实时访问数PV、访问用户数UV等。因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。
也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。大差不差就行了
统计单日一个页面的访问量(PV),单次访问就算一次。
统计单日一个页面的用户访问量(UV),即按照用户为维度计算,单个用户一天内多次访问也只算一次。多个key的合并统计,某个门户网站的所有模块的PV聚合统计就是整个网站的总PV。
基本的命令
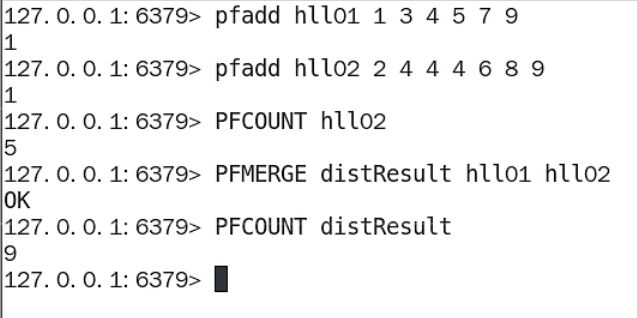
在Java中最能想到的就是HashSet,Redis中有bitmap
概率算法
通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,由于又不储存数据故此可以大大节约内存。
HyperLogLog就是一种概率算法的实现。
HyperLogLog原理
只是进行不重复的基数统计,不是集合也不保存数据,只记录数量而不是具体内容。
他是有误差的,牺牲准确率来换取空间,误差仅仅只是0.81%左右

模拟淘宝网站首页亿级UV的Redis统计方案
需求:
- UV的统计需要去重,一个用户一天内的多次访问只能算作一次
- 淘宝、天猫首页的UV,平均每天是1~1.5个亿左右
- 每天存1.5个亿的IP,访问者来了后先去查是否存在,不存在加入
-
用redis的hash结构存储
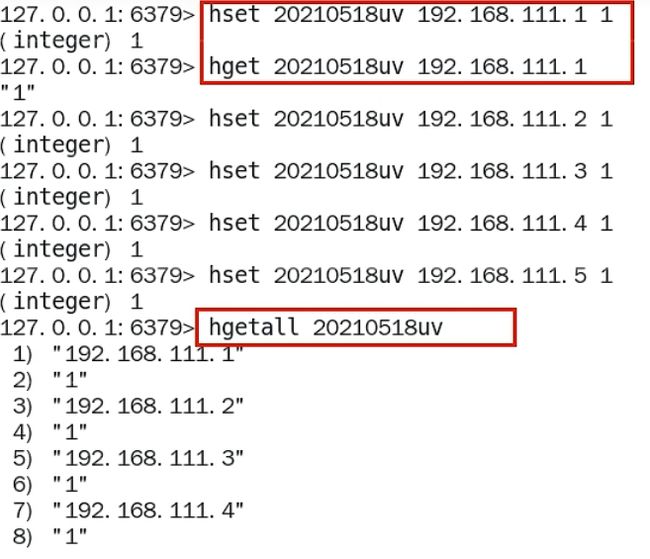
说明,redis—hash =
按照IP v4结构来说,每一个IP v4的地址最多是15个字节
某一天的1.5忆 * 15字节= 2G 那一个月就是60G,redis就炸了
-
HyPerLogLog
HyPerLogLogService
@Service public class HyPerLogLogService { @Resource private RedisTemplate redisTemplate; //模拟后台用户点击淘宝,每一个用户来自不同的IP地址 @PostConstruct public void initIP(){ new Thread(()->{ String ip = null; for (int i = 0; i < 200; i++) { Random random = new Random(); ip = random.nextInt(256) + "." + random.nextInt(256) + "." + random.nextInt(256) + "." + random.nextInt(256); Long hll = redisTemplate.opsForHyperLogLog().add("hll", ip); System.out.println("IP----->" + ip + "次数----->" + hll); //暂停三秒 try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); } } },"t1").start(); } public long uv(){ //PFCOUNT var return redisTemplate.opsForHyperLogLog().size("hll"); } }HyPerLogLogController
@Api(tags = "模拟淘宝忆级UV的Redis统计方案") @RestController public class HyPerLogLogController { @Resource HyPerLogLogService hyPerLogLogService; @ApiOperation("获得去重后的UV统计访问量") @RequestMapping("/uv") public long uv(){ return hyPerLogLogService.uv(); } }
4、GEO
面试题
移动互联网时代LBS应用越来越多,交友软鹤中附近的小姐姐、外卖软件中附近的美食店铺、打车软件附近的车辆等等。那这种附近各种形形色色的XXX地址位置选择是如何实现的?
会出现的问题
1.查询性能问题,如果并发高,数据量大这种查询是要搞垮mysql数据库的
2.一般mysql查询的是一个平面矩形访问,而叫车服务要以我为中心N公里为半径的圆形覆盖。
3.精准度的问题,我们知道地球不是平面坐标系,而是一个圆球,这种矩形计算在长距离计算时会有很大误差,mysql不合适
GEO的命令
-
GEOADD添加经纬度坐标
-
GEOPOS返回经纬度
-
GEOHASH返回坐标的geohash表示
-
GEODIST两个位置之间距离
-
GEORADIUS用的最多
georadius 以给定的经纬度为中心,返回键包含的位置元素当中,与中心的距离不超过给定最大距离的所有位置元素。
-
WITHDIST:在返回位置元素的同时,将位置元素与中心之间的距离也一并返回。距离的单位和用户给定的范围单位保持一致。
-
WITHCOORD:将位置元素的经度和维度也一并返回。
-
WITHASH:以.52位有符号整数的形式,返回位置元素经过原始 geohash编码的有序集合分值。这个选项主要用于底层应用或者调试,实际中的作用并不大
-
COUNT限定返回的记录数。
-
-
GEORADIUSBYMEMBER
美团地图位置附近的酒店推送
关键命令:GEORADIUS 以给定的经纬度为中心,找出某一半径内的元素
GeoController
@Api(tags = "美团地图位置附近的酒店推送GEO")
@RestController
@Slf4j
public class GeoController
{
@Resource
private GeoService geoService;
@ApiOperation("添加坐标geoadd")
@RequestMapping(value = "/geoadd",method = RequestMethod.GET)
public String geoAdd()
{
return geoService.geoAdd();
}
@ApiOperation("获取经纬度坐标geopos")
@RequestMapping(value = "/geopos",method = RequestMethod.GET)
public Point position(String member)
{
return geoService.position(member);
}
@ApiOperation("获取经纬度生成的base32编码值geohash")
@RequestMapping(value = "/geohash",method = RequestMethod.GET)
public String hash(String member)
{
return geoService.hash(member);
}
@ApiOperation("获取两个给定位置之间的距离")
@RequestMapping(value = "/geodist",method = RequestMethod.GET)
public Distance distance(String member1, String member2)
{
return geoService.distance(member1,member2);
}
@ApiOperation("通过经度纬度查找北京王府井附近的")
@RequestMapping(value = "/georadius",method = RequestMethod.GET)
public GeoResults radiusByxy()
{
return geoService.radiusByxy();
}
@ApiOperation("通过地名查找附近")
@RequestMapping("/radiusByName")
public GeoResults radiusByName(String name){
return geoService.radiusByName(name);
}
}
GeoService
@Service
@Slf4j
public class GeoService
{
public static final String CITY ="city";
@Autowired
private RedisTemplate redisTemplate;
public String geoAdd()
{
Map<String, Point> map = new HashMap<>();
map.put("天安门",new Point(116.403963,39.915119));
map.put("故宫",new Point(116.403414,39.924091));
map.put("长城",new Point(116.024067,40.362639));
redisTemplate.opsForGeo().add(CITY,map);
return map.toString();
}
public Point position(String member) {
//获取经纬度坐标
List<Point> list = redisTemplate.opsForGeo().position(CITY, member);
return list.get(0);
}
public String hash(String member) {
//geohash算法生成的base32编码值
List<String> list = redisTemplate.opsForGeo().hash(CITY, member);
return list.get(0);
}
public Distance distance(String member1, String member2) {
//获取两个给定位置之间的距离
Distance distance = redisTemplate.opsForGeo().distance(CITY, member1, member2,
RedisGeoCommands.DistanceUnit.KILOMETERS);
return distance;
}
public GeoResults radiusByxy() {
//通过经度,纬度查找附近的,北京王府井位置116.418017,39.914402
Circle circle = new Circle(116.418017, 39.914402, Metrics.KILOMETERS.getMultiplier());
// 返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortDescending().limit(50);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults = redisTemplate.opsForGeo().radius(CITY, circle, args);
return geoResults;
}
//类似的通过地名查找附近
public GeoResults radiusByName(String name){
Point position = position(name);
Circle circle = new Circle(position, Metrics.KILOMETERS.getMultiplier());
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().limit(20);
GeoResults<RedisGeoCommands.GeoLocation<String>> radius = redisTemplate.opsForGeo().radius(CITY, circle, args);
return radius;
}
}
5、bitmap
面试题
- 日活统计
- 连续签到打卡
- 最近一周的活跃用户
- 统计指定用户一年之中的登陆天数
- 某用户按照一年365天,哪几天登陆过?哪几天没有登陆?全年中登录的天数一共多少?
bitmap就是由O和1状态表现的二进制位的bit数组

布隆过滤器BloomFilter
一些问题
- 现有50亿个电话号码,现有10万个电话号码,
如何要快速准确的判断这些电话号码是否已经存在? - 判断是否存在,布隆过滤器了解过吗?
- 安全连接网址,全球数10亿的网址判断
- 黑名单校验,识别垃圾邮件
- 白名单校验,识别出合法用户进行后续处理
布隆过滤器是干啥的?
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素
布隆过滤器是一种类似set的数据结构,只是统计结果在巨量数据下有点小瑕疵,不够完美
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。
它实际上是一个很长的二进制数组(0000oo00)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为o(n),0(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生

能干什么?
高效地插入和查询,占用空间少,返回的结果是不确定性+不够完美。不保存数据信息,只是在内存中做一个是否存在的标记flag
一个元素如果判断结果:存在时,元素不一定存在,可能有哈希冲突的(不一定这个坑里有多少意思),但是判断结果为不存在时,则一定不存在。
布隆过滤器可以添加元素,但是不能删除元素,由于涉及hashcode判断依据,删掉元素会导致误判率增加。
-
添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
-
查询key时
只要有其中一位匙零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
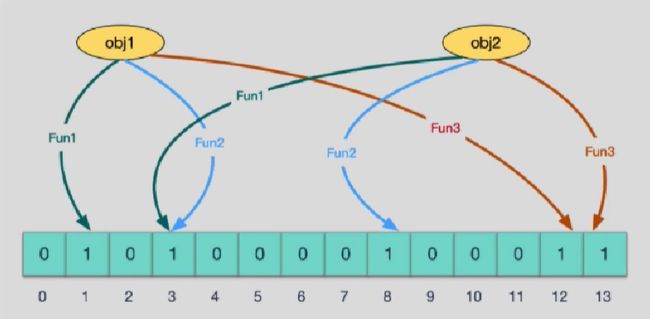
查询某个变量的时候我们只要看看这些点是不是都是1,就可以大概率知道集合中有没有它了,==如果这些点,有任何一个为零则被查询变量一定不在,==如果都是1,则被查询变量很可能存在。
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用再去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询Redis和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。布隆过滤器可以使用Redis实现,本身就能承担较大的并发访问压力。
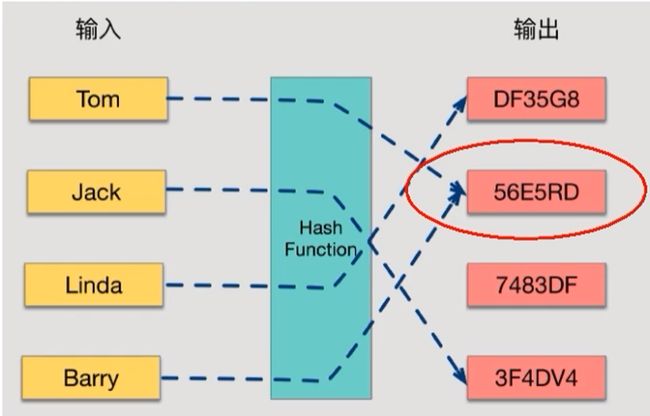
哈希函数的概念
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值。
建议:
- 使用时最好不要让实际元素数量远大于初始化数量,一次给够避免扩容。
- 当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个size更大的过滤器,再将所有的历史元素批量add进行
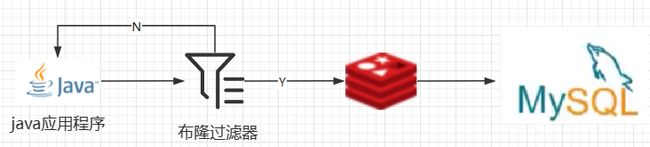
将布隆过滤器放在redis前,请求先在布隆过滤器中查一遍,如果有就可能是有再去redis查,如果没有就是没有直接拦截过滤掉。

布隆过滤器实例
二进制数值构建过程:
1 预加载符合条件的记录
2 计算每条记录的hash值
3 计算hash值对应的bitmap数组位置
4 修改值为1
查找元素的存在过程:
1 计算元素的hash值
2 计算hash值对应二进制数组的位置
3 找到数组中对应位置的值,1就是存在,0就是不存在。
搭建测试环境
-
t_customer用户表SQL
CREATE TABLE t_customer( id INT(20) NOT NULL AUTO_INCREMENT, cname VARCHAR(50) NOT NULL, age INT(10) NOT NULL, phone VARCHAR(20) NOT NULL, sex TINYINT(4) NOT NULL, birth TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (id), KEY idx_cname (cname) );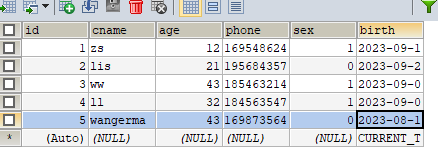
-
建springboot的Module
-
改POM
<dependencies> <dependency> <groupId>org.mybatisgroupId> <artifactId>mybatisartifactId> <version>3.4.6version> dependency> <dependency> <groupId>org.mybatis.spring.bootgroupId> <artifactId>mybatis-spring-boot-starterartifactId> <version>3.0.2version> dependency> <dependency> <groupId>org.mybatis.generatorgroupId> <artifactId>mybatis-generator-coreartifactId> <version>1.4.0version> <scope>compilescope> <optional>trueoptional> dependency> <dependency> <groupId>tk.mybatisgroupId> <artifactId>mapperartifactId> <version>4.2.3version> dependency> <dependency> <groupId>javax.persistencegroupId> <artifactId>persistence-apiartifactId> <version>1.0.2version> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-thymeleafartifactId> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-webartifactId> dependency> <dependency> <groupId>com.mysqlgroupId> <artifactId>mysql-connector-jartifactId> <scope>runtimescope> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> <optional>trueoptional> dependency> <dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-testartifactId> <scope>testscope> dependency> dependencies> -
mgb配置相关src\main\resources路径下新建
-
config.properties
package.name=com.zm jdbc.driverClass = com.mysql.jdbc.Driver jdbc.url = jdbc:mysql://localhost:3306/bigdata jdbc.user = root jdbc.password =123456 -
generatorConfig.xml
DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN" "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd"> <generatorConfiguration> <properties resource="config.properties"/> <context id="Mysql" targetRuntime="MyBatis3Simple" defaultModelType="flat"> <property name="beginningDelimiter" value="`"/> <property name="endingDelimiter" value="`"/> <plugin type="tk.mybatis.mapper.generator.MapperPlugin"> <property name="mappers" value="tk.mybatis.mapper.common.Mapper"/> <property name="caseSensitive" value="true"/> plugin> <jdbcConnection driverClass="${jdbc.driverClass}" connectionURL="${jdbc.url}" userId="${jdbc.user}" password="${jdbc.password}"> jdbcConnection> <javaModelGenerator targetPackage="${package.name}.entities" targetProject="src/main/java"/> <sqlMapGenerator targetPackage="${package.name}.mapper" targetProject="src/main/java"/> <javaClientGenerator targetPackage="${package.name}.mapper" targetProject="src/main/java" type="XMLMAPPER"/> <table tableName="t_customer" domainObjectName="Customer"> <generatedKey column="id" sqlStatement="JDBC"/> table> context> generatorConfiguration>
-
-
一键生成
生成出来的
SpringBoot + Mybatis + Redis缓存实战编码
更改配置文件
server.port=7777
#swagger2
spring.mvc.pathmatch.matching-strategy=ant_path_matcher
#redis单机
spring.redis.database=0
spring.redis.host=192.168.111.26
spring.redis.port=6379
spring.redis.password=123456
spring.redis.lettuce.pool.max-active=8
spring.redis.lettuce.pool.max-wait=-1ms
spring.redis.lettuce.pool.max-idle=8
spring.redis.lettuce.pool.min-idle=0
#==================alibaba.druid================
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/huanyuan?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.druid.test-while-idle=false
# ========================mybatis===================
mybatis.mapper-locations=classpath:mapper/*.xml
mybatis.type-aliases-package=com.zm.entities
在resource目录下新建mapper文件夹,然后复制CustomerMapper.xml
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zm.mapper.CustomerMapper">
<resultMap id="BaseResultMap" type="com.zm.entities.Customer">
<id column="id" jdbcType="INTEGER" property="id" />
<result column="cname" jdbcType="VARCHAR" property="cname" />
<result column="age" jdbcType="INTEGER" property="age" />
<result column="phone" jdbcType="VARCHAR" property="phone" />
<result column="sex" jdbcType="TINYINT" property="sex" />
<result column="birth" jdbcType="TIMESTAMP" property="birth" />
resultMap>
mapper>
将之前一键生成的实体类和mapper复制过来

使用了mybatis在主启动类上添加注解扫描mapper包
@MapperScan("com.zm.mapper")
业务类
CustomerController
@Api(tags = "布隆过滤器的controller")
@RequestMapping
public class CustomerController {
@Resource
private CustomerService customerService;
@ApiOperation("新添加俩数据")
@RequestMapping("/add")
public void addCustomer(){
for (int i = 0; i < 2; i++) {
Customer customer = new Customer();
customer.setCname("customer"+i);
customer.setAge(new Random().nextInt(30)+1);
customer.setPhone("1669238438"+i);
customer.setSex((byte)new Random().nextInt(2));
customer.setBirth(Date.from(LocalDateTime.now().atZone(ZoneId.systemDefault()).toInstant()));
customerService.addCustomer(customer);
}
}
@ApiOperation("通过id查询客户")
@RequestMapping("/getCustomer/{id}")
public Customer getCustomerByID(@PathVariable Integer id){
return customerService.getCustomerByID(id);
}
@ApiOperation("通过id修改数据")
@RequestMapping("/update/{id}")
public void updateCustomer(@PathVariable Integer id){
Customer customer = getCustomerByID(id);
customerService.updateCustomer(customer);
}
@ApiOperation("通过id删除客户")
@RequestMapping("/delete/{id}")
public void deleteCustomer(@PathVariable Integer id){
customerService.deleteCustomer(id);
}
}
CustomerService
@Service
public class CustomerService {
public static final String CHAR_KEY_CUSTOMER = "customer:";
@Resource
private CustomerMapper customerMapper;
@Resource
private RedisTemplate redisTemplate;
//添加数据并写入到redis
public void addCustomer(Customer customer){
int i = customerMapper.insertSelective(customer);
//i>0就代表插入数据库成功可以后续操作
if (i > 0){
String key =CHAR_KEY_CUSTOMER + customer.getId();
//存入redis
redisTemplate.opsForValue().set(key,customerMapper.selectByPrimaryKey(customer.getId()));
}
}
//读操作,要求去redis查的时候没有就去MySQL查,然后把查到的再回写到redis,如果直接有就返回即可
public Customer getCustomerByID(Integer id){
Customer customer = null;
String key = CHAR_KEY_CUSTOMER + id;
customer = (Customer) redisTemplate.opsForValue().get(key);
if (customer == null){
//redis中没有就去查MySQL
customer = customerMapper.selectByPrimaryKey(key);
if (customer != null){
//如果MySQL中有数据就往redis中回写
redisTemplate.opsForValue().set(key,customer);
}
}
return customer;
}
//通过id修改数据
public void updateCustomer(Customer customer){
if (customer != null){
redisTemplate.delete(CHAR_KEY_CUSTOMER+customer.getId());
customer.setCname("updateAfterName");
customer.setPhone("11111111111");
customer.setAge(new Random().nextInt(30)+1);
customer.setBirth(Date.from(LocalDateTime.now().atZone(ZoneId.systemDefault()).toInstant()));
customerMapper.updateByPrimaryKey(customer);
redisTemplate.opsForValue().set(CHAR_KEY_CUSTOMER+customer.getId(),customer);
}
}
//通过id删除
public void deleteCustomer(Integer id){
Customer customer = customerMapper.selectByPrimaryKey(id);
if (customer != null){
int i = customerMapper.delete(customer);
if (i > 0){
redisTemplate.delete(CHAR_KEY_CUSTOMER+id);
}
}
}
}
接下来编写布隆过滤器
BloomFilterInit(白名单)
/*
* 布隆过滤器白名单初始化工具类,
* 一开始就设置一部分数据为白名单所有,
* 白名单业务默认规定:布隆过滤器有,redis是极大可能有。
* 白名单: whitelistcustomer
* */
@Component
public class BloomFilterInit {
@Resource
private RedisTemplate redisTemplate;
//初始化白名单
@PostConstruct
public void init(){
String key = "customer:1";
//计算key的哈希值,由于计算出来的有可能是负数,所以加绝对值
int hashValue = Math.abs(key.hashCode());
//将计算的哈希值与2的32次方取余,获得对应下标坑位
long index = (long)(hashValue % Math.pow(2,32));
System.out.println(key+"对应的坑位index为:"+index);
//设置redis中的bitmap对应的白名单:whiteListCustomer 设置对应坑位的值为1,true
redisTemplate.opsForValue().setBit("whiteListCustomer",index,true);
}
}
CheckUtils 检查单元
@Component
public class CheckUtils {
@Resource
private RedisTemplate redisTemplate;
public boolean checkWithBloomFilter(String checkItem,String key){
int hashValue = Math.abs(key.hashCode());
long index = (long)(hashValue % Math.pow(2,32));
Boolean exisOK = redisTemplate.opsForValue().getBit(checkItem, index);
System.out.println(key+"key的对应下标index为:"+index+"是否存在:"+exisOK);
return exisOK;
}
}
CustomerService 更改
//读操作,要求去redis查的时候没有就去MySQL查,然后把查到的再回写到redis,如果直接有就返回即可
public Customer getCustomerByID(Integer id){
Customer customer = null;
String key = CHAR_KEY_CUSTOMER + id;
//-----------------布隆过滤器白名单检查---------------
if ( !checkUtils.checkWithBloomFilter("whiteListCustomer",key)){
System.out.println("白名单没有此顾客,博不可以访问:"+key);
return null;
}
customer = (Customer) redisTemplate.opsForValue().get(key);
if (customer == null){
//redis中没有就去查MySQL
customer = customerMapper.selectByPrimaryKey(key);
if (customer != null){
//如果MySQL中有数据就往redis中回写
redisTemplate.opsForValue().set(key,customer);
}
}
return customer;
}
CustomerController更改
@ApiOperation("带布隆过滤器的通过id查询客户")
@RequestMapping("/getByBloomFilter/{id}")
public Customer getCustomerByIDBloomFilter(Integer id){
return customerService.getCustomerByIDBloomFilter(id);
}
布隆过滤器的优缺点
优点
高效地插入和查询,内存占用bit空间少
缺点
不能删除元素。
因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的,你删除一个元素的同时可能也把其它的删除了。
存在误判,不能精准过滤
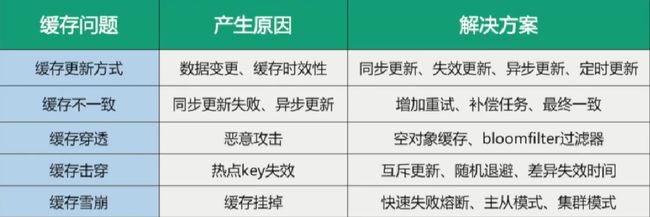
缓存预热+缓存雪崩+缓存击穿+缓存穿透
1、面试题
- 缓存预热、雪崩、穿透、击穿分别是什么?你遇到过那几个情况?
- 缓存预热你是怎么做的?
- 如何避免或者减少缓存雪崩?
- 穿透和击穿有什么区别?他两是一个意思还是截然不同?
- 穿透和击穿你有什么解决方案?如何避免?
- 假如出现了缓存不一致,你有哪些修补方案?
2、缓存预热
假设MySQL有100条数据,现在是MySQL有了,但是redids中没有缓存,这就需要操作让redis也有这100条数据。
可以的办法
- 最简单的就是利用redis回写,第一个人全部查询一遍都去MySQL查然后回写到redis,redis就有了,但是这第一个人最好是自己人,开发和测试人员完成,别让客户等
- 通过中间件或者程序自动完成,这边MySQL新增数据,redis同步得新增
3、缓存雪崩
- redis主机挂了, Redis全盘崩溃,偏硬件运维
- redis中有大量key同时过期大面积失效,偏软件开发
预防
-
redis中key设置为永不过期or 过期时间错开
-
redis缓存集群实现高可用
- 主从+哨兵
- Redis Cluster
- 开启Redis持久化机制aof/rdb,尽快恢复缓存集群
-
多缓存结合预防雪崩
ehcache本地缓存+ redis缓存
-
服务降级
Hystrix或者阿里sentinel限流&降级,温馨提示404
-
人民币玩家
阿里云-云数据库Redis版
https://www.aliyun.com/product/kvstore?spm=5176.54432.J3207526240.15.2a3818a5iG19IE
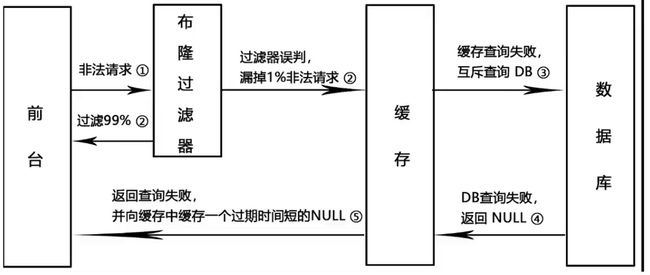
4、缓存穿透
请求去查询一条记录,先查redis无,后查mysql无,都查询不到该条记录,但是请求每次都会打到数据库上面去,导致后台数据库压力暴增,这种现象我们称为缓存穿透,这个redis变成了一个摆设。
简单说就是
本来无一物,两库都没有。
既不在Redis缓存库,也不在mysql,数据库存在被多次暴击风险
怎么预防这个恶意攻击导致缓存穿透的问题
-
方案一:空对象缓存或者缺省值
-
一般情况下
第一种解决方案,回写增强
如果发生了缓存穿透,我们可以针对要查询的数据,在Redis里存一个和业务部门商量后确定的缺省值(比如,零、负数、defaultNull等)。比如,键uid:abcdxxx,值defaultNull作为案例的key和value
先去redis查键uid:abcdxxx没有,再去mysql查没有获得﹐这就发生了一次穿透现象。但是,可以增强回写机制
mysql也查不到的话也让redis存入刚刚查不到的key并保护mysql。
第一次来查询uid:abcdxxx,redis和Imysql都没有,返回null给调用者,但是增强回写后第二次来查uid:abcdxxx,此时redis就有值了。可以直接从Redis中读取default缺省值返回给业务应用程序,避免了把大量请求发送给mysql处理,打爆mysql。这种情况只能解决key相同的情况,正常的人家恶意攻击你了怎么可能都用相同的key
-
黑客恶意攻击
黑客会对你的系统进行攻击,拿一个不存在的id去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉
-
key相同去打你的系统,回写增强
第一次打到mysql,空对象缓存后第二次就返回defaultNull缺省倬,避免mysql被攻击,不用再到数据库中去走一圈了
-
key不同去打你的系统
由于存在空对象缓存和缓存回写(看自己业务不限死),
redis中的无关紧要的key也会越写越多(记得设置redis过期时间)
-
-
-
Google布隆过滤器Guaava解决缓存穿透
Guava 中布隆过滤器的实现算是比较权威的,
所以实际项目中我们可以直接使用Guava布隆过滤器源码地址guava/guava/src/com/google/common/hash/BloomFilter.java at master · google/guava · GitHub
-
白名单过滤器
全部合法的key都需要放入Guava版布隆过滤器+redis里面,不然数据就是返回null
案例
在pom.xml中添加Guava依赖
<dependency> <groupId>com.google.guavagroupId> <artifactId>guavaartifactId> <version>20.0version> dependency>入个门
创建一个helloword
@Test public void t1(){ //创建guava版的布隆过滤器 BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 100); // 判断指定元素是否存在 System.out.println(bloomFilter.mightContain(1)); System.out.println(bloomFilter.mightContain(2)); //添加数据到过滤器 bloomFilter.put(1); bloomFilter.put(2); System.out.println(bloomFilter.mightContain(1)); System.out.println(bloomFilter.mightContain(2)); }GuavaBloomFilterController
@Service @Slf4j public class GuavaBloomFilterService { //1 定义一个常量 public static final int _1W = 10000; //2 定义我们guava布隆过滤器,初始容量 public static final int SIZE = 100 * _1W; //3 误判率,它越小误判的个数也就越少(思考,是否可以是无限小??没有误判岂不是更好) public static double fpp = 0.01;//0.01 0.000000000000001 //4 创建guava布隆过滤器 private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), SIZE,fpp); public void guavaBloomFilter() { //1 先让bloomFilter加入100W白名单数据 for (int i = 1; i <= SIZE ; i++) { bloomFilter.put(i); } //2 故意取10W个不在合法范围内的数据,来进行误判率的演示 ArrayList<Integer> list = new ArrayList<>(10 * _1W); //3 验证 for (int i = SIZE+1; i <= SIZE+(10 * _1W) ; i++) { if(bloomFilter.mightContain(i)) { log.info("被误判了:{}",i); list.add(i); } } log.info("误判总数量:{}",list.size()); } }GuavaBloomFilterService
@Api(tags = "google工具Guava处理布隆过滤器") @RestController @Slf4j public class GuavaBloomFilterController { @Resource private GuavaBloomFilterService guavaBloomFilterService; @ApiOperation("guava布隆过滤器插入100万样本数据并额外10W测试是否存在") @RequestMapping(value = "/guavafilter",method = RequestMethod.GET) public void guavaBloomFilter() { guavaBloomFilterService.guavaBloomFilter(); } }
设置的误判率就和结果对应上了
fpp就是False positive probability------假阳性概率就是误判率
设置的误判率越小申请的比特位越多,哈希函数也越多,精确度越大使用资源越多
-
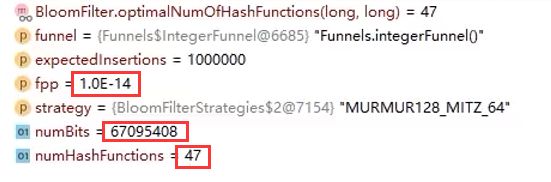
这个默认fpp就是0.03,哈希函数为5个
让布隆过滤器作黑名单使用:
抖音防止推荐重复视频,饿了么防止推荐重复优惠券,推荐过的尽量别在重复推荐
推荐时先去布隆过滤器判断,
存在
说明在黑名单里面,已经推荐过不再重复推荐;
不存在
就是新视频,推荐给用户并更新进布隆过滤器,防止下次重复推荐
5、缓存击穿
大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去
简单说就是热点key突然失效了,暴打mysql
可能导致击穿的原因
- 本来这个key就有自然过期时间的,时间一到就会没了。
- 删除老的key换上新的key时,删除的动作时,key没了,访问来了
危害
- 会造成某一时刻数据库请求量过大,压力剧增。
- 一般技术部门需要知道热点key是那些个?做到心里有数防止击穿
热点key失效
- 时间到了自然清除但还能被访问到
- 删除掉的key,刚巧又被访问
解决方案
- 方案1:差异失效时间,对于访问频繁的热点key,干脆就不设置过期时间
- 方案2:互斥更新,采用双检加锁策略
案例
天猫聚划算功能实现+防止缓存击穿
分析:
先把mysql里面参加活动的数据抽取进redis,一般采用定时器扫描来决定上线活动还是下线取消。
支持分页功能,一页20条记录。
高并发+定时任务+分页显示。。 。
redis数据类型选型

springboot+reedis实现高并发的聚划算业务
在原来的项目基础上再增加业务类
entity
@Data
@NoArgsConstructor
@AllArgsConstructor
@ApiModel(value = "聚划算活动的producet")
public class Producet {
//产品id
private int id;
//产品名称
private String name;
//产品价格
private int price;
//产品详情
private String detail;
}
JHSTaskService
采用定时器将参与聚划算活动的特价商品新增进入redis中
@PostConstruct
public void initJHS(){
System.out.println("《《《........启动计时器天猫聚划算功能模拟开始........》》》");
//用线程模拟定时任务,后台任务定时将MySQL里参加活动的商品刷新到redis里
new Thread(() ->{
while (true){
//模拟从MySQL查出数据,用于加载到redis并给聚划算页面显示
List<Producet> list = this.getProducetsFromMySQL();
//使用redis中的list数据结构的lpush命令来实现存储,加载新的数据之前把旧商品下架删除
redisTemplate.delete(JHS_KEY);
//加入新数据给redis参加活动
redisTemplate.opsForList().leftPushAll(JHS_KEY,list);
//暂停1分钟线程,一分钟执行一次,模拟聚划算一天的活动商品更换
try {
TimeUnit.MINUTES.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"t1").start();
}
JHSProductController
@RequestMapping
@Api(tags = "模拟聚划算")
public class JHSProductController {
public static final String JHS_KEY="jhs";
public static final String JHS_KEY_A="jhs:a";
public static final String JHS_KEY_B="jhs:b";
@Autowired
private RedisTemplate redisTemplate;
//分页查询,在高并发的情况下,只能走redis查询,走MySQL会崩
@RequestMapping("/find")
@ApiOperation("聚划算案例,每一次1页5条显示")
public List<Producet> find(int page,int size){
List<Producet> list = null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
list = redisTemplate.opsForList().range(JHS_KEY,start,end);
if (CollectionUtils.isEmpty(list)){
//如果list是空的说明redis没有,就去MySQL查询
}
System.out.println("参加活动的商家----"+list);
} catch (Exception e) {
//出异常了,一般是redis宕机或者是网络原因导致连接超时
System.out.println("错误");
e.printStackTrace();
//再次查询mysql
}
return list;
}
}
如果在商品进行下架更新时,老商品删除了但是新的还需要加载上去,执行delete的一瞬间有空隙,这个时候有请求进来找商品redis没有就去MySQL,数量一大那就击穿了。
2条命令的原子性是其次的,主要是防止热key突然失效打到MySQL
redisTemplate.delete(JHS_KEY);
//加入新数据给redis参加活动
redisTemplate.opsForList().leftPushAll(JHS_KEY,list);
解决这个问题可以使用
-
差异失效时间,也就是双缓存策略
-
开辟两块缓存,主A从B,先更新B再更新A,严格按照这个进行。
-
先查询主缓存A,如果A没有再找B
JHSTaskService增加内容
public void initJHSAB(){ System.out.println("启动AB定时器计划任务天猫聚划算功能模拟......"); //使用线程模拟定时任务,后台任务定时将MySQL里面的参加活动的商品刷新到redis里 new Thread(() ->{ while (true){ //模拟从MySQL中查出数据,用于加载到redis并给出聚划算页面显示 List<Producet> list = this.getProducetsFromMySQL(); //先更新B缓存且让B缓存过期时间超过A缓存,如果A突然失效了还有B兜底,防止击穿 redisTemplate.delete(JHS_KEY_B); redisTemplate.opsForList().leftPushAll(JHS_KEY_B,list); redisTemplate.expire(JHS_KEY_B,86410L,TimeUnit.SECONDS); //再更新A redisTemplate.delete(JHS_KEY_A); redisTemplate.opsForList().leftPushAll(JHS_KEY_A,list); redisTemplate.expire(JHS_KEY_A,86400L,TimeUnit.SECONDS); //暂停一分钟的线程,间隔一分钟执行一次,模拟聚划算一天执行的参加活动的品牌 try { TimeUnit.MINUTES.sleep(1);} catch (InterruptedException e) { e.printStackTrace(); } } },"t1").start(); }JHSProductController增加内容
//使用双缓存策略 public List<Producet> findAB(int page,int size){ List<Producet> list = null; long start = (page - 1) * size; long end = start + size - 1; try { list = redisTemplate.opsForList().range(JHS_KEY_A, start, end); if (CollectionUtils.isEmpty(list)){ System.out.println("----A缓存已经过期失效或活动已经结束,需要人工修改,B缓存顶上"); list = redisTemplate.opsForList().range(JHS_KEY_B, start, end); if (CollectionUtils.isEmpty(list)){ //就连B都是空的就不正常了,去数据库查询 } } System.out.println("参加活动的商家----"+list); } catch (Exception e) { //出异常了,一般是redis宕机或者是网络原因导致连接超时 System.out.println("错误"); e.printStackTrace(); //再次查询mysql } return list; }
-
6、总结
redisTemplate.opsForList().leftPushAll(JHS_KEY_B,list);
redisTemplate.expire(JHS_KEY_B,86410L,TimeUnit.SECONDS);
//再更新A
redisTemplate.delete(JHS_KEY_A);
redisTemplate.opsForList().leftPushAll(JHS_KEY_A,list);
redisTemplate.expire(JHS_KEY_A,86400L,TimeUnit.SECONDS);
//暂停一分钟的线程,间隔一分钟执行一次,模拟聚划算一天执行的参加活动的品牌
try { TimeUnit.MINUTES.sleep(1);} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"t1").start();
}
```
JHSProductController增加内容
```java
//使用双缓存策略
public List findAB(int page,int size){
List list = null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
list = redisTemplate.opsForList().range(JHS_KEY_A, start, end);
if (CollectionUtils.isEmpty(list)){
System.out.println("----A缓存已经过期失效或活动已经结束,需要人工修改,B缓存顶上");
list = redisTemplate.opsForList().range(JHS_KEY_B, start, end);
if (CollectionUtils.isEmpty(list)){
//就连B都是空的就不正常了,去数据库查询
}
}
System.out.println("参加活动的商家----"+list);
} catch (Exception e) {
//出异常了,一般是redis宕机或者是网络原因导致连接超时
System.out.println("错误");
e.printStackTrace();
//再次查询mysql
}
return list;
}
```
6、总结
[外链图片转存中…(img-lkYZfBZe-1697718422865)]