python3一篇学会人脸识别(详细教学篇(附源码))
说明:
本章用到的模块与软件:windows10 + Pycharm专业版 + python3.10 + opencv-python(版本4.6.0.66)模块 + Numpy(版本1.24.0)模块
模块可以通过pycharm软件下 文件 > 设置 > 项目 > python解释器 > 左上角 加号 > 搜索opencv-python和Numpy 下载即可
一般安装OpenCV(opencv-python)时,会同时安装Numpy,因为有些人脸识别的运算需要使用Numpy的数学函数库的数据类型
本章用到的所有图片全是百度而来,如果有侵权,私信删除
我们会先从opencv的基本操作一步步到人脸识别,适合初学玩家
目录
一 . 读取和显示图像
1.建立OpenCV图像窗口,设置等待时间
2.读取图像和显示窗口
3.关闭OpenCV窗口
4.存储图像
二. OpenCV的绘图功能
1.直线绘图
2.绘制矩形
3.绘制圆形
4.输出文字
三. 人脸识别
1.下载人脸识别的特征文件
2.脸部识别
2.1 脸部识别
2.2 识别启动
2.3 程序实战
2.4 将脸部截取保存下来
3.读取摄像头识别的人脸
四.人脸对比
五.完整人脸识别的项目:
一 . 读取和显示图像
1.建立OpenCV图像窗口,设置等待时间
可以使用namedWindow()建立未来要显示图像的窗口
语法:
cv2.namedWindow("窗口标题", 窗口旗标参数)窗口旗标参数值:
WINDOW_AUTOSIZE : 系统将依图像大小调整窗口大小
WINDOW_NORMAL: 用户可自行调整窗口大小
WINDOW_OPENGL: 将以OpenGL支持方式打开窗口
时间等待:
cv2.waitKey(n) 运行时间等待, n单位为毫秒,不写n值就默认无限期等待
演示:
import cv2
cv2.namedWindow("abc", cv2.WINDOW_AUTOSIZE) # 建立标题为 abc 的窗口
cv2.waitKey(1000) # 设置窗口等待时间 注意这里是毫秒 如果不设定会秒退
2.读取图像和显示窗口
可以使用cv2.imread()读取图像,读完后将图像设定个变量内。目前OpenCV支持大部分图像格式,例如:jpg,jpeg,png,bmp,tiff等图片格式
语法:
image = cv2.imread(图像文件,图像旗标)图像旗标参数:
cv2.IMREAD_COLOR: 这是默认值,以彩色图像读取,值为 1
cv2.IMREAD_GRAYSCALE: 以灰色图像读取,值为 0
cv2.IMREAD_UNCHANGED: 以色彩读取包含 alpha 值的图像,值为 -1
显示窗口:
通过cv2.imread(窗口名称,图像对象)的方式就可以显示窗口了例如:
import cv2
cv2.namedWindow("abc", cv2.WINDOW_AUTOSIZE) # 随图片大小改变窗口改变
img1 = cv2.imread("C:\image\\test.png",1) # 注意这里的路径不识别带中文的路径 这里可以用 1 ,0,-1 方式代替图像旗标
cv2.imshow("abc", img1) # 显示窗口
cv2.waitKey() # 设定等待时间,不设置具体时间 则为无限时间等待# 运行结果
3.关闭OpenCV窗口
如果像删除窗口可以使用下面的方法
cv2.destroyAllWindows() # 删除所有OpenCV的图像窗口
cv2.destroyWindow("abc") # 关闭单一窗口4.存储图像
语法:
cv2.imwrite(文件路径,图像对象) # 存储图像例如:
import cv2
cv2.namedWindow("abc", cv2.WINDOW_AUTOSIZE) # 创建窗口
img1 = cv2.imread("C:\image\\test.png") # 默认使用彩色预设
cv2.imshow("abc", img1) # 预览窗口
cv2.imwrite("C:\image\\image.png", img1) # 将test.png的图片保存为 image.png 这里是另存为注意
cv2.waitKey(3000) # 等待三秒
cv2.destroyAllWindows() # 关闭所有窗口
运行结果:
二. OpenCV的绘图功能
1.直线绘图
语法:
cv2.line(绘图对象,(x1,y1),(x2,y2),颜色,宽度)绘图对象可以想成画布,(x1,y1)是线条的起点,(x2,y2)是线条的终点。画布左上角是(0,0)的坐标,往右是x轴,往下是 y 轴 ,单位为像素,颜色为RGB,数值是0到255,默认是黑色,线条宽度默认是 1 px
#实例:
绘制一个线条
import cv2
cv2.namedWindow("abc", cv2.WINDOW_AUTOSIZE) # 创建窗口
img1 = cv2.imread("C:\image\\test.png") # 默认使用彩色预设
cv2.line(img1, (0, 32), (311, 32), (121, 127, 211), 10) # 绘制一个宽度为10 的粉色线条
cv2.imshow("abc", img1) # 预览窗口
cv2.waitKey(3000) # 等待三秒
# 运行结果
2.绘制矩形
语法:
cv2.rectangle(绘图对象,(x1,y1),(x2,y2),颜色,宽度)与直线绘制的方法差不多都是以坐标的形式,只不过(x1,y1)为左上角,(x2,y2)为右下角,注意这里宽度是矩形线条宽度,如果为负值代表是实心矩形
例如:
import cv2
cv2.namedWindow("abc", cv2.WINDOW_AUTOSIZE) # 创建窗口
img1 = cv2.imread("C:\image\\test.png") # 默认使用彩色预设
cv2.rectangle(img1, (645, 53), (1113, 473), (121, 127, 211), 10) # 绘制矩形,线条宽度为10 如果为负数则是实心矩形注意
cv2.imshow("abc", img1) # 预览窗口
cv2.waitKey(3000) # 等待三秒# 运行结果
到这里我们看的审美疲劳了,换一个妹子~继续讲解
3.绘制圆形
语法:
cv2.circle(绘制对象,(x,y),radius,颜色,宽度)注意: 这里的(x,y) 是以圆心展开的,radius:为半径,其他的与矩形绘制一样
# 例如:
import cv2
cv2.namedWindow("abc", cv2.WINDOW_AUTOSIZE) # 创建窗口
img1 = cv2.imread("C:\image\\test.png") # 默认使用彩色预设 # 当前图片大小为 1920 * 1080
cv2.circle(img1, (859, 352), 340, (121, 127, 211), 10) # 绘制园,如果宽度为负数则为实心园
cv2.imshow("abc", img1) # 预览窗口
cv2.waitKey(3000) # 等待三秒后自动就关闭窗口 因为程序结束了
# 运行结果:
4.输出文字
语法:
cv2.putText(绘图对象,文字,位置,字体,字号大小,颜色,文字宽度)其中字体为:
FONT_HERSHEY_SIMPLEX: sans-serif 字体正常大小
FONT_HERSHEY_PLAY: sans-serif 字体较小的字号
FONT_HERSHEY_COMPLEX:serif 字体正常大小
FONT_ITALIC:italic 字体
位置:代表第一个字左下角的坐标
# 例如:
import cv2
cv2.namedWindow("abc", cv2.WINDOW_AUTOSIZE) # 创建窗口
img1 = cv2.imread("C:\image\\test.png") # 默认使用彩色预设 # 当前图片大小为 1920 * 1080
cv2.putText(img1, "This is a very pretty girl", (44, 89), cv2.FONT_ITALIC, 1, (64, 228, 211), 2) # 编写字体
cv2.imshow("abc", img1) # 预览窗口
cv2.waitKey(3000) # 等待三秒后自动就关闭窗口 因为程序结束了
# 运行结果:
三. 人脸识别
人脸识别检测过程中,最重要的是与图像数据库相互匹配对比,所用的技术是哈尔(Harr)特征,OpenCV已经将许多训练测试过的面部,表情,笑脸等特征文件存储了起来
1.下载人脸识别的特征文件
我们在pycharm内下载的opencv-python时并没有下载特征文件,以下有两种下载方式请自行下载,推荐去国内的网站下,国外的网站特别慢
国内:opencv特征文件 # windows请走这里,下载后是个tar包解压,双击opencv-3.3.0这个程序---选好文件位置就可以点击 extract下载了,请放心使用这是官网下载的时候专门的下载器

国外官网: OpenCV 3.3 - OpenCV 非windows的请去官网下载(网不好很慢),下面有几个可以选

2.脸部识别
如果不好理解,还请通过结合本章的实战程序来看
2.1 脸部识别
首先我们需要将图像的人脸标记出来,可以使用cv2.CascadeClassifier()类别执行脸部识别
语法:
face_cascade = cv2.CascadeClassifier(r'C:\Facial-feature-file\opencv\sources\data\haarcascades\haarcascade_frontalface_default.xml')
# haarcascade_frontalface_default.xml是常用的人脸特征识别的文件 2.2 识别启动
其次需要使用识别对象启动detectMultiScale()方法
语法:
faces = face_cascade.detectMultiScale(img,参数1,参数2,.....)
参数:
# face_cascade 是特征文件存放位置的变量
参数 1 - N
# scaleFactor: 如果没有指定,一般是1:1,主要是指在特征对比中,图像比例的缩小倍数
# minNeighbors:每个区块的特征皆会对比,可以设定特征对比数,达到以后就算成功,默认是3
# minSize: 最小识别区块
# maxSize: 最大识别区块
例如:
faces = face_cascade.detectMultiScale(img, 1.3 , 5)
1.3 代表scaleFactor -- 5 代表: minNeighbors
以此顺序推
上述执行成功以后返回值是列表的形式,列表的元素是元组,每个元组内有四组数字,分别代表脸坐上角的x,y轴坐标,脸部的宽w 脸部的高 h
2.3 程序实战
原图:

程序:
import cv2
# 注意,因人脸识别无法识别太远或者太模糊的照片可能会出错,图片最好五官清晰的大头贴类
img1 = cv2.imread("C:\image\\6.jpg") # 默认使用彩色预设 # 当前图片大小为 1280 * 1024
file_name = r'C:\Facial-feature-file\opencv\sources\data\haarcascades\haarcascade_frontalface_default.xml' # 定位人脸识别特征文件
face_cascade = cv2.CascadeClassifier(file_name) # 读取图像文件建立图像文件对象
faces = face_cascade.detectMultiScale(img1, scaleFactor=1.3, minNeighbors=3, minSize=(30, 30)) # 启动识别并设定参数
# 根据图片大小在右下角绘制一个矩形
cv2.rectangle(img1, (img1.shape[1] - 400, img1.shape[0] - 70), (img1.shape[1], img1.shape[0]), (0, 255, 255), -1)
# print(img1.shape) # 该数值打印的是当前图片高,宽和图像通道
# 标注找到多少张脸,在图片内编写文字
cv2.putText(img1, f" {int(len(faces))} face ", (img1.shape[1] - 400, img1.shape[0] - 10), cv2.FONT_HERSHEY_COMPLEX,
2,
(255, 0, 0), 3)
# 将人脸框起来,由于图片中不止一张脸所以利用循环找出全部的脸并框出来
for (x, y, w, h) in faces:
print(x, y, w, h)
cv2.rectangle(img1, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.namedWindow("face", cv2.WINDOW_NORMAL) # 建立图像对象窗口
cv2.imshow("face", img1) # 显示图像
cv2.waitKey(3000) # 等待 3 秒# 运行结果:

2.4 将脸部截取保存下来
想完成图像存储需要借助Pillow模块来实现
如果不熟悉理解 Pillow模块的作用请跳转:Python3一篇学会“图像处理”的基本操作_i鲸落i的博客-CSDN博客
代码:
import cv2
from PIL import Image
# 注意,因人脸识别无法识别太远或者太模糊的照片可能会出错,图片最好五官清晰的大头贴类
img1 = cv2.imread("C:\image\\6.jpg") # 默认使用彩色预设 # 当前图片大小为 1280 * 1024
file_name = r'C:\Facial-feature-file\opencv\sources\data\haarcascades\haarcascade_frontalface_default.xml' # 定位人脸识别特征文件
face_cascade = cv2.CascadeClassifier(file_name) # 读取图像文件建立图像文件对象
faces = face_cascade.detectMultiScale(img1, scaleFactor=1.3, minNeighbors=3, minSize=(30, 30)) # 启动识别并设定参数
# 根据图片大小在右下角绘制一个矩形
cv2.rectangle(img1, (img1.shape[1] - 400, img1.shape[0] - 70), (img1.shape[1], img1.shape[0]), (0, 255, 255), -1)
# print(img1.shape) # 该数值打印的是当前图片高,宽和图像通道
# 标注找到多少张脸,在图片内编写文字
cv2.putText(img1, f" {int(len(faces))} face ", (img1.shape[1] - 400, img1.shape[0] - 10), cv2.FONT_HERSHEY_COMPLEX,
2,
(255, 0, 0), 3)
# 将人脸框起来,由于图片中不止一张脸所以利用循环找出全部的脸并框出来
num = 1
for (x, y, w, h) in faces:
# print(x, y, w, h)
cv2.rectangle(img1, (x, y), (x + w, y + h), (255, 0, 0), 2)
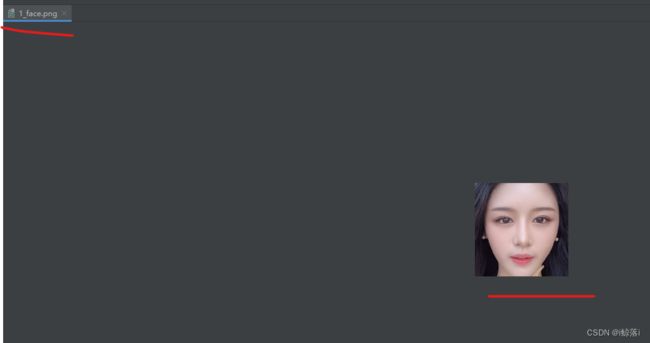
Picture_name = f"{num}_face.png"
image = Image.open("C:\image\\6.jpg") # 这里需要打开你识别的人脸图像
imageCrop = image.crop((x, y, x + w, y + h)) # 剪裁 坐标就按绘画的识别的框 剪
imageRresize = imageCrop.resize((150, 150), Image.ANTIALIAS) # 设置图片存储质量
imageRresize.save(Picture_name) # 保存
num += 1
cv2.namedWindow("face", cv2.WINDOW_NORMAL) # 建立图像对象窗口
cv2.imshow("face", img1) # 显示图像
cv2.waitKey(3000) # 等待 3 秒重点部分:

# 运行结果:
3.读取摄像头识别的人脸
OpenCV 也可有可以控制摄像头的语法,如下:
video = VideoCapture(n) # 笔记本电脑上内置摄像头, n的值是0判断摄像头是否打开:
video.isOpened() #结果为True 为打开,反之False是失败读取摄像头所拍图像:
ret,img = cap.read()案例:
利用电脑摄像头识别人脸并尝试根据人脸实现画框
说明:
详细可以结合上面的内容以及代码的注释来看
1.根据自定的faces参数中的列表坐标值来实现定位坐标并根据这个坐标进行人脸周边画方框
2.detectMultiScale 函数参数含义:
第一个参数:image--待检测图片,一般为灰度图像加快检测速度;
第二个参数:objects--被检测物体的矩形框向量组;
第三个参数:scaleFactor--表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%;
第四个参数:
minNeighbors--表示构成检测目标的相邻矩形的最小个数(默认为3个)。
如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。
如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框,
这种设定值一般用在用户自定义对检测结果的组合程序上;
第五个参数:
flags--要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置为CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域,因此这些区域通常不会是人脸所在区域;
第六和第七:minSize和maxSize用来限制得到的目标区域的范围
import cv2
file_name = r'C:\Facial-feature-file\opencv\sources\data\haarcascades\haarcascade_frontalface_default.xml' # 定位人脸识别特征文件
face_cascade = cv2.CascadeClassifier(file_name) # 读取图像文件建立图像文件对象
cv2.namedWindow('face recognition')
video = cv2.VideoCapture(0)
print(video.isOpened())
while (video.isOpened()):
ret, img = video.read()
img = cv2.flip(img, 1)
grey = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图片转为灰度图片加速检测速度
faces = face_cascade.detectMultiScale(grey, scaleFactor=1.3, minNeighbors=3, minSize=(30, 30)) # 启动识别并设定参数
# print("faces", faces)
if len(faces) == 1: # 想要是被多张脸 请将 1 改大
for faceRect in faces:
# print(faceRect)
x, y, w, h = faceRect
cv2.rectangle(img, (x - 10, y - 10), (x + w + 10, y + h + 10), (0, 255, 0), 1) # 实现实时定位人脸的绘图
else:
# 当未检测到人脸或者检测到大于1张脸的时候,给与提示
cv2.putText(img, f"Multiple faces detected!", (200, 60), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 0, 0), 1)
key = cv2.waitKey(200) # 200 是等待时间毫秒 key是用户的按键
if key == ord("a") or key == ord("A"): # 如果按a或A
cv2.imwrite("C:\image\\photo.jpg", img) # 将图片写入c盘image下
break
cv2.imshow('face recognition', img) # 左上角窗口名称
video.release() # 关闭摄像头
cv2.destroyAllWindows() # 销毁所有窗口四.人脸对比
# 注意对比的方式为图片与图片之间的距离对比
# 为什么使用numpy进行人脸对比:
在人脸识别中,常常需要将人脸图像转换为一个特征向量或特征描述子,然后通过比较不同人脸的特征向量之间的距离来判断是否是同一个人脸。而这个距离通常使用范数(norm)来表示。
在这个应用中,'numpy.linalg.norm函数可以方便地计算两个特征向量之间的距离,通常使用的是欧几里德范数(也称 L2 范数),其公式为:
$$|x-y|2 = \sqrt{\sum{i=1}^{n}(x_i-y_i)^2}$$
其中 $x$ 和 $y$ 分别为两个特征向量。
因此,在进行人脸识别时,可以将每个人脸的特征向量存储下来,当需要识别某个人脸时,首先提取该人脸的特征向量,然后计算该特征向量与已存储的所有特征向量之间的距离,找到距离最小的特征向量所对应的人脸即为最可能的匹配结果。
在实际应用中,为了提高匹配精度,常常会使用多种特征描述子和距离计算方法,并且通过一些预处理和优化技术来加速计算,具体实现方法和细节可能有所不同。
# 说明:
以下代码是通过循环一个文件夹内的所有图片对一张进行对比看结果是否为最小值,如果是最小值那么我们认为这两照片非常相似,是同一个人
上代码:
import dlib, numpy, glob, os
import cv2
from skimage import io
# 人脸关键点检测器
face_key_point_path = r".\shape_predictor.dat"
# 人脸识别模型,提取特征的数值
face_rec_model_path = r".\dlib_face_recognition.dat"
# 加载dilb模型
detector = dlib.get_frontal_face_detector()
sp = dlib.shape_predictor(face_key_point_path) # 加载关键点检测器文件
facerec = dlib.face_recognition_model_v1(face_rec_model_path) # 将照片转为dlib格式
# 存储人名
names = []
drill_number = [] # 存储特征点的距离
for f in glob.glob(os.path.join(r"D:\python练习专用目录\dilb模块\image", "*.jpg")):
# print(f)
# print("正在处理: {}".format(f))
img = io.imread(f) # 读取每张图片
names.append(f.split('\\')[-1].split('.')[0]) # 这里取的是文件前面的姓名
dets = detector(img, 1)
for i in dets:
# print(i)
shape = sp(img, i)
# facerec.compute_face_descriptor(图片对象, 特征点)
face = facerec.compute_face_descriptor(img, shape) # 计算特征向量
# 将计算的距离存入一个列表中,为下面做对比用
numpy_number = numpy.array(face)
drill_number.append(numpy_number)
# print(drill_number)
# 这里写你要识别的图片
img = io.imread(r"D:\python练习专用目录\dilb模块\识别的图片\face.jpg")
dets = detector(img, 1)
# 对比后的数据存放点
contrast_list = []
for k, d in enumerate(dets):
# print(k, d) # 识别路径
shape = sp(img, d)
face_descriptor = facerec.compute_face_descriptor(img, shape)
d_test = numpy.array(face_descriptor)
for i in drill_number: # 计算距离
# 在人脸识别中,常常需要将人脸图像转换为一个特征向量或特征描述子,然后通过比较不同人脸的特征向量之间的距离来判断是否是同一个人脸。而这个距离通常使用范数(norm)来表示。
dist_1 = numpy.linalg.norm(i - d_test)
contrast_list.append(dist_1) # 将计算的量存入一个列表中
dict_names = dict(zip(names, contrast_list)) # 将名字和计算结果拼成一个结果
names_sorted = sorted(dict_names.items(), key=lambda d: d[1]) # 转成一个元组并排序
# 那么第一个就是最小值,那么我们认为他就是识别到的人
print("识别的照片可能是:", names_sorted[0][0]) # names_sorted[0][0]取出元组中的人名
五.完整人脸识别的项目:
项目简介:
该项目是人脸识别相对完整的一套,可以识别到人脸,并在识别到的人脸周边自动画上框,可以自动识别到你的人脸是否存在库中,如果不在库中,会提示你让你输入传入图片的名字,并记录到库中,下一次识别到对应的人脸就会识别其输入的名字,识别最后会对你的人脸进行一个对比,识别准确的机率很高。
架构介绍:
windows10 + pycharm + python3.6 + 第三方函数模块需要单独下载:opencv + PTL + dlib + numpy + 数据库:MySQL8
# 注意要先创建数据库:
创建数据库语句:
# 创建数据库
CREATE DATABASE images;
# 进入创建的数据库
USE images;
# 创建存储表
CREATE TABLE face_picture1(
id INT NOT NULL AUTO_INCREMENT COMMENT 'ID',
names VARCHAR(20) NOT NULL COMMENT"姓名",
image LONGBLOB NOT NULL COMMENT "人脸照片",
type VARCHAR(10) NOT NULL DEFAULT "JPG" COMMENT "图片格式",
PRIMARY KEY(id)
)下载地址:
纯后端python人脸识别完整项目-Python文档类资源-CSDN文库