图Graph的存储、图的广度优先(BFS)和深度优先遍历(DFS)
目录
一、图的两种存储方式
1.邻接矩阵
2.邻接表
二、图的遍历
1.广度优先遍历
2.深度优先遍历
️生活中处处有图Graph的影子,例如交通图,地图,电路图等,形象的表示点与点之间的联系。
首先简单介绍一下图的概念和类型:
图的的定义:
图是由一组顶点和一组能够将两个顶点相连的边组成的。
图的类型:
顶点之间的连接方向:无方向-->无向图 有方向-->有向图 ;
边上是否有权值:有-->带权图 无-->无权图;
以下分别是:无向无权、有向无权、无向有权、有向有权图。


一、图的两种存储方式⭐️
1.邻接矩阵
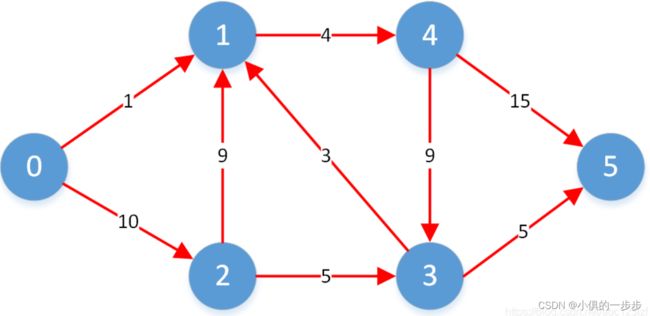
存储原理:邻接矩阵是一种用数组来表示图的方法,其中矩阵的行和列表示图中的顶点,矩阵元素表示顶点之间是否有边相连。具体来说,如果顶点v和顶点u之间有边,则矩阵的第u行第v列的元素为1;否则为0。带权值则为权值,没有相连的为0。
优点:
-
结构简单,易于理解和实现。
-
对于稠密图,邻接矩阵的空间利用率较高。
-
可以方便地计算出图中节点的度(即与该节点相邻的节点的数量)。
缺点:
-
对于稀疏图,邻接矩阵可能占用大量空间。
-
访问相邻节点的速度较慢,需要进行遍历操作。
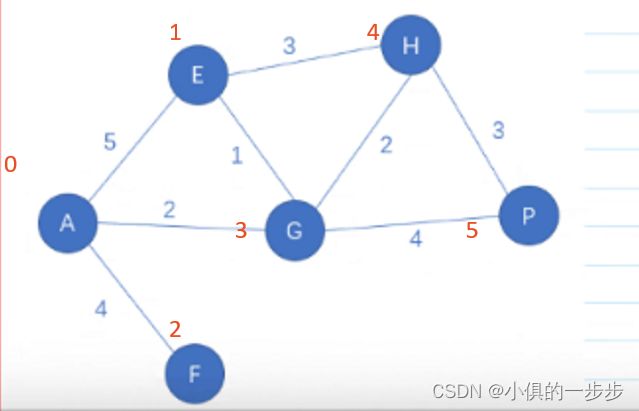
示例:下图的邻接矩阵存储
代码实现
import java.util.Arrays;
//邻接矩阵
public class Graph01 {
char[] val;//顶点数据
int[][] edges;//二维数组记录边
Vertex[] vertices;//顶点类数组
int N;//表大小
public Graph01(char[] arr) {
this.N = arr.length;
//初始化顶点数据
this.val = Arrays.copyOf(arr, arr.length);
this.edges = new int[this.N][this.N];
this.vertices = new Vertex[this.N];
for (int i = 0; i < this.N; i++) {
this.vertices[i] = new Vertex(arr[i]);
}
}
private class Vertex {
Character val;
public Vertex(Character val) {
this.val = val;
}
}
//打印邻接矩阵
public void show() {
System.out.format("%5c", 32);
for (int i = 0; i < this.N; i++) {
System.out.format("%5c", this.val[i]);
}
System.out.println();
for (int i = 0; i < this.N; i++) {
System.out.format("%5c", this.val[i]);
for (int j = 0; j < this.N; j++) {
System.out.format("%5d", this.edges[i][j]);
}
System.out.println();
}
}
public static void main(String[] args) {
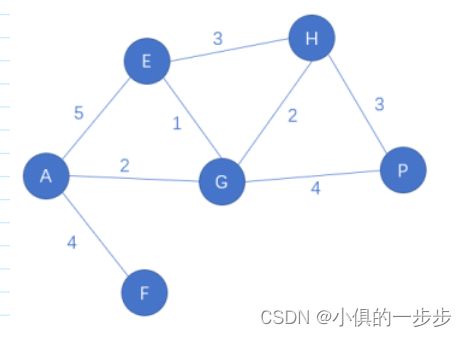
char[] arr = {'A', 'E', 'F', 'G', 'H', 'P'};
Graph01 graph01 = new Graph01(arr);
// 构建边集
int[][] edges = graph01.edges;
edges[0][1] = 5;
edges[0][2] = 4;
edges[0][3] = 2;
edges[1][0] = 5;
edges[1][3] = 1;
edges[1][4] = 3;
edges[2][0] = 4;
edges[3][0] = 2;
edges[3][1] = 1;
edges[3][4] = 2;
edges[3][5] = 4;
edges[4][1] = 3;
edges[4][3] = 2;
edges[4][5] = 3;
edges[5][3] = 4;
edges[5][4] = 3;
// 调用打印方法
graph01.show();
}
}
打印结果 :

2.邻接表
存储原理:
邻接表中的每个节点都对应一个链表,链表中的每个元素都是一个顶点(或节点),表示与当前节点相邻的节点。这种方式在处理稀疏图(即边的数量远小于顶点的数量)时效率较高。
优点:
-
存储空间开销较小,适用于稀疏图。
-
查找速度快,可以直接通过索引访问相邻节点。
-
可动态添加、删除节点和边。
缺点:
-
存储结构相对复杂,不利于处理大规模数据。
-
空间利用率不高,对于稠密图可能存在大量未使用的节点和边。
代码实现
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
//邻接表
public class Graph02 {
char[] val;//顶点数据
List[] edgesList;//边连接
Vertex[] vertices;
int N;//表大小
public Graph02(char[] arr){
this.N = arr.length;
this.val = Arrays.copyOf(arr,arr.length);
this.edgesList = new List[this.N];
this.vertices = new Vertex[this.N];
for (int i = 0; i < this.N; i++) {
this.vertices[i] = new Vertex(arr[i]);
this.edgesList[i] = new ArrayList<>();
}
}
private class Vertex{
Character val;
public Vertex(Character val){
this.val = val;
}
}
public void show(){
//打印邻接矩阵
for (int i = 0; i list = this.edgesList[i];
list.stream().forEach(item->{
System.out.format("%d-->",item);
});
System.out.println();
}
}
public static void main(String[] args) {
char[] arr = {'A', 'E', 'F', 'G', 'H', 'P'};
Graph02 graph02 = new Graph02(arr);
// 构建边集
List[] edges = graph02.edgesList;
edges[0].add(1);
edges[0].add(2);
edges[0].add(3);
edges[1].add(0);
edges[1].add(3);
edges[1].add(4);
edges[2].add(0);
edges[3].add(0);
edges[3].add(1);
edges[3].add(4);
edges[3].add(5);
edges[4].add(1);
edges[4].add(3);
edges[4].add(5);
edges[5].add(3);
edges[5].add(4);
// 调用打印方法
graph02.show();
}
}
打印结果 :

二、图的遍历⭐️
1.广度优先遍历
算法思想:
某个顶点V0出发,首先访问这个顶点,然后访问V0的各个未曾访问的邻接点W1,W2,…,Wk。然后,依次从W1,W2,…,Wk出发访问各自未被访问的邻接点。这个过程重复进行,直到全部顶点都被访问为止。
实现要点:
使用队列维护,派对将保存顶点值和层数,使用数组将顶点是否访问进行记录。
解决问题:
广度优先遍历能够找出图中从源点到其余所有顶点的最短路径问题。
代码实现:
import java.util.*;
//BFS:广度优先遍历
public class Graph03 {
char[] val;//顶点数据
List[] edgesList;//边连接
Vertex[] vertices;//点集
int N;//表大小
public Graph03(char[] arr) {
this.N = arr.length;
this.val = Arrays.copyOf(arr, arr.length);
this.edgesList = new List[this.N];
this.vertices = new Vertex[this.N];
for (int i = 0; i < this.N; i++) {
this.vertices[i] = new Vertex(arr[i]);
this.edgesList[i] = new ArrayList<>();
}
}
private class Vertex {
Character val;
public Vertex(Character val) {
this.val = val;
}
}
public List> bfs(int startIndex) {
//保存结果
List> result = new ArrayList<>();
//记录节点是否访问过
boolean[] visited = new boolean[this.N];
//使用队列
Queue> queue = new LinkedList<>();
//将第一个顶点入队
queue.offer(new AbstractMap.SimpleEntry<>(startIndex, 0));
//并设置第一个节点已访问
visited[startIndex] = true;
while (!queue.isEmpty()) {
//出队
AbstractMap.SimpleEntry pair = queue.poll();
int key = pair.getKey();//顶点的索引
int level = pair.getValue();//顶点的值
//创建本层结果记录
if (level == result.size()) {
result.add(new ArrayList<>());
}
//将出队元素添加到结果中
result.get(level).add(key);
//从邻接表中获取下一层的节点
List edges = this.edgesList[key];
//入队下一层节点
for (int i = 0; i < edges.size(); i++) {
if (!visited[edges.get(i)]) {
queue.add(new AbstractMap.SimpleEntry<>(edges.get(i), level + 1));
visited[edges.get(i)] = true;
}
}
}
return result;
}
//广度优先结果打印
public void showBfs(int startIndex) {
List> lists = bfs(startIndex);
for (int i = 0; i < lists.size(); i++) {
System.out.print((i + 1) + ": ");
lists.get(i).stream().forEach(v -> {
System.out.format("%-2c,", this.val[v]);
});
System.out.println();
}
}
public void show() {
//打印邻接矩阵
for (int i = 0; i < this.N; i++) {
System.out.format("%-3c", this.val[i]);
List list = this.edgesList[i];
list.stream().forEach(item -> {
System.out.format("%d-->", item);
});
System.out.println();
}
}
public static void main(String[] args) {
char[] arr = {'A', 'E', 'F', 'G', 'H', 'P'};
Graph03 graph03 = new Graph03(arr);
// 构建边集
List[] edges = graph03.edgesList;
edges[0].add(1);
edges[0].add(2);
edges[0].add(3);
edges[1].add(0);
edges[1].add(3);
edges[1].add(4);
edges[2].add(0);
edges[3].add(0);
edges[3].add(1);
edges[3].add(4);
edges[3].add(5);
edges[4].add(1);
edges[4].add(3);
edges[4].add(5);
edges[5].add(3);
edges[5].add(4);
// 调用打印方法
//graph02.show();
graph03.showBfs(4);
}
}
样图:
输出结果:

2.深度优先遍历
算法思想:
它从根节点开始,沿着一个路径一直到达最深的节点,然后回溯到之前的节点,继续探索下一个路径,直到所有的节点都被访问过。
实现要点:
使用栈将路径保存
解决问题:
最小生成树灯等
代码实现:
import java.util.*;
// 深度优先遍历使用栈
public class Graph04 {
char[] vals; // 顶点的数据
int N;//图中顶点的个数
// 点集
Vertex[] vertexs;
//边集
List[] edges;
public Graph04(char[] arr) {
this.N = arr.length;
vals = Arrays.copyOf(arr, this.N);
// 先构建点集
this.vertexs = new Vertex[this.N];
for (int i = 0; i < this.N; i++) {
this.vertexs[i] = new Vertex(this.vals[i]);
}
this.edges = new List[this.N];
for (int i = 0; i < this.N; i++) {
this.edges[i] = new ArrayList<>();
}
}
// 打印边集(临近矩阵)
public void show() {
for (int i = 0; i < this.N; i++) {
System.out.format("%-5c", this.vals[i]);
List edgeList = this.edges[i];
edgeList.stream().forEach(edge -> {
System.out.format("%c-->", this.vals[edge]);
});
System.out.println();
}
}
/**
* @param startIndex 起点
* @param endIndex 终点
* @param visited 是否已访问的数组
* @param path 路径
* @param result 最终的结果
* @return
*/
public void dfs(int startIndex, int endIndex, boolean[] visited, Stack path, List> result) {
// 递归终止的条件
if (startIndex == endIndex) {
path.add(startIndex);
result.add(new ArrayList<>(path));
// 回溯
path.pop();
return;
}
// 递归操作
// 入栈
path.add(startIndex);
visited[startIndex] = true;
// 从邻接表中获取连接的顶点
List edgeList = this.edges[startIndex];
for (int i = 0; i < edgeList.size(); i++) {
if (!visited[edgeList.get(i)]) {
dfs(edgeList.get(i), endIndex, visited, path, result);
}
}
// 回溯
path.pop();
visited[startIndex] = false;
}
// 打印每一层的顶点
public void showDfs(int startIndex, int endIndex) {
boolean[] visited = new boolean[this.N];
// 保存路径
Stack stack = new Stack<>();
// 最种保存的结果集
List> result = new ArrayList<>();
dfs(startIndex, endIndex, visited, stack, result);
for (int i = 0; i < result.size(); i++) {
List p = result.get(i);
p.stream().forEach(index -> {
System.out.print(this.vals[index] + "--->");
});
System.out.println();
}
}
private class Vertex {
Character val;
public Vertex(Character val) {
this.val = val;
}
}
public static void main(String[] args) {
char[] arr = {'A', 'E', 'F', 'G', 'H', 'P'};
Graph04 graph01 = new Graph04(arr);
// 构建边集
List[] edges = graph01.edges;
edges[0].add(1);
edges[0].add(2);
edges[0].add(3);
edges[1].add(0);
edges[1].add(3);
edges[1].add(4);
edges[2].add(0);
edges[3].add(0);
edges[3].add(1);
edges[3].add(4);
edges[3].add(5);
edges[4].add(1);
edges[4].add(3);
edges[4].add(5);
edges[5].add(3);
edges[5].add(4);
graph01.showDfs(1, 3);
}
} 样例:索引1->3
输出结果:
