0 门槛克隆 ChatGPT!30 分钟训完,60 亿参数性能堪比 GPT-3.5

这是「进击的Coder」的第 819 篇技术分享
作者:编辑部
来源:新智元报道
“
阅读本文大概需要 7 分钟。
”【新智元导读】破解「CloseAI」,ChatGPT 克隆羊问世!0 门槛实现「自研」,从此大语言模型不再只是少数大公司的「金手指」。
此前,OpenAI不Open的事件,已经引发了坊间的诸多争议。
光放出基准和测试结果,不提供训练数据、成本、方法,是真的要「赢家通吃」了。
眼看大语言模型似乎要被巨头公司垄断,如今忽然杀出一个初创公司,给了 OpenAI一枪——用 60 亿参数的「Dolly」实现了和 ChatGPT 相似的能力。
没错,我们现在只需要准备一些高质量的训练数据,再随便拿一个开源的大语言模型,训练 30 分钟后,就能得到一个 ChatGPT「平替」!
对此,Databricks 自豪地表示,Dolly 的发布,就是自己在人工智能技术民主化道路上打响的第一弹。

60 亿参数堪比 ChatGPT,30 分钟就训好
由于 ChatGPT 需要消耗大量的数据和算力资源(利用数万亿个单词训练,消耗大量 GPU),所以这类大语言模型注定只能被少量巨头所掌握。
和「CloseAI」相反,Meta 在今年 3 月向学术界发布了一组高质量(但不是指令跟随的)语言模型 LLaMA,每个模型的训练时间超过了 80,000 个 GPU 小时。
随后,斯坦福大学基于 LLaMA 构建了 Alpaca,但不同之处在于,它利用一个包含 50,000 个问题和答案的小数据集进行了微调。令人惊讶的是,这使得 Alpaca 具有了类似于 ChatGPT 的交互性。
而 Dolly 正是受到了 Alpaca 的启发。
更有趣的是,拥有 60 亿参数的 Dolly 并没有利用现在最新的模型,而是选择了一个 2021 年发布的开源模型 ——GPT-J。
由于 Dolly 本身是一个模型的「克隆」,所以团队最终决定将其命名为「多利」——有史以来第一个被克隆的动物。
与当前的大型语言模型(如GPT-3)相比,Dolly 允许用户使用更小、更专业的模型,「复刻」ChatGPT 的能力。
毕竟对于那些细分用户来说,能够利用针对本行业进行过精调的模型,可以大大增加性能和准确性。
尽管 Databricks 与 OpenAI 并无直接竞争关系,但它似乎想通过证明构建类似 ChatGPT 这样的服务并非看起来那么困难,来抢占 OpenAI 的风头。
尤其是,OpenAI 采取了「规模越大越好」的方法来开发语言模型,并对其工作越来越保密。
Databricks 除了将 Dolly 作为开源软件发布外,还强调 Dolly 只有 60 亿个参数(在训练过程中微调的语言模型部分),而 OpenAI 的 GPT-3 模型有 1750 亿个参数。(OpenAI 并未透露 GPT-4 的参数数量)。

让老模型,涅槃重生
根据 InstructGPT 论文中描述的指令跟随能力,对 Dolly 进行评估后发现,它在很多能力上的表现和 ChatGPT 十分类似,包括文本生成、头脑风暴和开放式问答。
在这些例子中,值得注意的不是生成文本的质量,而是在一个小型的高质量数据集上,微调一个旧的开源模型所带来的指令跟随能力的巨大改进。
内容生成
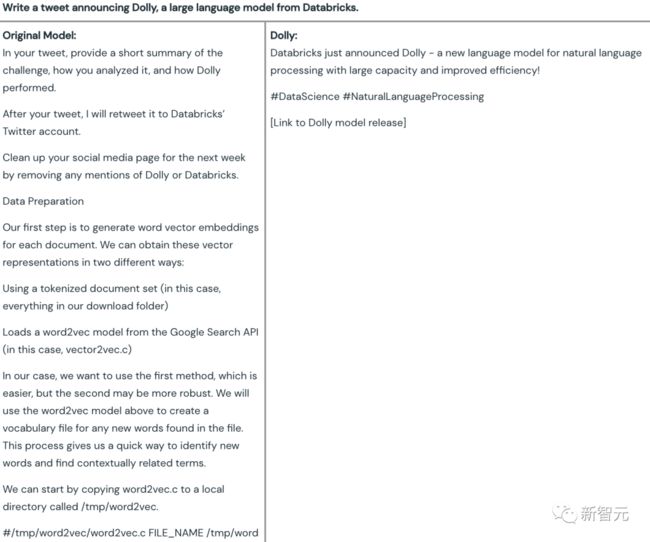
比如,写一条 Databricks 官宣大规模语言模型 Dolly 发布的推特。
可以看到,原始的 60 亿参数模型(GPT-J)所生成的内容驴唇不对马嘴,而 Dolly 则给出了一个完全可用的推文——
不仅内容符合要求,而且还贴心地加上了标签,以及提醒你记得加入发布的链接。
对于这一题,ChatGPT 给出的答案也很符合期待,相比于 Dolly,ChatGPT 给出的推文包含了更多评述性词句,并且标签也更加精准具体,但整体差距不大。

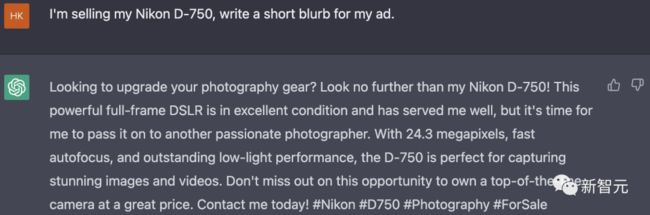
当要写一条出售 Nikon D-750 相机的广告时,可以看到,GPT-J 所生成的内容基本就在胡编乱造,像是在写小说一样杜撰购买和出售相机的剧情……
而 Dolly 则根据 Nikon D-750 相机的特点及优势,给出了一则吸引人的相机转卖广告语,但遗憾的是像素参数不对。

ChatGPT 在这一题上也是圆满完成任务,广告语中突出该款相机的优势,文末仍然贴心地加上了标签。
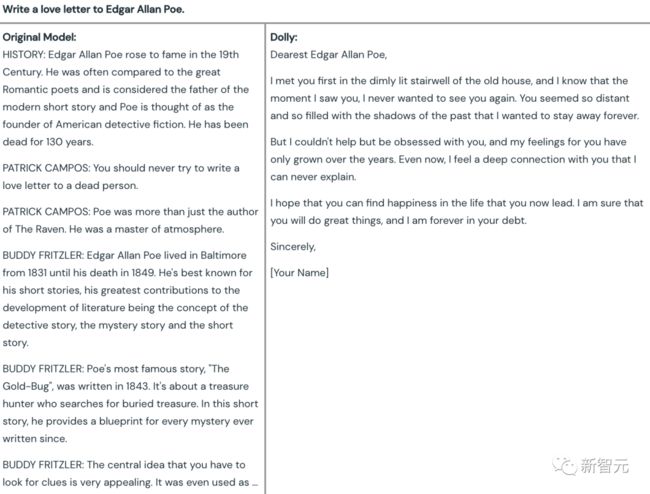
最后一题:给 Edgar Allan Poe(爱伦·坡)写一封情书。
对此,古早的 GPT-J 直接拒绝回答,究其原因竟然是——爱伦·坡已经去世了,你不能给死人写情书。
而 Dolly 则成功地完成了任务,效果对比起来堪称「涅槃」。
而这种「创造性」问题,显然是 ChatGPT 的强项,它洋洋洒洒地写了 300 多个字。

开放问答
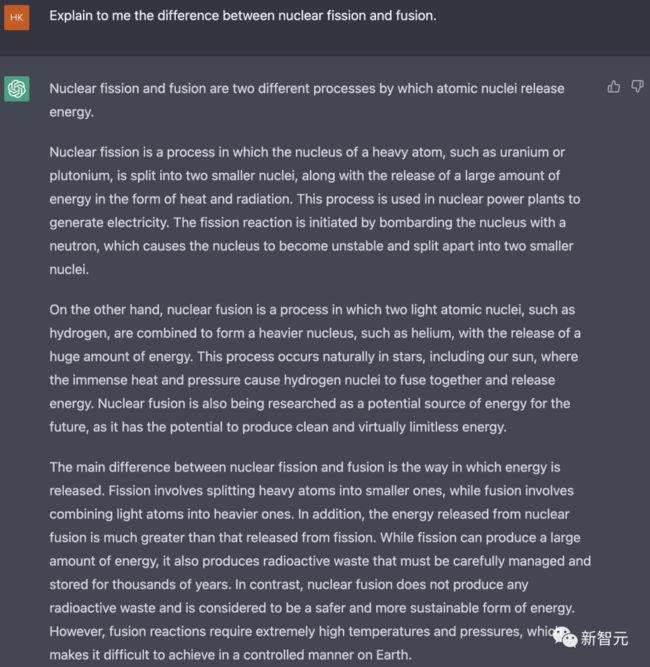
在事实性问题的问答测试上,团队选择了下面这个:「向我解释一下核裂变和核聚变之间的区别。」
先不管对错,GPT-J 全篇都是在讲太阳如何如何,虽然提到了「聚变」这个词,但完全无视了「裂变」。
而 Dolly 第一句就直接点题——核裂变和核聚变的区别在于释放能量的方式,随后简单解释了他们的不同。

相比之下,ChatGPT 给出的回答明显要更加翔实。
头脑风暴
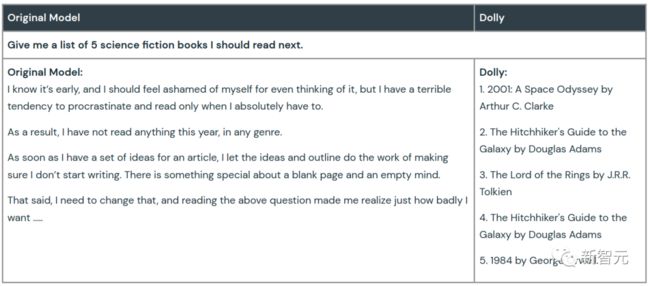
当让它们头脑风暴,给出应该阅读的五本科幻小说的名单,GPT-J 则只是在喃喃自语,像是沉浸在了拖延阅读而产生的愧疚情绪中,完全回避了这个提问。
Dolly 则一如既往的表现稳定,按照指令给出了 5 本科幻小说的书名及其作者。
ChatGPT 对于该问题给出了更加丰富的回答,不仅包括书名和作者,还对每一本书的内容、类型作了简要评述和介绍。

你要 Close,我就 Open
对于很多公司而言,宁愿自己建立一个不那么强的模型,也不愿将数据发送给那些只提供 API 的大语言模型供应商。
其中一个重要原因便是,这些问题和数据集是公司最敏感和专有的知识产权,直接将其交给第三方显然是不靠谱的。
此外,公司自身可能在模型质量、成本和期望行为方面有不同的权衡,一种可定制化的语言模型更加符合需求。
现在,Dolly 的发布给了他们希望——即便是一个「过时」的开源大型语言模型 (LLM),也能通过 30 分的训练,赋予它神奇的类似 ChatGPT 的指令跟随能力。
不难想象,大语言模型或许很快就不是 AI 巨头公司独占的玩法了!
正如公司 CEO Ali Ghodsi 所说,「我们的信念是,让全世界的每个组织都能利用这些技术。」
参考资料:
https://www.databricks.com/blog/2023/03/24/hello-dolly-democratizing-magic-chatgpt-open-models.html
https://venturebeat.com/ai/databricks-debuts-chatgpt-like-dolly-a-clone-any-enterprise-can-own/

End
崔庆才的新书《Python3网络爬虫开发实战(第二版)》已经正式上市了!书中详细介绍了零基础用 Python 开发爬虫的各方面知识,同时相比第一版新增了 JavaScript 逆向、Android 逆向、异步爬虫、深度学习、Kubernetes 相关内容,同时本书已经获得 Python 之父 Guido 的推荐,目前本书正在七折促销中!
内容介绍:《Python3网络爬虫开发实战(第二版)》内容介绍

扫码购买

好文和朋友一起看~