linux内核源码分析之伙伴系统(一)
目录
一、重要结构体
二、数据结构之间的关系
1、分配数量
2、区域类型
3,备用区域列表
4、区域水位
5、min_free_kbytes
三、分配页面
1、ac参数获取值
2,快速分配
3,慢速分配
伙伴系统是linux内存管理的方法。两个关键特征:速度和效率。
一、重要结构体
- 页 (page)
一个 page 结构表示一个物理内存页面。
- 区(zone)
因为硬件限制,Linux内核不能把所有的物理内存页统一对待,把属性相同的物理内存页面。归结到了一个区中。
- 节点 (pglist_data)
pglist_data 结构中包含了 zonelist 数组。第一个 zonelist 类型的元素指向本节点内的 zone 数组,第二个 zonelist 类型的元素指向其它节点的 zone 数组,而一个 zone 结构中的 free_area 数组中又挂载着 page 结构。
二、数据结构之间的关系

伙伴系统重要结构体 zone, free_area
1、分配数量
伙伴分配器一次最多可以分配2的10次方的页
#define MAX_ORDER 11
struct zone{
struct free_area free_area[MAX_ORDER];//不同长度的空间区域
...
}2、区域类型
根据分配标志获取首选区域类型
#define __GFP_WAIT ((__force gfp_t)0x10u) /* 可以等待和重调度? */
#define __GFP_HIGH ((__force gfp_t)0x20u) /* 应该访问紧急分配池? */
#define __GFP_IO ((__force gfp_t)0x40u) /* 可以启动物理IO? */
#define __GFP_FS ((__force gfp_t)0x80u) /* 可以调用底层文件系统? */
#define __GFP_COLD ((__force gfp_t)0x100u) /* 需要非缓存的冷页 */
#define __GFP_NOWARN ((__force gfp_t)0x200u) /* 禁止分配失败警告 */
#define __GFP_REPEAT ((__force gfp_t)0x400u) /* 重试分配,可能失败 */
#define __GFP_NOFAIL ((__force gfp_t)0x800u) /* 一直重试,不会失败 */
#define __GFP_NORETRY ((__force gfp_t)0x1000u) /* 不重试,可能失败 */
#define __GFP_NO_GROW ((__force gfp_t)0x2000u) /* slab内部使用 */
#define __GFP_COMP ((__force gfp_t)0x4000u) /* 增加复合页元数据 */
#define __GFP_ZERO ((__force gfp_t)0x8000u) /* 成功则返回填充字节0的页 */
#define __GFP_NOMEMALLOC ((__force gfp_t)0x10000u) /* 不使用紧急分配链表 */
#define __GFP_HARDWALL ((__force gfp_t)0x20000u) /* 只允许在进程允许运行的CPU所关联
* 的结点分配内存 */
#define __GFP_THISNODE ((__force gfp_t)0x40000u) /* 没有备用结点,没有策略 */
#define __GFP_RECLAIMABLE ((__force gfp_t)0x80000u) /* 页是可回收的 */
#define __GFP_MOVABLE ((__force gfp_t)0x100000u) /* 页是可移动的 */配的内存标记为可回收的或可移动的。这影响从空闲列表的哪个子表获取内存
//需要原子分配内存,不得让请求者进入睡眠
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
//分配用于内核自己使用的内存,IO 文件系统
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_KERNEL_ACCOUNT (GFP_KERNEL | __GFP_ACCOUNT)
//分配内存不能睡眠,不能有I/O和文件系统相关操作
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
//分配用于用户进程的内存
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
//用于DMA的内存
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
//把高端内存区的内存分配给用户进程
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (GFP_HIGHUSER | __GFP_MOVABLE)
#define GFP_TRANSHUGE_LIGHT ((GFP_HIGHUSER_MOVABLE | __GFP_COMP | \
__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
#define GFP_TRANSHUGE (GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM)#define GFP_ZONE_TABLE ( \
(ZONE_NORMAL << 0 * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA << ___GFP_DMA * GFP_ZONES_SHIFT) \
| (OPT_ZONE_HIGHMEM << ___GFP_HIGHMEM * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA32 << ___GFP_DMA32 * GFP_ZONES_SHIFT) \
| (ZONE_NORMAL << ___GFP_MOVABLE * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA << (___GFP_MOVABLE | ___GFP_DMA) * GFP_ZONES_SHIFT) \
| (ZONE_MOVABLE << (___GFP_MOVABLE | ___GFP_HIGHMEM) * GFP_ZONES_SHIFT)\
| (OPT_ZONE_DMA32 << (___GFP_MOVABLE | ___GFP_DMA32) * GFP_ZONES_SHIFT)\
)内核使用宏GFP_ZONE_TABLE定义了标志组合到区域类型的映射表,其GFP_ZONE_SHIFT是区域类型占用的位数,GFP_ZONE_TABLE把每种标志组合映射到32位整数的某个位置,偏移是(标志组合*区域类型位数),从偏移开始的GFP_ZONE_SHIFT个二进制存放区域类型。
3,备用区域列表
3.1 借用规则
- 一个内存节点的某个区域类型可以从另一个内存节点相同区域类型借用物理页,比如节点0的普通区域可以从节点1的普通区域借用物理页。
- 高区域类型可以从低区域类型借用物理页,比如普通区域可以从DMA借用物理页。
- 低区域类型不能从高区域类型借用物理页,比如DMA区域不能从普通区域借用物理页。
3.2 内存节点的备用区域列表有两种排序方法
节点优先顺序
- 先根据节点距离从小到大排序,然后在每个节点里面根据区域类型从高到低排序;
- 优点是优先选择距离近的内存,缺点是在高区域耗尽以前使用的低区域。
区域优先顺序
- 先根据区域类型从高到低排序,然后在每个区域类型里面根据节点距离从小到大排序;
- 优点是减少低区域耗尽的统率,缺点是不能保证优先选择近距离的内存。
默认的排序方法是自动选择最优的排序方法,比如64位系统,因为需要DMA和DMA32区域的备用相对少,所以选择节点优先顺序;如果是32位系统,选择区域优先顺序。
使用内核参数numa_zonelist_order指定排序方法: /proc/sys/vm/numa_zonelist_order
d:表示默认排序
n:表示节点优先排序
z:表示区域优先排序
4、区域水位
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};最低水线以下的内存称为紧急保留内存,在内存严重不足的紧急情况下,给承诺“分给我们少量的紧急保留内存使用,我可以释放更多的内存”的进程使用。
水位线的重要成员参数
struct zone {
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
...
}
#define min_wmark_pages(z) (z->_watermark[WMARK_MIN] + z->watermark_boost)
#define low_wmark_pages(z) (z->_watermark[WMARK_LOW] + z->watermark_boost)
#define high_wmark_pages(z) (z->_watermark[WMARK_HIGH] + z->watermark_boost)- managed_pages 伙伴分配器管理的物理页的数量
计算方式:managed_pages = present_pages - reserved_pages
- spanned_pages 当前区域跨越的总页数,包括空洞
计算方式:spanned_pages = zone_end_pfn - zone_start_pfn
- present_pages 当前区域存在的物理页的数量,不包括空洞
计算方式:present_pages = spanned_pages - absent_pages(pages in holes)
三者在系统中的查看
# cat /proc/zoneinfo
Node 0, zone DMA
Node 0, zone DMA32
pages free 705602
min 6327
low 7908
high 9489
spanned 1044480
present 782288
managed 765904
...5、min_free_kbytes
代表的时系统保留空闲内存的最低限
/*
* Initialise min_free_kbytes.
*
* For small machines we want it small (128k min). For large machines
* we want it large (64MB max). But it is not linear, because network
* bandwidth does not increase linearly with machine size. We use
*
* min_free_kbytes = 4 * sqrt(lowmem_kbytes), for better accuracy:
* min_free_kbytes = sqrt(lowmem_kbytes * 16)
*
*/
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
if (new_min_free_kbytes > user_min_free_kbytes) {
min_free_kbytes = new_min_free_kbytes;
if (min_free_kbytes < 128)
min_free_kbytes = 128;
if (min_free_kbytes > 65536)
min_free_kbytes = 65536;
} else {
pr_warn("min_free_kbytes is not updated to %d because user defined value %d is preferred\n",
new_min_free_kbytes, user_min_free_kbytes);
}
setup_per_zone_wmarks();
refresh_zone_stat_thresholds();
setup_per_zone_lowmem_reserve();
#ifdef CONFIG_NUMA
setup_min_unmapped_ratio();
setup_min_slab_ratio();
#endif
return 0;
}三、分配页面
首先要找到内存节点,接着找到内存区,然后找到合适的空闲链表,最后在其中找到页的 page 结构,完成物理内存页面的分配。
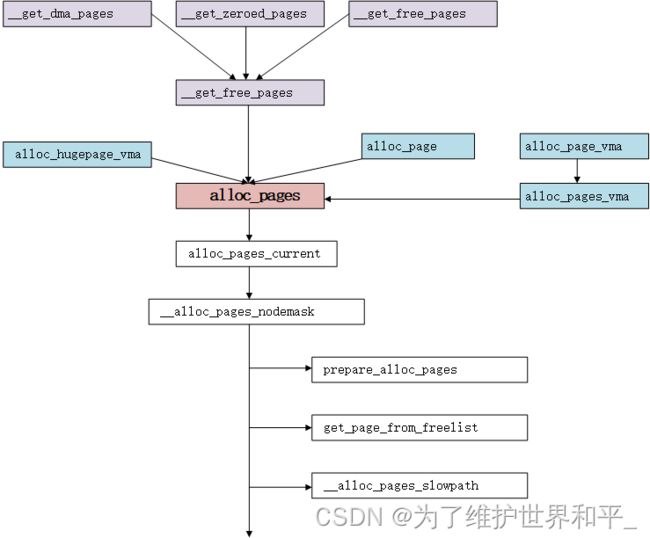
源码分析
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}__alloc_pages_nodemask函数实现以下三个任务
1,ac参数准备,得到首选区域类型和迁移类型
2,快速分配,使用低水线尝试第一次分配
3,快速分配失败,慢速分配
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
//1,准备分配页面的参数在ac变量中
if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags))
return NULL;
//2,快速分配
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
//3,慢速分配
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
...
}gfp_mask:分配标志位
order:阶数
zonelist:首选内存节点的备用区域列表;
nodemask:运行从哪些内存节点分配页
1、ac参数获取值
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,
int preferred_nid, nodemask_t *nodemask,
struct alloc_context *ac, gfp_t *alloc_mask,
unsigned int *alloc_flags)
{
//在哪个内存区分配内存
ac->high_zoneidx = gfp_zone(gfp_mask);
//根据节点id计算zone的指针
ac->zonelist = node_zonelist(preferred_nid, gfp_mask);
ac->nodemask = nodemask;
//计算出free_area中的migratetype值
ac->migratetype = gfpflags_to_migratetype(gfp_mask);
...
return true;
}2,快速分配
快速分配不会进行页面回收
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
bool no_fallback;
retry:
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;
z = ac->preferred_zoneref;
//扫描备用区域列表中每个满足条件的区域:区域类型小于或等于首选区域类型,并且内存节点在节点掩码中的相应位被设置处理
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
//如果编程cpuset功能,调用者设置ALLOC_CPUSET要求使用cpuset检测,并且cpuset不允许当前进程从
//这个内存节点分配,那么不能从这个区域分配页
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
//如果调用者设置__GFP_WRITE,表示文件系统申请分配一个缓存页来写文件,
//那么检查内存的脏页数量是否超过限制。如果超过限制就不能从这个区域分配
if (ac->spread_dirty_pages) {
if (last_pgdat_dirty_limit == zone->zone_pgdat)
continue;
if (!node_dirty_ok(zone->zone_pgdat)) {
last_pgdat_dirty_limit = zone->zone_pgdat;
continue;
}
}
if (no_fallback && nr_online_nodes > 1 &&
zone != ac->preferred_zoneref->zone) {
int local_nid;
local_nid = zone_to_nid(ac->preferred_zoneref->zone);
if (zone_to_nid(zone) != local_nid) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
}
//检查水线,如果(区域的空闲页数-申请的页数) 小于水线
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags)) {
int ret;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
//如果没有开启节点回收功能,或者当前节点和首选节点之间的距离大于回收距离,不能从这个
//区域分配页
if (node_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
//从节点回收没有映射到虚拟地址空间的文件页的块分配器申请的页,然后重新检测水线
//如果小于(区域的空闲页数-申请的页数)水线,不能从这个区域分配页
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
//快速分配路径不处理页面回收问题
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
//根据分配的order数量判断内存区的水位线是否满足要求
if (zone_watermark_ok(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
//如果可以就从这个区域开始分配
goto try_this_zone;
continue;
}
}
try_this_zone:
//直接从当前区域分配页,调用rmqueue来分配
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
//如果成功,调用函数prep_new_page初始化页
if (page) {
//清除一些标志或者设置联合页等等
prep_new_page(page, order, gfp_mask, alloc_flags);
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
} else {
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
}
}
...
return NULL;
}3,慢速分配
如果低水线分配失败,则执行慢速路径。执行页面回收
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned int cpuset_mems_cookie;
int reserve_flags;
if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==
(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))
gfp_mask &= ~__GFP_ATOMIC;
retry_cpuset:
compaction_retries = 0;
no_progress_loops = 0;
compact_priority = DEF_COMPACT_PRIORITY;
/*后面检查cpuset是否允许当前进程从哪个内存节点申请页,需要读当前进程的成员mems_allowed,使用顺序锁保护*/
cpuset_mems_cookie = read_mems_allowed_begin();
//把分配标志转换成内部分配标志位
alloc_flags = gfp_to_alloc_flags(gfp_mask);
//获取首先的内存区域
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
if (!ac->preferred_zoneref->zone)
goto nopage;
//异步回收页,唤醒页回收线程
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
//使用最低水线分配页
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
//针对申请除数大于0,满足三个条件
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
if (costly_order && (gfp_mask & __GFP_NORETRY)) {
if (compact_result == COMPACT_SKIPPED ||
compact_result == COMPACT_DEFERRED)
goto nopage;
compact_priority = INIT_COMPACT_PRIORITY;
}
}
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop */
//唤醒所有交换内存的线程,确保页回收线程不会意外地睡眠
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);
if (reserve_flags)
alloc_flags = reserve_flags;
if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {
ac->nodemask = NULL;
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}
/* Attempt with potentially adjusted zonelist and alloc_flags */
//依然调用快速分配入口函数尝试分配内存页面
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* Caller is not willing to reclaim, we can't balance anything */
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* Try direct reclaim and then allocating */
//直接回收内存并且再次分配内存页面
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* Try direct compaction and then allocating */
//尝试直接压缩(碎片整理)内存并且再分配内存页面
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
//如果调用者要求不要重试,那么放弃
if (gfp_mask & __GFP_NORETRY)
goto nopage;
if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))
goto nopage;
//检查对于给定的分配请求,重试回收是否有意义
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
//检查对于给定的分配请求,重试压缩是否有意义
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/* Deal with possible cpuset update races before we start OOM killing */
///如果cpuset修改允许当前进程从哪些内存节点申请页
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/* Reclaim has failed us, start killing things */
//回收压缩失败了,开始尝试杀死进程,回收内存页面oom
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
/* Avoid allocations with no watermarks from looping endlessly */
if (tsk_is_oom_victim(current) &&
(alloc_flags == ALLOC_OOM ||
(gfp_mask & __GFP_NOMEMALLOC)))
goto nopage;
/* Retry as long as the OOM killer is making progress */
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
nopage:
...
return page;
} 内存压缩不是指压缩内存中的数据,而是指移动内存页面,进行内存碎片整理,腾出更大的连续的内存空间。
参考
https://www.kernel.org/doc/html/v5.6/
《深入Linux内核架构》