Golang 基础二
十一、接口 (interface)
11.1 接口
Go 语言不是一种 “传统” 的面向对象编程语言:它里面没有类和继承的概念。
但是 Go 语言里有非常灵活的 接口 概念,通过它可以实现很多面向对象的特性。
接口定义了一组方法(方法集),但是这些方法不包含(实现)代码:它们没有被实现(它们是抽象的)。接口里也不能包含变量。
type Namer interface {
Method1(param_list) return_type
Method2(param_list) return_type
...
}
接口是一种契约,实现类型必须满足它,它描述了类型的行为,规定类型可以做什么。接口彻底将类型能做什么,以及如何做分离开来,使得相同接口的变量在不同的时刻表现出不同的行为,这就是多态的本质。
编写参数是接口变量的函数,这使得它们更具有普适性、一般性。
(按照约定,只包含一个方法的)接口的名字由方法名加 er 后缀组成,例如 Printer、Reader、Writer、Logger、Converter 等等。还有一些不常用的方式(当后缀 er 不合适时),比如 Recoverable,此时接口名以 able 结尾,或者以 I 开头(像 .NET 或 Java 中那样)。
Go 语言中的接口都很简短,通常它们会包含 0 个、最多 3 个方法。
在 Go 语言中接口可以有值,一个未初始化的接口类型的变量或一个 接口值 :var ai Namer,ai 是一个多字(multiword)数据结构,它的值是 nil。它本质上是一个指针,虽然不完全是一回事。
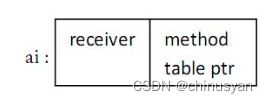
接口变量里包含了接收者实例的值和指向对应方法表的指针。
类型(比如结构体)可以实现某个接口的方法集:这个实现可以描述为,该类型的变量上的每一个具体方法所组成的集合,包含了该接口的方法集。实现了 Namer 接口的类型的变量可以赋值给 ai(即 receiver 的值),方法表指针(method table ptr)就指向了当前的方法实现。
类型不需要显式声明它实现了某个接口:接口被隐式地实现。多个类型可以实现同一个接口。
实现某个接口的类型(除了实现接口方法外)可以有其他的方法。
一个类型可以实现多个接口。
接口类型可以指向一个实例的引用, 该实例的类型实现了此接口(接口是动态类型)。
即使接口在类型之后才定义,二者处于不同的包中,被单独编译:只要类型实现了接口中的方法,它就实现了此接口。
type Shaper interface {
Area() float32
}
type Square struct {
side float32
}
func (sq *Square) Area() float32 {
return sq.side * sq.side
}
type Rectangle struct {
length, width float32
}
func (r Rectangle) Area() float32 {
return r.length * r.width
}
func main() {
r := Rectangle{5, 3} // Area() of Rectangle needs a value
q := &Square{5} // Area() of Square needs a pointer
// shapes := []Shaper{Shaper(r), Shaper(q)}
// or shorter
shapes := []Shaper{r, q}
for n, _ := range shapes {
fmt.Println("Shape details: ", shapes[n])
fmt.Println("Area of this shape is: ", shapes[n].Area()) //接口实例上调用方法
}
}
在接口实例上调用方法,它使此方法更具有一般性
这是 多态 的 Go 版本,多态:根据当前的类型选择正确的方法,或者说:同一种类型在不同的实例上似乎表现出不同的行为。
通过接口产生 更干净、更简单 及 更具有扩展性 的代码。在开发中为类型添加新的接口很容易。
备注
有的时候,也会以一种稍微不同的方式来使用接口这个词:从某个类型的角度来看,它的接口指的是:它的所有导出方法,只不过没有显式地为这些导出方法额外定一个接口而已。
11.2 接口嵌套接口(内嵌接口)
一个接口可以包含一个或多个其他的接口,这相当于直接将这些内嵌接口的方法列举在外层接口中一样。
type ReadWrite interface {
Read(b Buffer) bool
Write(b Buffer) bool
}
type Lock interface {
Lock()
Unlock()
}
type File interface {
ReadWrite
Lock
Close()
}
11.3 类型断言
一个接口类型的变量 varI 中可以包含任何类型的值,必须有一种方式来检测它的 动态 类型,即运行时在变量中存储的值的实际类型。
类型断言
通常我们可以使用 类型断言 来测试在某个时刻 varI 是否包含类型 T 的值:
1)
v := varI.(T) // unchecked type assertion
varI 必须是一个接口变量
类型断言可能是无效的,虽然编译器会尽力检查转换是否有效,但是它不可能预见所有的可能性。如报错:panic: interface conversion: main.Shape is *main.Square, not main.Rectangle
2)
if v, ok := varI.(T); ok { // checked type assertion
Process(v)
return
}
// varI is not of type T
如果转换合法,v 是 varI 转换到类型 T 的值,ok 会是 true;否则 v 是类型 T 的零值,ok 是 false,也没有运行时错误发生。
应该总是使用上面的方式来进行类型断言。
多数情况下,我们可能只是想在 if 中测试一下 ok 的值
if _, ok := varI.(T); ok {
// ...
}
type Shape interface {
Area() float64
}
type Square struct {
side float64
}
func (s *Square) Area() float64 {
return s.side * s.side
}
type Rectangle struct {
length, width float64
}
func (r Rectangle) Area() float64 {
return r.length * r.width
}
func main() {
r := Rectangle{3, 5}
s := &Square{5}
shapes := []Shape{r, s}
for i2 := range shapes {
fmt.Printf("index: %d\n", i2)
// v 为指针(*Square)
if v, ok := shapes[i2].(*Square); ok {
fmt.Println("square")
}
// v 为 Rectangle 变量
if v, ok := shapes[i2].(Rectangle); ok {
fmt.Println("square")
}
}
// 判断一个值是否实现了某个接口
if shape, ok := shapes[0].(Shape); ok {
fmt.Println(shape.Area())
}
}
类型判断:type-switch
接口变量的类型也可以使用一种特殊形式的 switch 来检测:type-switch:
switch v := shapes[i2].(type) {
case Rectangle:
fmt.Printf("Rectangle: %T, value: %v\n", v, v)
case *Square:
fmt.Printf("Square: %T, value: %v\n", v, v)
case nil:
fmt.Printf("nil value\n")
default:
fmt.Printf("Unexpected type %T\n", v)
}
可以用 type-switch 进行运行时类型分析,但是在 type-switch 不允许有 fallthrough 。
如果仅仅是测试变量的类型,不用它的值,那么就可以不需要赋值语句,比如:
switch areaIntf.(type) {
case *Square:
// TODO
case *Circle:
// TODO
...
default:
// TODO
}
在处理来自于外部的、类型未知的数据时,比如解析诸如 JSON 或 XML 编码的数据,类型测试和转换会非常有用。
测试一个值是否实现了某个接口
这个是类型断言中的一个特例
假定 v 是一个值,然后我们想测试它是否实现了 Stringer 接口
if shape, ok := shapes[0].(Shape); ok {
fmt.Println(shape.Area())
}
使用接口使代码更具有普适性。
11.4 接口方法集
接口变量中存储的具体值是不可寻址的
type List []int
func (l List) Len() int {
return len(l)
}
func (l *List) Append(val int) {
*l = append(*l, val)
}
type Appender interface {
Append(int)
}
func CountInto(a Appender, start, end int) {
for i := start; i <= end; i++ {
a.Append(i)
}
}
type Lener interface {
Len() int
}
func LongEnough(l Lener) bool {
return l.Len()*10 > 42
}
func main() {
var lst List
// compiler error:
// cannot use lst (type List) as type Appender in argument to CountInto:
// List does not implement Appender (Append method has pointer receiver)
// CountInto(lst, 1, 10)
if LongEnough(lst) { // VALID: Identical receiver type
fmt.Printf("- lst is long enough\n")
}
// A pointer value
plst := new(List)
CountInto(plst, 1, 10) // VALID: Identical receiver type
if LongEnough(plst) {
// VALID: a *List can be dereferenced for the receiver
fmt.Printf("- plst is long enough\n")
}
}
将一个值赋值给一个接口时,编译器会确保所有可能的接口方法都可以在此值上被调用,因此不正确的赋值在编译期就会失败。
总结
Go 语言规范定义了接口方法集的调用规则:
- 类型
*T的可调用方法集包含接受者为*T或T的所有方法集 - 类型
T的可调用方法集包含接受者为T的所有方法 - 类型
T的可调用方法集不包含接受者为*T的方法
11.5 空接口
空接口或者最小接口 不包含任何方法,它对实现不做任何要求:
type Any interface {}
任何其他类型都实现了空接口,any 或 Any 是空接口一个很好的别名或缩写。
空接口类似 Java/C# 中所有类的基类: Object 类,二者的目标也很相近。
可以给一个空接口类型的变量 var val interface {} 赋任何类型的值。
每个 interface {} 变量在内存中占据两个字长:一个用来存储它包含的类型,另一个用来存储它包含的数据或者指向数据的指针。
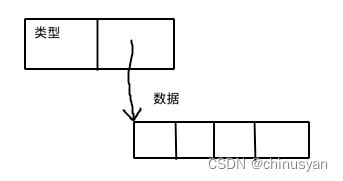
构建通用类型或包含不同类型变量的数组
使用空接口
type Element interface{}
type Vector struct {
a []Element
}
Vector 中存储的所有元素都是 Element 类型,要得到它们的原始类型(unboxing:拆箱)需要用到类型断言。
复制数据切片至空接口切片
类似:
var dataSlice []myType = FuncReturnSlice()
var interfaceSlice []interface{} = dataSlice //错误
可惜不能这么做,编译时会出错:cannot use dataSlice (type []myType) as type []interface { } in assignment。
原因是它们俩在内存中的布局是不一样的
// 必须使用 `for-range` 语句来一个一个显式地赋值
var interfaceSlice []interface{} = make([]interface{}, len(dataSlice))
for i, d := range dataSlice {
interfaceSlice[i] = d
}
结论: interface{} 可以接收任何类型,但是[]interface{} 并不可以接收任何类型的切片
可是普通类型的切片内存布局是:

通用类型的节点数据结构
type Node struct {
le *Node
data interface{}
ri *Node
}
func NewNode(left, right *Node) *Node {
return &Node{left, nil, right}
}
func (n *Node) SetData(data interface{}) {
n.data = data
}
接口到接口
一个接口的值可以赋值给另一个接口变量,只要底层类型实现了必要的方法。这个转换是在运行时进行检查的,转换失败会导致一个运行时错误:这是 Go 语言动态的一面,可以拿它和 Ruby 和 Python 这些动态语言相比较。
type any01 interface {
Name() string
}
type any02 interface {
Age() int
}
type type01 struct {
}
func (t *type01) Name() string {
return "hello"
}
func (t *type01) Age() int {
return 19
}
func main() {
var empty interface{}
var a any01
var c any02
fmt.Printf("%T\n", a)
b := new(type01)
empty = b
a = empty.(any01)
c = a.(any02)
c.Age()
}
a 转换为 any02 类型是完全动态的:只要 a 的底层类型(动态类型)定义了 Age 方法这个调用就可以正常运行(译注:若 a 的底层类型未定义 Age 方法,此处类型断言会导致 Age,最佳实践应该为 if mpi, ok := a.(any02); ok { mpi.Age() }
十二、反射 (reflection)/反射包
Value
type Value struct {
// contains filtered or unexported fields
}
Value 是Go值的反射接口。
并非所有方法都适用于所有类型的值。
在调用特定于类型的方法之前,使用Kind方法找出值的类型。调用不适合类型的方法会导致panic
The zero Value(nil) represents no value。它的IsValid方法返回false,它的Kind方法返回Invalid,它的String方法返回“
一个值可以被多个go例程并发使用,前提是底层的Go值可以并发地用于等价的直接操作。
要比较两个 Value,请比较Interface方法的结果。对两个Value使用==不会比较它们表示的基础值。
1、Interface()
func (v Value) Interface() (i any)
Interface returns v’s current value as an interface{}. It is equivalent to:
var i interface{} = (v's underlying value)
如果Value是通过访问未导出的struct字段获得的,它会panic
2、Type()
func (v Value) Type() Type
返回v的 Type。
3、Kind()
func (v Value) Kind() Kind
Kind returns v’s Kind. If v is the zero Value (IsValid returns false), Kind returns Invalid.
4、Len()
func (v Value) Len() int
Len返回v的长度。如果v的Kind不是Array、Chan、Map、Slice、String或指向Array的指针,它会 panic
5、Int()
func (v Value) Int() int64
Int返回v的基础值,作为int64。如果v的Kind不是Int、Int8、Int16、Int32或Int64,则会panic
6、Float()
func (v Value) Float() float64
Float返回v的基础值,为float64。如果v的种类不是floati32或floati64,它会panic
7、String()
func (v Value) String() string
String以字符串形式返回 v的基础值。String是一种特殊的情况,因为Go的String方法约定。与其他getter不同,如果v的Kind不是String,它不会panic。相反,它返回一个“”形式的字符串,如(
8、Bool()
func (v Value) Bool() bool
Bool返回v的基础值。如果v不是Bool类型,它会 panic
9、Complex()
func (v Value) Complex() complex128
Complex返回v的基础值,作为 complex128。如果v的Kind不是Complex64或Complex128,它就会 panic
10、CanSet()
func (v Value) CanSet() bool
CanSet 确定是否可以修改v的值。只有当值是可寻址的且不是通过使用未导出的结构字段获得时,才可以更改值。如果CanSet返回false,调用Set或任何类型特定的setter(例如SetBool, SetInt)将会出现panic。
11、NumField()
func (v Value) NumField() int
NumField 返回结构v中字段的数量,如果v的Kind不是struct则会panic
12、NumMethod()
func (v Value) NumMethod() int
NumMethod 返回该Value的方法集中的方法数量。
对于非接口类型,它返回导出方法的数量。
对于接口类型,它返回导出和未导出方法的数量。
13、Call()
func (v Value) Call(in []Value) []Value
调用输入参数为in的函数v。例如,如果len(in) == 3, v. call (in)表示Go调用v(in[0], in[1], in[2])。如果v星人不是Func就叫恐慌。它以值的形式返回输出结果。在Go中,每个输入参数必须可赋值给函数对应的输入参数的类型。如果v是一个可变参数函数,Call创建可变参数片本身,复制相应的值。
14、Field()
func (v Value) Field(i int) Value
Field 返回结构体v的第i个字段。如果v的Kind不是Struct,或者i超出了范围,则会产生 panic
15、Method()
func (v Value) Method(i int) Value
方法返回对应于v的第 i (从0开始)个方法的函数值。调用返回函数的参数不应该包括 receiver;返回的函数将始终使用v作为 receiver。如果 i 超出了范围,或者v为nil接口值,则方法会 panic
16、Elem()
func (v Value) Elem() Value
Elem返回接口 v 所包含的值或 v 所指向的指针的值。如果 v 的种类不是接口或指针,它会panic。如果 v 为nil,则返回零值。
17、MapKeys
// MapKeys返回一个包含map中所有键的切片,未指定顺序
// 如果v的Kind不是Map,它就会恐慌
// 如果v表示nil Map,则返回空片。
func (v Value) MapKeys() []Value
Type
type Type interface {
// 字段返回一个结构类型的第i个字段。
// 如果类型的类型不是结构体,它会 panic。如果i不在范围[0,NumField())),它会 panic
Field(i int) StructField
// contains filtered or unexported methods
}
Type 是Go类型的表示。
并非所有方法都适用于所有类型的值。
在调用特定于类型的方法之前,使用Kind方法找出值的类型。调用不适合类型的方法会导致panic
Type 值具有可比性,例如==操作符,因此可以将它们用作映射键。
如果两个Type值表示相同的类型,则它们是相等的。
Kind
type Kind uint
Kind 表示一个 Type 所表示的特定类型。The zero Kind is not a valid kind.
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Pointer
Slice
String
Struct
UnsafePointer
)
String()
func (k Kind) String() string
String returns the name of k.
12.1 方法和类型的反射
反射是用程序检查其所拥有的结构,尤其是类型的一种能力;这是元编程的一种形式。
反射可以在运行时检查变量的类型,例如:它的大小、它的方法以及它能“动态地”调用这些方法。这对于没有源代码的包尤其有用。这是一个强大的工具,除非真得有必要,否则应当避免使用或小心使用。
变量的最基本信息就是类型和值:反射包的 Type 用来表示一个 Go 类型,反射包的 Value 为 Go 值提供了反射接口。
reflect.TypeOf 和 reflect.ValueOf,返回被检查对象的类型和值。
func reflectTest() {
var x float64 = 3.4
fmt.Println(reflect.TypeOf(x)) // float64
fmt.Println(reflect.ValueOf(x)) // 3.4
}
实际上,反射是通过检查一个接口的值,变量首先被转换成空接口,接口的值包含一个 type 和 value。
1、ValueOf()
func ValueOf(i any) Value
ValueOf返回一个新值,初始化为存储在接口i中的具体值。
ValueOf(nil) returns the zero Value.
2、TypeOf()
func TypeOf(i any) Type
TypeOf返回表示i的动态类型的反射Type
If i is a nil interface value, TypeOf returns nil.
反射可以从接口值反射到对象(即反射对象),也可以从对象反射回接口值。
Value 有一个 Type() 方法返回 reflect.Value 的 Type 类型。另一个是 Type 和 Value 都有 Kind() 方法返回一个常量来表示类型:Uint、Float64、Slice 等等。同样 Value 有叫做 Int() 和 Float() 的方法可以获取存储在内部的值(跟 int64 和 float64 一样)
type MyInt int
var m MyInt = 5
v := reflect.ValueOf(m)
v.Kind() // reflect.Int
变量 v 的 Interface() 方法可以得到还原(接口)值,所以可以这样打印 v 的值:fmt.Println(v.Interface())
12.2 通过反射修改(设置)值
var x float64 = 3.4
v := reflect.ValueOf(x)
fmt.Println(v.Type())
fmt.Println(v.CanSet()) // false
// v.SetFloat(3.1414) //panic: reflect: reflect.Value.SetFloat using unaddressable value
// v = reflect.ValueOf(x) // panic: reflect: call of reflect.Value.Elem on float64 Value
v = reflect.ValueOf(&x)
fmt.Println(v.Type()) // *float64
v = v.Elem()
fmt.Println(v.CanSet()) // true
v.SetFloat(3.1415)
fmt.Println(v.Interface()) // 3.1415
fmt.Println(v.String()) // 3.1415
出现错误:reflect.Value.SetFloat using unaddressable value。
问题的原因是 v 不是可设置的(这里并不是说值不可寻址)。是否可设置是 Value 的一个属性,并且不是所有的反射值都有这个属性:可以使用 CanSet() 方法测试是否可设置。
v := reflect.ValueOf(x) 函数通过传递一个 x 拷贝创建了 v,那么 v 的改变并不能更改原始的 x。要想 v 的更改能作用到 x,那就必须传递 x 的地址 v = reflect.ValueOf(&x)。
要想让其可设置我们需要使用 Elem() 函数,这间接地使用指针:v = v.Elem()
反射中有些内容是需要用地址去改变它的状态的。
12.3 反射结构类型
有些时候需要反射一个结构类型。NumField() 方法返回结构内的字段数量;通过一个 for 循环用索引取得每个字段的值 Field(i)。
我们同样能够调用签名在结构上的方法,例如,使用索引 n 来调用:Method(n).Call(nil)。
type notKnownType struct {
s1, s2, s3 string
}
func (n notKnownType) String() string {
return n.s1 + "-" + n.s2 + "-" + n.s3
}
var secret interface{} = notKnownType{"Ada", "Oberon", "Go"}
func reflectTest02() {
value := reflect.ValueOf(secret)
typ := reflect.TypeOf(secret)
fmt.Println("type:", typ)
kind := value.Kind()
fmt.Println("kind:", kind)
for i := 0; i < value.NumField(); i++ {
fmt.Printf("field %d: %v\n", i, value.Field(i))
}
result := value.Method(0).Call(nil)
fmt.Println(result)
}
但是如果尝试更改一个值,会得到一个错误:
panic: reflect.Value.SetString using value obtained using unexported field
这是因为结构中只有被导出字段(首字母大写)才是可设置的
func reflectTest03() {
t := T{23, "abc"}
//v := reflect.ValueOf(t).Elem() // panic: reflect: call of reflect.Value.Elem on struct Value
v := reflect.ValueOf(&t).Elem()
t2 := v.Type()
for i := 0; i < v.NumField(); i++ {
f := v.Field(i)
fmt.Printf("%d: %s %s = %v\n", i, t2.Field(i).Name, f.Type(), f.Interface())
}
v.Field(0).SetInt(100)
v.Field(1).SetString("def")
fmt.Println("更改后的值:", v)
}
12.4 Printf() 和反射
在 Go 语言的标准库中,反射的功能被大量地使用。举个例子,fmt 包中的 Printf()(以及其他格式化输出函数)都会使用反射来分析它的 ... 参数。
func Printf(format string, args ... interface{}) (n int, err error)
Printf() 中的 ... 参数为空接口类型。Printf() 使用反射包来解析这个参数列表。所以,Printf() 能够知道它每个参数的类型。因此格式化字符串中只有 %d 而没有 %u 和 %ld,因为它知道这个参数是 unsigned 还是 long。这也是为什么 Print() 和 Println() 在没有格式字符串的情况下还能如此漂亮地输出。
12.5 接口与动态类型
12.5.1 Go 的动态类型
在经典的面向对象语言(像 C++,Java 和 C#)中数据和方法被封装为类的概念:类包含它们两者,并且不能剥离。
Go 没有类:数据(结构体或更一般的类型)和方法是一种松耦合的正交关系。
Go 中的接口跟 Java/C# 类似:都是必须提供一个指定方法集的实现。但是更加灵活通用:任何提供了接口方法实现代码的类型都隐式地实现了该接口,而不用显式地声明。
和其它语言相比,Go 是唯一结合了接口值,静态类型检查(是否该类型实现了某个接口),运行时动态转换的语言,并且不需要显式地声明类型是否满足某个接口。该特性允许我们在不改变已有的代码的情况下定义和使用新接口。
接收一个(或多个)接口类型作为参数的函数,其实参可以是任何实现了该接口的类型的变量。 实现了某个接口的类型可以被传给任何以此接口为参数的函数。
类似于 Python 和 Ruby 这类动态语言中的动态类型 (duck typing);这意味着对象可以根据提供的方法被处理(例如,作为参数传递给函数),而忽略它们的实际类型:它们能做什么比它们是什么更重要。
12.5.2 动态方法调用
像 Python,Ruby 这类语言,动态类型是延迟绑定的(在运行时进行):方法只是用参数和变量简单地调用,然后在运行时才解析
Go 的实现与此相反,通常需要编译器静态检查的支持:当变量被赋值给一个接口类型的变量时,编译器会检查其是否实现了该接口的所有函数。如果方法调用作用于像 interface{} 这样的“泛型”上,你可以通过类型断言(参见 11.3 节)来检查变量是否实现了相应接口。
Go 的接口提高了代码的分离度,改善了代码的复用性,使得代码开发过程中的设计模式更容易实现。用 Go 接口还能实现“依赖注入模式”。
12.5.3 接口的提取
提取接口是非常有用的设计模式,可以减少需要的类型和方法数量,而且不需要像传统的基于类的面向对象语言那样维护整个的类层次结构。
Go 接口可以让开发者找出自己写的程序中的类型。假设有一些拥有共同行为的对象,并且开发者想要抽象出这些行为,这时就可以创建一个接口来使用。
12.5.4 显式地指明类型实现了某个接口
如果你希望满足某个接口的类型显式地声明它们实现了这个接口,你可以向接口的方法集中添加一个具有描述性名字的方法。例如:
type Fooer interface {
Foo()
ImplementsFooer()
}
类型 Bar 必须实现 ImplementsFooer 方法来满足 Fooer 接口,以清楚地记录这个事实。
type Bar struct{}
func (b Bar) ImplementsFooer() {}
func (b Bar) Foo() {}
大部分代码并不使用这样的约束,因为它限制了接口的实用性。
但是有些时候,这样的约束在大量相似的接口中被用来解决歧义。
12.5.5 空接口和函数重载
Go语言中,函数重载是不被允许的。在 Go 语言中函数重载可以用可变参数 ...T 作为函数最后一个参数来实现。如果我们把 T 换为空接口,那么可以知道任何类型的变量都是满足 T (空接口)类型的,这样就允许我们传递任何数量任何类型的参数给函数,即重载的实际含义。
函数 fmt.Printf 就是这样做的:
fmt.Printf(format string, a ...interface{}) (n int, errno error)
这个函数通过枚举 slice 类型的实参动态确定所有参数的类型,并查看每个类型是否实现了 String() 方法,如果是就用于产生输出信息。
12.5.6 接口的继承
当一个类型包含(内嵌)另一个类型(实现了一个或多个接口)的指针时,这个类型就可以使用(另一个类型)所有的接口方法。
例如:
type Task struct {
Command string
*log.Logger
}
这个类型的工厂方法像这样:
func NewTask(command string, logger *log.Logger) *Task {
return &Task{command, logger}
}
当 log.Logger 实现了 Log() 方法后,Task 的实例 task 就可以调用该方法:
task.Log()
类型可以通过继承多个接口来提供像多重继承一样的特性:
type ReaderWriter struct {
*io.Reader
*io.Writer
}
上面概述的原理被应用于整个 Go 包,多态用得越多,代码就相对越少。这被认为是 Go 编程中的重要的最佳实践。
有用的接口可以在开发的过程中被归纳出来。添加新接口非常容易,因为已有的类型不用变动(仅仅需要实现新接口的方法)。已有的函数可以扩展为使用接口类型的约束性参数:通常只有函数签名需要改变。对比基于类的 OO 类型的语言在这种情况下则需要适应整个类层次结构的变化。
12.6 Go 中的面向对象
总结:Go 没有类,而是松耦合的类型、方法对接口的实现。
OO 语言最重要的三个方面分别是:封装、继承和多态,在 Go 中它们是怎样表现的呢?
-
封装(数据隐藏):和别的 OO 语言有 4 个或更多的访问层次相比,Go 把它简化为了 2 层):
1)包范围内的:通过标识符首字母小写,对象只在它所在的包内可见
2)可导出的:通过标识符首字母大写,对象对所在包以外也可见
类型只拥有自己所在包中定义的方法。
- 继承:用组合实现:内嵌一个(或多个)包含想要的行为(字段和方法)的类型;多重继承可以通过内嵌多个类型实现
- 多态:用接口实现:某个类型的实例可以赋给它所实现的任意接口类型的变量。类型和接口是松耦合的,并且多重继承可以通过实现多个接口实现。Go 接口不是 Java 和 C# 接口的变体,而且接口间是不相关的,并且是大规模编程和可适应的演进型设计的关键。
12.7 结构体、集合和高阶函数
通常在应用中定义了一个结构体,也可能需要这个结构体的(指针)对象集合,比如:
type Any interface{}
type Car struct {
Model string
Manufacturer string
BuildYear int
// ...
}
type Cars []*Car
然后我们就可以使用高阶函数,实际上也就是把函数作为定义所需方法(其他函数)的参数,例如:
1)定义一个通用的 Process() 函数,它接收一个作用于每一辆 car 的 f 函数作参数:
// Process all cars with the given function f:
func (cs Cars) Process(f func(car *Car)) {
for _, c := range cs {
f(c)
}
}
2)在上面的基础上,实现一个查找函数来获取子集合,并在 Process() 中传入一个闭包执行(这样就可以访问局部切片 cars):
// Find all cars matching a given criteria.
func (cs Cars) FindAll(f func(car *Car) bool) Cars {
cars := make([]*Car, 0)
cs.Process(func(c *Car) {
if f(c) {
cars = append(cars, c)
}
})
return cars
}
3)实现对应作用的功效 (Map-functionality),从每个 car 对象当中产出某些东西:
// Process cars and create new data.
func (cs Cars) Map(f func(car *Car) Any) []Any {
result := make([]Any, 0)
ix := 0
cs.Process(func(c *Car) {
result[ix] = f(c)
ix++
})
return result
}
现在我们可以定义下面这样的具体查询:
allNewBMWs := allCars.FindAll(func(car *Car) bool {
return (car.Manufacturer == "BMW") && (car.BuildYear > 2010)
})
4)我们也可以根据参数返回不同的函数。也许我们想根据不同的厂商添加汽车到不同的集合,但是这(这种映射关系)可能会是会改变的。所以我们可以定义一个函数来产生特定的添加函数和 map 集:
func MakeSortedAppender(manufacturers []string)(func(car *Car),map[string]Cars) {
// Prepare maps of sorted cars.
sortedCars := make(map[string]Cars)
for _, m := range manufacturers {
sortedCars[m] = make([]*Car, 0)
}
sortedCars["Default"] = make([]*Car, 0)
// Prepare appender function:
appender := func(c *Car) {
if _, ok := sortedCars[c.Manufacturer]; ok {
sortedCars[c.Manufacturer] = append(sortedCars[c.Manufacturer], c)
} else {
sortedCars["Default"] = append(sortedCars["Default"], c)
}
}
return appender, sortedCars
}
现在我们可以用它把汽车分类为独立的集合,像这样:
manufacturers := []string{"Ford", "Aston Martin", "Land Rover", "BMW", "Jaguar"}
sortedAppender, sortedCars := MakeSortedAppender(manufacturers)
allUnsortedCars.Process(sortedAppender)
BMWCount := len(sortedCars["BMW"])
十三、协程 (goroutine) 与通道 (channel)
Go 原生支持应用之间的通信(网络,客户端和服务端,分布式计算和程序的并发。程序可以在不同的处理器和计算机上同时执行不同的代码段。Go 语言为构建并发程序的基本代码块是协程 (goroutine) 与通道 (channel)。他们需要语言,编译器,和 runtime 的支持。Go 语言提供的垃圾回收器对并发编程至关重要。
不要通过共享内存来通信,而通过通信来共享内存。
通信强制协作。
13.1 什么是协程
一个应用程序是运行在机器上的一个进程;进程是一个运行在自己内存地址空间里的独立执行体。一个进程由一个或多个操作系统线程组成,这些线程其实是共享同一个内存地址空间的一起工作的执行体。
一个并发程序可以在一个处理器或者内核上使用多个线程来执行任务,但是只有同一个程序在某个时间点同时运行在多核或者多处理器上才是真正的并行。
并行是一种通过使用多处理器以提高速度的能力。所以并发程序可以是并行的,也可以不是。
公认的,使用多线程的应用难以做到准确,最主要的问题是内存中的数据共享,它们会被多线程以无法预知的方式进行操作,导致一些无法重现或者随机的结果(称作竞态)。
不要使用全局变量或者共享内存,它们会给你的代码在并发运算的时候带来危险。
解决之道在于同步不同的线程,对数据加锁,这样同时就只有一个线程可以变更数据。
Go 更倾向于其他的方式,在诸多比较合适的范式中,有个被称作 Communicating Sequential Processes(顺序通信处理)(CSP, C. Hoare 发明的)还有一个叫做 message passing-model(消息传递)(已经运用在了其他语言中,比如 Erlang)。
在 Go 中,应用程序并发处理的部分被称作 goroutines(协程),它可以进行更有效的并发运算。在协程和操作系统线程之间并无一对一的关系:协程是根据一个或多个线程的可用性,映射(多路复用,执行于)在他们之上的;协程调度器在 Go 运行时很好的完成了这个工作。
协程工作在相同的地址空间中:Go 使用 channels 来同步协程
协程是轻量的,比线程更轻:使用 4K 的栈内存就可以在堆中创建它们。
存在两种并发方式:确定性的(明确定义排序)和非确定性的(加锁/互斥从而未定义排序)。Go 的协程和通道理所当然的支持确定性的并发方式(例如通道具有一个 sender 和一个 receiver)
协程是通过使用关键字 go 调用(执行)一个函数或者方法来实现的(也可以是匿名或者 lambda 函数)。
协程的栈会根据需要进行伸缩,不出现栈溢出;开发者不需要关心栈的大小。当协程结束的时候,它会静默退出:用来启动这个协程的函数不会得到任何的返回值。
任何 Go 程序都必须有的 main() 函数也可以看做是一个协程,尽管它并没有通过 go 来启动
13.2 并发和并行的差异
并行是一种通过使用多处理器以提高速度的能力。
往往是,一个设计良好的并发程序在并行方面的表现也非常出色。
runtime.GOMAXPROCS()
这会告诉运行时有多少个协程同时执行。
环境变量 GOMAXPROCS`
更多的处理器并不意味着性能的线性提升。有这样一个经验法则,对于 n 个核心的情况设置 GOMAXPROCS 为 n-1 以获得最佳性能,也同样需要遵守这条规则:协程的数量 > 1 + GOMAXPROCS > 1。
所以如果在某一时间只有一个协程在执行,不要设置 GOMAXPROCS!
总结:GOMAXPROCS 等同于(并发的)线程数量,在一台核心数多于 1 个的机器上,会尽可能有等同于核心数的线程在并行运行。
协程可以通过调用 runtime.Goexit() 来停止
Goexit终止调用它的goroutine。没有其他goroutine受到影响。
Goexit在终止goroutine之前运行所有延迟调用。因为Goexit不是panic,所以这些延迟函数中的任何恢复调用都将返回nil。
协程按顺序启动,然后开始并行运行
协程是独立的处理单元,一旦陆续启动一些协程,你无法确定他们是什么时候真正开始执行的。你的代码逻辑必须独立于协程调用的顺序。
Go 协程 (goroutines) 和协程 (coroutines)
在其他语言中,比如 C#,Lua 或者 Python 都有协程的概念。这个名字表明它和 Go 协程有些相似,不过有两点不同:
- Go 协程意味着并行(或者可以以并行的方式部署),协程一般来说不是这样的
- Go 协程通过通道来通信;协程通过让出和恢复操作来通信
13.3 协程间的信道
协程间通信才会变得更有用:彼此之间发送和接收信息并且协调/同步他们的工作
通道(channel),就像一个可以用于发送类型化数据的管道,由其负责协程之间的通信,从而避开所有由共享内存导致的陷阱;这种通过通道进行通信的方式保证了同步性。数据在通道中进行传递:在任何给定时间,一个数据被设计为只有一个协程可以对其访问,所以不会发生数据竞争。 数据的所有权(可以读写数据的能力)也因此被传递。
通道服务于通信的两个目的:值的交换和同步,保证了两个计算(协程)任何时候都是可知状态。
声明通道:
var identifier chan datatype
通道也是引用类型。 未初始化的通道的值是 nil。
通道只能传输一种类型的数据,比如 chan int 或者 chan string,所有的类型都可以用于通道,空接口 interface{} 也可以,甚至可以(有时非常有用)创建通道的通道。
通道实际上是类型化消息的队列,它是先进先出(FIFO) 的结构
用 make() 函数来给它分配内存
var ch1 chan string
ch1 = make(chan string)
函数通道:funcChan := make(chan func())
通道是第一类对象:可以存储在变量中,作为函数的参数传递,从函数返回以及通过通道发送它们自身。另外它们是类型化的,允许类型检查,比如尝试使用整数通道发送一个指针。
通信操作符 <-
这个操作符直观的标示了数据的传输:信息按照箭头的方向流动。
流向通道(发送)
ch <- int1 表示:用通道 ch 发送变量 int1(双目运算符,中缀 = 发送)
从通道流出(接收),三种方式:
int2 := <- ch 表示:变量 int2 从通道 ch(一元运算的前缀操作符,前缀 = 接收)接收数据(获取新值)
虽非强制要求,但为了可读性通道的命名通常以 ch 开头或者包含 chan 。通道的发送和接收都是原子操作:它们总是互不干扰地完成。
x, ok := <-ch x为从通道中获取的值,ok为bool值,表示获取是否成功
func main() {
var chInt chan string
chInt = make(chan string)
go send(chInt)
go getData(chInt)
time.Sleep(9 * 1e9)
}
func send(ch chan string) {
ch <- "hello"
ch <- "world"
}
func getData(ch chan string) {
var input string
for {
input = <-ch
fmt.Printf("%s ", input)
}
}
如果 2 个协程需要通信,你必须给他们同一个通道作为参数才行。
getData() 使用了无限循环:它随着 send() 的发送完成和 ch 变空也结束了。
移除一个或所有 go 关键字,程序无法运行,Go 运行时会抛出 panic:
panic: all goroutines are asleep-deadlock!
为什么会这样?运行时 (runtime) 会检查所有的协程(像本例中只有一个)是否在等待着什么东西(可从某个通道读取或者写入某个通道),这意味着程序将无法继续执行。这是死锁 (deadlock) 的一种形式,而运行时 (runtime) 可以为我们检测到这种情况。
通道阻塞
默认情况下,通信是同步且无缓冲的(cap()为0)。无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通道要求发送goroutine 和接收goroutine 同时准备好,才能完成发送和接收操作。所以通道的发送/接收操作在对方准备好之前是阻塞的:
1)对于同一个通道,发送操作(协程或者函数中的),在接收者准备好之前是阻塞的:
2)对于同一个通道,接收操作是阻塞的(协程或函数中的),直到发送者可用:如果通道中没有数据,接收者就阻塞了。
通过一个(或多个)通道交换数据进行协程同步
通信是一种同步形式:通过通道,两个协程在通信(协程会合)中某刻同步交换数据。无缓冲通道成为了多个协程同步的完美工具。
甚至可以在通道两端互相阻塞对方,形成了叫做死锁(程序运行不下去)的状态。
异步通道-使用带缓冲的通道
给通道提供了一个缓存,可以在扩展的 make 命令中设置它的容量,如下:
buf := 100
ch1 := make(chan string, buf) // buf 是通道可以同时容纳的元素(这里是 `string`个数)
在缓冲满载(缓冲被全部使用)之前,给一个带缓冲的通道发送数据是不会阻塞的,而从通道读取数据也不会阻塞,直到缓冲空了。
内置的 cap() 函数可以返回缓冲区的容量。
缓冲容量和类型无关
如果容量大于 0,通道就是异步的了:缓冲满载(发送)或变空(接收)之前通信不会阻塞,元素会按照发送的顺序被接收。如果容量是 0 或者未设置,通信仅在收发双方准备好的情况下才可以成功。
同步:ch :=make(chan type, value)
- value == 0 -> synchronous, unbuffered (阻塞)
- value > 0 -> asynchronous, buffered(非阻塞)取决于 value 元素
在设计算法时首先考虑使用无缓冲通道,只在不确定的情况下使用缓冲。
协程中用通道输出结果
ch := make(chan int)
go sum(bigArray, ch) // bigArray puts the calculated sum on ch
// .. do something else for a while
sum := <- ch // wait for, and retrieve the sum
可以使用通道来达到同步的目的,这个很有效的用法在传统计算机中称为信号量 (semaphore)
或者换个方式:通过通道发送信号告知处理已经完成(在协程中)
在其他协程运行时让 main 程序无限阻塞的通常做法是在 main() 函数的最后放置一个 select {}
也可以使用通道让 main 程序等待协程完成,就是所谓的信号量模式
select
信号量模式
协程通过在通道 ch 中放置一个值来处理结束的信号。main() 协程等待 <-ch 直到从中获取到值。
func compute(ch chan int){
ch <- someComputation() // when it completes, signal on the channel.
}
func main(){
ch := make(chan int) // allocate a channel.
go compute(ch) // start something in a goroutines
doSomethingElseForAWhile()
result := <- ch
}
这个信号也可以是其他的,不返回结果
type Empty interface {}
var empty Empty
...
data := make([]float64, N)
res := make([]float64, N)
sem := make(chan Empty, N)
...
for i, xi := range data { // for 循环的每一个迭代是并行完成的:
go func (i int, xi float64) {
res[i] = doSomething(i, xi)
sem <- empty
} (i, xi)
}
// wait for goroutines to finish
for i := 0; i < N; i++ { <-sem }
上述代码中闭合函数的用法:i、xi 都是作为参数传入闭合函数的,从而向闭合函数内部屏蔽了外层循环中的 i 和 xi 变量
实现并行的 for 循环
如上例
在 for 循环中并行计算迭代可能带来很好的性能提升。
不过所有的迭代都必须是独立完成的
用带缓冲通道实现一个信号量
信号量是实现互斥锁(排外锁)常见的同步机制,限制对资源的访问,解决读写问题,比如没有实现信号量的 sync 的 Go 包,使用带缓冲的通道可以轻松实现:
- 带缓冲通道的容量和要同步的资源容量相同
- 通道的长度(当前存放的元素个数)与当前资源被使用的数量相同
- 容量减去通道的长度就是未处理的资源个数(标准信号量的整数值)
因此我们创建了一个长度可变但容量为 0(字节)的通道
type Empty interface {}
type semaphore chan Empty
直接对信号量进行操作:
// acquire n resources
func (s semaphore) P(n int) {
e := new(Empty)
for i := 0; i < n; i++ {
s <- e
}
}
// release n resources
func (s semaphore) V(n int) {
for i:= 0; i < n; i++{
<- s
}
}
实现一个互斥的例子
/* mutexes */
func (s semaphore) Lock() {
s.P(1)
}
func (s semaphore) Unlock(){
s.V(1)
}
/* signal-wait */
func (s semaphore) Wait(n int) {
s.P(n)
}
func (s semaphore) Signal() {
s.V(1)
}
// integer producer:
func numGen(start, count int, out chan<- int) {
for i := 0; i < count; i++ {
out <- start
start = start + count
}
close(out)
}
习惯用法:通道工厂模式
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
go func() {
for v := range ch { //通道使用 for 循环
fmt.Println(v)
}
}()
}
func main() {
ch := pump()
suck(ch)
time.Sleep(2e9)
}
给通道使用 for 循环
for 循环的 range 语句可以用在通道 ch 上,便可以从通道中获取值
for v := range ch {
fmt.Printf("The value is %v\n", v)
}
习惯用法:通道迭代器模式
通常,需要从包含了地址索引字段 items 的容器给通道填入元素。为容器的类型定义一个方法 Iter(),返回一个只读的通道items,如下:
func (c *container) Iter () <- chan item {
ch := make(chan item)
go func () {
for i:= 0; i < c.Len(); i++{ // or use a for-range loop
ch <- c.items[i]
}
} ()
return ch
}
调用这个方法的代码可以这样迭代容器:
for x := range container.Iter() { ... }
迭代运行在自己启动的协程中,所以上边的迭代用到了一个通道和两个协程(可能运行在不同的线程上)。 这样我们就有了一个典型的生产者-消费者模式。如果在程序结束之前,向通道写值的协程未完成工作,则这个协程不会被垃圾回收;这是设计使然。这种看起来并不符合预期的行为正是由通道这种线程安全的通信方式所导致的。如此一来,一个协程为了写入一个永远无人读取的通道而被挂起就成了一个 bug ,而并非你预想中的那样被悄悄回收掉 (garbage-collected) 了。
两个协程经常是一个阻塞另外一个。如果程序工作在多核心的机器上,大部分时间只用到了一个处理器。可以通过使用带缓冲(缓冲空间大于 0)的通道来改善。
习惯用法:生产者消费者模式
for {
Consume(Produce())
}
通道的方向
通道类型可以用注解来表示它只发送或者只接收:
var send_only chan<- int // channel can only send data
var recv_only <-chan int // channel can only receive data
只接收的通道 (<-chan T) 无法关闭,因为关闭通道是发送者用来表示不再给通道发送值了,所以对只接收通道是没有意义的。
通道创建的时候都是双向的,但也可以分配给有方向的通道变量
var c = make(chan int) // bidirectional
go source(c)
go sink(c)
func source(ch chan<- int){
for { ch <- 1 }
}
func sink(ch <-chan int) {
for { <-ch }
}
习惯用法:管道和选择器模式
Go 指导的很赞的例子,打印了输出的素数,使用选择器(‘筛’)作为它的算法。每个 prime 都有一个选择器。

func generate(ch chan int) {
for i := 2; ; i++ {
ch <- i
}
}
func filter(in, out chan int, prime int) {
for {
i := <-in
if i%prime != 0 {
out <- i
}
}
}
func main() {
ch := make(chan int)
go generate(ch)
for {
prime := <-ch
fmt.Print(prime, " ")
ch1 := make(chan int)
go filter(ch, ch1, prime)
ch = ch1
time.Sleep(1e9)
}
}
版本二:
// Send the sequence 2, 3, 4, ... to returned channel
func generate() chan int {
ch := make(chan int)
go func() {
for i := 2; ; i++ {
ch <- i
}
}()
return ch
}
// Filter out input values divisible by 'prime', send rest to returned channel
func filter(in chan int, prime int) chan int {
out := make(chan int)
go func() {
for {
if i := <-in; i%prime != 0 {
out <- i
}
}
}()
return out
}
func sieve() chan int {
out := make(chan int)
go func() {
ch := generate()
for {
prime := <-ch
ch = filter(ch, prime)
out <- prime
}
}()
return out
}
func main() {
primes := sieve()
for {
fmt.Println(<-primes)
}
}
13.4 协程的同步:关闭通道-测试阻塞的通道
通道可以被显式的关闭;尽管它们和文件不同:不必每次都关闭。只有在当需要告诉接收者不会再提供新的值的时候,才需要关闭通道。只有发送者需要关闭通道,接收者永远不会需要。
在创建一个通道后使用 defer 语句是个不错的办法:
ch := make(chan float64)
defer close(ch)
close(ch) :这个将通道标记为无法通过发送操作 <- 接受更多的值;给已经关闭的通道发送或者再次关闭都会导致运行时的 panic()
如何来检测可以收到没有被阻塞(或者通道没有被关闭)?
使用逗号 ok 模式用来检测通道是否被关闭
v, ok := <-ch // ok is true if v received value
if v, ok := <-ch; ok {
process(v)
}
检测通道当前是否阻塞,需要使用 select
select {
case v, ok := <-ch:
if ok {
process(v)
} else {
fmt.Println("The channel is closed")
}
default:
fmt.Println("The channel is blocked")
}
实现非阻塞通道的读取,需要使用 select
使用 for-range 语句来读取通道是更好的办法,因为这会自动检测通道是否关闭:
for input := range ch {
process(input)
}
func source() chan int {
ch := make(chan int)
go func() {
for i := 0; i < 5; i++ {
ch <- i
}
close(ch)
fmt.Println("通道关闭。。。")
}()
return ch
}
func main() {
ch := source()
for v := range ch {
fmt.Println("获取到的值为: ", v)
}
time.Sleep(1e9)
fmt.Println("main 结束。")
}
结果:
获取到的值为: 0
获取到的值为: 1
获取到的值为: 2
获取到的值为: 3
获取到的值为: 4
通道关闭。。。
main 结束。
阻塞和生产者-消费者模式:
前面通道迭代器中,两个协程经常是一个阻塞另外一个。如果程序工作在多核心的机器上,大部分时间只用到了一个处理器。可以通过使用带缓冲(缓冲空间大于 0)的通道来改善。
由于容器中元素的数量通常是已知的,需要让通道有足够的容量放置所有的元素。这样,迭代器就不会阻塞(尽管消费者协程仍然可能阻塞)。然而,这实际上加倍了迭代容器所需要的内存使用量,所以通道的容量需要限制一下最大值。记录运行时间和性能测试可以帮助你找到最小的缓存容量带来最好的性能。
13.5 使用 select 切换协程
从不同的并发执行的协程中获取值可以通过关键字 select 来完成。也被称作通信开关。
它的行为像是“你准备好了吗”的轮询机制。
select 监听进入通道的数据,也可以是用通道发送值的时候。
select {
case u:= <- ch1:
...
case v:= <- ch2:
...
...
default: // no value ready to be received
...
}
default 语句是可选的;fallthrough 行为,和普通的 switch 相似,是不允许的。在任何一个 case 中执行 break (退出本次)或者 return(结束协程),select 就结束了。
select 做的就是:选择处理列出的多个通信情况中的一个。
- 如果都阻塞了,会等待直到其中一个可以处理
- 如果多个可以处理,随机选择一个
- 如果没有通道操作可以处理并且写了
default语句,它就会执行:default永远是可运行的。
在 select 中使用发送操作并且有 default 可以确保发送不被阻塞!如果没有 default,select 就会一直阻塞。
select 语句实现了一种监听模式,通常用在(无限)循环中;
需要注意在有多个 case 符合条件时, select 对 case 的选择是伪随机的
func suck(ch1, ch2 chan int) {
for {
select {
case v, ok := <-ch1:
if ok {
fmt.Printf("Received on channel 1: %d\n", v)
}
case v := <-ch2:
fmt.Printf("Received on channel 2: %d\n", v)
}
}
}
习惯用法:后台服务模式
服务通常是是用后台协程中的无限循环实现的,在循环中使用 select 获取并处理通道中的数据:
// Backend goroutine.
func backend() {
for {
select {
case cmd := <-ch1:
// Handle ...
case cmd := <-ch2:
...
case cmd := <-chStop:
// stop server
}
}
}
另一种方式(但是不太灵活)就是(客户端)在 chRequest 上提交请求,后台协程循环这个通道,使用 switch 根据请求的行为来分别处理:
func backend() {
for req := range chRequest {
switch req.Subjext() {
case A1: // Handle case ...
case A2: // Handle case ...
default:
// Handle illegal request ..
// ...
}
}
}
13.6 通道、超时和计时器(Ticker)
time 包中 time.Ticker 结构体,这个对象以指定的时间间隔重复的向通道 C 发送时间值
type Ticker struct {
C <-chan Time // the channel on which the ticks are delivered.
// contains filtered or unexported fields
...
}
时间间隔的单位是 ns(纳秒,int64),在工厂函数 time.NewTicker 中以 Duration 类型的参数传入:func NewTicker(dur) *Ticker。
在协程周期性的执行一些事情(打印状态日志,输出,计算等等)的时候非常有用。
ticker := time.NewTicker(updateInterval)
defer ticker.Stop()
...
select {
case u:= <-ch1:
...
case v:= <-ch2:
...
case <-ticker.C:
logState(status) // call some logging function logState
default: // no value ready to be received
...
}
习惯用法:简单超时模式
要从通道 ch 中接收数据,但是最多等待 1 秒。
timeout := make(chan bool, 1)
go func() {
time.Sleep(1e9) // one second
timeout <- true
}()
然后使用 select 语句接收 ch 或者 timeout 的数据:如果 ch 在 1 秒内没有收到数据,就选择到了 timeout 分支并放弃了 ch 的读取。
select {
case <-ch:
// a read from ch has occured
case <-timeout:
// the read from ch has timed out
break
}
第二种形式:取消耗时很长的同步调用
可以使用 time.After() 函数替换 timeout-channel
ch := make(chan error, 1)
go func() { ch <- client.Call("Service.Method", args, &reply) } ()
select {
case resp := <-ch
// use resp and reply
case <-time.After(timeoutNs):
// call timed out
break
}
在 timeoutNs 纳秒后执行 select 的 timeout 分支后,执行 client.Call 的协程也随之结束,不会给通道 ch 返回值
注意缓冲大小设置为 1 是必要的,可以避免协程死锁以及确保超时的通道可以被垃圾回收。
第三种形式:假设程序从多个复制的数据库同时读取。只需要一个答案,需要接收首先到达的答案,Query 函数获取数据库的连接切片并请求。并行请求每一个数据库并返回收到的第一个响应:
func Query(conns []Conn, query string) Result {
ch := make(chan Result, 1)
for _, conn := range conns {
go func(c Conn) {
select {
case ch <- c.DoQuery(query):
default:
}
}(conn)
}
return <- ch
}
13.7 协程和恢复 (recover)
停掉了服务器内部一个失败的协程而不影响其他协程的工作
func server(workChan <-chan *Work) {
for work := range workChan {
go safelyDo(work) // start the goroutine for that work
}
}
func safelyDo(work *Work) {
defer func() {
if err := recover(); err != nil {
log.Printf("Work failed with %s in %v", err, work)
}
}()
do(work)
}
如果 do(work) 发生 panic(),错误会被记录且协程会退出并释放,而其他协程不受影响。
defer 修饰的代码可以调用那些自身可以使用 panic() 和 recover() 避免失败的库例程(库函数)。如:safelyDo() 中 defer 修饰的函数可能在调用 recover() 之前就调用了一个 logging() 函数,panicking 状态不会影响 logging() 代码的运行。因为加入了恢复模式,函数 do()(以及它调用的任何东西)可以通过调用 panic() 来摆脱不好的情况。但是恢复是在 panicking 的协程内部的:不能被另外一个协程恢复。
13.8 新旧模型对比:任务和 worker
假设我们需要处理很多任务;一个 worker 处理一项任务。
type Task struct {
// some state
}
旧模式:使用共享内存进行同步
由各个任务组成的任务池共享内存;为了同步各个 worker 以及避免资源竞争,我们需要对任务池进行加锁保护:
type Pool struct {
Mu sync.Mutex
Tasks []*Task
}
sync.Mutex 是互斥锁:它用来在代码中保护临界区资源
新模式:使用通道
对一个通道读数据和写数据的整个过程是原子性的
使用通道进行同步:使用一个通道接受需要处理的任务,一个通道接受处理完成的任务(及其结果)
主线程扮演着 Master 节点角色:
func main() {
pending, done := make(chan *Task), make(chan *Task)
go sendWork(pending) // put tasks with work on the channel
for i := 0; i < N; i++ { // start N goroutines to do work
go Worker(pending, done)
}
consumeWork(done) // continue with the processed tasks
}
worker 的逻辑比较简单:从 pending 通道拿任务,处理后将其放到 done 通道中:
func Worker(in, out chan *Task) {
for {
t := <-in
process(t)
out <- t
}
}
对于任何可以建模为 Master-Worker 范例的问题,一个类似于 worker 使用通道进行通信和交互、Master 进行整体协调的方案都能完美解决。如果系统部署在多台机器上,各个机器上执行 Worker 协程,Master 和 Worker 之间使用 netchan 或者 RPC 进行通信
怎么选择是该使用锁还是通道?
-
使用锁的情景:
- 访问共享数据结构中的缓存信息
- 保存应用程序上下文和状态信息数据
-
使用通道的情景:
- 与异步操作的结果进行交互
- 分发任务
- 传递数据所有权
当你发现你的锁使用规则变得很复杂时,可以反省使用通道会不会使问题变得简单些。
13.9 惰性生成器的实现
生成器是指当被调用时返回一个序列中下一个值的函数,例如:
generateInteger() => 0
generateInteger() => 1
generateInteger() => 2
....
生成器每次返回的是序列中下一个值而非整个序列;这种特性也称之为惰性求值:只在你需要时进行求值,同时保留相关变量资源(内存和 CPU):这是一项在需要时对表达式进行求值的技术
生成一个无限数量的自然数序列:
var resume chan int
func integers() chan int {
yield := make(chan int)
count := 0
go func() {
for {
yield <- count
count++
}
}()
return yield
}
func generateInteger() int {
return <-resume
}
有一个细微的区别是从通道读取的值可能会是稍早前产生的,并不是在程序被调用时生成的。如果确实需要这样的行为,就得实现一个请求响应机制。当生成器生成数据的过程是计算密集型且各个结果的顺序并不重要时,那么就可以将生成器放入到 go 协程实现并行化。
这些原则可以概括为:通过巧妙地使用空接口、闭包和高阶函数,我们能实现一个通用的惰性生产器的工厂函数 BuildLazyEvaluator
type Any interface{}
type EvalFunc func(Any) (Any, Any)
func main() {
evenFunc := func(state Any) (Any, Any) {
os := state.(int)
ns := os + 2
return os, ns
}
even := BuildLazyIntEvaluator(evenFunc, 0)
for i := 0; i < 10; i++ {
fmt.Printf("%vth even: %v\n", i, even())
}
}
func BuildLazyEvaluator(evalFunc EvalFunc, initState Any) func() Any {
retValChan := make(chan Any)
loopFunc := func() {
var actState Any = initState
var retVal Any
for {
retVal, actState = evalFunc(actState)
retValChan <- retVal
}
}
retFunc := func() Any {
return <- retValChan
}
go loopFunc()
return retFunc
}
func BuildLazyIntEvaluator(evalFunc EvalFunc, initState Any) func() int {
ef := BuildLazyEvaluator(evalFunc, initState)
return func() int {
return ef().(int)
}
}
13.10 实现 Futures 模式
所谓 Futures 就是指:有时候在你使用某一个值之前需要先对其进行计算。这种情况下,你就可以在另一个处理器上进行该值的计算,到使用时,该值就已经计算完毕了。
Futures 模式通过闭包和通道可以很容易实现,类似于生成器,不同地方在于 Futures 需要返回一个值。
计算两个矩阵 A 和 B 乘积的逆:
func InverseProduct(a Matrix, b Matrix) {
a_inv_future := InverseFuture(a) // start as a goroutine
b_inv_future := InverseFuture(b) // start as a goroutine
a_inv := <-a_inv_future
b_inv := <-b_inv_future
return Product(a_inv, b_inv)
}
func InverseFuture(a Matrix) chan Matrix {
future := make(chan Matrix)
go func() {
future <- Inverse(a)
}()
return future
}
当开发一个计算密集型库时,使用 Futures 模式设计 API 接口是很有意义的。
13.11 典型的客户端/服务器(C/S)模式
客户端-服务器应用正是 goroutines 和 channels 的亮点所在。
使用 Go 的服务器通常会在协程中执行向客户端的响应,故而会对每一个客户端请求启动一个协程。一个常用的操作方法是客户端请求自身中包含一个通道,而服务器则向这个通道发送响应。
type Reply struct{...}
type Request struct{
arg1, arg2, arg3 some_type
replyc chan *Reply
}
服务器会为每一个请求启动一个协程并在其中执行 run() 函数
type binOp func(a, b int) int
func run(op binOp, req *Request) {
req.replyc <- op(req.a, req.b)
}
func server(op binOp, service chan *Request) {
for {
req := <-service; // requests arrive here
// start goroutine for request:
go run(op, req); // don’t wait for op to complete
}
}
func startServer(op binOp) chan *Request {
reqChan := make(chan *Request);
go server(op, reqChan);
return reqChan;
}
func main() {
adder := startServer(func(a, b int) int { return a + b })
const N = 100
var reqs [N]Request
for i := 0; i < N; i++ {
req := &reqs[i]
req.a = i
req.b = i + N
req.replyc = make(chan int)
adder <- req // adder is a channel of requests
}
}
卸载 (Teardown):通过信号通道关闭服务器
在上一个版本中 server() 在 main() 函数返回后并没有完全关闭,而被强制结束了。
func startServer(op binOp) (service chan *Request, quit chan bool) {
service = make(chan *Request)
quit = make(chan bool)
go server(op, service, quit)
return service, quit
}
server() 函数现在则使用 select 在 service 通道和 quit 通道之间做出选择:
func server(op binOp, service chan *request, quit chan bool) {
for {
select {
case req := <-service:
go run(op, req)
case <-quit:
return
}
}
}
当 quit 通道接收到一个 true 值时,server 就会返回并结束。
在 main() 函数中我们做出如下更改:
adder, quit := startServer(func(a, b int) int { return a + b })
在 main() 函数的结尾处我们放入这一行:quit <- true
限制同时处理的请求数
使用带缓冲区的通道很容易实现这一点,其缓冲区容量就是同时处理请求的最大数量。
const MAXREQS = 50
var sem = make(chan int, MAXREQS)
type Request struct {
a, b int
replyc chan int
}
func process(r *Request) {
// do something
}
func handle(r *Request) {
sem <- 1 // doesn't matter what we put in it
process(r)
<-sem // one empty place in the buffer: the next request can start
}
func server(service chan *Request) {
for {
request := <-service
go handle(request)
}
}
func main() {
service := make(chan *Request)
go server(service)
}
通过这种方式,应用程序可以通过使用缓冲通道(通道被用作信号量)使协程同步其对该资源的使用,从而充分利用有限的资源(如内存)。
13.12 链式协程
展示了启动巨量的 Go 协程是多么容易
var numGoroutine = flag.Int("n", 100000, "How many goroutines")
func q(left, right chan int) {
left <- 1 + <-right
}
func main() {
flag.Parse()
leftmost := make(chan int)
var left, right chan int = nil, leftmost
log.Println("启动协程。。。")
for i := 0; i < *numGoroutine; i++ {
left, right = right, make(chan int)
go q(left, right)
}
log.Println("协程启动完毕。。。")
right <- 0
x := <-leftmost
log.Println("结果为:", x) // 100000 about <1s
}
这些协程已全部在 main() 函数中的 for 循环里启动。当循环完成之后,一个 0 被写入到最右边的通道里,于是 100,000 个协程开始执行,接着 100000 这个结果会在 1 秒之内被打印出来。
13.13 在多核心上并行计算
假设有 NCPU 个 CPU 核心:const NCPU = 4 //对应一个四核处理器 然后我们想把计算量分成 NCPU 个部分,每一个部分都和其他部分并行运行。
func DoAll(){
sem := make(chan int, NCPU) // Buffering optional but sensible
for i := 0; i < NCPU; i++ {
go DoPart(sem)
}
// Drain the channel sem, waiting for NCPU tasks to complete
for i := 0; i < NCPU; i++ {
<-sem // wait for one task to complete
}
// All done.
}
func DoPart(sem chan int) {
// do the part of the computation
sem <-1 // signal that this piece is done
}
func main() {
runtime.GOMAXPROCS(NCPU) // runtime.GOMAXPROCS = NCPU
DoAll()
}
sem 通道就像一个信号量,这份代码展示了一个经典的信号量模式
13.14 并行化大量数据的计算
假设我们需要处理一些数量巨大且互不相关的数据项,它们从一个 in 通道被传递进来,当我们处理完以后又要将它们放入另一个 out 通道,就像一个工厂流水线一样。处理每个数据项也可能包含许多步骤:
Preprocess(预处理) / StepA(步骤A) / StepB(步骤B) / … / PostProcess(后处理)
一个更高效的计算方式是让每一个处理步骤作为一个协程独立工作。每一个步骤从上一步的输出通道中获得输入数据。这种方式仅有极少数时间会被浪费,而大部分时间所有的步骤都在一直执行中:
func ParallelProcessData (in <-chan *Data, out chan<- *Data) {
// make channels:
preOut := make(chan *Data, 100)
stepAOut := make(chan *Data, 100)
stepBOut := make(chan *Data, 100)
stepCOut := make(chan *Data, 100)
// start parallel computations:
go PreprocessData(in, preOut)
go ProcessStepA(preOut,StepAOut)
go ProcessStepB(StepAOut,StepBOut)
go ProcessStepC(StepBOut,StepCOut)
go PostProcessData(StepCOut,out)
}
通道的缓冲区大小可以用来进一步优化整个过程。
13.15 漏桶算法
考虑以下的客户端-服务器结构:客户端协程从某个源头(也许是网络)接收数据;数据读取到 Buffer 类型的缓冲区。为了避免分配过多的缓冲区以及释放缓冲区,它保留了一份空闲缓冲区列表,并且使用一个缓冲通道来表示这个列表:var freeList = make(chan *Buffer,100)
这个可重用的缓冲区队列 (freeList) 与服务器是共享的。 当接收数据时,客户端尝试从 freeList 获取缓冲区;但如果此时通道为空,则会分配新的缓冲区。一旦消息被加载后,它将被发送到服务器上的 serverChan 通道:
var serverChan = make(chan *Buffer)
以下是客户端的算法代码:
func client() {
for {
var b *Buffer
// Grab a buffer if available; allocate if not
select {
case b = <-freeList:
// Got one; nothing more to do
default:
// None free, so allocate a new one
b = new(Buffer)
}
loadInto(b) // Read next message from the network
serverChan <- b // Send to server
}
}
服务器的循环则接收每一条来自客户端的消息并处理它,之后尝试将缓冲返回给共享的空闲缓冲区:
func server() {
for {
b := <-serverChan // Wait for work.
process(b)
// Reuse buffer if there's room.
select {
case freeList <- b:
// Reuse buffer if free slot on freeList; nothing more to do
default:
// Free list full, just carry on: the buffer is 'dropped'
}
}
}
但是这种方法在 freeList 通道已满的时候是行不通的,因为无法放入空闲 freeList 通道的缓冲区会被“丢到地上”由垃圾收集器回收(故名:漏桶算法)。
13.16 对 Go 协程进行基准测试
func main() {
fmt.Println("Sync:", testing.Benchmark(BenchmarkChannelSync).String())
fmt.Println("Buffered:", testing.Benchmark(BenchmarkChannelBuffered).String())
}
func BenchmarkChannelSync(b *testing.B) {
ch := make(chan int)
go func() {
for i := 0; i < b.N; i++ {
ch <- i
}
close(ch)
}()
for range ch {
}
}
func BenchmarkChannelBuffered(b *testing.B) {
ch := make(chan int, 100)
go func() {
for i := 0; i < b.N; i++ {
ch <- i
}
close(ch)
}()
for range ch {
}
}
Sync: 5192534 237.0 ns/op
Buffered: 18510776 63.96 ns/op
13.17 使用通道并发访问对象
type Person struct {
name string
salary float64
chF chan func()
}
func NewPerson(name string, salary float64) *Person {
p := &Person{name, salary, make(chan func())}
go p.backend()
return p
}
func (p *Person) backend() {
for f2 := range p.chF {
f2()
}
}
func (p *Person) SetSalary(salary float64) {
p.chF <- func() {
p.salary = salary
}
}
func (p *Person) Salary() float64 {
fChan := make(chan float64)
p.chF <- func() {
fChan <- p.salary
}
return <-fChan
}
func (p *Person) String() string {
return "Person - name: " + p.name + "- salary: " + strconv.FormatFloat(p.Salary(), 'f', 2, 64)
}
func main() {
person := NewPerson("William", 1800.09)
fmt.Println("初始:", person)
person.SetSalary(1900.78)
fmt.Println("修改后:", person)
}
为了保护对象被并发访问修改,我们可以使用协程在后台顺序执行匿名函数来替代使用同步互斥锁。在程序中我们有一个类型 Person 中包含一个字段 chF ,这是一个用于存放匿名函数的通道。
浅谈golang for 循环中使用协程的问题
go语言内置的goroutine池