解决吞吐问题,拒绝吞吞吐吐!理论加持,一鼓作气!
导读
本文介绍我们在遇到海东青主从模式下写入吞吐降低一倍的问题时,尝试一些处理方式却无济于事,在通过理清并发、QPS、响应时间之间的关系得出经验理论后,才得以帮助我们找到问题的原因,最终解决QPS降低的问题。
本文中的经验理论(以及结尾附带的性能优化经验)可以用到所有程序架构中,不需要读者具备数据库经验,希望能对大家有所帮助,如有疑问或意见,可在评论区留言或加群探讨。
全文5500余字,预计阅读时间15分钟。其中章节4和章节5是本文重点。
本文章节简要大纲:
01. 介绍主从模式下数据写入的吞吐问题
02. 介绍海东青单主模式和主从模式下的数据写入流程
03. 介绍使用一些方式进行优化,但并没有解决问题
04. 梳理并发、QPS、响应时间之间的关系
05. 应用章节04重新分析问题,最终找到问题模块并解决问题
06. 分享一些性能优化和问题处理方面的经验
07. 结语
1. 问题
在介绍问题之前,我们先介绍两个名称:
1. 主从模式:由一个海东青主节点和一个从节点组成,采用同步复制。硬件均为64核、128G内存、SSD
2. 单主模式:只有一个海东青节点,也为主节点,硬件为64核、128G内存、SSD
测试同学分别在海东青主从模式和单主模式下,对车载场景的数据写入进行性能测试,结果发现:主从模式下数据写入的QPS相比较单主模式降低了一倍。测试结果如下图所示:

通过报告以及机器监控得到了以下三个信息:
1、主从模式下的CPU和IO资源利用率相比较单主时降低了一倍。
2、主从模式下的写入响应延迟相比较单主时增加了一倍。
3、主从模式下增加请求的并发数没有增加QPS(且系统资源并没有达到瓶颈)。
第三点是我们最为疑惑的问题,本文要解决的问题也就是希望在资源没有达到瓶颈的时候,能通过增加并发请求数提高主从模式下的写入QPS,充分发挥硬件能力。
2. 写入流程介绍
因为是写入QPS存在问题,因此问题通常是由于写入流程的某些环节所导致(或者至少是其相关联模块间接影响),所以我们先介绍一下目前海东青的写入流程。
2.1 单主写入流程
首先看下图所示的单主时的写入流程:
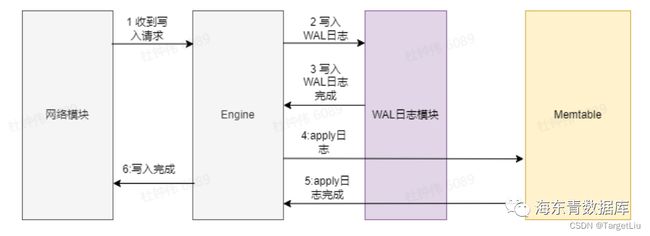
单个写入请求的响应时间可以简单的表示为:
WriteWAL(IO)
+ ApplyLog(CPU)
// IO表示磁盘IO类型开销
// CPU则表示CPU计算开销,
// 下文会出现Network,表示网络通信开销
本文为了简单起见,且不影响本文理论分析,公式除去了和客户端通信、排队、内存分配、获取锁等开销时间。
WAL为预写日志,它是数据库在处理写入请求时将随机写转换为顺序写的手段(也可理解为操作日志,通常将日志写入WAL成功就可以认为完成数据写入请求),其中写入的每一个日志对象称之为LogEntry。可参考:https://zh.wikipedia.org/zh-cn/%E9%A2%84%E5%86%99%E5%BC%8F%E6%97%A5%E5%BF%97。
Memtable为内存数据表,其中存放最近成功写入的数据(写入WAL即可认为成功),它可用于后续的数据持久化(刷脏)和数据查询请求。
2.2 主从写入流程
主从模式下的写入流程为:
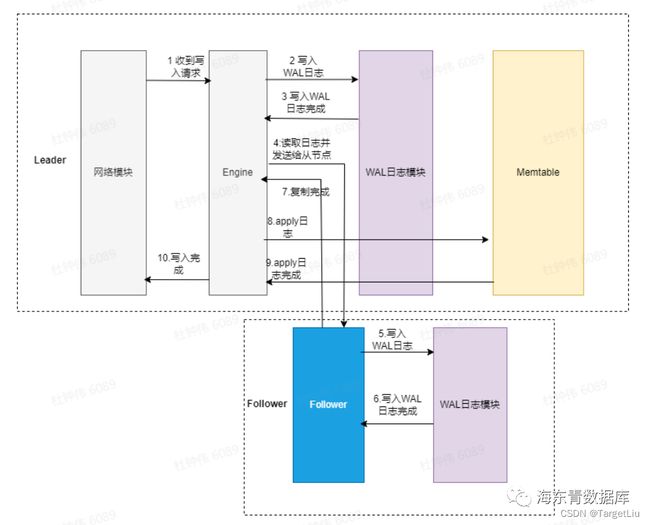
(图例为同步复制模式。图例中的Leader表示主节点,Follower表示从节点)
写入的响应时间最理想情况可以表示为:
WriteWAL(IO)
+ ReadWAL(IO)
+ SendReplicaLog(Network)
+ WriteWAL(IO)
+ ReplyReplica(Network)
+ ApplyLog(CPU)
// 第一个WriteWAL是主节点写WAL
// 第二个WriteWAL是从节点写WAL
// SendReplicaLog 表示主节点通过网络发送WAL日志给从节点
// ReplyReplica(Network) 表示从节点回应主节点但由于目前的主从同步的日志复制是串行的,即同一时间只有一个in-flight 日志复制(可理解为线头阻塞:https://en.wikipedia.org/wiki/Head-of-line_blocking)。
那么就可能会出现:在主节点处理当前写入请求写入LogEntry时,主节点已经刚发送一批LogEntry日志给从节点(这是处理上一轮写入请求所产生的),那么此时写入的LogEntry就必须等到在收到从节点下一轮的复制请求后才会发送给从节点(此请求也携带了从节点的复制状态)。
因此主从模式下单个写入请求的延迟最差情况可表示为:
WriteWAL(IO)
+ ReadWAL(IO)
+ SendLog(Network) // 源于上一轮写入请求
+ WriteWAL(IO) // 源于上一轮写入请求
+ ReplyReplica(Network) // 源于上一轮写入请求
+ SendLog(Network)
+ WriteWAL(IO)
+ ReplyReplica(Network)
+ ApplyLog(CPU)3. 快速排查验证
(如果对数据库本身的实现不感兴趣,可以跳过本章节,直接进入第四章节,不会影响本文阅读)
通过对写入流程的分析,我们尝试以下两个快速排查方法。(自以为可以解决问题~~哈哈哈哈)
3.1 主节点流式发送日志
通过修改GRPC服务接口协议,让主节点采用stream方式同步日志给从节点(期望能避免线头阻塞),并且去掉了发送日志前读取WAL日志的环节,省掉了IO开销。
性能测试结果如下:
2022/04/12 05:31:30 Has writen 7464000 point, 5932.75MB (mean point rate 19601.43/sec, value rate 1176086.02/s, 15.58MB/sec in this 5.00 sec)
2022/04/12 05:31:33 Total write 7528000 points, 5983.62MB in 302.45sec (mean point rate 24889.92/sec, mean value rate 1493395.13/s, 19.78MB/sec)
Label P50(ms) P90(ms) P95(ms) P99(ms) Min(ms) Max(ms) Avg(ms) Fail Total RunSec(s) Qps
write 2501.1 3440.7 3850 4698.1 650.8 8365.8 2556.4 0 7528 302.452 24.89
2022/04/12 05:31:33 CPU: 64核; CPU架构: amd64; 内存: 126G; 操作系统: linux;从结果来看,并没有解决问题。
3.2 从节点不写WAL
这一次,我们直接省去从节点写WAL的延迟开销,这样就可以尽快响应主节点发起下一轮复制请求,让主节点能够尽快发送下一批日志给从节点,希望以此提高QPS。
这是一个POC验证,如果测试结果能有所改进,就可以进一步沿着这个方向做真正正确的优化。
测试结果如下:
2022/04/14 04:08:43 Total write 8356000 points, 6641.76MB in 329.67sec (mean point rate 25346.80/sec, mean value rate 1520807.77/s, 20.15MB/sec)
Label P50(ms) P90(ms) P95(ms) P99(ms) Min(ms) Max(ms) Avg(ms) Fail Total RunSec(s) Qps
write 2643.3 3497.1 3896.6 4855.1 564.5 5665.3 2308 1 8357 329.667 25.347
2022/04/14 04:08:43 CPU: 64核; CPU架构: amd64; 内存: 126G; 操作系统: linux;结果仍然无济于事。
从这两种快速修改方式(以及尝试了一些其他的方式,在此省去)的结果来看,吞吐并没有得到提升。
4. 上升理论:并发、响应、QPS
在快速排查没有解决问题后,我陷入了迷茫,明明优化了一些模块的处理开销,为什么还是无法提高QPS呢!是我的认知出了问题么?于是我尝试整理问题相关指标的计算关系(主要是响应时间、QPS、并发、并行之间的关系),期望通过这些关系来帮助我们重新审视问题以找到原因所在。

我们以上图举例来阐述理论相关计算公式,先对此图表示的系统有如下定义/约定:
1. 系统由三个模块组成(分别称为A、B、C)。
2. 每个模块有且只有一个线程。
3. 每个模块有着不同的线程。(所有模块并行执行)
4. 一个请求经由A -> B -> C 三个模块处理后才算完成。(可理解为A、B、C是一个流水线,对于每一个请求自身而言,它是依次被A、B、C串行处理的)
怎么计算请求的响应时间呢?很简单,就是A、B、C三个模块分别处理它的时间的总和。比如我们看req-1 这个请求,它的响应时间就是此图中间靠左竖着的虚线高度。
注:本文为了保持简单且更契合我们所遇到的问题/例子,没有探讨每个模块内部并行执行的场景 - 当然这种情况也并不困难 - 简单来讲我们仍然可以把这个模块当作一个黑盒先计算它的各个指标--再纳入它所在的架构整体去计算,就像俄罗斯套娃一样, 如果你有这方面的想法,欢迎评论区沟通交流
4.1 理论计算公式
先假定:
1. 请求在A、B、C三个模块的处理时间分别为:3ms、1ms、1ms。
2. 每个模块处理每个请求的时间是恒定不变的 (这是一个极理想状态,但不影响我们分析问题)。
1. 由于我不善定理证明,因此下文中的公式~~都没有证明~~大家不妨就认为我是在致敬黎曼的“显而易见”吧。
2. 暂不需要考虑batch、资源饱和度、排队延迟等问题。
我们可以得到如下指标的计算公式(请大胆阅读,所有公式只需加减乘除)
1. 请求最小响应时间
sum (A处理单请求的时间,
B处理单请求的时间,
C处理单请求的时间)此公式计算单个请求被整个系统处理完毕所需要的最小时间。
此例中即为:sum(3ms,1ms,1ms) = 5ms
2. 最大单模块处理时间
max (A处理单请求的时间,
B处理单请求的时间,
C处理单请求的时间)这个公式是计算处理时间最长的模块的处理时间。
此例中即为:max(3ms, 1ms, 1ms) = 3ms
3. 单并发最大QPS
1s/请求最小响应时间此公式用于计算当系统被持续施加并发为1的请求时(即当一个请求处理完毕再发起下一个请求)系统所能达到的最大QPS。
此例中即为:1s / 5ms = 200
4. 系统最大QPS
这是本文最最重要的公式!它表示:无论增加到多大的并发,系统所能提供的最大QPS是多少?在给出公式之前,大家不妨先想想自己的公式。

显而易见,计算公式为:
1s/最大单模块处理时间此例中即为:1s / 3ms ≈ 333.333。注意,此公式只适用于每个模块内都是单线程的场景。
下面的公式有着同样的能力:
min (A模块最大QPS,
B模块最大QPS,
C模块最大QPS)而且它可适用于多线程模型(即每个模块内有多个线程在并行执行,但注意,每个请求在模块内仍然是被一个线程所执行 - 而并非切分成多个子任务在多个线程并行执行)。
模块最大QPS又怎么计算呢?在多线程下,假设某模块内的线程数为M,模块最大QPS公式为:
M * (1s/模块处理时间)此例中所有模块的为M均为1,因此系统最大QPS为:
min( 1*(1s/3ms), 1*(1s/1ms), 1*(1s/1ms) ) ≈ 333.333
5. 最大QPS所需最小并发数
系统最大QPS / 单并发最大QPS此公式用于计算至少多少并发数可以达到系统最大QPS。(这个公式可以帮助我们设计系统,比如不能一味的增加请求并发数,因为这不但无法提高吞吐,还反而增加一些开销降低吞吐)
此例中即为:(1s/3ms) / (1s/5ms) ≈ 1.666
单线程下可等价使用下面的公式:
请求最小响应时间 / 最大单模块处理时间此例中即为:5ms / 3ms ≈ 1.666
4.2 推论
在我们所探讨的场景下,由"请求最小响应时间"公式和”系统最大QPS“公式可以得到以下三个非常重要的推论:
1. 在流程中添加模块,或增加模块的处理时间,必然会增加请求的响应时间。
2. 在流程中减少模块,优化模块处理时间,必然会减小请求的响应时间。
3. 整个系统所能达到的最大QPS吞吐,只由当前系统的最大单模块处理时间而决定!
5. 使用理论解决问题
分析
根据上面的推论,我们的吞吐问题一定是由于处理时间最大的模块所导致和决定的!
这也解释了为什么在快速验证的方式中没有解决问题,因为它们只是去掉了一些模块,或者减少了某些模块的处理时间,这些方式只能减少单个请求的响应时间!然而,处理时间最大的模块并没有被优化改进(没有被撞上大运)!再结合“系统最大QPS”计算公式,导致提高并发无法提高吞吐。
既然如此,那么现在的问题就变成了:找到处理时间最大的那个模块。
排查
因此我们决定在主从复制流程里添加日志来统计各个模块的处理时间,并不断的对比分析各个模块处理时间的日志,再逐步细化的打印日志,一步步逼近最根本的问题模块:
-
通过主节点的日志发现,从节点回传复制状态的延迟太大。(即主节点开始通过gRPC发送日志给从节点 到 收到从节点回复的复制状态里包含此日志时,这个时间间隔太大)
-
进一步发现从节点的流程里,“gprc消息处理模块”在收到日志写WAL后,会通过写Golang channel通知“日志Apply模块”新的CI发生变更,但通知的延迟花费太大(也是整个流程最耗时的),从而导致回传复制状态太晚,因此延缓了主节点发送下一批日志导致吞吐无法提升。通知的延迟为什么变大呢?因为随着并发数的增加,“日志Apply模块”的处理时间也开始增加,导致无法及时读取channel,从而变相增加了“gRPC消息处理模块”的处理时间。
从这现象也可以看出,在现实中,模块的处理时间是变化的,但我们仍然可以使用理想模型帮助我们排查和思考问题。
最终,我们通过扩大“gRPC消息处理模块”和“日志Apply模块”之间通信channel的缓冲容量,并将写入此channel的操作进行异步化来减小整个写入流程里的单模块最大处理时间,使得本文的吞吐问题得以解决。
6. 性能问题排查经验
在本章节,我分享个人总结的一些性能问题排查方面的经验,仅供大家参考。
-
理清业务的处理流程链路对性能排查至关重要,比如各个相关模块的依赖关系,并发/并行机制等,以及每个流程使用的资源类型:IO、CPU、网络、队列、channel、锁等;切记不要只关注CPU和IO !比如写入channel阻塞则等价于增加了模块的处理时间,虽然此时可能没有使用CPU,但实际上却影响了响应时间和吞吐。
-
USE:https://www.brendangregg.com/usemethod.html ,在排查性能问题之前先查看资源利用率、饱和度、错误报告。特别是避免在忽视了系统已经出现错误的情况下去分析性能。此外,应对不同的资源利用率问题有不同的处理方式(分为On-CPU、Off-CPU)
-
可以适当快速猜测和求证,以缩小问题范围(撞大运,哈哈)。若无法解决问题则跳转到下面的第4条经验。
-
对各个大的处理模块打印日志记录耗时可以帮助分析,然后再对有问题的大模块里进行更详细的日志打印。
-
一个性能问题(或者推广到Bug)可能是多个原因导致的,因此在排查过程中"修改"某个模块没有发生大的改进时,并不代表它就没有问题!!!
-
排查问题过程中若"发现"某个模块存在问题,并不代表此模块就是真正的问题,它可能是受到其他模块影响所导致的结果。排查性能问题(以及Bug)需要找到最小原因集(最根本性、最本质的问题)。
-
在程序里引入跟踪Opentracing 可以更直观的发现耗时的模块,这比打日志人肉分析方便一些(至少可以保护我们的视力...)。
7. 结语
总结起来讲,本文旨在从平时编程中所总结的经验中提炼出一些通用理论,期望使用这些理论帮助我们以更正确、更节省时间的方式去剖析问题、真正的解决问题,而非使用撞大运的方式去穷举试错来排查问题。
当然,由于作者技术水平有限,文中难免出现错误,还请读者批评指正。
最后,感谢大家的阅读,谢谢大家。
关于海东青
海东青时序数据库是一款高性能的支持跨平台、国产化、主从高可用、SQL的时序数据库,兼容InfluxDB、MySQL协议。
海东青官网:
https://fctsdb.rockontrol.com/
海东青下载:
https://github.com/falcontsdb/release
Docker使用:
docker pull falcontsdb/fctsdb:free_2.2.0
