TinyViT: 一种高效的蒸馏方法
目录
-
- 背景
- 方法大意
-
- 快速预训练蒸馏(Fast Pretraining Distillation, FPD)
-
- 如何实现快速
- 三个细节深入理解FPD
- 模型架构
- 训练trick
-
- 预训练参数配置(Imagenet21k-pretraining)
- finetuning 参数配置(Imagenet-1k)
- 消融实验
-
- **Q: 数据是否越多越好?**
- **Q: logitK的数量是否越多越好?**
- **Q: distill pretrain + finetune架构真的有效吗?**
- Q: 预训练的Tearcher 模型对student的影响大吗?
- 扩展思考
-
-
- What are the underlying factors limiting small models to fit large data?
- Why can distillation improve the performance of small models on large datasets?
-
- 参考文献
背景
最近,视觉Transformer(ViT)由于其出色的模型能力而在计算机视觉领域引起了极大的关注。然而,大多数流行的ViT模型存在大量参数的问题,这限制了它们在资源有限的设备上的应用。
方法大意
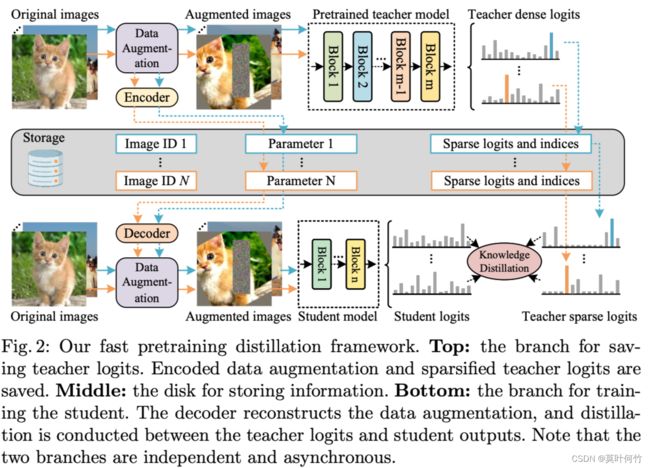
快速预训练蒸馏(Fast Pretraining Distillation, FPD)
如何实现快速
常规的pretrain with distillation 非常慢并且成本高。因为teacher网络的每次推理都占用了大量的计算资源(GPU),并且也需要推理时间。为了解决efficient和costly的问题,作者提出了一个fast pretraining distillation 框架。这个框架是如何做的呢?
他在teacher的预训练阶段存储两个信息:一者输入图片的增强 A A A,二者tercher对该图片的预测概率向量 y ^ = T ( A ) \hat{y}=T(A) y^=T(A),记做 ( A , T ( A ) ) (A, T(A)) (A,T(A))。由于数据增强中有随机数,这会导致即使采用同样的增强参数,所获得得增强图片也不一致。因此 ( A , T ( A ) ) (A, T(A)) (A,T(A))需要在不同的迭代位置都保存。
在训练阶段,学生网络会读取teacher网络对同一图片的增强参数,对图片进行增强,优化目标为:
L = C E ( y ^ , S ( A ( x ) ) ) \mathcal{L} = CE(\hat{y}, S(\mathcal{A}(x))) L=CE(y^,S(A(x)))
其中 A ( x ) \mathcal{A}(x) A(x)是增强后的图片, S ( A ( x ) ) S(\mathcal{A}(x)) S(A(x))是学生模型的预测概率分布, y ^ \hat{y} y^是teacher预测的概率分布。 C E CE CE为交叉熵损失。可见这个框架是label-free的,学生网络的训练不依赖标签。因此用该方法可利用大量互联网无标注的图片。
三个细节深入理解FPD
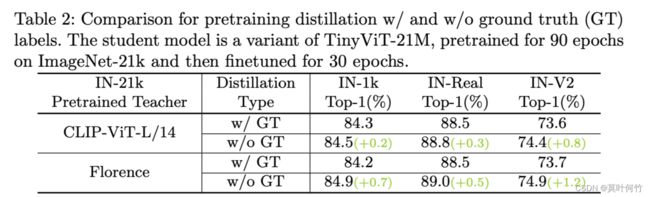
- 蒸馏阶段没有用GT的标签信息
作者发现,distillation with GT会导致性能下降。作者认为主要的原因可能是imagenet21k的有些标签间的类间差异很小,例如椅子和家具,马和动物,因此基于one-hot的GT标签不能很好的表征物体的类别信息。
- 对 y ^ \hat{y} y^进行了稀疏编码节约存储空间
对于imgnet21k来说总计有21841个标签,每个向量有21841维,非常大。作者的处理方式是,只存储向量中topk的元素的数值和位置,这大大降低了存储内存。在训练阶段,其它位置基于label smoothing的方式进行补充。
- 优化数据增强的编码方式
比如一次的数据增强中包含,crop的坐标,旋转的角度等,每一次迭代中对同一图片的增强可能都不一样。直接存储是memory-inefficient的。作者采用了一种编码函数来解决这个问题。比如数据增强参数为d, 为编码的参数。训练过程对该参数进行解码 d = ϵ ′ ( d 0 ) d = \epsilon'(d_0) d=ϵ′(d0)
模型架构
作者采用一种渐进式模型压缩方法(processive model contraction approach)实现从一个大模型中剪枝成小模型[1,2]。收缩因子有6个:embedding的维度、每个stage中block的个数、最后3个stage 的window size、MbConv block的通道扩展率、transformer中MLP的通道扩展率、多头attention,每个头的维度。
模型架构简要描述:
- 类似swin-transformer同样有4个stage,每个stage都会下采样
- patch embedding 采用了两个kernle为3补偿为2的卷积。
- stage1 采用MBConv[3],剩下三个stage都是transformer with window attention.
- 各个stage都用了残差连接。
- 激活函数都用GELU。
- 卷积的采用BN,线性层采用LN[4]

训练trick
预训练参数配置(Imagenet21k-pretraining)
| epoch | 90 |
|---|---|
| optimizer | AdamW(weight-decay 0,01) |
| lr | 0.002, cosine scheduler |
| Warm-up | 5-epoch |
| Batch-size | 4096 |
| Gradient-clip | Max-norm of 5 |
| Stochastic depth ratio | 0 for TinyViT-5/11M, 0,1 for TinyViT 21M |
| Data-aug | Random resize, crop, horizontal-flip, color jitter, random erasing, RandomAugment, Mixup, CutMix |
finetuning 参数配置(Imagenet-1k)
| epoch | 30 |
|---|---|
| optimizer | AdamW(weight-decay 10^-8) |
| lr | 0.0005, for each layer is decayed by the rate 0.8 form output to input |
| Warm-up | 5-epoch, cosine learning rate |
| bn | frozon |
| Batch-size | 1024 |
| Gradient-clip | Max-norm of 5 |
| Stochastic depth ratio | 0 for TinyViT-5/11M, 0,1 for TinyViT 21M |
| Data-aug | Random resize, crop, horizontal-flip, color jitter, random erasing, RandomAugment, Mixup, CutMix |
消融实验
Q: 数据是否越多越好?
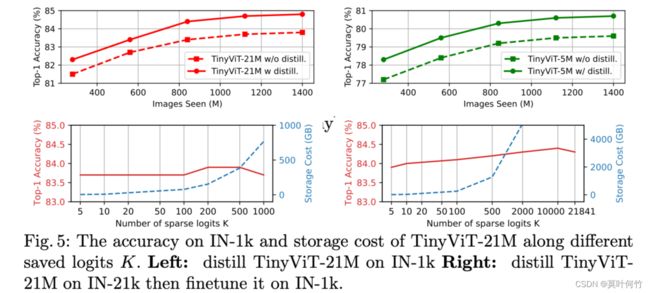
A: 模型的性能随着数据量的增加而呈现加速度不断降低的增大,同样的数据量,最终的性能受限于模型的大小。
Q: logitK的数量是否越多越好?
A: 保存的logitK的的数量不是越多越好,因为teacher模型的logit也可能有部分噪声,选取topk的策略不仅可以降低存储成本,也能起到一定的降噪作用。(作者在imagenet1k取得是10, imagenet21k取的是100)
Q: distill pretrain + finetune架构真的有效吗?
A: 从实验来看是有效的,不同的数据规模、不同的基础模型均能得到一定的提升。因此distill pretrain + fintuning可以作为一种较为通用的范式。
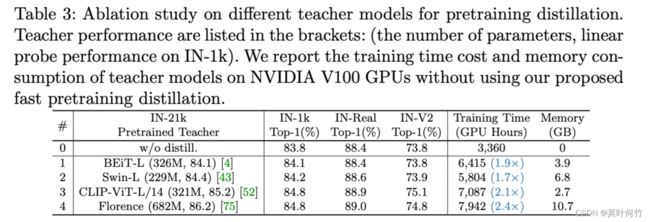
Q: 预训练的Tearcher 模型对student的影响大吗?
A: 更好的teacher模型能训练得到更强student模型,但好的teacher模型往往很大,会带来较大的时间消耗。
扩展思考
What are the underlying factors limiting small models to fit large data?
主要是由于数据集中的Hardsample导致的
标签错误、由于一张图片中有多个目标导致相似的图片有不同的标签。Imagenet21k大约有10%的困难样本。对于小模型来说,拟合这些困难样本较为吃力以至于训练准确率比起大模型低得多。
作者提出两个方法解决这个问题:1. 采用大规模数据集训练的预训练模型(Florence)在imagenet21k微调,找出哪些大模型在top5都识别错误的样本(这个操作移除了2M个图片)。2. 以大模型作为teacher,采用文中提出的蒸馏方法在imagenet-21k训练小模型。
上述两个方法的收益:1. 方法一能够提升0.7%的性能. 2. 方法2能提升1.7%的性能。
Why can distillation improve the performance of small models on large datasets?
作者认为核心原因是teacher模型能够将类别间的关系注入给学生模型。对于常规的分类任务,一张图片只对应一个类别,但忽视了类别与类别之间联系,而论文提出的distillation是根据概率向量进行优化,概率向量反映了该图片在各个类别上的分布。