MySQL like “%XX“ 和 like “XX%“ 的特殊情况
在 MySQL 使用 InnoDB 的引擎的情况下, 对某一建过索引的列进行 like 模糊查询时, 一般情况下
- like “%XX” 是不会走索引的
- like “XX%” 还是会走索引的
但是还是存在一些特殊的情况, MySQL 的底层会帮我们优化, 使上面的 2 条结论变成不一定, 下面做一个小小的总结。
1 表结构 SQL
CREATE TABLE `test_table`(
`id` int unsigned auto_increment comment '主键',
`name` varchar(10) not null comment '姓名',
`age` tinyint not null comment '年龄',
primary key(`id`),
unique `name_index`(`name`)
) ENGINE= INNODB DEFAULT CHARSET=utf8;
2 like “%XX” 走索引
执行 SQL
# 第一句
explain SELECT 'id', `name` from `test_table` WHERE `name` like '%123';
# 第二句
explain SELECT `age`, `name` from `test_table` WHERE `name` like '%123';
# 第三句
explain SELECT * from `test_table` WHERE `name` like '%123';
第一句的执行计划为:
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | test_table | index | name_index | 32 | 1 | 100 | Using where; Using index |
从 type = index 和 key = name_index 可以知道走了索引。
为什么呢? 一般情况下的确是不会走索引的, 但是这里刚好满足了一个情况:“覆盖索引”。在后面的 Extra 说明了这条 SQL 走了覆盖索引。
在理解这个问题前, 只要知道几个概念就能解决了。
2.1 主键索引和二级索引
在基于 InnoDB 为引擎的 MySQL 的索引是基于 B+Tree 实现的, 同时在基于 B+Tree 的基础上有 2 种实现方式:
- 主键索引: 简单理解的话, 就是通过
primary key创建的索引, 在test_table里面就是我们的 id- 二级索引: 可以简单的理解为除了主键索引以外的索引类型, 比如:普通索引, 复合索引, 唯一索引等, 在
test_table里面就是唯一索引 name
其中主键索引的实现是这样的是(注这是简略版):
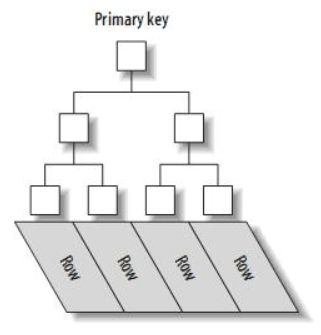
在树的非叶子节点, 存放的就是我们的主键的值, 而叶子节点存放的是主键和主键对应的数据行。
【注】:想要真正了解 B+Tree 所有的话, 可以看一下这里
二级索引的实现是这样的(同样的, 这也是简略版):
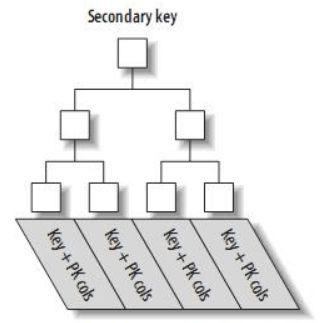
在树的非叶子节点, 存放的是索引的值, 而叶子节点存放的是索引的值 + 对应的行的主键 Id。(所以平时在使用非主键索引查询数据时, 都是在二级索引的 B+Tree 里面找到了对应的行的主键 Id, 在通过这个 Id 到主键索引的 B+Tree 查找)
2.2 覆盖索引
定义: 指一个查询语句的执行只需要从索引中就可以得到查询记录, 而不用从数据表中读取。也可以称之为实现了索引覆盖。
举个例子:一张表
| id | first_name | last_name | birthday | sex |
|---|---|---|---|---|
| 1 | can | lee | 2020-03-23 | 1 |
| 2 | cn | l | 2020-02-23 | 2 |
在这种表中, 我们建立了一个复合索引 index(‘first_name’, ‘last_name’, ‘birthday’);
然后查询的时候 select first_name, last_name from 表名 where first_name like "c%"; 这时观察我们的 SQL 发现了需要的几列刚好是我们复合索引里面有的。
这时 MySQL 就会在我们的 B+Tree 的非叶子节点找到了需要的数据了, 直接返回, 而不用到叶子节点去取数据, 这就是 “覆盖索引”。
从中我们知道: 覆盖索引不是一种索引, 更类似于一种行为。
需要理解的 2 个概念都讲完了, 那么为什么 like “%XX” 走索引的情况, 应该可以分析出来了。
- 查询的是列有 id, name, 查询的条件为 name like “%123”。
- 在 name 上面建了唯一索引, 也就是二级索引
- 在这里二级索引的叶子节点存放的是 name + id
- 需要的列数据在二级索引树的叶子节点就有了, 那么 MySQL 直接去遍历索引也能找到数据了, 而不用直接全表扫描。
所以这里走了索引。
第二句的执行计划
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | test_table | ALL | 1 | 100 | Using where |
就是我们平时常说的 like “%XX” 不走索引的情况了。
第三句的分析, 类似的情况
3 like “XXX%” 不走索引
依旧是上面的 test_table 表, 我们先通过一个存储过程, 给这张表填充一些数据
新建一个存储过程: 给表里面填充 140 条数据, 每条的 name 的前缀都是 ‘name’ + 数字
delimiter //
CREATE PROCEDURE insertdata()
begin
declare tempName varchar(20);
DECLARE sourceStr VARCHAR(100);
declare count int;
set count = 0;
WHILE count <140 DO
set tempName=CONCAT('name', count);
set count = count + 1;
insert into test_table(name, age) VALUES (tempName, 1);
END WHILE;
end;
//
执行存储过程, 填充数据
call insertdata();
准备完成, 开始
explain SELECT * from test_table where name like 'name%';
他的执行计划是这样的
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | test_table | ALL | name_index | 140 | 100 | Using where; |
可以看到 type 的类型是 all, 走的是全表扫描。
之所以为这样是存的值的相似度高 + like 的条件刚好在他们相似的地方。
我们存的 name 的格式都是 name + 数字, 同时查询条件为 like ‘name%’, MySQL 判断走全表扫描比索引快。