【shell】shell脚本函数和数组的原理及使用注意
目录
一、函数
1.1函数的优点:
1.2如何定义函数(shell)
1.3 演示函数的作用以及增删改查
关于函数的使用
关于declare查询的用法
关于函数的增加与调用
关于函数的返回值return
关于echo作为返回
关于函数的参数传递
关于函数的环境变量和内置变量:local
关于函数的位置与调用
递归函数
二、数组
2.1数组的分类
2.2定义数组
2.3调用数组以及给数组赋值
##获取数组长度
##获取数组的所有信息
##读取下标的标号有哪些
##数组切片
##给某个数组原有的值重新赋值
##取出数组中的最大值和最小值
##永久修改数组,批量修改数组内容
##删除数组
三、总结:
一、函数
1.1函数的优点:
函数可以理解为脚本的别名,使用函数可以避免代码错误,增强可读性,简化脚本;函数可以将大的工程来分割为若干小的功能模块,代码的可读性更强;
我个人目前认为,没有感受到shell脚本使用函数的简化,但是能明显感受增强了shell脚本的模块化,因为函数与函数之间没有关联,调用的时候更加方便,这样对于写脚本来说,可以让脚本的功能更加强大。
1.2如何定义函数(shell)
##第一种:简单常用
函数名(){
脚本(命令集合)
}
##第二种:
function 函数名{
脚本内容(命令集合)
}
##第三种
function 函数名(){
脚本(命令集合)
}
1.3 演示函数的作用以及增删改查
关于函数的使用
#!/bin/bash
num(){ ##num是定义的函数名称
a=66
echo ${a}
}
num ##这里的num是调用上面的num函数脚本
关于declare查询的用法
【查看函数列表】
declare -F
#查看当前已定义的函数名,仅仅显示名称
declare -f
#查看当前已定义的函数定义,包含脚本代码
declare -f 函数名称
#查看该函数是否存在(这里必须是已经用source或者.已经声明过的函数内容,要不然系统无法识别)
declare -F 函数名称
#查看当前已定义的函数,以及详细代码
unset 函数名
#表明从系统中删除定义的函数,但是如果函数脚本使用source再次声明,还是会存在的

关于函数的增加与调用


关于函数的返回值return
return表示退出函数并返回一个退出值,脚本中可以用$?变量表示该值,使用原则:
1. 函数一结束就去返回值,应为$?变量只返回执行的最后一条命令的退出返回码
2. 退出码必须是0-255,超出的值将为除以256取余
第一个知识点:要知道函数中的return跟调用时$?一起搭配使用,这样return才有意义

第二个知识点:return返回值是不能大于255,要不然就是除以256取余
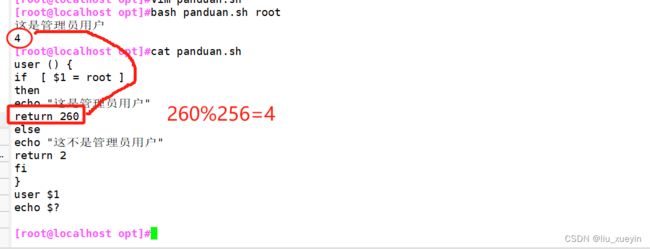 第三个知识点:return在使用的时候注意,但在执行完脚本后用于给与返回值,否则会直接退出
第三个知识点:return在使用的时候注意,但在执行完脚本后用于给与返回值,否则会直接退出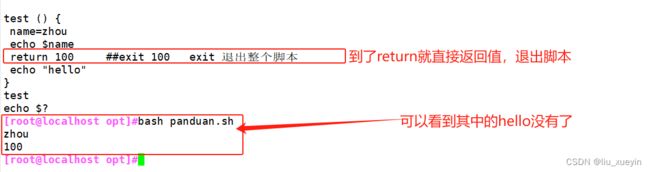
关于echo作为返回
个人理解是:如果说return不能很好使用的时候,可以使用echo来输出对于命令执行的判断,这样更方便,没有例子更好的去感受
关于函数的参数传递
脚本中写的$1、$2等位置变量是调用函数的时候跟上的值
调用函数的时候的位置变量是使用bash调用脚本的时候的位置变量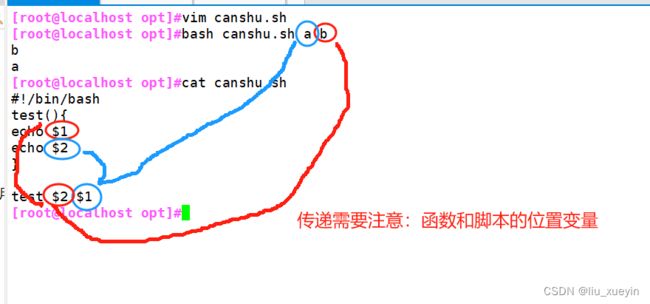
关于函数的环境变量和内置变量:local
local值

关于函数的位置与调用
一定要先有函数的定义,然后再调用函数,否则不生效

递归函数
递归函数就是调用自身的函数,注意:必须要有结束函数的语句,要不然就会死循环
实验查看下一篇博客
常见的fork炸弹都是递归函数,已知不停调用自己,没有跳出循环的条件
:(){:|:&};:
个人的理解:这里的:可以是一个字符或其他字符串,相当于定义了一个函数叫做:,执行:并且将内容传给:自己,再并行操作,分号表示接下来执行这个动作的分隔符,最后的:为调用执行这个函数
bomb(){ bomb|bomb & };bomb ##这就是将冒号换成了bomb
总结:关于函数的使用,可以准备一个函数的总的脚本,然后准备一个工具箱,整体调用,但是一定要把函数脚本放在工具箱脚本的最最最开头!(实操后补博客)
二、数组
2.1数组的分类
第一种:普通数组
下标索引是从0开始的数字,下标数字是可以不连续的
普通数组是系统会自动进行声明的,

第二种:关联数组
一定一定要使用declare -A 数据名称进行声明

declare -a 可以查看所有的普通数组;
declare -A 可以查看所有的关联数组 ;
拓展:也可以以文件名来定义数组
[root@host1 /data]#ls
a.sh chmod.sh compare.sh f.sh name.txt num.sh test2.sh yum.sh
[root@host1 /data]#file=(*.sh)
[root@host1 /data]#echo ${file[*]}
a.sh chmod.sh compare.sh f.sh num.sh test2.sh yum.sh

[root@host1 /data]#echo ${num[*]}
[root@host1 /data]#num=`echo {1..10}`
[root@host1 /data]#echo ${num[*]}
1 2 3 4 5 6 7 8 9 10
[root@host1 /data]#echo ${xx[*]}
[root@host1 /data]#i=10
[root@host1 /data]#xx=`eval echo {1..$i}`
[root@host1 /data]#echo ${xx[*]}
1 2 3 4 5 6 7 8 9 10
2.2定义数组
方法有5种,常用的是这两种
1、总体赋值
2、单个赋值
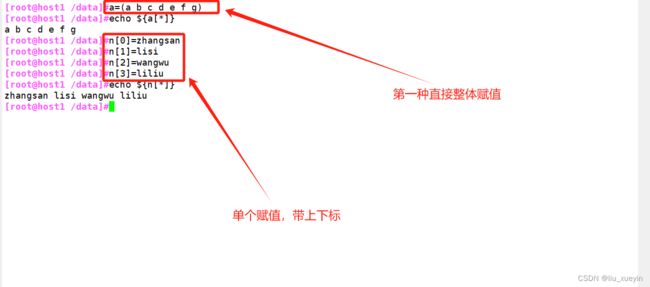
[root@host1 /data]#a=(a b c d e f g)
[root@host1 /data]#echo ${a[*]}
a b c d e f g
[root@host1 /data]#n[0]=zhangsan
[root@host1 /data]#n[1]=lisi
[root@host1 /data]#n[2]=wangwu
[root@host1 /data]#n[3]=liliu
[root@host1 /data]#echo ${n[*]}
zhangsan lisi wangwu liliu
2.3调用数组以及给数组赋值
##获取数组长度
##获取数组长度
[root@host1 /data]#echo ${#a[*]} ##echo ${#数组名[*]}
7
[root@host1 /data]#echo ${#a[@]} ##echo ${#数组名[@]}
7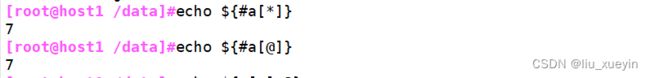
##获取数组的所有信息
##获取数组的所有信息
[root@host1 /data]#echo ${a[*]} ##echo ${数组名[*]}
a b c d e f g
[root@host1 /data]#echo ${a[@]} ##echo ${数组名[@]}
a b c d e f g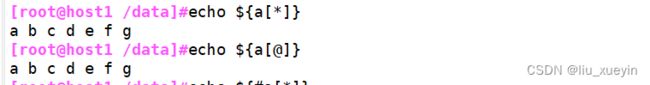
##读取下标的标号有哪些
##读取下标的标号有哪些
[root@host1 /data]#echo ${!a[*]} ##echo ${!数组名[*]}
0 1 2 3 4 5 6![]()
##数组切片
##数组切片
[root@host1 /data]#echo ${a[@]:2} ##echo ${数组名[@]:n:m}表示跳过前n个,只看m个,如果没有m则是后面所有
c d e f g
[root@host1 /data]#echo ${a[@]:2:2} ##跳过前2个,看后面2个
c d
[root@host1 /data]#echo ${a[@]:2:3} ##跳过前2个,看后面3个
c d e
[root@host1 /data]#echo ${a[@]} ##对比查看学习
a b c d e f g
##给某个数组原有的值重新赋值
##给某个数组原有的值重新赋值
数组名[标号]=新的值 
##取出数组中的最大值和最小值
#!/bin/bash
for i in {0..6} ##这里是表明有7个随机数,也可以用read交互的办法来写
do
num[$i]=$[RANDOM] ##表示随机给数组num赋值
[[ $i -eq 0 ]] && min=${num[0]}&&max=${num[0]} ##当有第一个数组时,最大值和最小都是它
[[ ${num[$i]} -gt ${max} ]]&& max=${num[$i]} ##表示随机产生的数字与最大值比较,如果大成立,则执行将其值赋给max
[[ ${num[$i]} -lt ${min} ]]&& min=${num[$i]} ##表示随机产生的数字与最小值比较,如果小成立,则执行将其值赋给min
done
echo "所有的随机数为:${num[@]}"
echo "最大值为:${max}"
echo "最小值为:${min}"
##永久修改数组,批量修改数组内容
首先学习临时修改:

永久修改的思路
其实没有永久修改的办法,只能思考,定义一个新的数组,过度一下,将改过的赋给新的数组,然后再把旧的数组删除了,把新的数组再传给 旧的数组名

##删除数组
##删除数组
unset 数组名称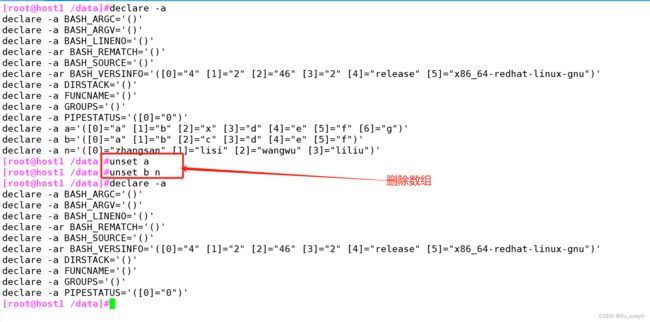
三、总结:
函数总结:
1、先定义函数
2、调用函数(注意:若定义完成不调用则函数无效),在命令行调用需要使用source和.来执行函数脚本申明
3、查看系统的所有函数名称:declare -F (如果函数脚本没有用source,那么在系统中查不到)
4、查看函数定义详细内容:declare -f 函数名称
5、删除函数格式:unset 函数名称
6、函数中的变量注意,根据使用可以加上local为局部变量,只在执行函数时生效
数组总结:
1、关联数组需要先声明,即使在脚本中也需要使用(declare -A 数组名)来进行声明,否则无效
2、查询系统中的所有普通数组为declare -a ;查询所有关联数组为:declare -A
3、查询数组内容:echo ${数组名[*]}、${数组名[@]}
4、删除数组格式:unset 数组名;删除单个数组内容:unset 数组名[下标]