知识补给站20230419-20230421
文章目录
-
-
-
- 1. FTP定价
- 2. BP
- 3. XGB中的SHAP
- 4. 其他格式转数据框
- 5. 树模型当中的增益是怎么计算的?
- 6. plt作图小结?
- 7. 解决样本不平衡问题?
- 8.缺失值填充
- 9. 周期损失的计算方法?
- 10. 贷款五级分类
- 11. B端业务和C端业务(参考人人都是产品经理的文章)
- 12. 欺诈检测-多分类
- 13. 过拟合
- 14. 广义线性模型
- 15. 经验风险+结构风险
- 16. 极大似然估计-求最优参数
- 17. 逻辑回归
- 18. 混淆矩阵
- 19. 评分卡模型的业务评价需要满足哪些性质
- 20. 模型部署
- 21. 模型监控(时效性、准确性)
- 22. 一口气说清楚XGB
- 23. 用户画像
- 24 又忘记lift了
-
-
1. FTP定价
- 内部资金转移定价(Funds Transfer Pricing)
- 内部资金转移定价(FTP)是指,商业银行内部资金中心与业务经营单位按照一定规则
全额有偿转移资金,达到核算业务资金成本或收益等目的的一种内部经营管理模式。 - 业务经营单位每笔负债业务所筹集的资金,均以该业务的FTP价格全额转移给资金中心;每笔资产业务所需要的资金,均以该业务的FTP价格全额向资金管理部门购买。
- 对于资产业务,FTP价格代表其资金成本,需要支付FTP利息;对于负债业务,FTP代表其资金收益,可以从中获取FTP利息收入。
2. BP
- BP在银行业中指的是
基点,英文名称为Basis Point,常用于价差或者汇率变动幅度计量,通常为汇率最小的变动单位。1个基点的数值通常是0.0001,但USD/JPY和EUR/JPY为0.01。利率是很敏感的,所以在中国人民银行调整利率的时候,不使用百分点调控,而是使用小于百分点的基点来调控。基准利率有一点轻微的变动,就能给市场造成很大的影响。 BP= business partner,指业务伙伴;HR=human resources,指人力资源。HRBP即“人力资源合作伙伴”: 在企业战略的发展与实施,人力资源政策事宜等方面,为企业并购提供人力资源支持。该岗位的设置相当于在业务部门和人力资源部门架起桥梁,能够让招聘更加贴近用人部门的需求
3. XGB中的SHAP
- XGB特征重要性计算方式
- 分裂次数
xgb_model.get_score(importance_type='weight')
- gain增益
xgb_model.get_score(importance_type='gain')
- 基于排列的特征重要性
使用scikit-learn接口API,这种排列方法将随机打乱每个特征并计算模型性能的变化,对性能影响最大的特性是最重要的特性,而且可以很容易地计算出来并可视化
from sklearn.inspection import permutataion_importance
perm_importance = permutation_importance(xgb, X_test, y_test)
- SHAP值计算重要性
在上述的几种计算特征重要性的方法中,只能得到特征对分类结果的影响大小,但是没有影响的方向,比如是正的作用还是负作用。而SHAP值是可以解决这个问题的
Shapley 来自于合作博弈论的方法,主要用来解决在多人合作的模式下,如何公平得分配收益的问题。该方法为通过计算在合作中个体的贡献来确定该个体的重要程度。
import shap
explainer = shap.TreeExplainer(xgb_model)
shap_values = explainer.shap_values(X_test)
shap.summary_plot(shap_values, X_test, plot_type="bar")
(1) shap_values得出来是一个数组,每个样本的每个特征对应的shap值,若进行聚合,只需要求平均即可,即某个特征的shap值=mean(所有样本该特征的值)
(2) shap.summry_plot(shap_values, features(df), plot_type), 作图的格式可以是默认的dot,也可以是bar条形图。但是两种图形其实对于正反方向都不是很直观,还需要继续优化

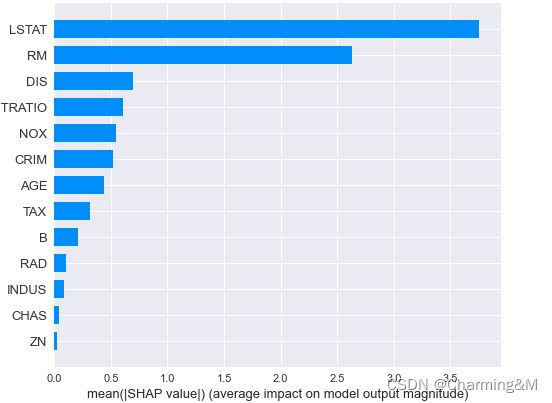
(3) 部分依赖图dependence_plot()
可以根据shap值和特征值之间的关系查看特征和因变量的关系,是否单调
shap.dependence_plot(feature,shap_values, data[fea_6],interaction=None)

(4) 单个样本可解释性shap.force_plot
explainer=shap.TreeExplainer(model)
shap_values=explainer.shap_values(X)
shap.force_plot(
explainer.expected_values,
shap_values[0:,],
x.iloc[0,:],
matplotlib=True
)
当我们需要对单个样本的评分结果进行客观解释的时候,可以直接使用其shap值作为特征对最终结果的影响,单样本shap图表名各个特征都有各自的贡献,将模型的预测结果从基本值推动到最终的取值,蓝色的表示特征的贡献是负数,红色的表示该特征的贡献是正数,若样本为低分客户,那么可能是由于蓝色条代表的特征起了比较重要的影响造成的。
-
shap计算特征重要性的原理是什么?
-
shap怎么来阐述变量的可解释性?
主要是看整体特征的可视化和部分依赖图,看特征和shap值的变化趋势,是否单调,单调递增或是递减,是否符合业务逻辑
4. 其他格式转数据框
- 数组array转df
pd.DataFrame(explainer.shap_values(X_test))
- 字典转df
使用函数pd.DataFrame.from_dict(dict, orient, columns)
orient:{‘columns’, ‘index’, 'tight}, 该参数表示字典的键用作行名或者是列名,注意若为index这里直接得到的是索引,因此在写列名的时候直接写值的columns
gain_dict=xgb_model.get_score(importance_type='gain')
#一个以变量名为键,gain值为值的字典
#转为数据框
gain_df=pd.DataFrame.from_dict(gain_dict, orient='index', columns='gain_importance')
5. 树模型当中的增益是怎么计算的?
6. plt作图小结?
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.plot(x, results['validation_0']['error'], label='Train')
ax.plot(x, results['validation_1']['error'], label='Test')
ax.legend() # 显示图例
plt.ylabel('Log error')
plt.title('XGBoost Log error')
plt.show()
# 保存
fig.savefig(path)
7. 解决样本不平衡问题?
银行业里面本来坏客户就是占少数,肯定会存在样本不平衡的问题
(1) 过采样
对少数类的样本进行分析,人工合成更多的少数类新样本,比较有代表性的是smote过采样算法,其核心是在现有少数类样本之间进行插值
(2) 欠采样
就是减少多数类的样本
- 随机欠采样
从多数类的样本中随机选择一些样本,缺点是被剔除的样本可能包含着一些重要信息,致使学习出来的模型效果不好。
8.缺失值填充
逻辑回归是用WOE编码,XGB是自己有处理缺失值的机制,而决策树、随机森林建模过程中不能出现缺失值,因此需要去进行填充
9. 周期损失的计算方法?
周期预期损失 = 违约概率 ∗ 违约敞口 ∗ ( 1 − 违约回收率) 周期预期损失=违约概率*违约敞口*(1-违约回收率) 周期预期损失=违约概率∗违约敞口∗(1−违约回收率)
- 违约概率:违约的可能性
- 违约敞口:未还的本金+利息
- 违约回收率: 实际回收金额 / 第n期违约敞口
问题:周期损失?直接计算没有回收的钱不就好了吗?为啥要去计算违约概率?这是一个预测值?所以这里应该是预期损失
10. 贷款五级分类
贷款五级分类制度是根据内在风险程度将商业贷款划分为正常、关注、次级、可疑、损失五类
11. B端业务和C端业务(参考人人都是产品经理的文章)
- KOL: key opinion leader
关键意见领袖,通常被定义为:拥有更多、更准确的产品信息,且为相关群体所接受或信任,并对该群体的购买行为有较大影响力的人
(1) 不同点
交易主体不同
B端交易主体是组织,而C端交易主体是个人交易周期不同
交易周期是指买卖双方从首次接触到交易谈判,再到完成打款的整个时间段
B端交易周期比较长,而C端比较短售后服务轻重不同
B端由于量小,售后服务较好,主打效益,而C端由于个人量比较大,售后服务较少,主打体验
12. 欺诈检测-多分类
在做欺诈检测时,预测一个用户是否进行欺诈,这看似是一个二分类任务,但其实用户的欺诈手段各不相同,每一个欺诈方法都是一个单独的类别,因此它本质上是一个多分类任务
13. 过拟合
-
过拟合
模型学习的太过详细,把一些个例的特点作为共性,使得模型的泛化能力较低 -
泛化误差
训练集上的表现和测试集上的表现的差值 -
泛化能力
模型对未知数据的预测能力,是学习方法本质上重要的性质。在实际情况中我们通常通过测试误差来评价模型的泛化能力
14. 广义线性模型
- 是线性模型的拓展,通过
联结函数建立响应变量的数学期望值,与线性模型相结合来预测变量之间的关系。 - 其特点是不强行改变数据的自然度量,数据可以具有
非线性和非恒定方差结构。 - 广义线性模型是线性模型在研究
响应值的非正态分布以及非线性模型简洁直接的线性转化时的一种发展
# 线性回归
from sklearn.linear_model import LinearRegression, Lasso, Ridge
model=LinearRegression()
model.fit(X,y)
15. 经验风险+结构风险
- 线性回归的损失函数为
均方误差,通过迭代求解或者求极值的方式使损失函数找到最小值,从而解出最优参数。均方误差期望每一个实际的点到预测直线的欧氏距离之和最短,基于均方误差最小化来求解参数又叫做最小二乘法 - 经验风险:对
模型错误程度的量化指标,是对训练集上模型是否能有一个好的表现的度量 - 结构风险:我们希望在测试集上模型也有较好的
鲁棒性/泛化能力,因此我们定义另一种结构性风险,以应对由于尽可能降低经验风险而导致模型结构太复杂,进而导致的过拟合问题。通常是在经验损失函数的基础上添加一个正则项,用来惩罚模型的复杂度,以使模型的结构不那么复杂,从而避免模型的过拟合问题。
16. 极大似然估计-求最优参数
- 极大似然估计提供了一种
给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。 - 通过若干次试验,观察其结果,利用试验结果得到
某个参数值能够使样本出现的概率为最大,则称为极大似然估计。 - 最大似然估计的目的就是:利用已知的样本结果,
反推最有可能(最大概率)导致这样结果的参数值。
17. 逻辑回归
- 线性回归解释能力较强,模型的输出也有很好地排序能力,但是无法解决二分类问题,因此,为了使用线性回归良好的解释性,需要寻找一个
联结函数来将线性回归的输出规约在【0,1】之间,从而将模型的结果视为用户逾期概率的某种表示
from sklearn.linear_model import LogisticRegression
lr_model=LogisticRegression()
lr_model.fit(X,y)
- 逻辑回归之前需要对变量进行
标准化处理,统一量纲 - 采用离差标准化和标准差标准化对数据进行处理时,会受到
异常值的影响,导致分布不均匀,此时可以采用分位数标准化,根据中位数或者四分位数去中心化数据
# 离差标准化
from sklearn.preprocessing import MinMaxScaler
mm_scaler=MinMaxScaler()
x_new=mm_scaler.fit_transform(x)
# 标准差标准化
from sklearn.preprocessing import StanderdScaler
# 分位数标准化
from sklearn.preprocessing import robust_scale
x_new=robust_scale(x)
18. 混淆矩阵
- 真正类-TP:正类预测为正类
- 假负类-FN:
正类预测为负类 - 假正类-FP:负类预测为正类
- 真负类-TN:负类预测为负类
- 精确率/查准率
T P T P + F P \frac{TP}{TP+FP} TP+FPTP
所有预测为正样本中,真正为正样本的概率 - 召回率/查全率
T P T P + F N \frac{TP}{TP+FN} TP+FNTP
所有真实样本中,被预测为真正正样本的概率
关系:查准率和查全率相互矛盾,此消彼长,需要根据不同的业务场景,选择不同的模型评价指标
- 对于
信用评估场景,侧重的是精确率,我们希望推荐的结果都是用户感兴趣的结果,即用户感兴趣的信息比例要更高?(这跟信用评估有啥关系?不应该是我们希望通过模型识别出来的坏客户都是真正的坏客户) - 对于
反欺诈场景,侧重的是召回率,即我们希望不漏检任何欺诈用户,如果发生一笔欺诈订单,就可能造成平台的巨大损失
# 查准率
def precision(y_true,y_pred):
#统计同时为1的样本个数
true_positive=sum(y and y_p for y,y_p in zip(y_true,y_pred))
逻辑表达式,0 假 1 真 真真为真,真假为假
predicted_positive=sum(y_pred)
return true_positive/predicted_positive
# 查全率
def recall(y_true,y_pred):
true_positive=sum(y and y_p for y,y_p in zip(y_true,y_pred))
real_positive=sum(y_true)
return true_positive/real_positive
-
TPR真正利率
T P T P + F N \frac{TP}{TP+FN} TP+FNTP -
FPR假正利率
F P T N + F P = 1 − T N T N + F P \frac{FP}{TN+FP}=1-\frac{TN}{TN+FP} TN+FPFP=1−TN+FPTN -
ROC计算,先对模型的预测结果进行
排序,将排序后的预测结果的从大到小每个值作为阈值,然后逐个将前面的记录作为正样本,后面的记录作为负样本进行预测,计算FPR和TPR,然后在图中体现出来
def true_negative_rate(y_true,y_pred):
true_negative=sum(1-(yi or yi_hat) for yi,yi_hat in zip(y_true,y_pred))
#计算全为0的,表示真负样本数
actual_negative=len(y_true)-sum(y_true)
return true_negative/actual_negative
def roc(y,y_hat_prob):
thresholds=sorted(set(y_hat_prob),reverse=True)
ret=[[0,0]] #将FPR和TPR存储在数组中
for threshold in thresholds:
y_hat=[int(yi_hat_prob>=threshold) for yi_hat_prob in y_hat_prob]
ret.append([recall(y,y_hat),1-true_negative_rate(y,y_hat)])
return ret
# 求AUC
from sklearn.metrics import roc_auc_score
auc=roc_auc_score(y_true,y_pred)
19. 评分卡模型的业务评价需要满足哪些性质
稳定性
模型PSI
变量PSI
不同数据集上的差异,是否稳定
不同月份的差异,是否稳定有效性- 负样本抓取能力
指的是在分数比较低的几个客群上,可以捕捉到当前样本集中负样本的百分比,其实可以理解为头部lift,头部lift越高,模型越好 排序能力
用于定额定价的需要有良好的排序性
20. 模型部署
-
模型保存(评分卡、其他模型)
评分卡主要采用if_else的结构来进行打分,上传制作的评分卡就行
XGB等模型可以保存为pickle文件或者是pmml文件 -
其中
pypmml库是一个Python PMML评分库,它实际上是PMML4S的Python API
# 保存为PKL文件
import picke
with open(path,'wb') as f:
pickle.dump(model,f,protocol=2)
f.close()
# 加载pickle模型
from sklearn.external import joblib
model=joblib.load(path)
# PMML 预测模型标记语言
from sklearn2pmml import sklearn2pmml,PMMLPipeline
from sklearn_pandas import DataFrameMapper
mapper=DataFrameMapper([([i],None) for i in feat_list])
pipeline=PmmlPipeline([('mapper',mapper),('classifier',model)])
sklearn2pmml(pipeline,pmml=path)
#加载模型
from pypmml import Model
model=Model.fromFile(path)
- 旧模型预测新数据,先从部署环境中将
模型下载下来,然后加载到Jupyter中,再进行预测。预测时会比较慢,因为是一条一条进行预测的,并且输出的是概率
from pypmml import Model
model=Model.fromFile(path)
# 模型的输入
name=model.inputNames
#预测
model_p=model.predict(name) #什么格式?
#为坏样本的概率
bcard_p=np.array(model_p)[:,1]
# 转换标签
def change_p(p):
if p>=0.5:
return 1
return 0
model_y = list(map(change_p, np.array(model_p)[:, 1]))
# 评估整体AUC和KS
from sklearn.metrics import roc_auc_score
model_auc=roc_auc_score(data[y],model_y)
model_ks=evaluate.ks_score(df[y],pd.series(model_y))
# 打分
points0=600
odds0=1/50
pdo=-20
B=pdo/np.log(2)
A=points0-B*np.log(odds0)
bcard_score=np.round(A+B*np.log(bcard_p/(1-bcard_p)))
#查看分数段统计和排序性
bcard_a=utils.split_performance_table(df[y],bcard_score)
#得出所有样本的计算数据:分数、概率、标签
sdf=pd.DataFrame({
'y':df['mob3_target'],
'product':df['product_no'],
'month':df['month'],
'prob':bcard_p,
'mmodel_y':list(model_y),
'score':bcard_score
})
# 按月统计data=bcard_df
def anyue_ks(data,target,product_no):
total_ks=data.groupby('month').agg({target:['count','sum']}).reset_index()
total_ks.columns=['month','size','badCnt']
total_ks['goodcnt']=total_ks['size']-total_ks['badcnt']
total_ks['badrate']=total_ks['badcnt']/total_ks['size']
month_ks=[]
for i in sorted(data['month'].unique()):
t1=data[data['month']==i]
month_ks.append(ks_score(t1[target],t1['score']))
total_ks['ks']=pd.series(month_ks)
return total_ks
#分产品统计
model_p输出的是一个二维数据框,第一列表示为0的概率,第二列表示为1的概率,可以直接取第二列或者是先转为数组,再取[:,1],不过一维数组便于计算score,因为会用到np.log等数组类函数
21. 模型监控(时效性、准确性)
(1) 前端监控
- PSI:模型按月度统计的psi值+变量按月度统计的PSI的值
- 分数分布:模型失效的一个前兆就是
模型输出的分数分布下移 - 线上线下分数对比
(2) 后端监控 模型显著性:由于低分人群会因为被拒绝而没有真正的贷后表现,因此仅以有借贷的样本去计算auc和KS来评价模型的实际效果是不合理的,只能说去监控这个KS值是否稳定,是否衰退的很厉害- 低分原因
用在评分卡当中是比较合适的,由于评分卡具有加分和减分,因此很容易通过对低分客户的特征进行分析,查看到底是哪些变量进行了减分。当拒绝率过高时,我们可以较为容易的定位到是哪一些特征的客群质量下降
22. 一口气说清楚XGB
-
XGBoost是一种基于
前向分布算法实现的加法模型。通过损失函数的二阶泰勒展开近似模型的负梯度,并将其作为前一个模型的残差进行学习,从而实现多个模型的串行迭代,使偏差逐渐修正直至损失满足收敛条件。 -
可以用来作辅助校验模型,用来判断逻辑回归模型的
人工特征工程是否有继续交叉的必要(什么意思?) -
自定义损失函数 (customized objective function)
XGBoost支持自定义评价函数和损失函数,只要保证损失函数二阶可导,通过评价函数的最大化,即可对模型参数进行求解,在实际使用中,可以考虑根据业务目的对这二者进行调整
比如:现在有一个提额模型,用处是给予分数最高的20%客户更高的额度,也就是期望分数最高的20%的客群正样本捕获率最大化,其可以在保证上述前提的情况下,保证模型对正负样本有一定的区分能力。
# 自定义损失函数
def loglikehood(preds,dtrain):
labels=dtrain.get_label() # 标签列
preds=1/(1+np.exp(-preds))
grad=preds-labels
hess=preds*(1-preds)
return grad,hess
# 自定义评价函数:前20%正样本占比最大化
def binary_error(preds,train_data):
labels=train_data['y']
dct=pd.DataFrame({
'pred':preds,
'percent':preds,
'labels':labels
})
#取百分位点对应的阈值
key=dct['percent'].quantile(0.2)
# 按照阈值处理成二分类任务
23. 用户画像
-
用户画像最初是在电商领域得到应用的,在大数据时代背景下,用户信息充斥在网络中,将用户的
每个具体信息抽象成标签,利用这些标签将用户形象具体化,从而为用户提供有针对性的服务。 -
用户画像是一个
描述用户的工具。刻画出用户个体或者用户群体全方位的特征,为运营分析人员提供用户的偏好、行为等信息进而优化运营策略,为产品提供准确的用户角色信息以便进行针对性的产品设计。
用户画像是根据用户社会属性、生活习惯和消费行为等信息抽象出的标签化用户模型。
- 用户画像分为persona和profile。
Persona 典型用户画像,可以快速建立用户认知,进入一个模式领域,可以通过Persona快速了解用户的行为偏好,用户诉求,从而了解业务。Profile 人物档案,通过数据标签精确刻画用户,可以基于标签进行用户分群、个性化推送等。
24 又忘记lift了
Lift,名称为提升度,其含义为:经过某种排序后圈出来的坏人浓度,相对于随机抽样的坏人浓度的提升。
- 比如对于
分箱的lift,就是分箱之后的每一箱的坏账率相对于总的坏账率的提升度;模型分排序后的每个分数段的lift就是按照模型分段计算出的坏账率相对于总的坏账率的提升度 - 计算公式为: 分段 / 分箱的坏账率 随机抽样的坏账率(总坏账率) \frac{分段/分箱的坏账率}{随机抽样的坏账率(总坏账率)} 随机抽样的坏账率(总坏账率)分段/分箱的坏账率
啊啊啊!!!结束啦!!!下班啦!!!