C++ 带你吃透string容器的使用
C++ 带你吃透string容器的使用
- 一.string容器概述
- 二.string容器的使用
-
- 1.string容器的默认成员函数
-
- 1.构造函数和拷贝构造函数
- 2.赋值运算符重载
- 3.析构函数
- 2.string容器的遍历和访问元素
-
- 1.operator[]运算符重载
- 2.iterator迭代器
-
- 1.begin()和end()
- 2.rbegin()和rend()
- 3.iterator的真正价值
- 4.范围for
- 5.at()
- 3.string容器与容量相关的函数
-
- 1.capacity,size,length
- 2.reserve
- 3.resize
- 4.clear,empty
- 4.尾插操作
-
- 1.push_back
- 2.append
- 3.+=运算符重载
- 5.指定位置的修改操作
-
- 1.insert
- 2.erase
- 3.replace
- 6.查找,交换,截取操作
-
- 1.find
- 2.其他跟find相关的函数
-
- 1.rfind
- 2.了解即可
- 3.find和replace的应用场景
- 4.swap
- 5.substr
- 6.find和substr的应用场景
- 7.string类型转为const char*类型
-
- 1.c_str
- 2.data
- 8.非成员函数
-
- 1.比较运算符重载
- 2.+运算符重载
- 3.getline
- 4.<< 和 >>
- 9.其他不太重要的函数
-
- 1.assign
- 2.copy
- 三.揭秘string容器的迭代器
-
- 1.string容器迭代器的本质
- 2.iterator迭代器使用
- 3.范围for的本质
- 4.iterator的补充
-
- 补充最前面的构造函数的最后一个重载版本
- 注意:get_allocator以后会介绍
接下来我们就要正式进入C++中STL的学习当中了
今天我们介绍的是STL中的string容器
我们对于STL的学习可以借助文档去学习:
我们今天就要通过cplusplus这个网站来介绍string容器
一.string容器概述
首先我们要了解的是:
什么是string容器?

注意:使用string容器需要包含头文件:
在了解了string容器之后,我们先来学习一下string容器的使用
二.string容器的使用
1.string容器的默认成员函数
我们先来介绍string容器的默认成员函数,这里只显示了构造函数(其中也包含拷贝构造函数),析构函数,赋值运算符重载这4个默认成员函数.
至于剩下的那两个取地址运算符重载函数则不是很重要,我们平常也不需要特别关心那两个默认成员函数
那么下面我们就去介绍这4个默认成员函数

1.构造函数和拷贝构造函数
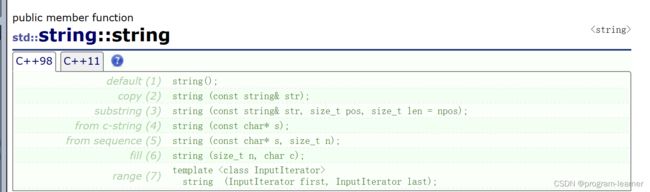
下面我们一一演示,并说明用法
第一种和第二种:

//这是最常用,最常见的两种用法
string s1;//第一种用法:无参构造
string s2("hello string");//第二种用法:含参构造,使用常量字符串来初始化s2
string s3 = s2;//注意:拷贝构造,而不是赋值运算符重载!
s3 = s1;//这个才是赋值运算符重载
string s4(s3);//拷贝构造

下面我们来看第三种用法:

string s2("hello string");
string s4(s2, 1, 6);//ello s
string s5(s2, 0, 100);//hello string

下面来看第4种用法
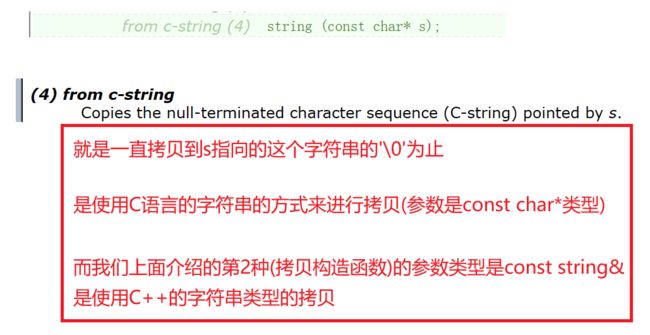
其实这个重载版本没什么太大的价值
因为string容器的构造函数支持单参数的构造函数的隐式类型转换
C++类和对象下(初始化列表,静态成员,explicit关键字,友元)
关于单参数的构造函数的隐式类型转换的问题,大家可以看我的这篇博客,在介绍explicit关键字的时候有详细的介绍
const char* ptr = "hello C string";
string s6(ptr);

下面来看第5种用法

const char* ptr = "hello C string";
string s7(ptr, 4);

下面来看第6种


至于第7种:
![]()
这个是跟迭代器有关的,我们目前先不谈,因为我们还没有介绍迭代器呢
在文章的最后的时候,我们就会揭开string容器的迭代器的神秘面纱
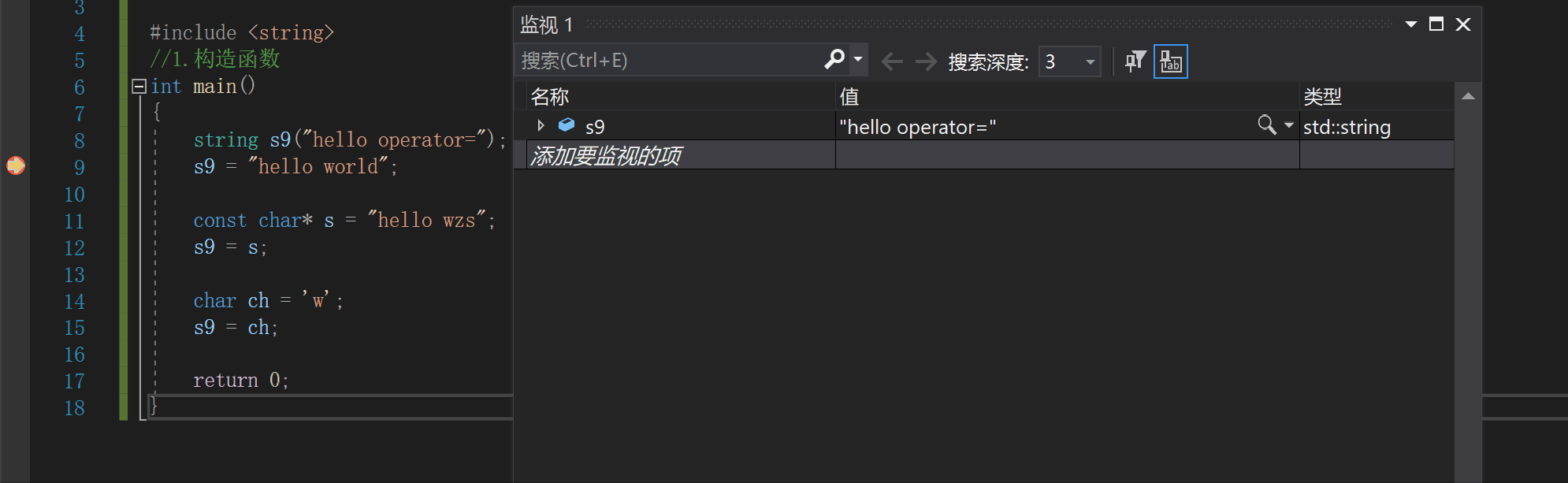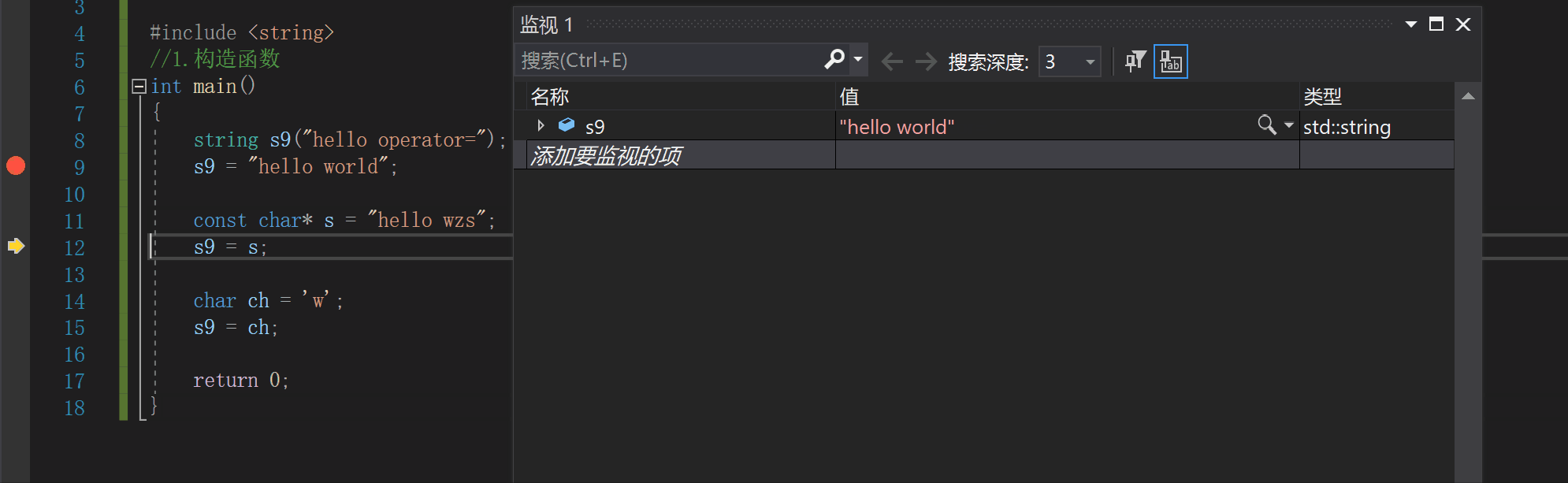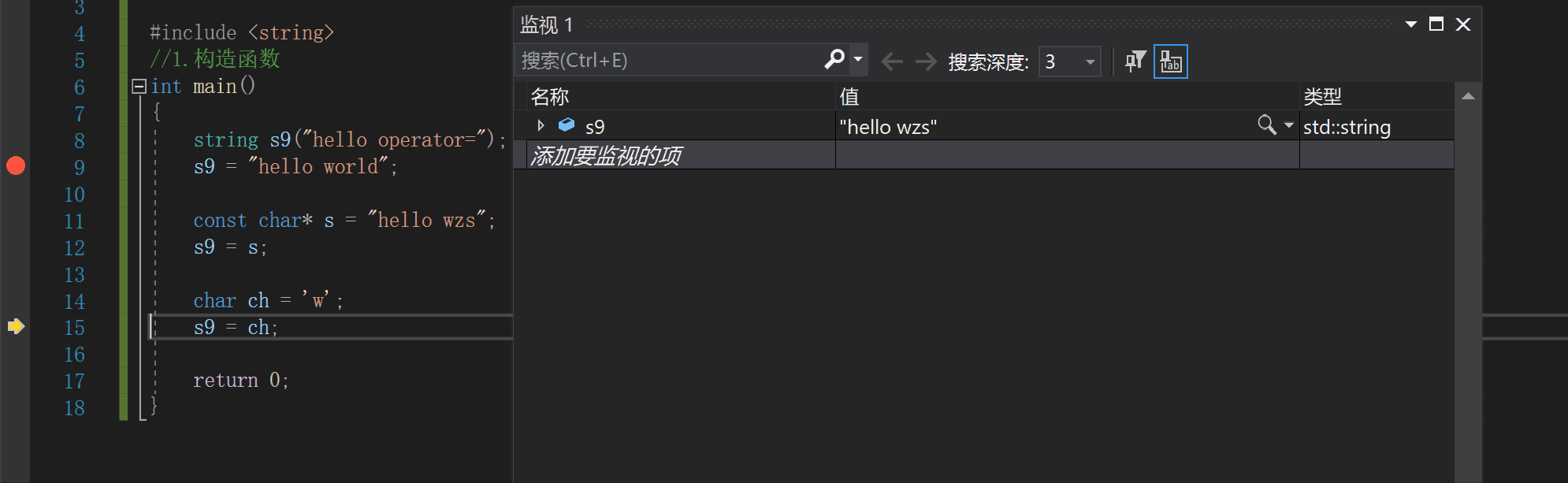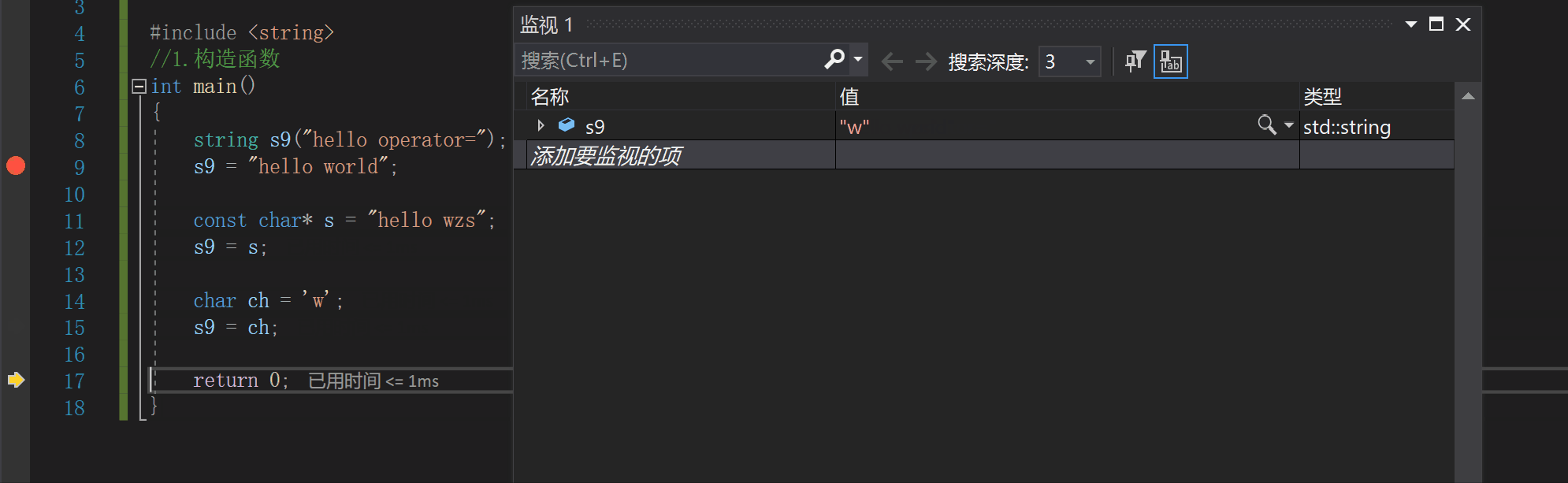
2.赋值运算符重载
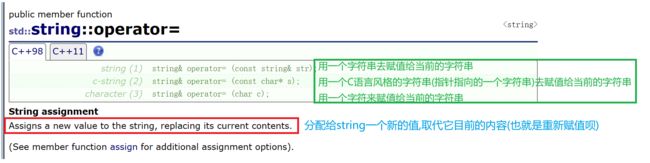
string s9("hello operator=");
s9 = "hello world";
const char* s = "hello wzs";
s9 = s;
char ch = 'w';
s9 = ch;
3.析构函数

2.string容器的遍历和访问元素
这里要首先介绍两个函数

1.operator[]运算符重载

也就是说我们可以像访问数组一样来访问string容器

string s1 = "hello string";
for (int i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}
cout << endl;
cout << s1 << endl;
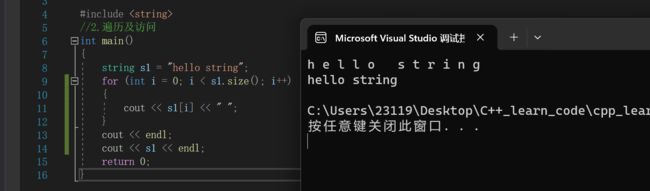
同理因为s1没有被const修饰,所以调用的是operator[]的第一种重载版本
char& operator[] (size_t pos);
因此也可以进行修改
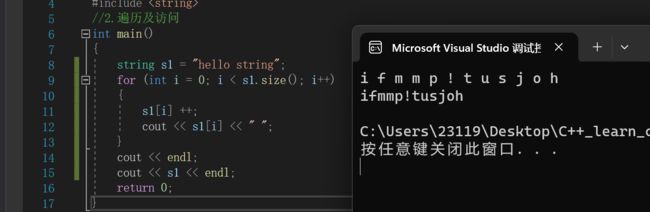
string s1 = "hello string";
for (int i = 0; i < s1.size(); i++)
{
s1[i] ++;
cout << s1[i] << " ";
}
cout << endl;
cout << s1 << endl;
介绍完operator[]的用法之后
让回到这个问题:为什么要重载两种版本呢?
因为会有const string这种类型的需求
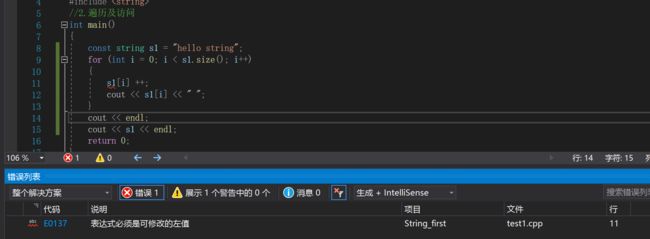
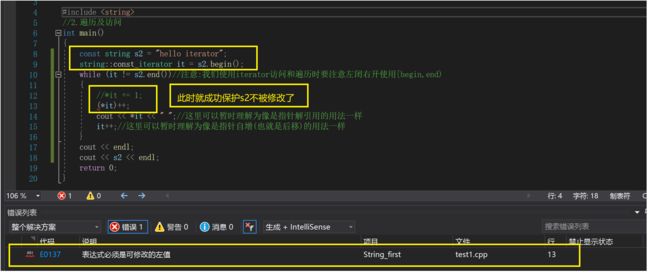
重载了两个版本之后:这样就可以保证s1这个被const修饰的字符串不被[]所修改了
2.iterator迭代器
1.begin()和end()
首先我们要先介绍两个特殊的迭代器:begin()和end()

在这个位置处,我们可以暂时把iterator迭代器当做指针去使用,因此我们就可以这样去遍历访问元素了
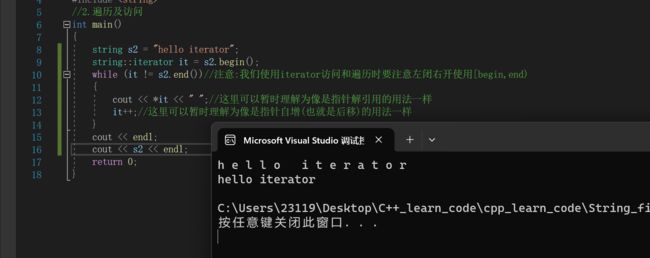
string s2 = "hello iterator";
string::iterator it = s2.begin();
while (it != s2.end())//注意:我们使用iterator访问和遍历时要注意左闭右开使用[begin,end)
{
cout << *it << " ";//这里可以暂时理解为像是指针解引用的用法一样
it++;//这里可以暂时理解为像是指针自增(也就是后移)的用法一样
}
cout << endl;
cout << s2 << endl;
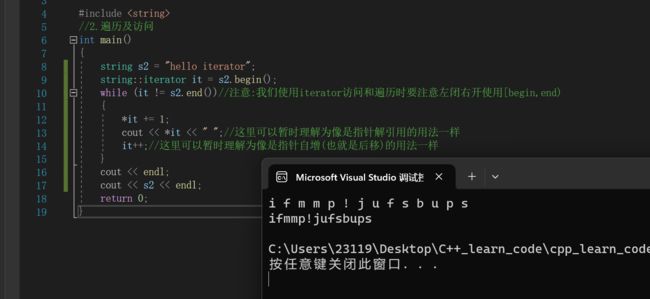
同样的,这个迭代器也可以用来改变这个string具体位置的元素的值
string s2 = "hello iterator";
string::iterator it = s2.begin();
while (it != s2.end())//注意:我们使用iterator访问和遍历时要注意左闭右开使用[begin,end)
{
*it += 1;//(*it)++;这样也可以,不过不要忘了加小括号(运算符优先级的问题)
cout << *it << " ";//这里可以暂时理解为像是指针解引用的用法一样
it++;//这里可以暂时理解为像是指针自增(也就是后移)的用法一样
}
cout << endl;
cout << s2 << endl;

const string s2 = "hello iterator";
string::const_iterator it = s2.begin();
while (it != s2.end())//注意:我们使用iterator访问和遍历时要注意左闭右开使用[begin,end)
{
//*it += 1;
(*it)++;//err
cout << *it << " ";//这里可以暂时理解为像是指针解引用的用法一样
it++;//这里可以暂时理解为像是指针自增(也就是后移)的用法一样
}
cout << endl;
cout << s2 << endl;
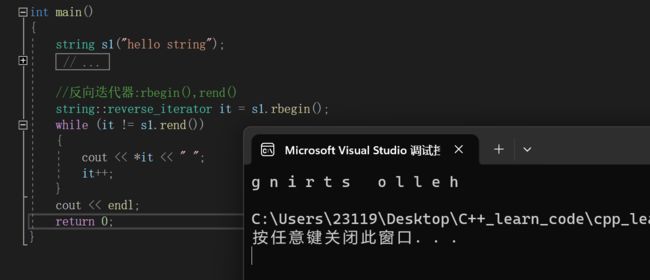
2.rbegin()和rend()
迭代器也可以倒着遍历,就像这样:

可能这个英文解释不是很好理解,下面我们来演示一下:
//反向迭代器:rbegin(),rend()
string::reverse_iterator it = s1.rbegin();
while (it != s1.rend())
{
cout << *it << " ";
it++;
}
cout << endl;
同理,这个rbegin()和rend()也分为const迭代器和非const迭代器,
在这里就不赘述了,因为刚才讲begin()和end()的时候说明过区别
不过实际当中这个rbegin()和rend()并不常用
远远没有begin()和end()的出场率高
下面大家可能有疑问,这个迭代器访问元素哪有我直接下标访问香啊
这个迭代器也不过如此嘛
下面我们来说一下iterator的真正价值
3.iterator的真正价值

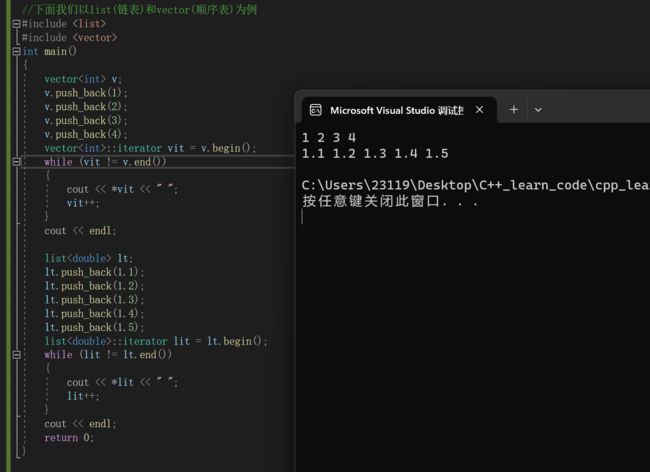
除此之外,借助迭代器还可以使用很多库函数的功能
比如:使用reverse逆置string,vector,list等等

#include
#include 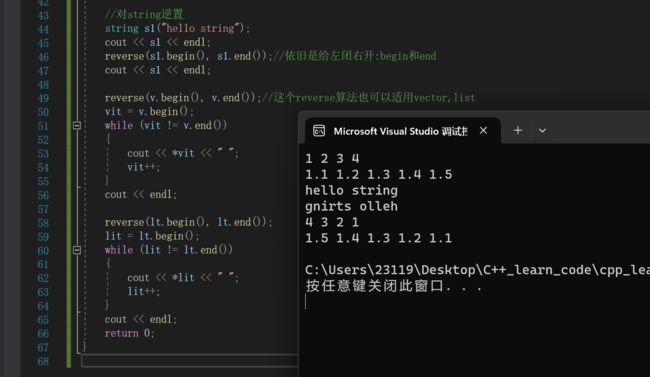
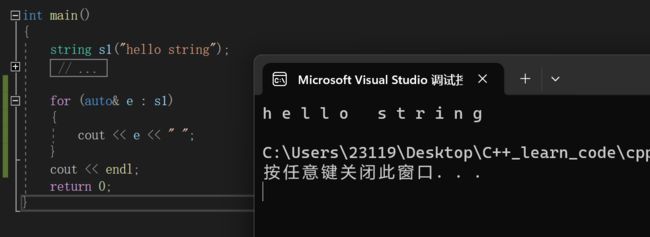
4.范围for
string容器也支持范围for的用法
关于范围for的知识,请看这篇博客:C++入门3+类和对象上
for (auto& e : s1)
{
cout << e << " ";
}
cout << endl;
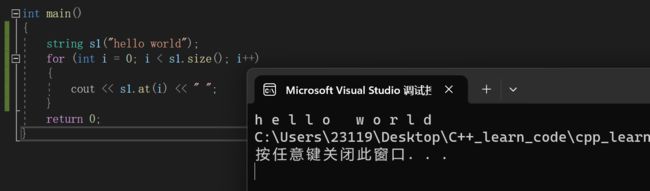
5.at()
关于at(),它跟[]的用法很像
string s1("hello world");
for (int i = 0; i < s1.size(); i++)
{
cout << s1.at(i) << " ";
}
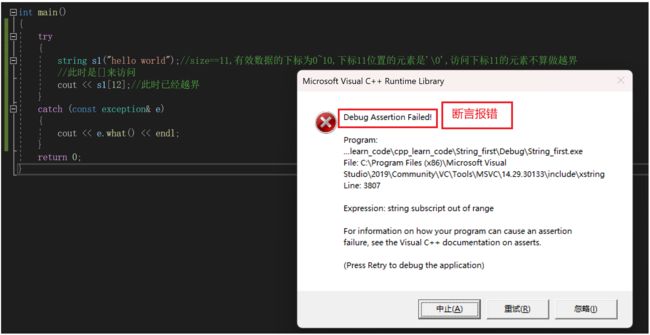
但是它们之间也存在一些差异

下面我们来演示一下:
这是[]来越界访问
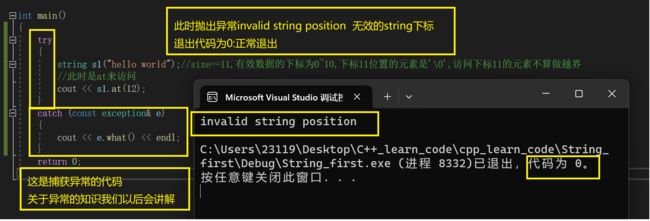
这是at来越界访问
3.string容器与容量相关的函数
1.capacity,size,length
size()和length()我们前面提到过了,这里就不赘述了

接下来是容量capacity这个概念

2.reserve
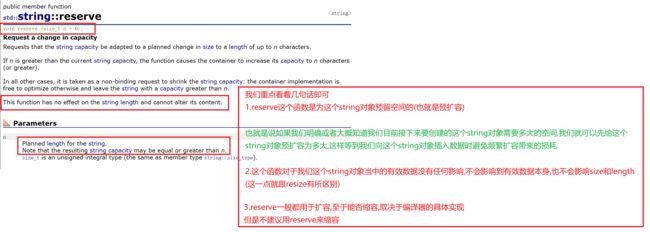
下面我们来演示一下,顺便看一下在VS2019中的扩容机制
string s1;
int old_capacity = s1.capacity();
cout << old_capacity << endl;
for (int i = 0; i < 100; i++)
{
s1.push_back('w');//将'w'这个字符尾插进入s1当中
if (old_capacity != s1.capacity())
{
cout << s1.capacity() << endl;
old_capacity = s1.capacity();
}
}
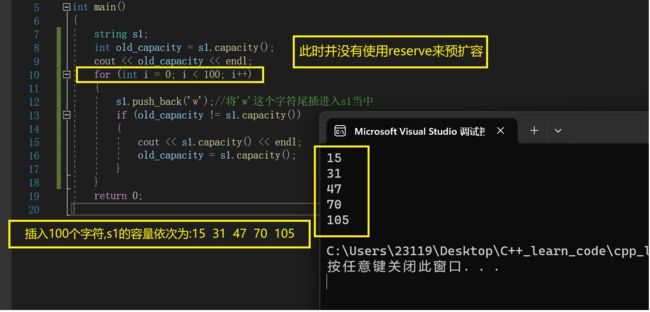
string s1;
s1.reserve(100);
int old_capacity = s1.capacity();
cout << old_capacity << endl;
for (int i = 0; i < 100; i++)
{
s1.push_back('w');//将'w'这个字符尾插进入s1当中
if (old_capacity != s1.capacity())
{
cout << s1.capacity() << endl;
old_capacity = s1.capacity();
}
}
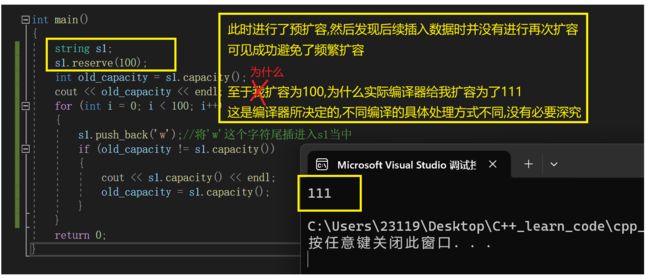
然后我们将插入的数据改为1000
看一下扩容的区别
string s1;
int old_capacity = s1.capacity();
cout << old_capacity << endl;
for (int i = 0; i < 1000; i++)
{
s1.push_back('w');//将'w'这个字符尾插进入s1当中
if (old_capacity != s1.capacity())
{
cout << s1.capacity() << endl;
old_capacity = s1.capacity();
}
}
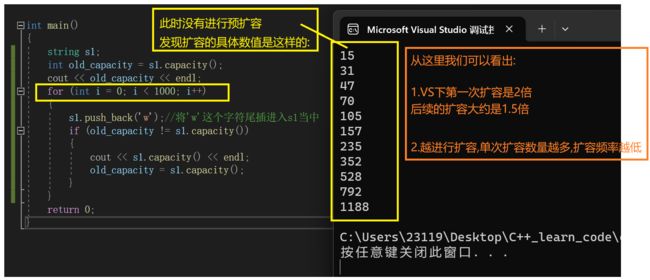
扩容的机制在不同编译器下是不一样的
下面我们以Linux环境下的g++编译器来演示一下
一模一样的代码,我们来看一下运行结果
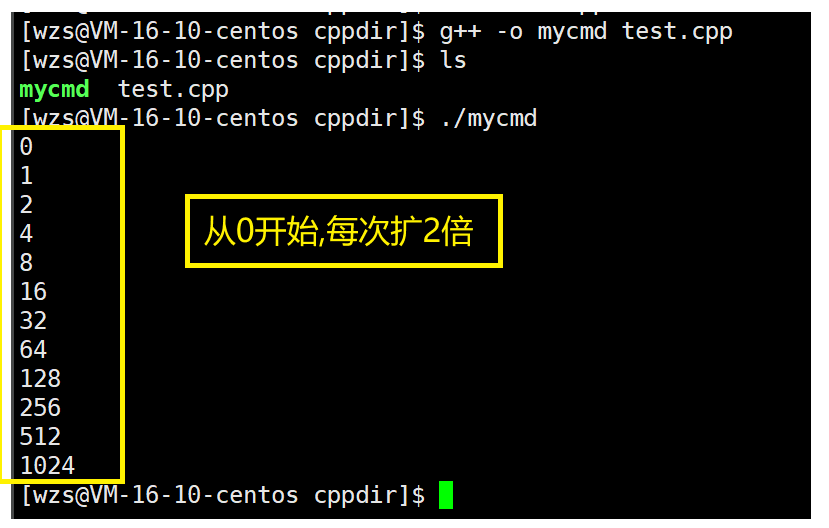
大家需要了解reserve的常见使用场景:提前扩容

3.resize
下面这几个尾插操作都是自动扩容的,不需要我们操心 真正常用的是这个+=运算符重载 所以insert能少用就少用 下面我们先来演示一下replace的用法 用法相同,注意跟find的区别即可 《剑指offer》上面有这么一道题: 下面介绍一种非常好用的方法: 这里的swap的实现其实就是 find和substr也能够很好地放到一起使用 对于这个网址来说: 我们想要截取它的 下面我们回归这个需求,开始实现一下 我们在文件操作的时候提到过fopen函数 要介绍这个getline 对于流插入和流提取 其实对于string容器来说 然后我们就可以使用了 在这里我先模拟实现了string的构造函数,析构函数,还有这个迭代器 然后我们就可以自己去玩这个迭代器了 其实范围for就是迭代器 但是所有的iterator都是指针吗? 这个get_allocator涉及到适配器的知识,我们以后会介绍的 以上就是C++ 带你吃透string容器的使用的全部内容,希望能对大家有所帮助!
下面我们来演示一下:
第一种情况:
nstring s1("hello world");
//1.n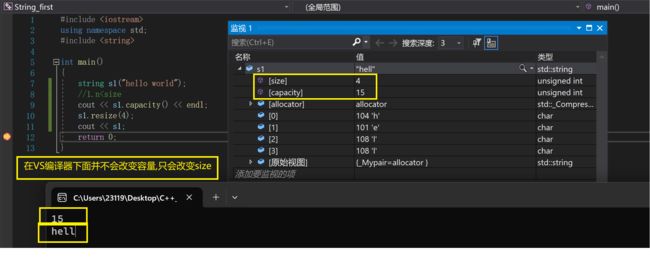
第二种情况:
sizestring s1("hello world");
//2.size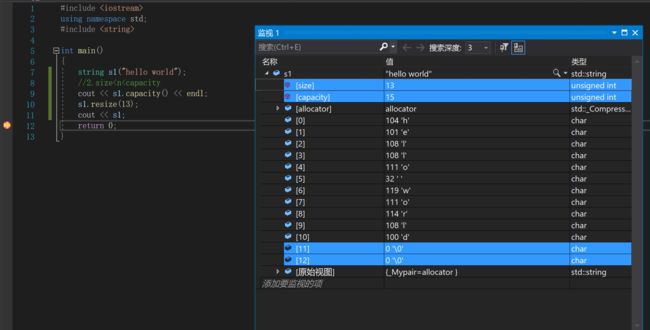
可见,的确是用’\0’来填充的
刚才我们看到:s1的容量是15
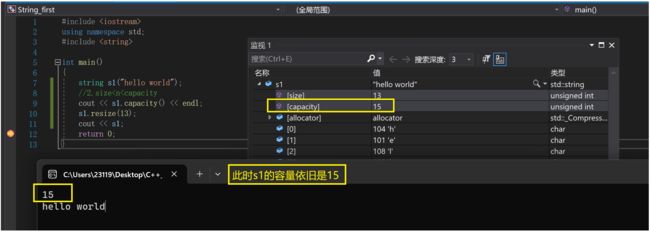
第三种情况:
n>capacity: 此时相当于先扩容,然后尾插字符c或者’\0’
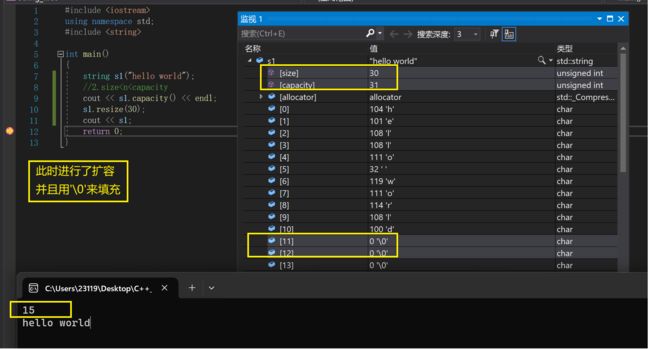
下面我们来介绍一下resize的常见使用场景:

4.clear,empty

这两个函数都很简单,大家了解即可4.尾插操作
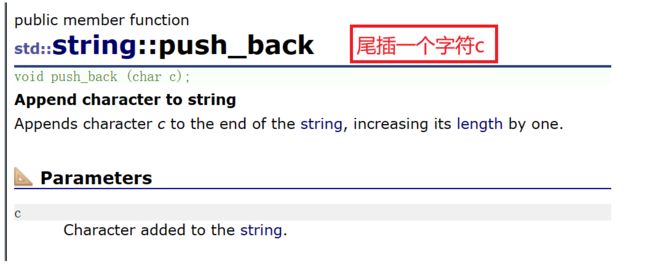
1.push_back
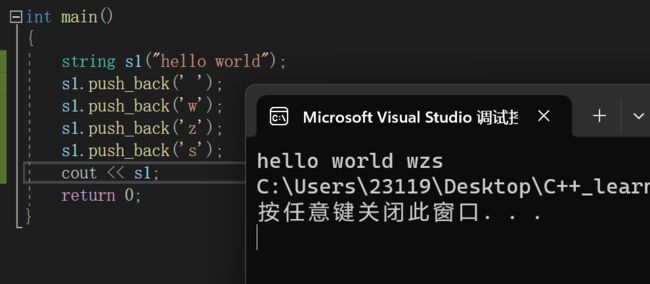
2.append

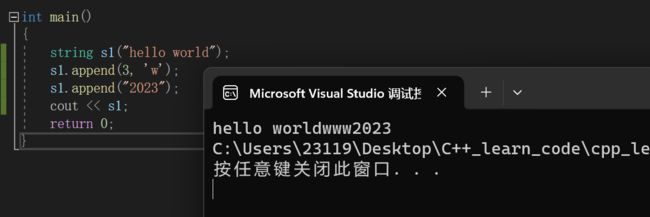
关于其他的用法,平常并不常用,大家知道即可
比如使用迭代器来append一段区间
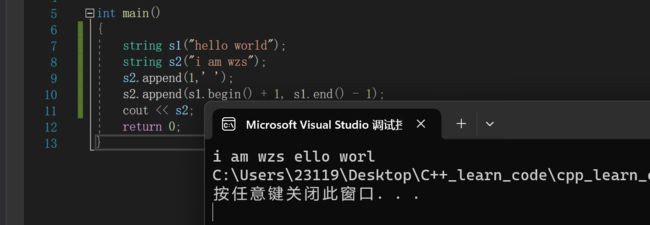
3.+=运算符重载
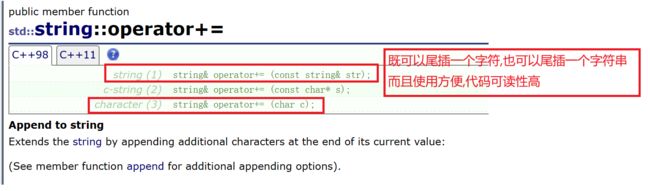
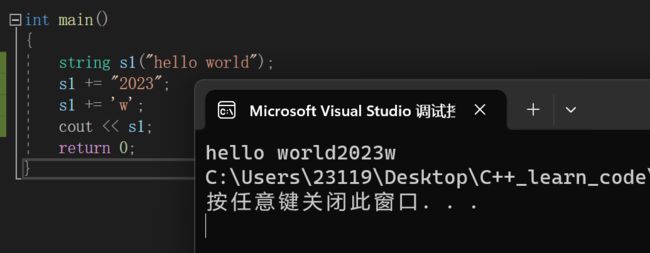
5.指定位置的修改操作
1.insert
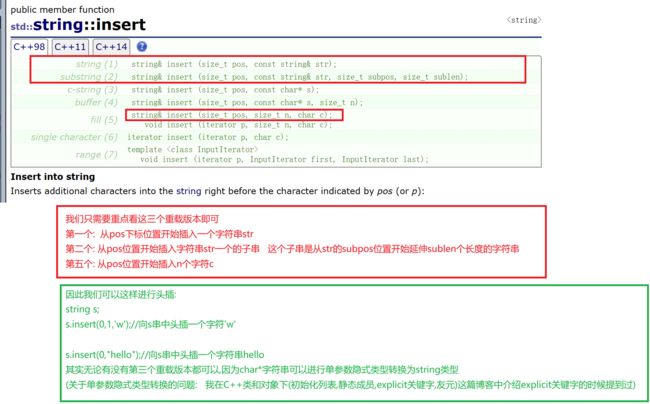
关于单参数隐式类型转换的问题,请看这篇博客当中的explicit关键字部分的介绍
C++类和对象下(初始化列表,静态成员,explicit关键字,友元)
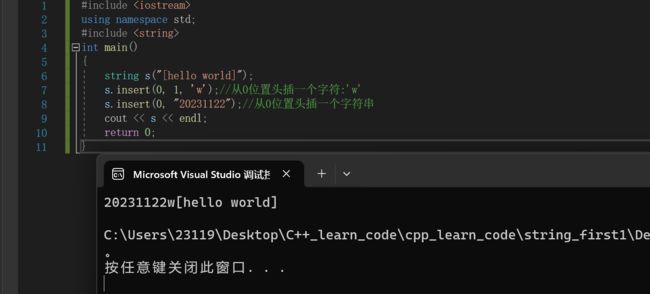
下面我们来演示一下insert的用法string s("[hello world]");
s.insert(0, 1, 'w');//从0位置头插一个字符:'w'
s.insert(0, "20231122");//从0位置头插一个字符串
cout << s << endl;
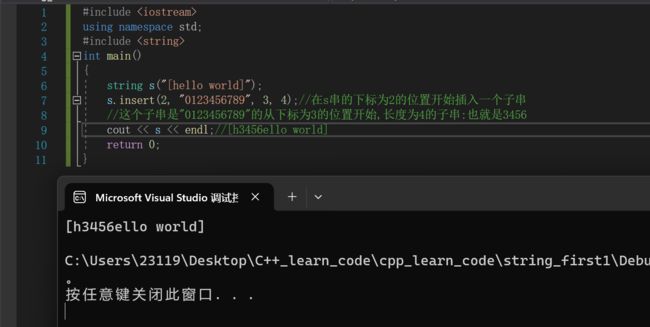
string s("[hello world]");
s.insert(2, "0123456789", 3, 4);//在s串的下标为2的位置开始插入一个子串
//这个子串是"0123456789"的从下标为3的位置开始,长度为4的子串:也就是3456
cout << s << endl;//[h3456ello world]
因为insert的插入效率不高(因为string是顺序表,物理空间是连续的,插入一个字符或者删除一个字符会造成大量数据的挪动,因此效率不高)2.erase
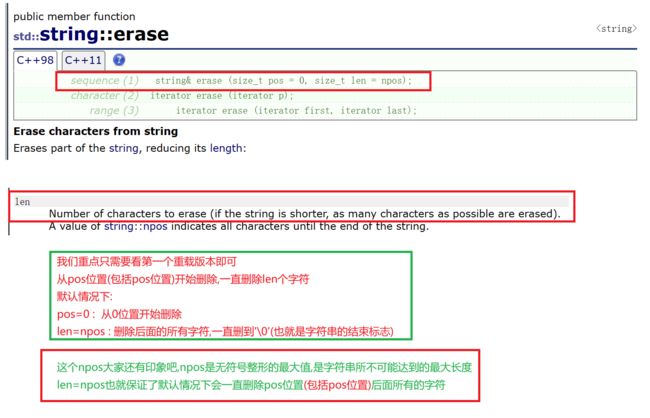
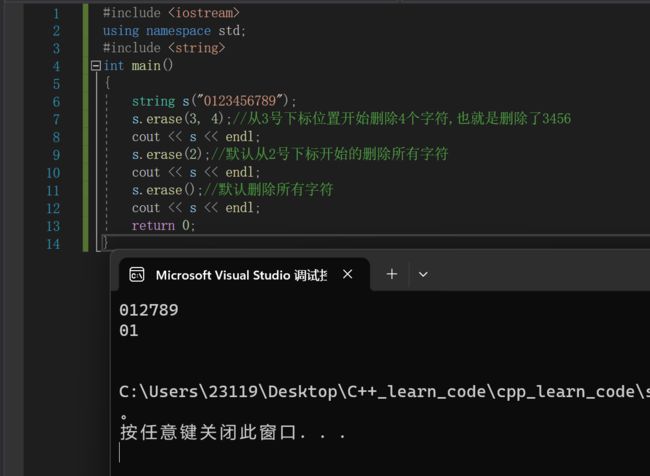
下面我们来演示一下:string s("0123456789");
s.erase(3, 4);//从3号下标位置开始删除4个字符,也就是删除了3456
cout << s << endl;
s.erase(2);//默认从2号下标开始的删除所有字符
cout << s << endl;
s.erase();//默认删除所有字符
cout << s << endl;
跟insert一样,效率低,能少用就少用3.replace

其实replace并不好用,因为效率低
频繁挪动数据,偶尔用一次就算了
但是不建议一次性使用很多次,效率会非常低,因为会造成数据频繁重复性地挪动
我们介绍完find之后会结合find跟replace来介绍一个场景
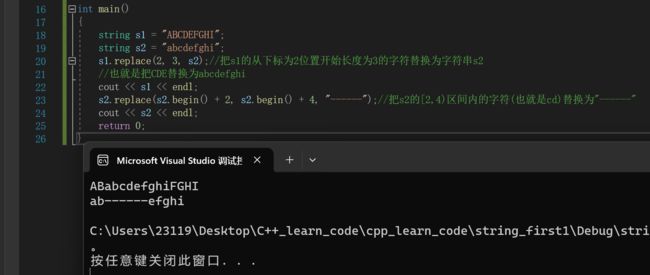
在那里我们将会对replace的低效性,重复性有更深的理解string s1 = "ABCDEFGHI";
string s2 = "abcdefghi";
s1.replace(2, 3, s2);//把s1的从下标为2位置开始长度为3的字符替换为字符串s2
//也就是把CDE替换为abcdefghi
cout << s1 << endl;
s2.replace(s2.begin() + 2, s2.begin() + 4, "------");//把s2的[2,4)区间内的字符(也就是cd)替换为"------"
cout << s2 << endl;
6.查找,交换,截取操作
1.find

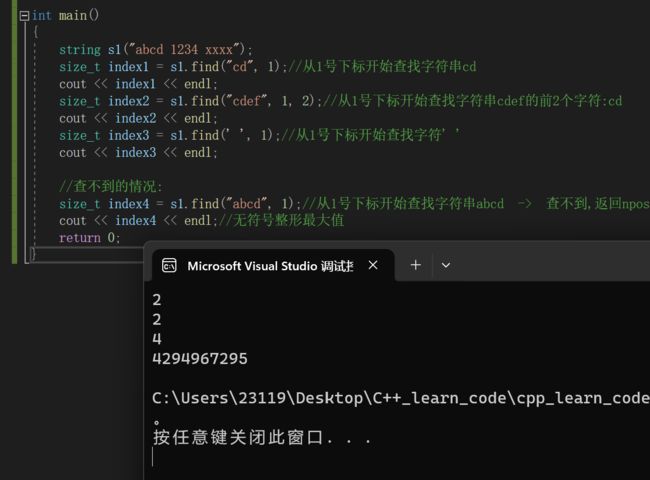
string s1("abcd 1234 xxxx");
size_t index1 = s1.find("cd", 1);//从1号下标开始查找字符串cd
cout << index1 << endl;
size_t index2 = s1.find("cdef", 1, 2);//从1号下标开始查找字符串cdef的前2个字符:cd
cout << index2 << endl;
size_t index3 = s1.find(' ', 1);//从1号下标开始查找字符' '
cout << index3 << endl;
//查不到的情况:
size_t index4 = s1.find("abcd", 1);//从1号下标开始查找字符串abcd -> 查不到,返回npos
cout << index4 << endl;//无符号整形最大值
2.其他跟find相关的函数
1.rfind
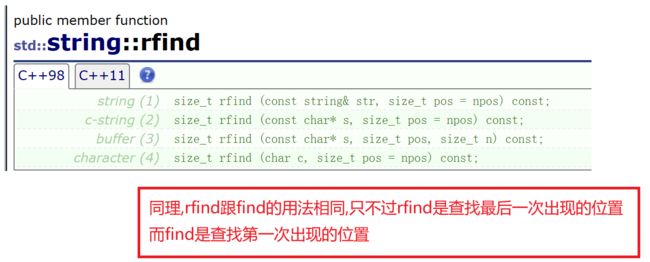
下面的这几个大家知道有这么个函数即可
不常用2.了解即可



下面是cplusplus网站上的几个用例
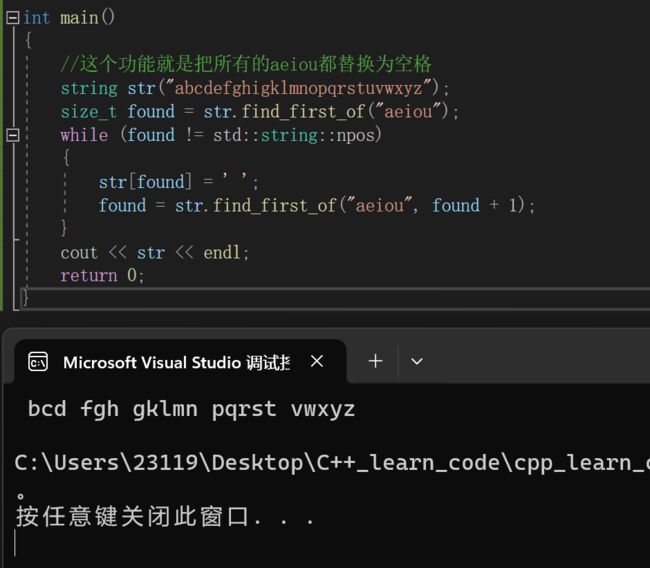
大家可以了解一下//这个功能就是把所有的aeiou都替换为空格
string str("abcdefghigklmnopqrstuvwxyz");
size_t found = str.find_first_of("aeiou");
while (found != std::string::npos)
{
str[found] = ' ';
found = str.find_first_of("aeiou", found + 1);
}
cout << str << endl;
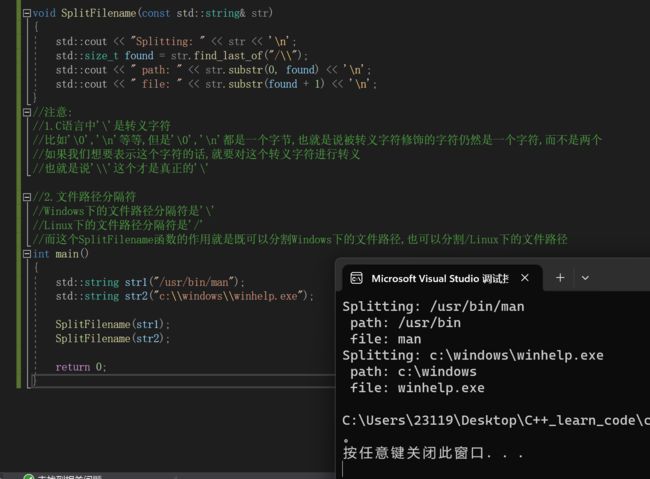
void SplitFilename(const std::string& str)
{
std::cout << "Splitting: " << str << '\n';
std::size_t found = str.find_last_of("/\\");
std::cout << " path: " << str.substr(0, found) << '\n';
std::cout << " file: " << str.substr(found + 1) << '\n';
}
注意:
1.C语言中'\'是转义字符
比如'\0','\n'等等,但是'\0','\n'都是一个字节,也就是说被转义字符修饰的字符仍然是一个字符,而不是两个
如果我们想要表示这个字符的话,就要对这个转义字符进行转义
也就是说'\\'这个才是真正的'\'
2.文件路径分隔符
Windows下的文件路径分隔符是'\'
Linux下的文件路径分隔符是'/'
而这个SplitFilename函数的作用就是既可以分割Windows下的文件路径,也可以分割/Linux下的文件路径
int main()
{
std::string str1("/usr/bin/man");
std::string str2("c:\\windows\\winhelp.exe");
SplitFilename(str1);
SplitFilename(str2);
return 0;
}
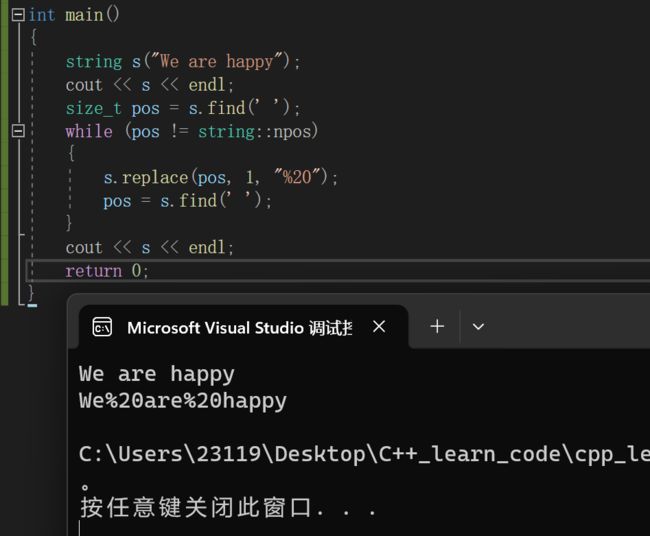
3.find和replace的应用场景

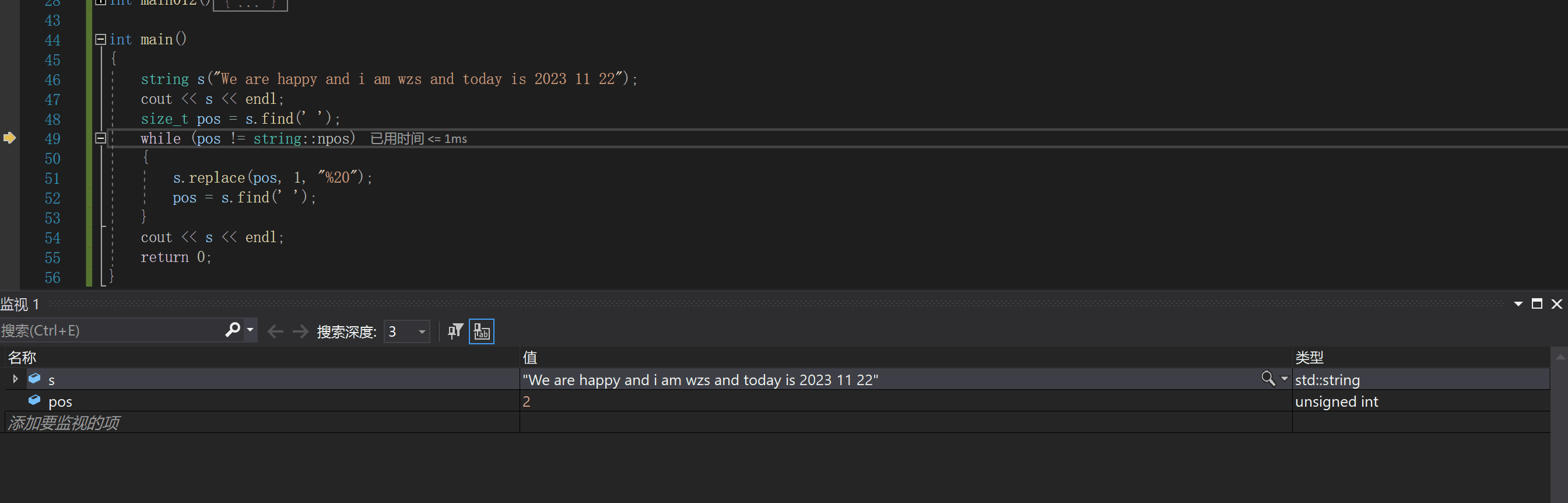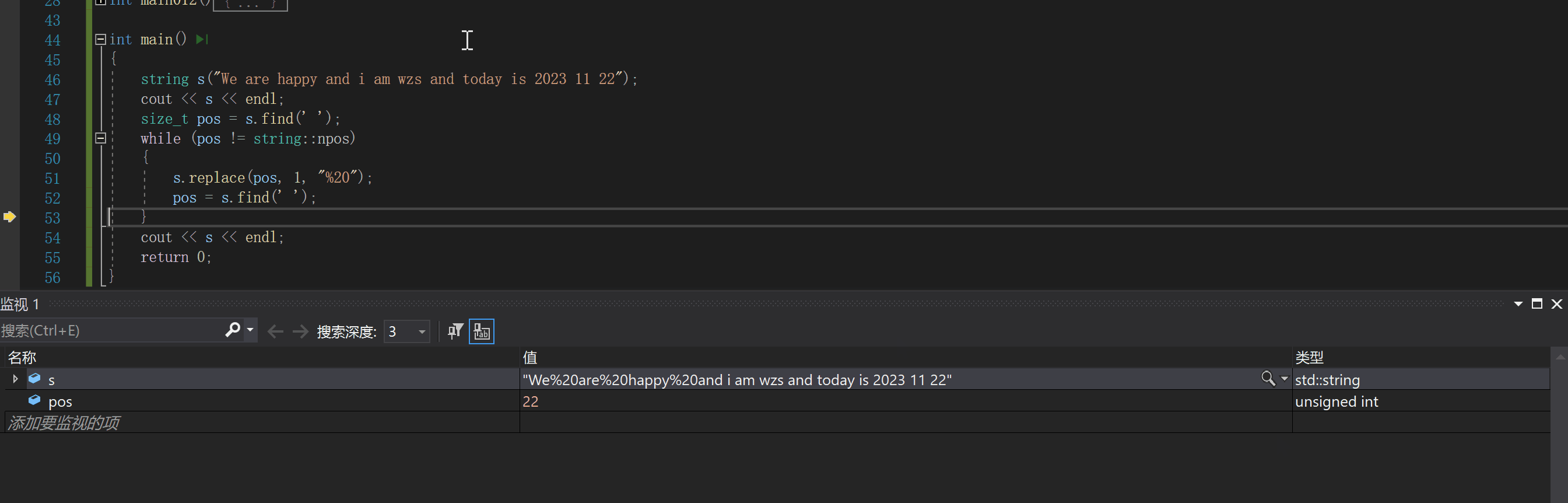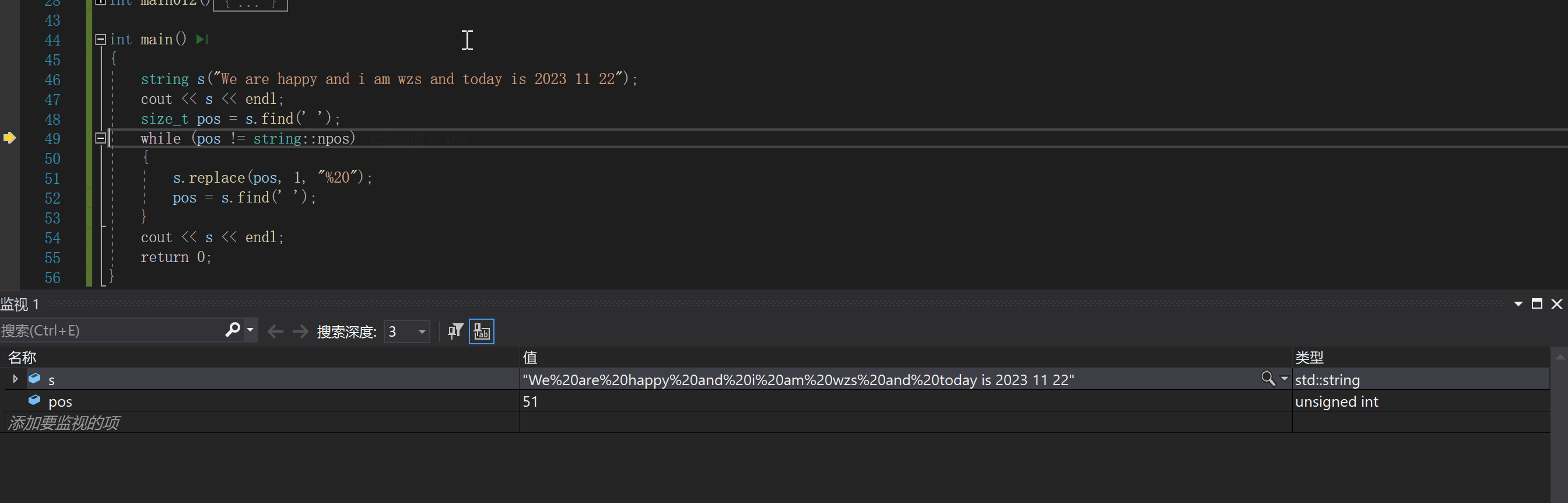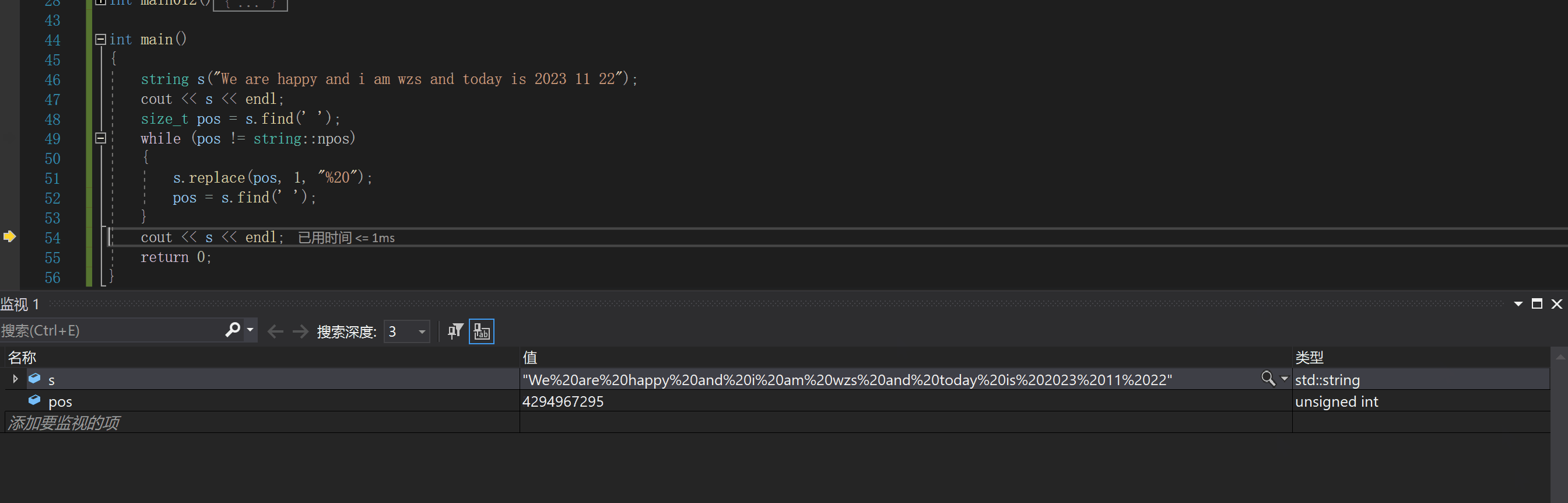
下面我们先使用find和replace来实现一下:string s("We are happy");
cout << s << endl;
size_t pos = s.find(' ');
while (pos != string::npos)
{
s.replace(pos, 1, "%20");
pos = s.find(' ');
}
cout << s << endl;
下面我们调试看看过程

我们可以看出,每次执行replace,对应空格之后的字符都要向后挪动
这就会导致出现频繁的空格移动
如果是比较长的字符:像是这样的
那这个效率就太低了
大家也可以用计算空格数来扩容后移的方法去做
但是那样还是比较麻烦的
空间换时间:string s("We are happy and i am wzs and today is 2023 11 22");
cout << s << endl;
string s1;
for (auto& e : s)
{
if (e == ' ')
{
s1 += "%20";
}
else
{
s1 += e;
}
}
s = s1;
cout << s << endl;
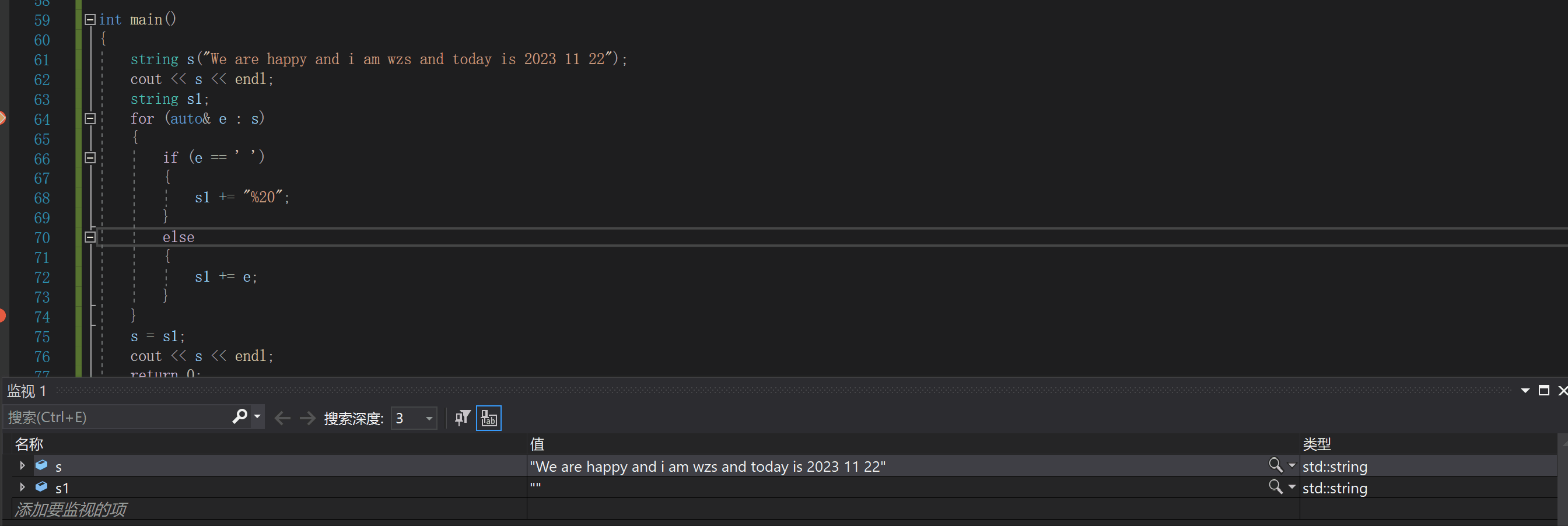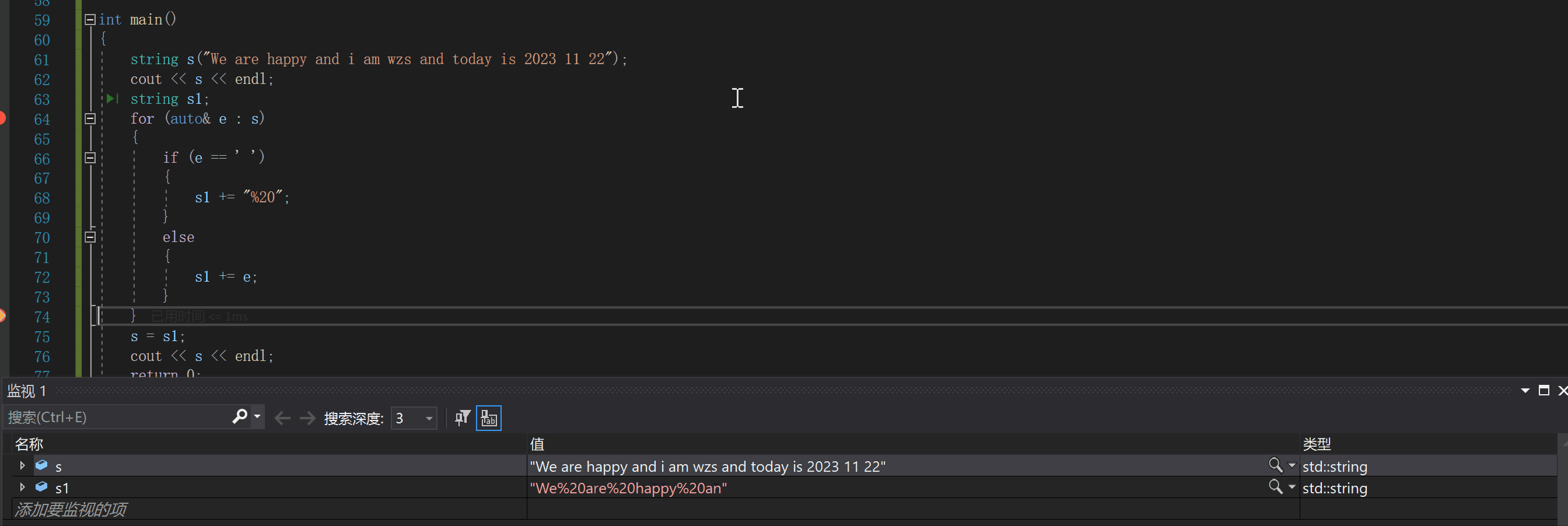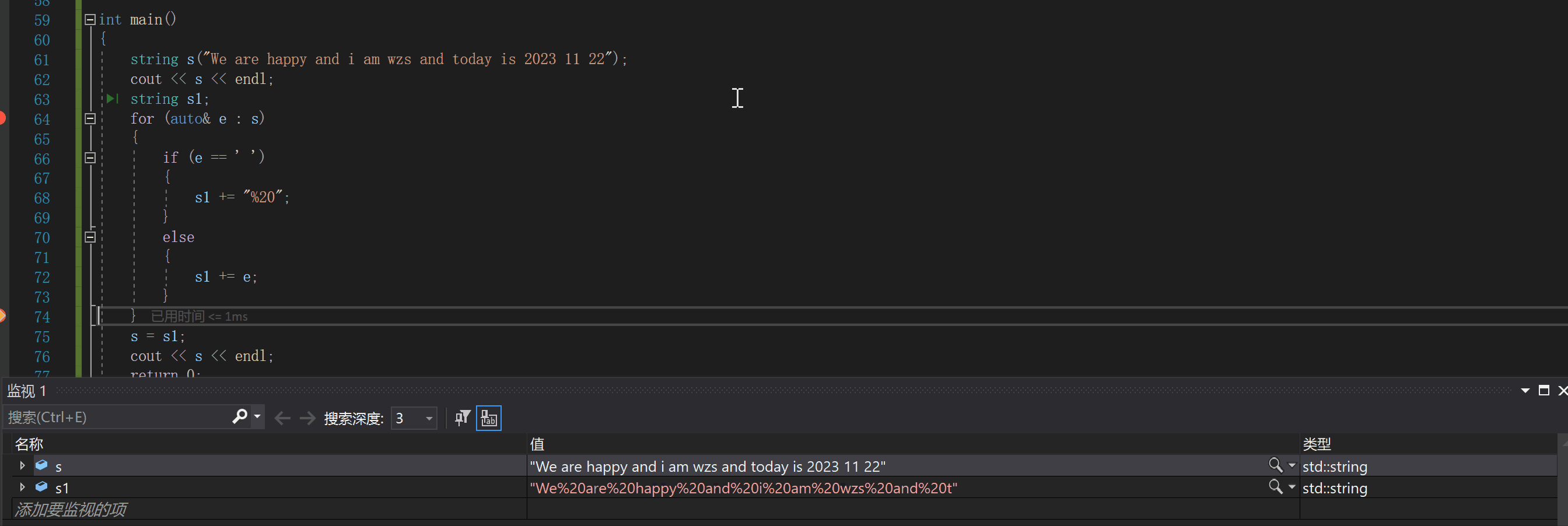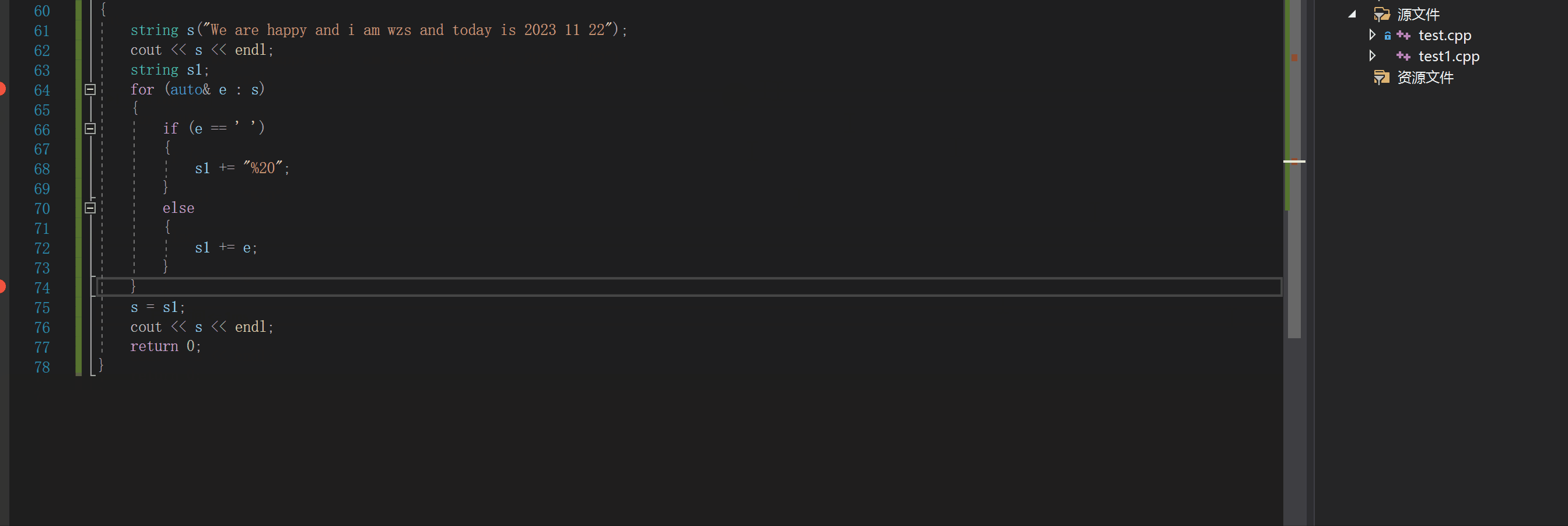
效率高,而且非常好实现4.swap
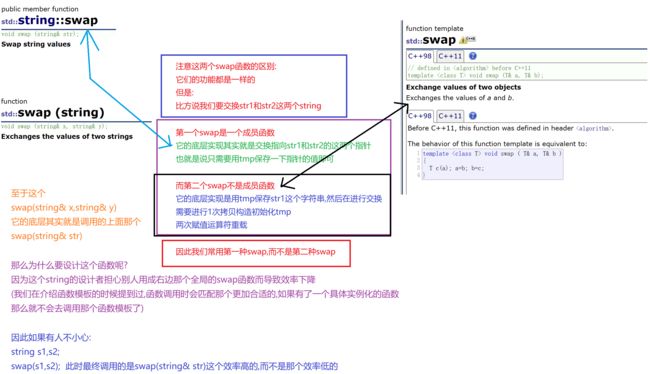
这个swap的底层实现类似于这样:void swap(string& s)
{
//这里调用的是std(标准库中的那个swap函数)
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
交换指针,交换_size和_capacity
这样做的好处是无需再去拷贝string了,而是直接交换指针即可,大大优化了swap的效率
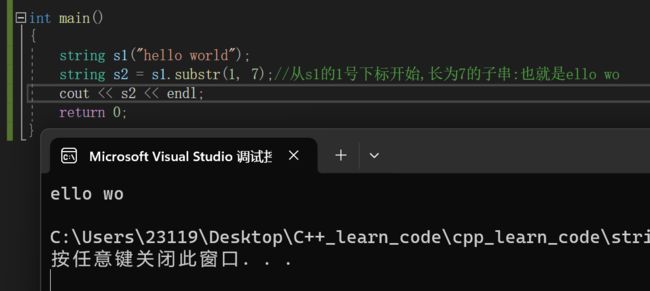
可见这个设计是非常巧妙的5.substr

下面我们来演示一下:
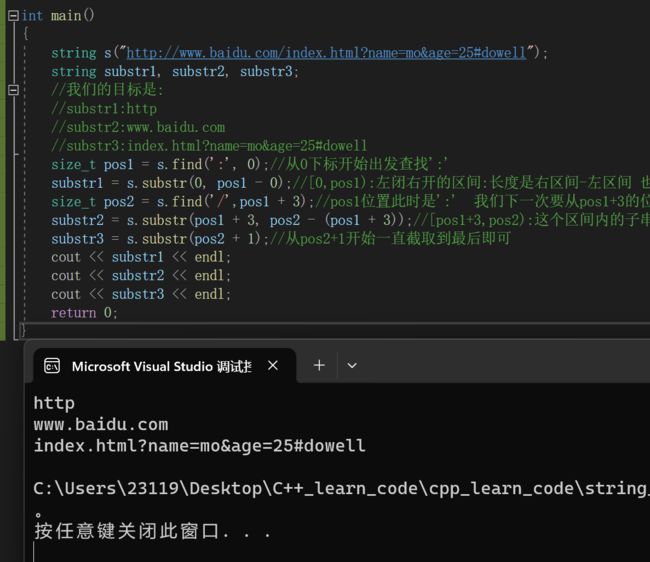
6.find和substr的应用场景
比方说下面这个场景
http://www.baidu.com/index.html?name=mo&age=25#dowell
1.协议:http
2.域名:www.baidu.com
3.剩下的这个 index.html?name=mo&age=25#dowell
(包括:端口、路径(虚拟路径)、携带的参数、哈希值)
浏览器地址栏的完整URL都包含哪些内容都各代表什么?
大家感兴趣的话可以看看这位大佬的文章
这些东西我们以后会介绍的string s("http://www.baidu.com/index.html?name=mo&age=25#dowell");
string substr1, substr2, substr3;
//我们的目标是:
//substr1:http
//substr2:www.baidu.com
//substr3:index.html?name=mo&age=25#dowell
size_t pos1 = s.find(':', 0);//从0下标开始出发查找':'
substr1 = s.substr(0, pos1 - 0);//[0,pos1):左闭右开的区间:长度是右区间-左区间 也就是pos1-0
size_t pos2 = s.find('/',pos1 + 3);//pos1位置此时是':' 我们下一次要从pos1+3的位置开始查找 也就是第一个'w'的位置
substr2 = s.substr(pos1 + 3, pos2 - (pos1 + 3));//[pos1+3,pos2):这个区间内的子串
substr3 = s.substr(pos2 + 1);//从pos2+1开始一直截取到最后即可
cout << substr1 << endl;
cout << substr2 << endl;
cout << substr3 << endl;
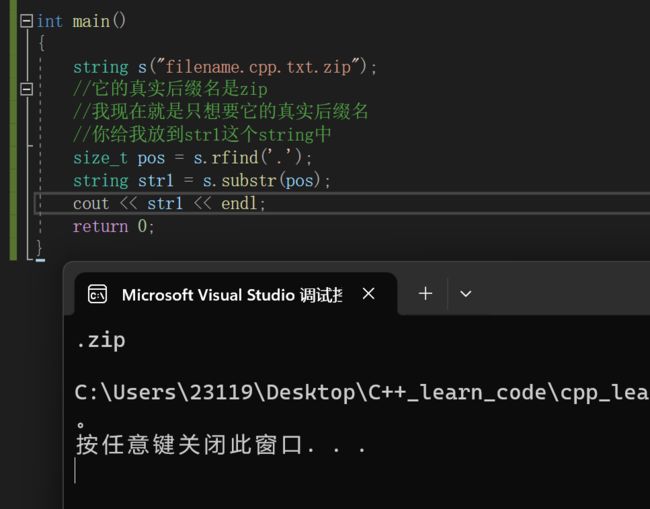
还有一个场景:
取文件后缀名
这是我随便编的一个文件string s("filename.cpp.txt.zip");
//它的真实后缀名是zip
//我现在就是只想要它的真实后缀名
//你给我放到str1这个string中
size_t pos = s.rfind('.');
string str1 = s.substr(pos);
cout << str1 << endl;
7.string类型转为const char*类型
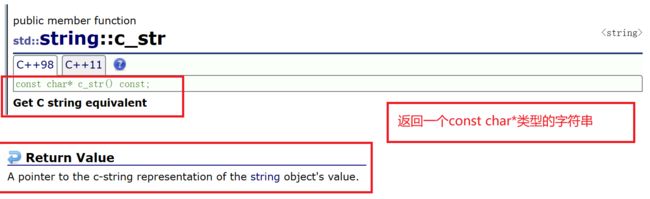
1.c_str
今天我们想这样去读取一个文件:
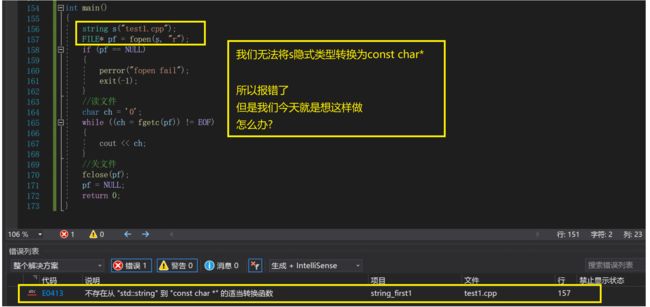
这时c_str就排上用场了
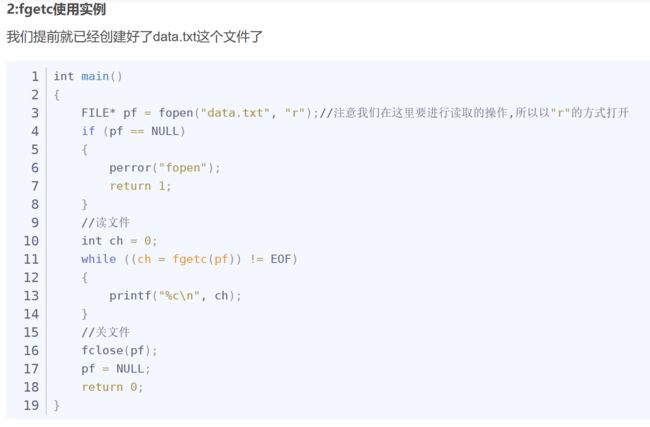
这时关于fgetc函数的使用:读取一个文件的内容
关于C语言文件操作的内容,大家可以看我的这一篇博客:
C语言文件操作详解
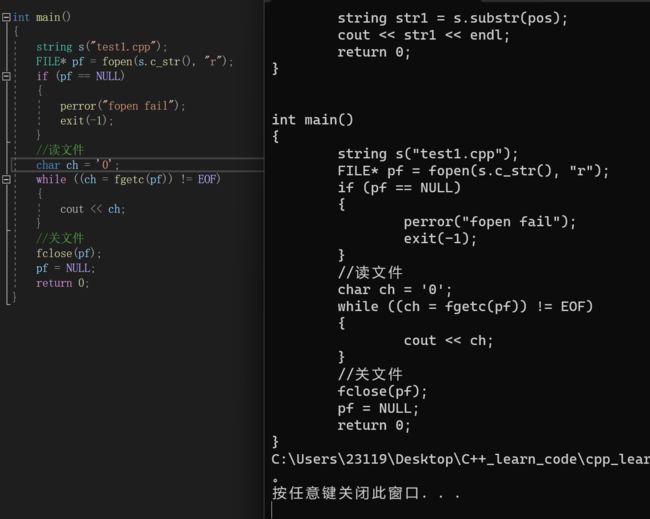
这样我们就成功读取了2.data

8.非成员函数
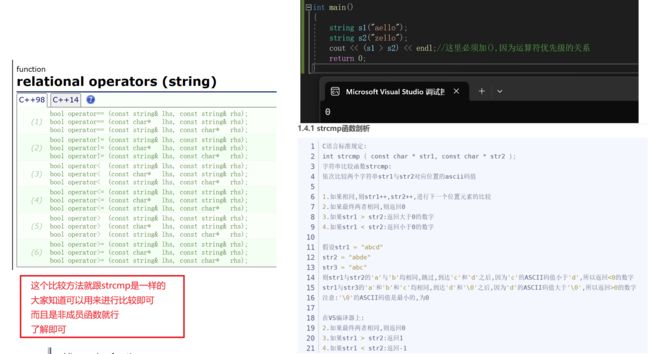
1.比较运算符重载
2.+运算符重载
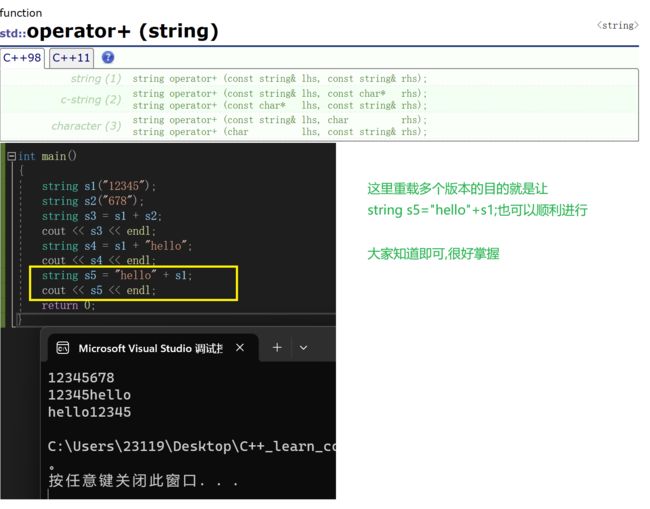
3.getline
我们可以通过一道题目来深刻理解getline的价值
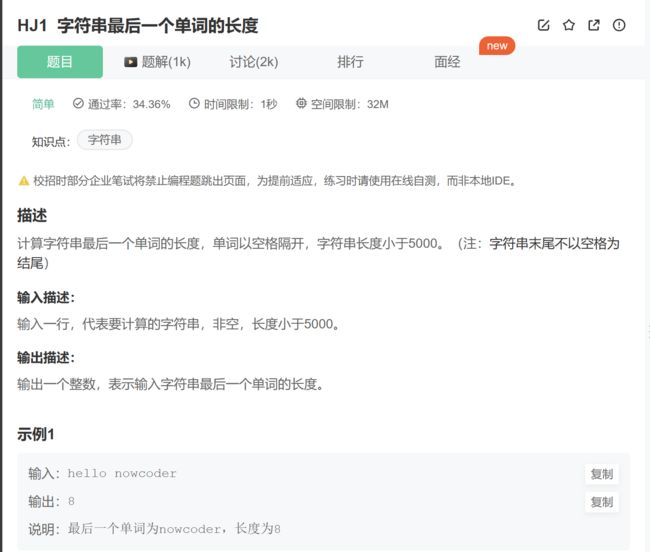
牛客:字符串最后一个单词的长度#include 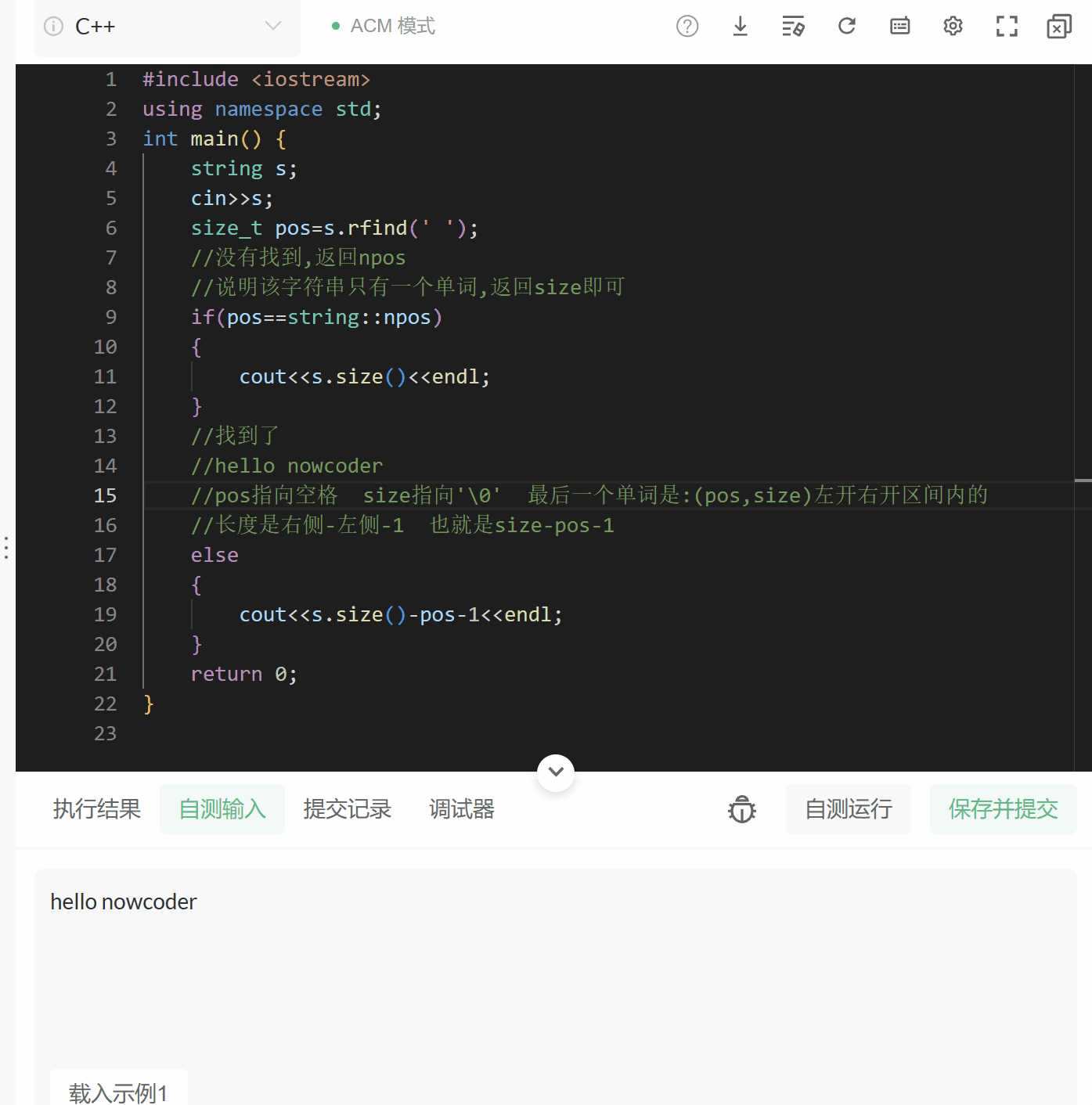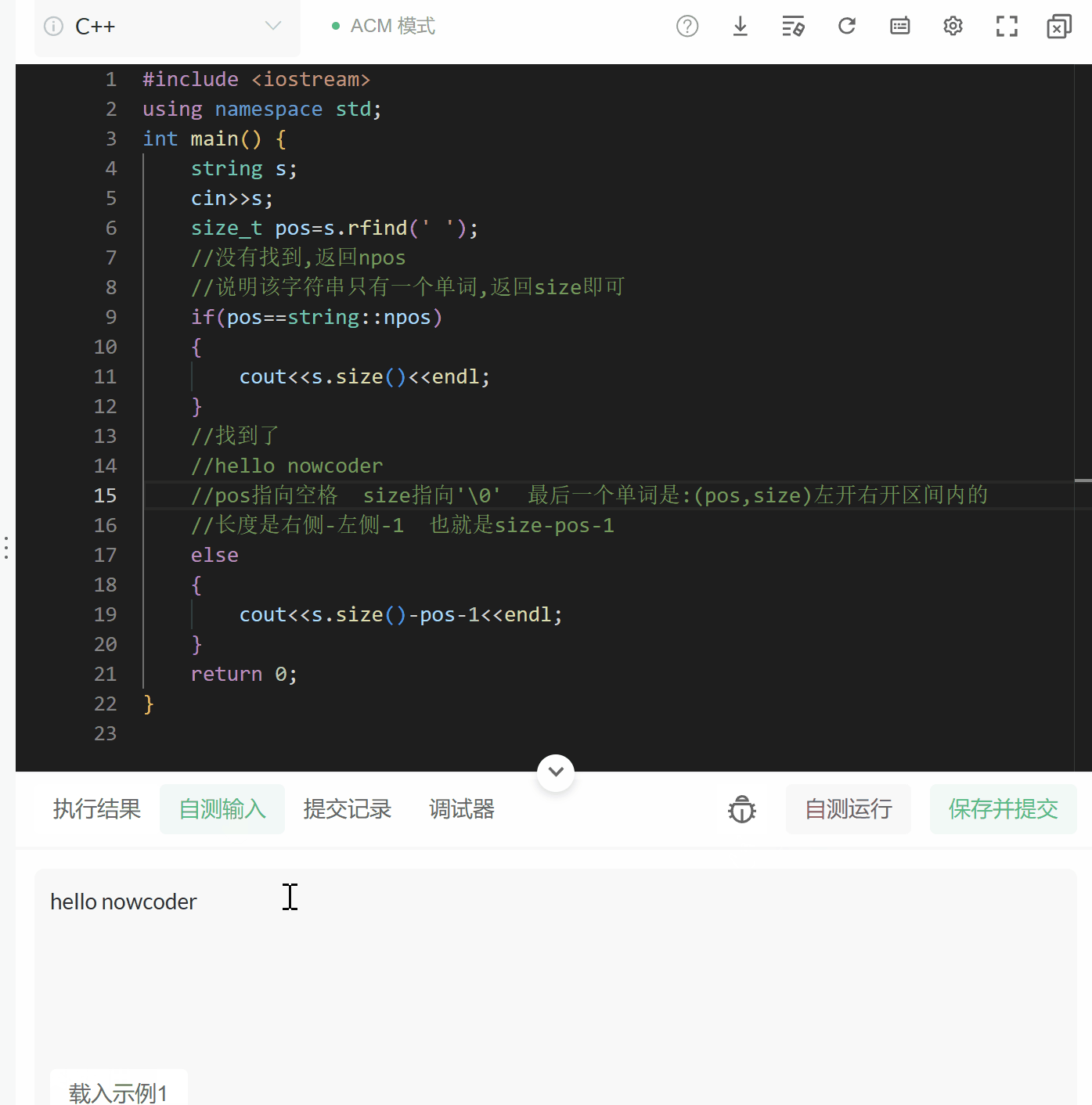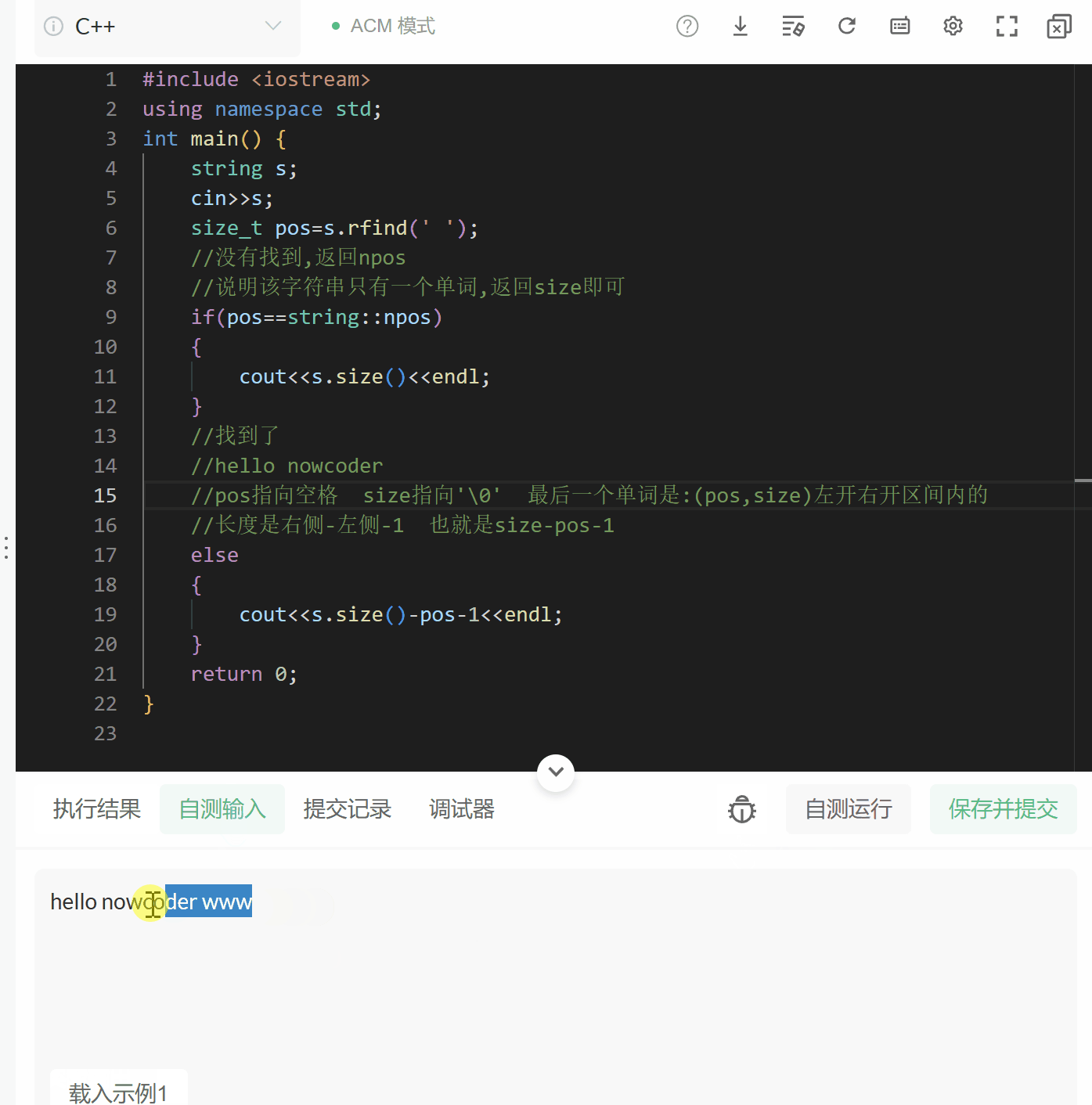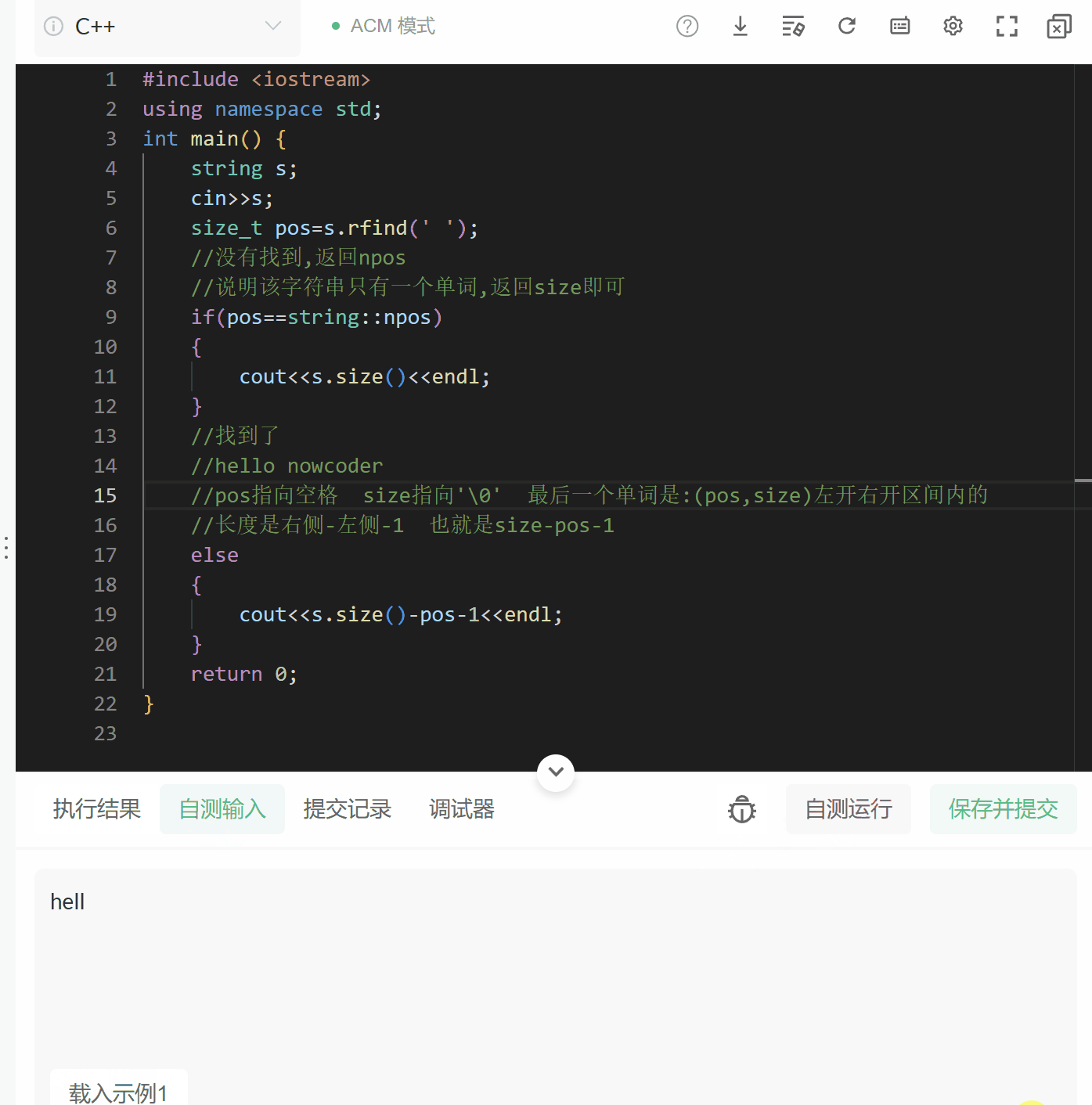
我们发现,我们输出的答案总是第一个单词的长度,为什么呢?
因为:

string s;
getline(cin,s);//getline的用法
#include 
4.<< 和 >>
我们只需要知道可以直接对string容器进行cout和cin即可9.其他不太重要的函数
1.assign

2.copy

三.揭秘string容器的迭代器
1.string容器迭代器的本质
我们完全可以使用一个char*指针去自己实现这个迭代器
也就是这样:typedef char* iterator
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
2.iterator迭代器使用
关于string的模拟实现,我们以后会单独出一篇博客的namespace wzs
{
class string
{
public:
//构造函数
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
//析构函数
~string()
{
delete[]_str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
//迭代器和范围for
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
private:
char* _str;
int _size;
int _capacity;
};
void test()
{
string s2 = "hello iterator";
string::iterator it = s2.begin();
while (it != s2.end())
{
(*it)++;
cout << *it << " ";
it++;
}
cout << endl;
for (auto& e : s2)
{
cout << e << " ";
}
}
}
int main()
{
wzs::test();
return 0;
}
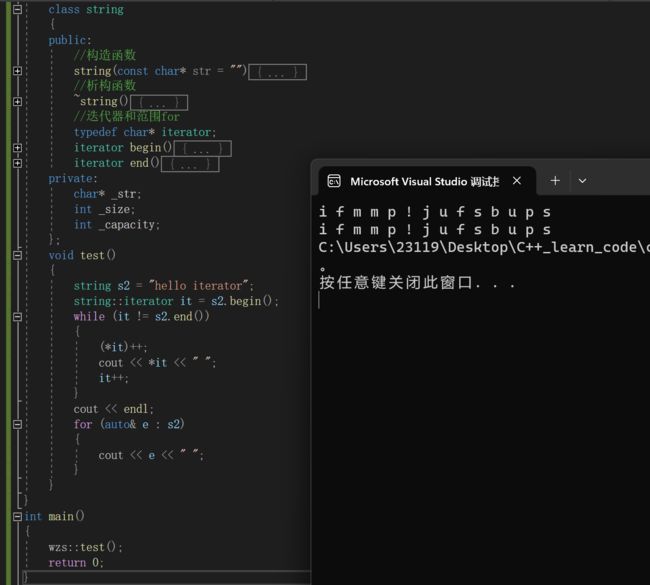
我们仅仅使用我们的这个string类,就可以实现iterator和范围for了3.范围for的本质

我们可以通过查看反汇编看到begin()和end()的身影
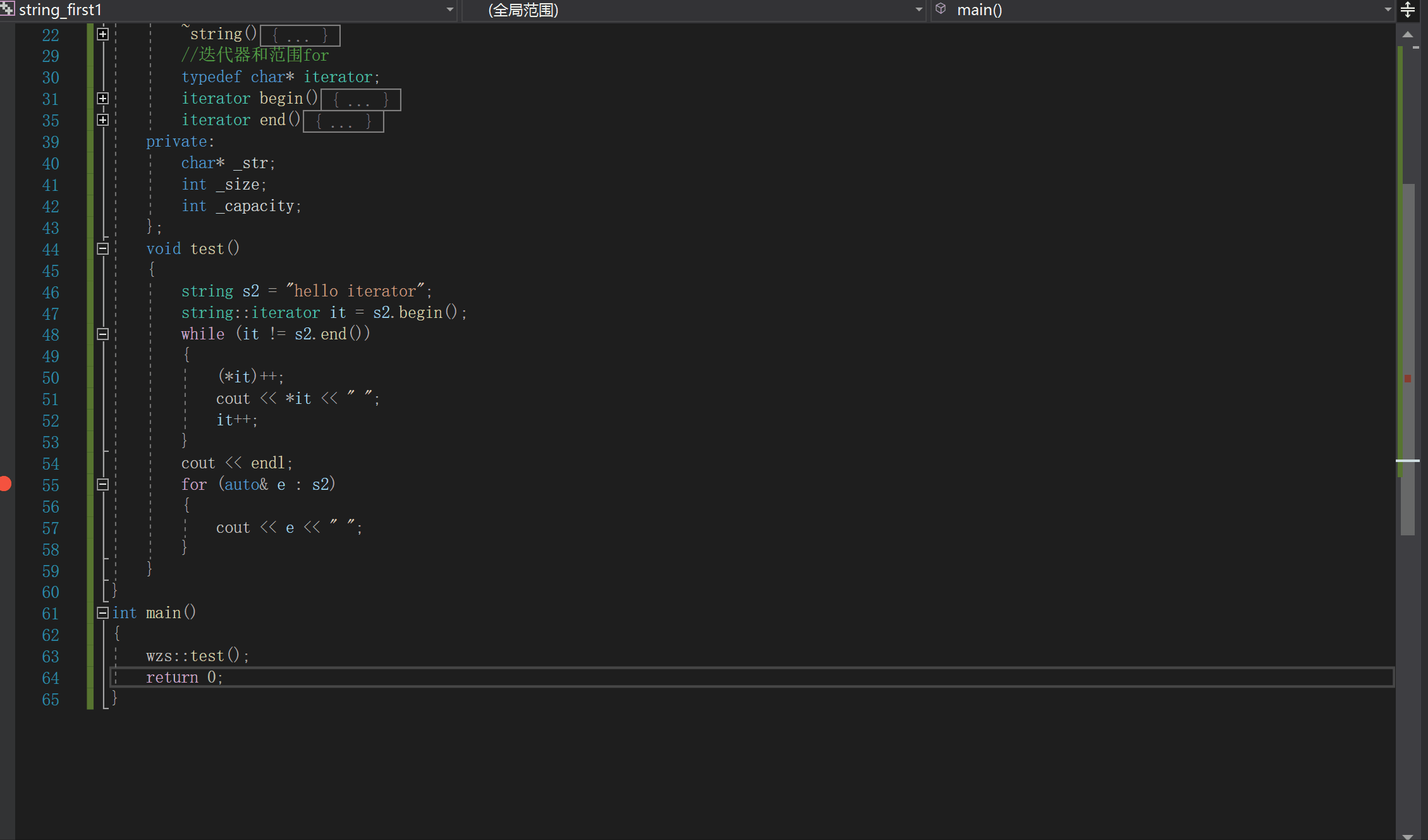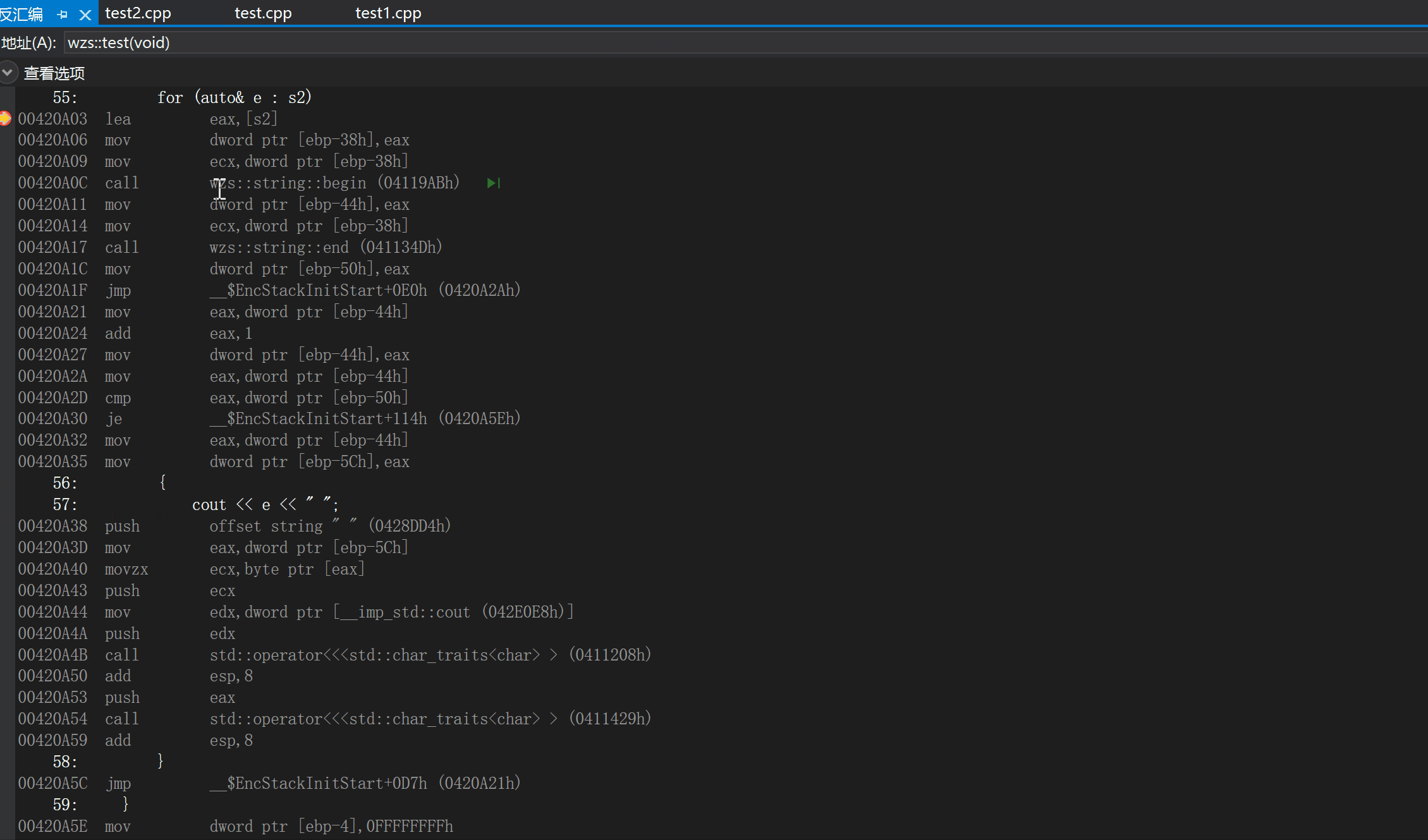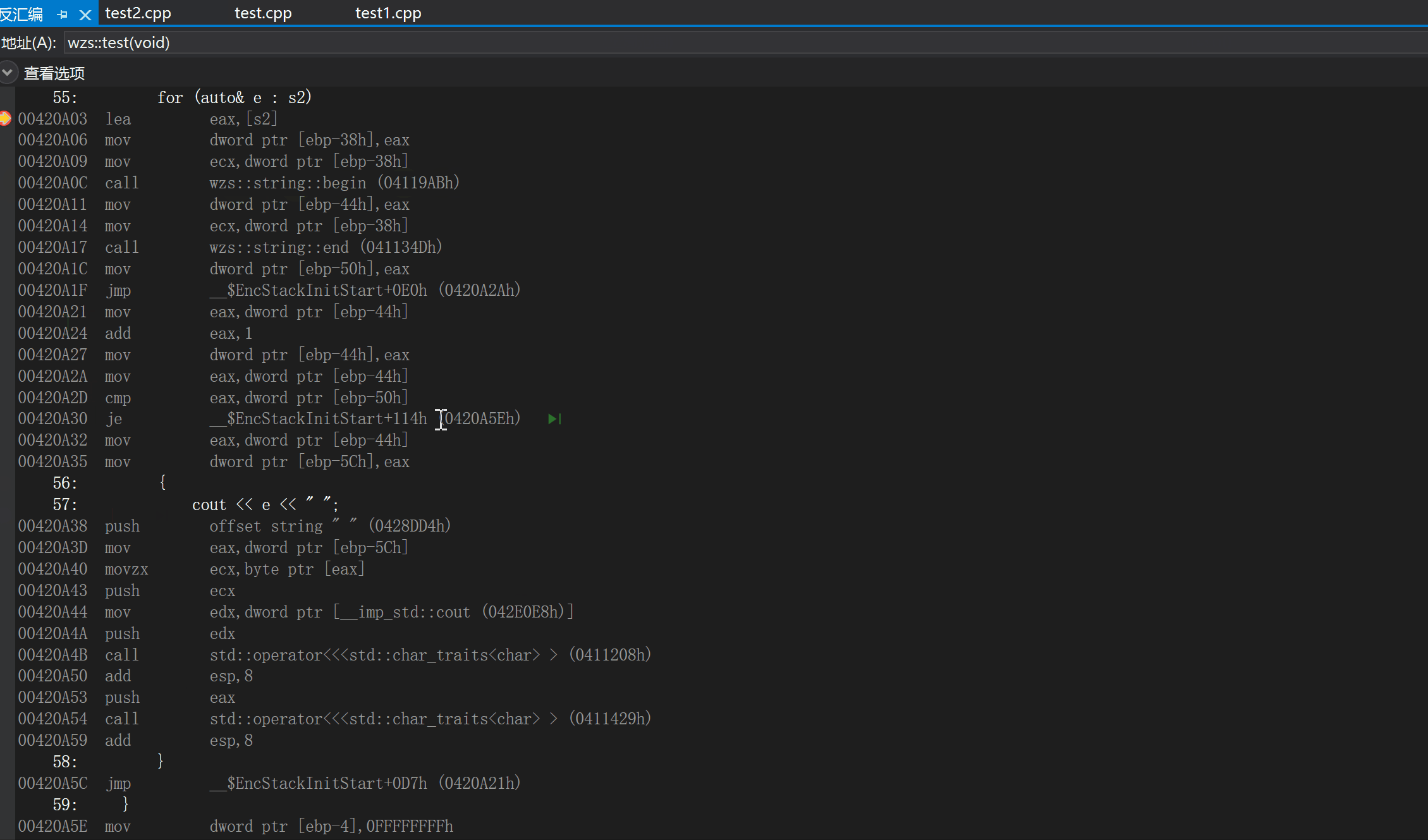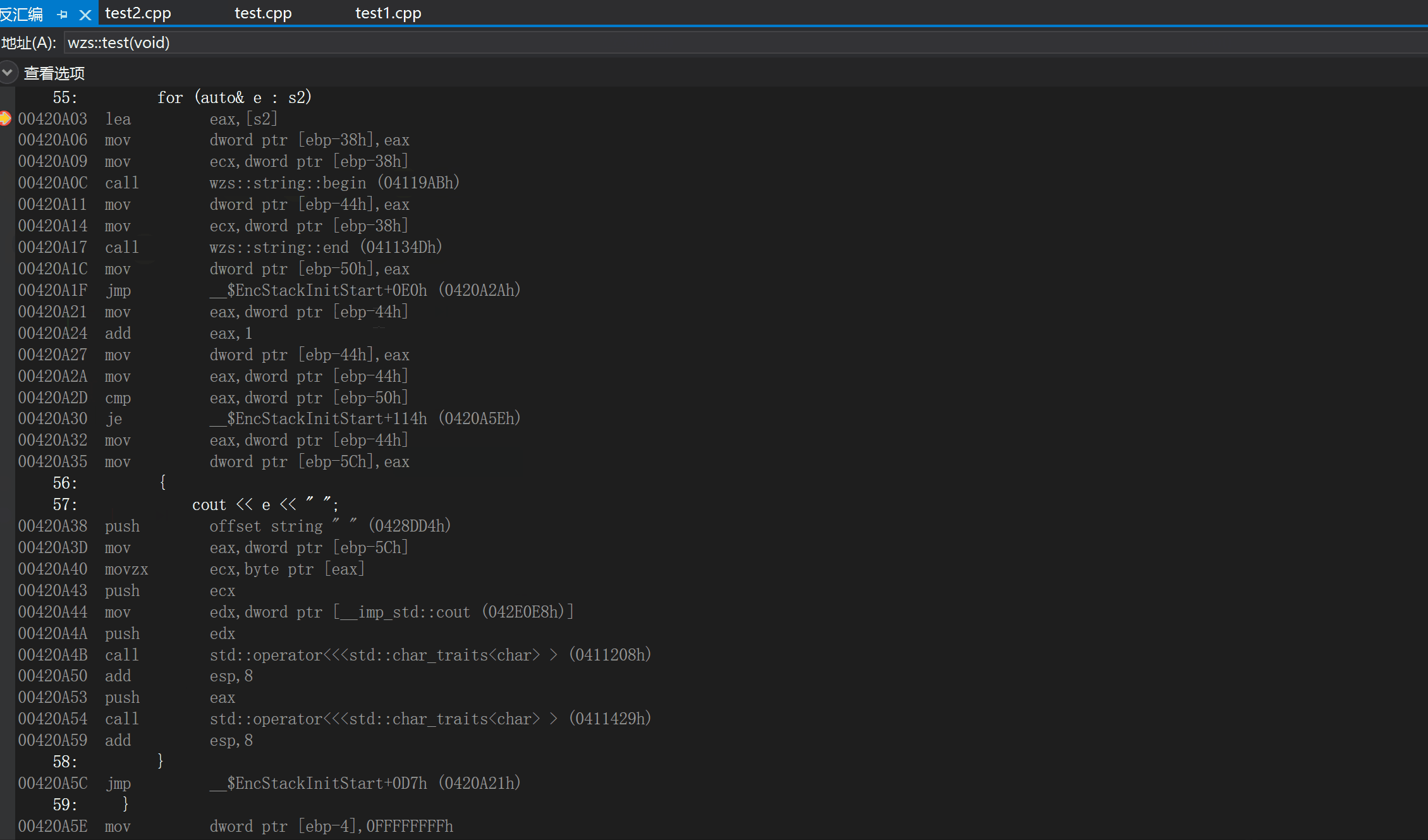
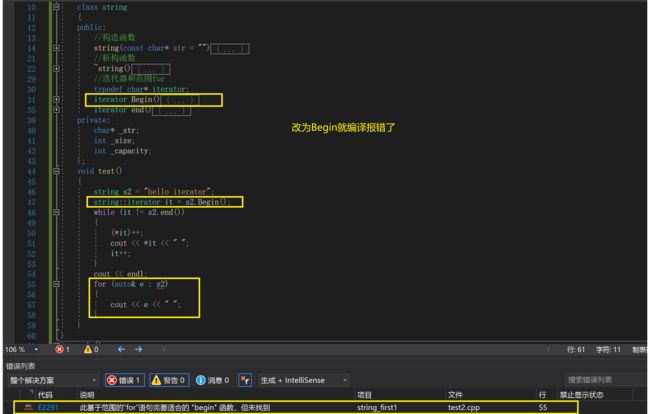
为什么说范围for式"傻瓜式"的替换呢?
因为我们只有当我们遵守迭代器的规范
把迭代器命名为begin(),end()时才会有用
否则就没用了
比如我现在给它改名为Begin
4.iterator的补充
并不是这样的
string容器之所以可以使用char*来当作迭代器是因为string容器在物理空间上是连续的
对于那些物理空间并不连续的容器来说,迭代器就不是这么简单了
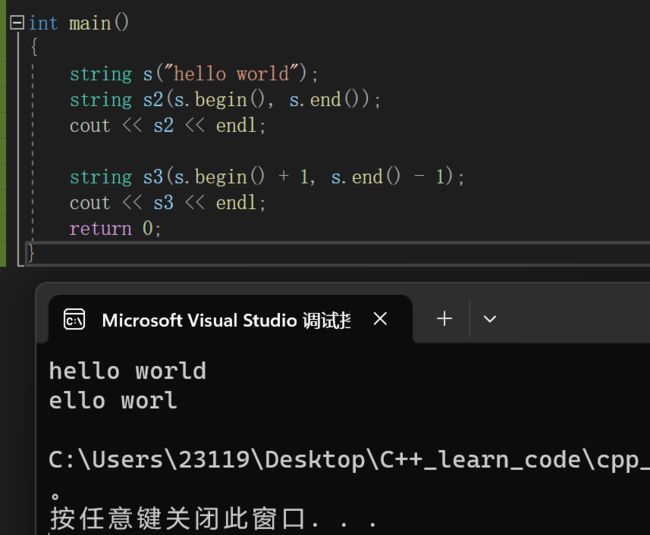
对于那些容器的迭代器我们以后会说明的补充最前面的构造函数的最后一个重载版本

了解了string容器的迭代器之后
我们再来谈一下最后一个构造函数的重载版本
这个其实就是传入迭代器区间进行构造
注意:get_allocator以后会介绍