狂神说Elastic search学习笔记
狂神Elastic search笔记
- 简介
- 安装
-
- es安装
- 安装可视化界面
- 下载kibana
- es核心概念理解
-
- 分片(倒排索引)
- ik分词器插件
-
- 安装
- rest风格操作
- 关于文档的基本操作(重点)
-
- 添加数据
- 获取数据
- 更新数据(如果参数少了会置空)
- 推荐使用POST更新
-
- 匹配查询
- 花式查询详解
-
- 查询指定字段
- 排序
- 分页
- 布尔值查询
- 多条件查询
- 精确查询
- 高亮查询
- springboot整合es
-
- 创建空项目
- 创建新的模块
- api测试
-
- 创建索引
- jd实战
-
- 数据的获取
视频链接:
简介
lucene是一套信息检索工具包!jar包,不包含搜索引擎系统
包含:索引结构,读写索引的工具!排序,搜索规则工具类
lucene和es的关系:
es是基于lucene做的一些封装和增强
es是一个开源的高扩展的分布式的全文检索引擎,它可以近乎实时的存储,检索数据,本身扩展性好,可以扩展到上百台服务器,处理pb(大数据时代)级别的数据,它通过简单的RESTful APi来隐藏lucene的复杂性,从而让全文搜索变得简单。
用于:全文搜索,结构化搜索,分析
es vs solr:

安装
下载地址:找到对应的版本即可
ElasticSearch: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
logstash: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D
es安装
声明:JDK1.8最低要求,es客户端,界面工具
window下学习
ELK解压即用
elastic search版本7.6.1
plugins用于存放插件如ik分词器。

双击bin包下面的elasticsearch.bat文件启动

可能存在闪退问题
解决方案:
在config/elasticsearch.yml添加一条配置:xpack.ml.enabled: false

访问9200端口,成功
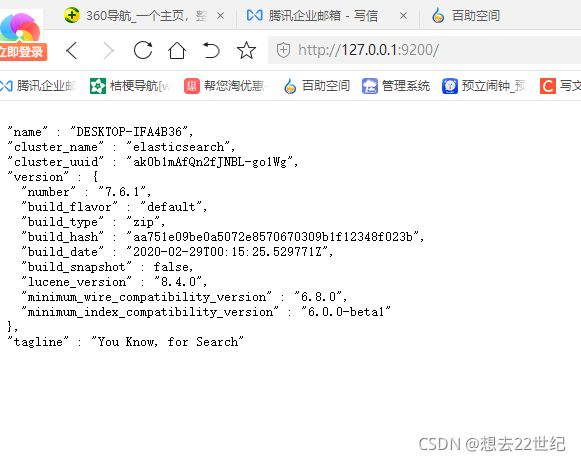
自称集群
安装可视化界面
没有npm,node.js环境不能启动
1.下载地址:https://github.com/mobz/elasticsearch-head
2.npm install

3.启动:npm run start


存在跨域问题

4.修改elasticsearch.yml,跨域配置:
http.cors.enabled: true
http.cors.allow-origin: “*”
重启es服务,连接成功

索引相当于数据库(表:文档)

创建成功

这个head仅把他当作数据展示工具,查询去kibana
下载kibana
解压即用,双击启动

访问测试
未来通过此开发

es核心概念理解
es是面向文档的,一切都是json,和关系型数据库对比
| relationDB | es |
|---|---|
| 数据库 | 索引 |
| 表 | types(慢慢会被弃用) |
| 行 | documents |
| 字段 | fields |
物理设计:
es在后台把每个索引划分为多个分片,每个分片可以在集群中的不同服务器迁移
一个人就是一个集群!默认集群名称:
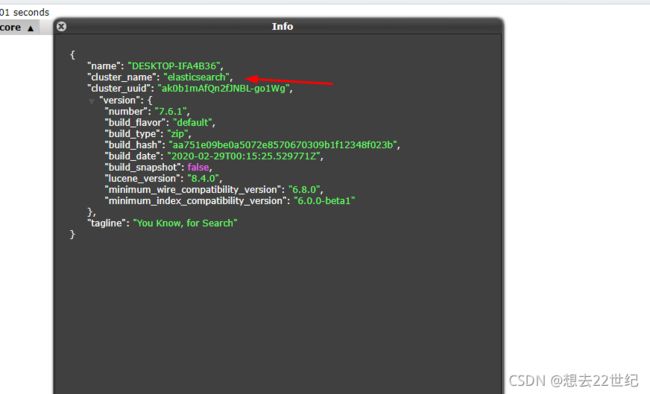
数据库的最小单位是文档,文档有几个重要的属性同时包含key:value
分片(倒排索引)
es使用的是一种倒排索引的结构,采用lucene倒排索引作为底层,这种数据结构适用于快速的全文搜索
。。。。。。
ik分词器插件
如果使用中文,建议使用ik分词器。
ik提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分
安装
1.下载(注意版本对应,7.6.1):https://github.com/medcl/elasticsearch-analysis-ik
2.下载放入es的plugins中
3.重启es观察

4.使用elasticsearch-plugin来查看加载进来的插件

5.使用kibana测试
查看不同分词器的效果




发现问题,狂神说被拆开了,可以自己通过配置文件扩展字典

新建自己的字典


重启es,再次测试

rest风格操作
删除多余的索引库

1.创建索引
put /索引名/类型名/文档id
{请求体}
请求也可以用postman发送
put /test/type1/1
{
“name”:“狂神说”,
“age”:3
}
查看

2.指定字段的类型
创建索引和字段类型。
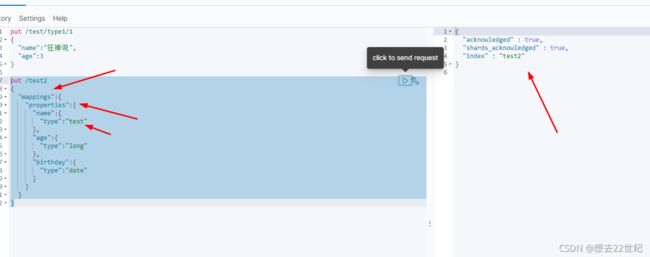
3.get获取信息
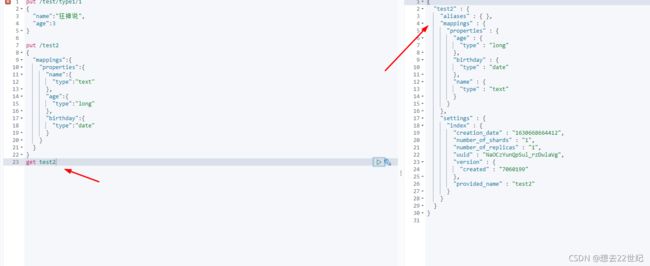
如果文档没有指定类型,es就会给我们配置默认数据类型

扩展:get _cat/indices?v

put,修改的话版本号会改变

post修改


删除索引
delete test1
删除文档
delete test/type1
删除记录
delete test/type1/1
关于文档的基本操作(重点)
添加数据
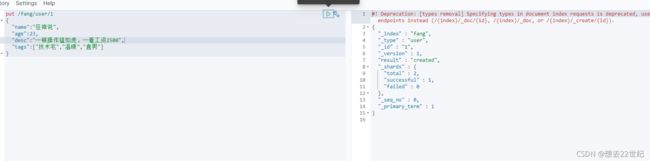
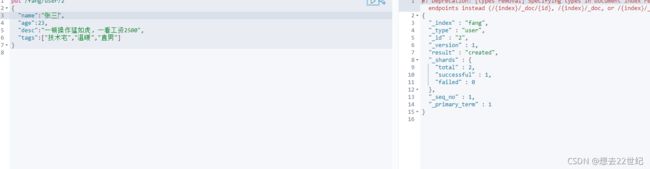

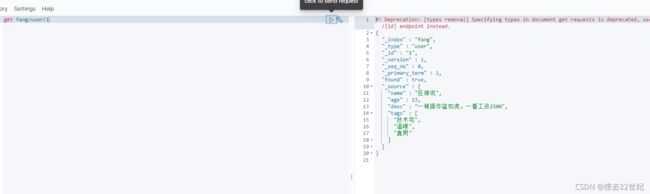
获取数据
更新数据(如果参数少了会置空)
version代表数据被改动的次数

推荐使用POST更新
不加update,其余字段置空


加update,修改指定参数


匹配查询


复杂操作select(排序,分页,高亮,模糊查询,精准查询)
花式查询详解
score代表匹配度,匹配度越高则分值越高

查询的参数是一个json


查询指定字段
我们之后使用java操作es,所有的方法和对象就是这里面的key

排序

分页
get fang/user/_search
{
"query":{
"match": {
"name": "李"
}
},
"sort":[
{
"age":{
"order":"desc"
}
}
],
"from":0,
"size":2
}

布尔值查询
多条件精确查询
must相当于(and),所有条件都要符合
get fang/user/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"name": "李四你发几款"
}
},
{
"match": {
"age": "26"
}
}
]
}
}
}
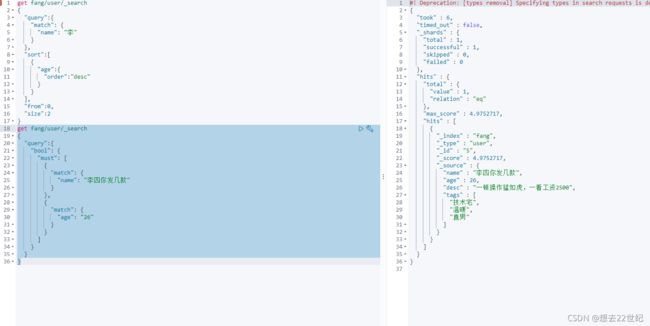
should相当于or(where id=1 or name=xxx)
get fang/user/_search
{
"query":{
"bool": {
"should": [
{
"match": {
"name": "李四你发几款"
}
},
{
"match": {
"age": "26"
}
}
]
}
}
}

mustr_not(not)

过滤器
过滤出小于10的

- gt 大于
- gte 大于等于(e=equal)
- lt 小于
- lte 小于等于
多条件查询
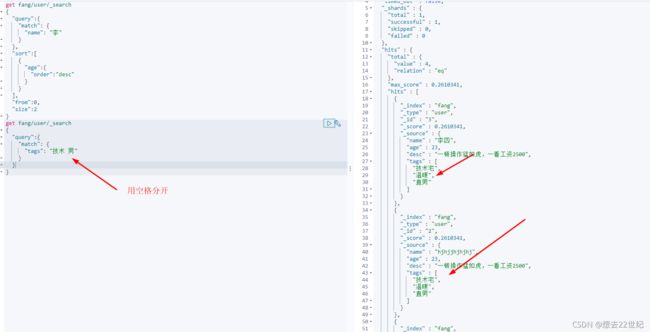
精确查询
term查询是直接通过倒排索引指定的词条进程精确查找的
term:精确查找
match:会使用分词 器解析
text类型会被分词器解析,keyword类型不会被分词器解析
高亮查询
搜索的结果可以被html包裹,也可以自定义标签

springboot整合es
看官方文档
创建空项目


创建新的模块

注意更改目录
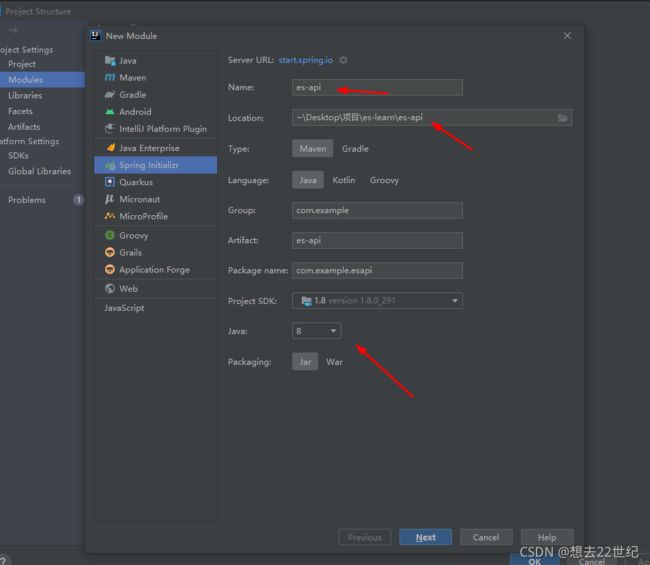

更改环境


javascript版本


一定要确保我们导入的依赖和es的版本一致
默认版本

自定义版本

刷新maven

@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1",9200,"http")
)
);
return client;
}
}
api测试
创建索引
@Test
void contextLoads() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("fang_index");
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}

jd实战
新建模块

改es版本,导包

数据的获取
爬虫,数据库,消息队列
原码:https://gitee.com/fangQingwpb/ElasticSearch-jd