【好书推荐-第30期】开发者请注意!因果推断与机器学习,终于有人能讲明白啦!
本文目录
- 一、因果推断
- 二、因果推断的前世今生
- 三、总结
- 四、赠书条件
今天给各位读者推荐一本好书:《机器学习高级实践:计算广告、供需预测、智能营销、动态定价》,好书链接。
2023年初是人工智能爆发的里程碑式的重要阶段,以OpenAI研发的GPT为代表的大模型大行其道,NLP领域的ChatGPT模型火爆一时,引发了全民热议。而最新更新的GPT-4更是实现了大型多模态模型的飞跃式提升,它能够同时接受图像和文本的输入,并输出正确的文本回复。很多从事人工智能的同行一方面惊叹于GPT-4的优秀表现,另一方面也为自己的职业生涯隐隐担忧。如果说“大算力+强算法”的大模型是人工智能未来发展的趋势,那么传统的机器学习算法在真实的业务场景中还有用吗?会不会早晚被大模型取代?我认为不会。每个业务场景都有其独特性,优秀的算法工程师最难能可贵的地方在于对业务知识的透彻理解和长期沉淀。而业务知识就如同机器学习项目这棵大树的根,理论知识如同大树的多个枝干,算法应用如同枝干上的叶,只有根扎得够深,这棵大树才能够开枝散叶、开花结果。到目前为止,大模型对于瞬息万变、复杂多样的业务形态的理解、思考还达不到人类算法工程师的水平,即使有朝一日能够在大模型的基础上研发出各种不同业务场景的算法应用,也依然需要算法工程师具备强悍的业务能力和扎实的机器学习理论知识,来引导大模型对特定的业务场景进行有效学习。
身处人工智能爆发式增长时代的机器学习从业者无疑是幸运的,人工智能如何更好地融入人类生活的方方面面是这个时代要解决的重要问题。滴滴国际化资深算法工程师王聪颖老师发现,很多新人在入行伊始,往往把高大上的模型理论背得滚瓜烂熟,而在真正应用时却摸不清门路、抓不住重点,导致好钢没用到刀刃上,无法取得实际的业务收益。如果能有一本指导新人从入门到精通、从理论到实践的技术书籍,那该多好,这样不仅省去了企业培养新人的成本,也留给了新人自我学习成长的空间。
本着这个初心,王老师花了将近一年的业余时间来复盘总结了自己以及身边同事从小白成长为独当一面的合格算法工程师的成长历程和项目经验,最终以理论结合实践的方式写入《机器学习高级实践:计算广告、供需预测、智能营销、动态定价》这本书中,希望能通过他的经验,真正地帮助到对机器学习算法感兴趣的读者。
京东购买链接:https://item.jd.com/14256304.html

在本文中,我们截取书中的部分内容,将大家比较关注的机器学习领域新兴分支,因果推断进行简要的介绍。
一、因果推断
因果推断是近年来机器学习领域新兴的一个分支,它主要解决“先有鸡还是先有蛋”的问题。因此,因果推断和关联关系最主要的区别是:因果推断是试图通过变量X的变化推断其对结果Y带来的影响有多少,而关联关系则侧重于表达变量之间的趋势变化,如两个变量图片之间有相关性关系,如果图片随着图片的递增而递增,则说明图片和图片正相关,如果图片随着图片递增而下降,则说明两者负相关。因此因果性(Causality)和相关性(Correlation)有着本质的不同,为了帮助读者更好地理解,这里举个例子:
某研究表明,吃早饭的人比不吃早饭的人体重更轻,因此“专家”得出结论——吃早饭可以减肥。但事实上,吃早饭和体重轻很有可能只是相关性关系,而并非因果关系。吃早饭的人可能是因为三餐规律、经常锻炼、睡眠充足等等一系列健康的生活方式,最终导致了他们的体重更轻。图1所示为因果推断中的混杂因子,描述了健康的生活方式、吃早饭、体重轻三者的关系。
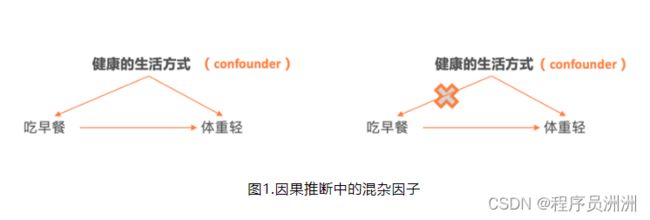
很显然,拥有健康的生活方式的人会吃早餐,健康生活方式同时也会导致体重轻,可见健康的生活方式是吃早餐和体重轻的共同原因。正是因为有这样的共同原因存在,导致我们不能轻易地得出吃早餐和体重轻之间存在因果关系,所以我们认为“专家”的结论是草率的。吃早餐和减肥之间只存在相关性,不存在因果性,并把这种阻断因果关系推断的共同原因称之为混杂因子。那么如图1右所示,消除混杂因子,寻找两个变量之间的因果关系,并量化出来某种自变量X的改变,影响了因变量Y的改变程度是因果推断主要探讨的内容。
二、因果推断的前世今生
纵观因果推断在统计学、机器学习领域的发展史,不得不提及两位大牛人物,一位是在1978年提出大名鼎鼎的RCM(Rubin Causal Model,等同于潜在因果框架)的Donald Rubin,另一位是在1995年提出Causal Diagram框架的Judea Pearl。2021年10月诺贝尔经济学奖颁发给了在因果关系分析有突出贡献的Joshua D.Angrist和Guido W.Imbens,而他们对因果关系的研究就是基于Rubin提出的潜在结果框架,Rubin对因果推断领域的影响可见一斑。Rubin的另一大贡献是提出PSM(Propensity Score Matching)框架解决观测数据存在混杂因子的问题。Pearl提出的Causal Diagram框架则完全脱离了Rubin的RCM框架,使用有向无环图来可视化的表示变量之间的因果关系,并因为提出Causal Diagram的思想做因果推断的研究而在2011年获得图灵奖。两位因果推断领域的大牛人物开创了该领域两种不同的框架,Pearl在2000年证明过两种框架是等价的,而Rubin却不认同他的观点,Rubin认为潜在结果框架能更清晰的表达因果推断问题,目前潜在结果框架相较于因果图而言也是因果推断领域更常用的分析框架,下面将分别介绍两种因果推断框架的分析视角。
(1)潜在结果框架(Potential Outcome Framework)
在介绍潜在结果框架之前,先列出两个需要声明的假设来描述个体因果效应,另外需要注意的是为了更快的帮助大家入门,本文只描述二元处理,即个体只有接受处理和不接受处理两种情况,并对应两种处理方式的结果。

但是在现实世界中,个体图片在同一时刻要么接受处理,要么不接受处理,不可能同时既接受处理又不接受处理,因此个体因果作用是不可识别的,个体的观测数据结果图片
在已知个体因果作用无法识别的情况下,如何进行因果推断呢?或许把因果作用的识别从个体转移到了总体身上是个行之有效的解决方案,于是便有了平均因果作用(ATE, Average Treatment Effect)的概念。平均因果作用不再比较个体的因果作用,而是比较两组群体在不同的处理下的潜在结果,这两组群体除了接受的处理不同之外,必须具有同质的属性,这样计算出的平均因果作用才能无偏,随机对照实验(Random controlled Trial,RCT)是保证两组群里无偏性的基本实验方法。把全量数据随机分为实验组(Treatment Group)和对照组(Control Group),其中实验组的T=1,对照组的T=0,那么平均因果作用的公式如下:ATE=E(Y(1)-Y(0))
其中Y(1)和Y(0)分别是接受处理情况下实验组的结果和不接受处理情况下对照组的结果。至此,潜在结果框架下做因果推断的基本理论知识已经讲解完毕,归纳起来主要有以下两点:
1)随机对照试验保证组别的同质性。
2)从不可评估的个体因果作用转移向评估总体的平均因果效应。
有了随机对照试验就万事大吉了吗?其实不然,设想这样一个问题,想要评估抗癌药物A对于患有癌症的病人的因果作用,这种情景下还适合做随机对照实验吗?答案显然是否定的,首先癌症是重疾,出于人道主义不可能完全随机出来一个对照组人群对其不进行抗癌药物干预,其次即使有奉献主义精神的癌症患者同意参与随机对照实验,在医疗的场景下,实验周期长、费用昂贵也是随机对照实验最大的弊病。通过上面这个实例,我们知道真实生活中并不是所有场景都适合做随机对照实验,于是研究者们设法通过对观测数据进行一系列处理达到随机对照实验的效果,其中最有名的就是Rubin提出的倾向分匹配算法(Propensity Score Matching,PSM)。
(2)结构因果模型(Structual Causal Model,SCM)
结构因果模型是基于图结构来描述两个变量之间的因果关系,因此在介绍SCM之前,先来了解下贝叶斯网络。贝叶斯网络是一种基于有向无环图(Directed Acyclic Graph,DAG)的概率图模型,其自身并不能表示因果关系,它表达的是变量之间的相关关系,但贝叶斯网络的有向无环图是结构因果模型的图结构基础,而贝叶斯网络的概率计算方式也是结构因果模型的推断基础。
有向无环图是由节点和有向边组成的,有向边的上游是父节点,有向边指向的方向是子节点。在DAG中的某个节点的父节点与其非子节点都独立,根据全概率公式和条件独立性,一个有向无环图中的所有节点的联合概率分布可以表达为:

其中图片是所有指向图片的父节点,为了更好地帮助读者理解有向无环图中的联合分布表达,这里给出一个具体的DAG实例,如图2所示。
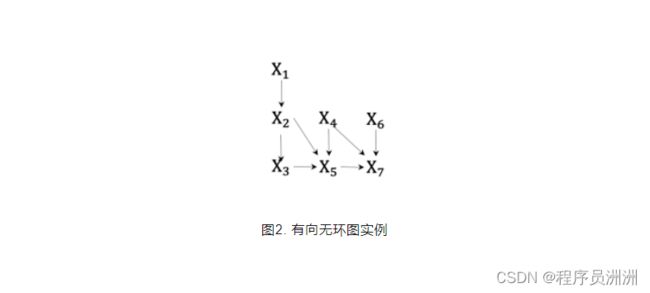
根据有向无环图的条件独立性和联合概率分布的公式,图2的联合分布可以表达为:

每一个有向无环图产出了唯一的联合分布,但是一个联合分布不一定只对应着一个有向无环图,比如P(X1,X2)的联合概率分布有可能是X1->X2,也可能是图结构X2->X1,而两种图结构的因果关系完全相反,这也正是贝叶斯网络不适合做因果模型的原因。为了把DAG改造成可以表达因果关系的因果图,需要引入do算子。这里的do算子就表达的是一种干预,do(Xi)表示将指向节点Xi的有向边全部切除掉,并且节点Xi赋值为常数,在do算子干预后,DAG的联合概率分布有了变化,表达为如下的形式:
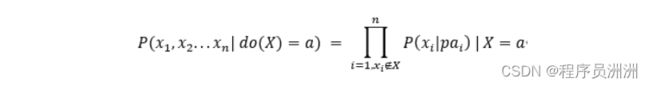
还是以图2为例,假设do算子对节点X3进行了干预,那么干预后的DAG的联合概率分布表达为:
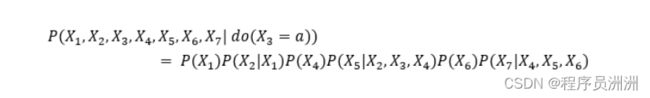
综上所述,加入了do算子的DAG图可以表达因果关系,其平均因果作用公式如下:
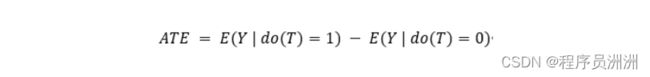
有了do算子的DAG图就有了因果推断的灵魂,但是新的问题来了,并不是所有的实际问题都给出显式的图结构。大部分的真实情况是,既无法得到图结构又无法观测到所有的变量。为了解决上述问题,Pearl提出了后门准则的方法,在介绍后门准则之前,先来看下d-分离的概念。
d-分离的全称是Directional Separation,它是一种判断变量之间是否独立的方法。对于以图结构为主的因果图而言,常见的有三种路径结构如图3所示:

在图3的链式、叉式、反叉式三种路径结构中,反叉式结构中的A、C天然相互独立,B又被称为对撞子,链式或者叉式结构,以B为条件可以阻断A和C之间的关联关系,从而实现A、C相互独立。d-分离就是为了达到变量独立的目的,而对不同的路径结构采取的阻断的操作,具体的d-分离法则归纳起来如下。
1)当某条路径上有两个箭头同时指向某个变量时,那这个变量称之为对撞子,并且这条路径被对撞子阻断。
2)如果某条路径含有非对撞子,那么当以非对撞子为条件时,这条路径可以被阻断。
3)当某条路径以对撞子为条件时,这条路径不仅不会被阻断,反而会被打开。
这里需要注意的是,以某个变量为条件指的是指定某个变量的值,比如以年龄这个变量为条件,就是指定年龄为0或者1。
在了解d-分离法则是可以通过以某个变量为条件进行阻断,从而实现变量间的独立之后,便可以结合后门准则消除混杂因子对未知结构的因果图进行因果推断了。在弄清楚后门准则之前,需要了解后门路径、前门路径的概念。从变量X到变量Y的后门路径就是连接X到Y,但是箭头不从X出发的路径,与之相应的前门路径是连接X到Y且箭头从X出发的路径,后门准则的定义是可以通过d-分离阻断X和Y之间所有的后门路径,那么我们认为可以识别从X到Y之间的因果关系,并把阻断后门路径的因子称之为混杂因子。至此,知道了后门准则的方法无须观测到所有的变量,只需要观测到以哪个变量为条件可以消除后门路径,从而使得X到Y之间的因果关系可识别。
(3)总结
不管是潜在结果框架还是结构因果模型,因果推断主要是从原因X推断结果Y的过程,为了保证原因X和结果Y之间没有混杂因子,一般选择在数据样本充足且实验条件允许的情况下做随机对照实验。当条件不允许做随机对照实验时,通过对观察数据进行处理从而达到消除混杂因子对原因X的影响的目的。

三、总结
除了为广大开发者量身打造的优质内容,这本书还得到了多位专业人士的认可及推荐。

四、赠书条件
京东购买链接:https://item.jd.com/14256304.html
1. 点赞+收藏 文章
2. 评论区留言:我要成为架构师(留言才能进入奖池,每人最多留言三条)
3. 周五晚(2023年12月1号)八点随机抽奖3人
4. 京东购买链接:https://item.jd.com/14256304.html