Java基础16 集合(ArrayList、LinkedList、HashSet,面试阿里露馅被怼了
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity); //复制数据到新数组中
}
Vector集合
Vector集合与ArrayList相似:
-
数据结构都是一维数组
-
方法完全相同
不同点:
-
ArrayList是非线程安全,Vector是线程安全
-
ArrayList性能更高
泛型集合
==================================================================
下面代码可能出现什么问题?
List list = new ArrayList();
list.add(100);
list.add(“123”);
int n = (int)list.get(1); //存在类型转换的错误
String s = (String)list.get(0); //存在类型转换的错误
非泛型的集合,添加数据的类型没有限制,在取出数据进行类型转换时,存在类型不兼容的问题。
使用泛型集合,就能解决这个问题。
创建方法:
ArrayList<类型> arrayList = new ArrayList<类型>();
例如:
ArrayList arrayList = new ArrayList();
ArrayList arrayList = new ArrayList();
后面的类型可以省略
ArrayList arrayList = new ArrayList<>();
优点:
-
只能添加一种类型的数据,不容易出错
-
不用类型转换,提升性能
ArrayList arrList = new ArrayList();
arrList.add(new Person(“张三”,20));
arrList.add(new Person(“张大三”,21));
arrList.add(new Person(“张小三”,23));
arrList.add(new Person(“张三三”,26));
arrList.add(100); //编译错误,不允许添加其他类型
//读取Person对象
Person person = arrList.get(3);
person.hello();
//删除
arrList.remove(0);
//遍历
for(Person per : arrList){
per.hello();
}
LinkedList
LinkedList的数据结构是:
双向链表

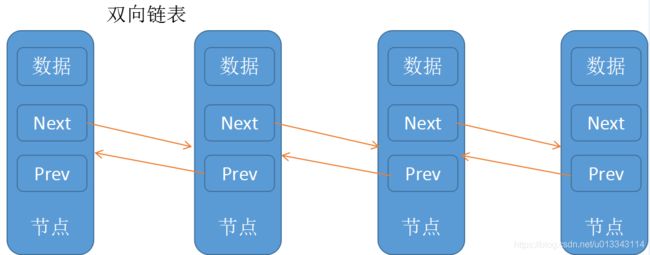
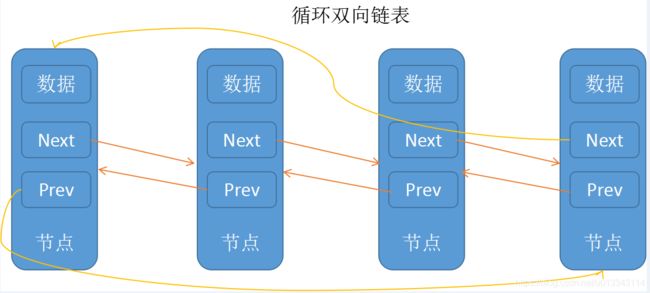
LinkedList的优缺点:
-
优点:删除和插入速度快,只需要修改前后的指向,不需要移动数据
-
缺点:访问速度慢,需要依次向前向后,效率低。
LinkedList的方法
| 方法 | 介绍 |
| — | — |
| void addFirst(Object obj) | 在第一个位置上添加对象 |
| void addLast(Object obj) | 在最后位置上添加对象 |
| Object removeFirst() | 删除第一个位置上的对象 |
| Object removeLast() | 删除最后位置上的对象 |
| Object getFirst() | 获得第一个位置的对象 |
| Object getLast() | 获得最后位置的对象 |
| void push(Object obj) | 入栈,先进后出 |
| Object pop() | 出栈,先进后出 |
LinkedList源码探究
//内部类,保存数据和前后指针
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
插入元素
//在succ节点前,插入新节点
void linkBefore(E e, Node succ) {
final Node pred = succ.prev; //succ前一个节点
//创建新节点,prev指向succ前面节点,next指向succ
final Node newNode = new Node<>(pred, e, succ);
succ.prev = newNode; //succ的prev指向新节点
if (pred == null)
first = newNode; //前面没有节点,新节点就是首节点
else
pred.next = newNode; //否则succ前面节点的next指向新节点
size++; //数量加1
modCount++;
}
插入元素
//删除x节点
E unlink(Node x) {
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
if (prev == null) { //x前面节点的next指向x节点的后面节点
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) { //x后面节点的prev指向x节点的前面节点
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size–;
modCount++;
return element;
}
Set接口
===================================================================
Set不能添加重复的数据,里面的数据也不能单独访问
Set接口的常用实现类有:
-
HashSet 无序的Set
-
TreeSet 会自动排序的Set
-
LinkedHashSet 可以保留添加顺序的Set
HashSet
无序,以哈希算法计算保存位置
添加到集合中的数据必须实现hashCode和equals方法
底层实现是HashMap,数据都是存到HashMap的键中
public class HashSet extends AbstractSet
{
private transient HashMap
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
…
}
Map接口
===================================================================
键值对结构存取数据,查找方便而且高效
常用方法:
| 方法 | 介绍 |
| — | — |
| V put(K key, V value) | 将指定的"键-值"对存入Map中 |
| V get(Object key) | 返回指定键所映射的值 |
| V remove(Object key) | 根据指定的键把此"键-值"对从Map中移除 |
| boolean containsKey(Object key) | 判断此Map是否包含指定键 |
| boolean containsValue(Object value) | 判断此Map是否包含指定值 |
| boolean isEmpty() | 判断此Map中是否有元素 |
| int size() | 获得Map中"键-值"对的数量 |
| void clear() | 清空Map中的所有"键-值"对 |
| Set keySet() | 返回此Map中包含的键的集合 |
| Collection values() | 返回此Map中值的集合 |
HashMap
以哈希表方式存取数据,是使用非常多的集合。
创建方法:
HashMap<键类型,值类型> hashmap = new HashMap<>();
使用方法:
//创建HashMap保存人的对象
HashMap
Person person1 = new Person(“张三”,20);
Person person2 = new Person(“李四”,22);
Person person3 = new Person(“王五”,20);
//添加人到集合中
map.put(person1.getName(), person1);
map.put(person2.getName(), person2);
map.put(person3.getName(), person3);
//通过键访问值
map.get(“张三”).hello();
//删除
map.remove(“李四”);
//添加重复的键,将新的值覆盖原来的值
map.put(“李四”, new Person(“李四”,33));
System.out.println(“长度:” + map.size());
//遍历所有的键
for(String key : map.keySet()){
System.out.println("键: " + key);
}
//遍历所有的值
for(Person per : map.values()){
per.hello();
}
//遍历所有的键和值
for(String key : map.keySet()){
System.out.println("键: " + key);
map.get(key).hello();
}
HashMap的特点
-
如果添加了重复的键,后面添加的值会替换前面的值。
-
数据是用哈希算法计算存储位置,不是添加顺序
-
添加的键必须实现hashCode和equals方法
HashMap的数据结构
一维数组 + 单向链表 + 红黑树
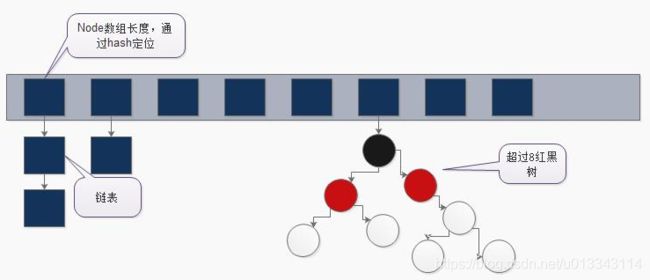
HashMap保存数据的过程
-
添加键值对数据时,首先会调用键的hashCode方法,计算出数组下标
-
如果该下标上的数据为空,就直接存入数据
-
如果该下标上存在数据,就调用键的equals和该位置上的键进行比较
-
如果equals返回true,就用新的数据将旧的数据覆盖掉
-
如果equals返回false,将新的数据放在旧的数据后面,就形成链表
-
当链表的长度超过8,自动转换为红黑树(java8的优化)
HashMap源码解析
//添加数据
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 获得数组长度
if ((p = tab[i = (n - 1) & hash]) == null) //hashCode对数组长度-1取模获得下标i
tab[i] = newNode(hash, key, value, null); //该位置为空就直接添加数据
else {
Node
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) //不为空就调用equals比较键
e = p; //键相同就赋值给e,后面直接覆盖value
else if (p instanceof TreeNode)
e = ((TreeNode
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); //键不相同就放到后面,形成链表
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); //链表长度超过8,转换为红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.eq
【一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义】
浏览器打开:qq.cn.hn/FTf 开源分享
uals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //覆盖旧的value
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Hashtable
Hashtable和HashMap的用法和结构相同
区别:
-
HashMap非线程安全,Hashtable是线程安全的
-
HashMap可以添加null的键和值,Hashtable不能添加null键和值
TreeMap
特点:添加数据后,会自动对键进行排序
数据结构:红黑树

使用时需要注意:
-
键必须实现Comparable接口
-
键如果和已存在的键相等,TreeMap就放弃添加
LinkedHashMap
继承于HashMap,通过额外的链表保留键的添加顺序。

如何选择集合
====================================================================
在开发过程中,需要根据实际业务场景,结合集合的特点选择集合
-
可以排序,可以添加重复数据,可以随机访问 ----- List
-
对数据访问要求高 ----- ArrayList
-
对插入和删除要求高 ----- LinkedList
-
不能添加重复的数据,不需要随机访问 ------ Set
-
没有顺序 ----- HashSet
-
可以进行排序 ----- TreeSet
-
保留添加顺序 ----- LinkedHashSet
-
可以进行快速查找 ,以键值对保存------ Map
-
键没有顺序 ----- HashMap
-
键可以排序 ----- TreeMap
-
键保留添加顺序 ----- LinkedHashMap
结束
================================================================
集合是Java的重点内容,尤其是ArrayList和HashMap这两个集合应用非常广泛,是否掌握了就通过作业检查了。
- 定义歌曲类,属性:歌曲名、歌手名、播放时长(int 类型),定义play方法显示歌曲信息。
1、添加10首歌到ArrayList集合中
2、遍历所有的歌曲,显示歌曲信息
3、输入歌曲名,在集合中查找该歌曲
4、输入整数索引,删除该位置的歌曲
5、找出播放时间最长的歌曲
6、将所有歌曲复制到LinkedList集合中