机器学习库:pandas

☁️主页 Nowl
专栏《机器学习实战》 《机器学习》
君子坐而论道,少年起而行之

文章目录
写在开头
基本数据格式
DataFrame
数据选取
iloc
数据描述
head
describe
数据合并
merge
数据删除
drop
drop删除多列
处理缺失值
查找缺失值
填充缺失值
写在开头

在机器学习中,我们除了关注模型的性能外,数据处理更是必不可少,本文将介绍一个重要的数据处理库pandas,将随着我的学习过程不断增加内容
基本数据格式
pandas提供了两种数据类型:Series和DataFrame,在机器学习中主要使用DataFrame,我们也重点介绍这个
DataFrame
dataframe是一个二维的数据结构,常用来处理表格数据
使用代码
import pandas as pd
a = {"a": [1, 3, 5, 3], "b": [3, 4, 2, 1]}
p = pd.DataFrame(a, index=None)
print(p)
dataframe是一个二维表格,包含行与列的信息
数据选取
iloc
我觉得pandas里面选取数据的一个很通用的方法是iloc
pd.iloc[行序号, 列序号]iloc的参数用逗号隔开,前面是行序号,后面是列序号
import pandas as pd
a = {"a": [1, 3, 5, 3], "b": [3, 4, 2, 1]}
p = pd.DataFrame(a, index=None)
print(p)
print("iloc示例:")
print(p.iloc[0, 0])
print(p.iloc[2, 0])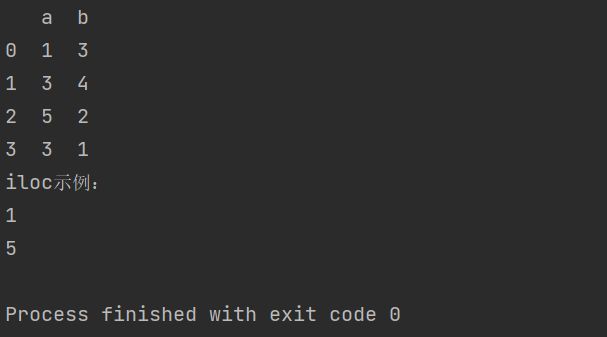
iloc也支持切片操作
import pandas as pd
a = {"a": [1, 3, 5, 3], "b": [3, 4, 2, 1]}
p = pd.DataFrame(a, index=None)
print(p)
print("iloc切片:")
print(p.iloc[0:4, 0])这会打印第一列的0到3行

数据描述
head
head可以查看指定前几行的值,这方便在处理一些大数据集时,我们可以只加载几列来了解数据集而不必加载整个数据集
import pandas as pd
a = {"a": [1, 3, 5, 3], "b": [3, 4, 2, 1]}
p = pd.DataFrame(a, index=None)
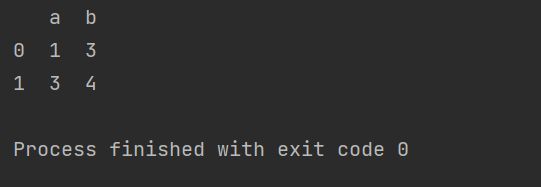
print(p.head(2))我们这里指定显示前2行,不指定默认值是前5行
describe
describe方法可以描述表格所有列的数字特征,中位数,平均值等
import pandas as pd
a = {"a": [1, 3, 5, 3], "b": [3, 4, 2, 1]}
p = pd.DataFrame(a, index=None)
print(p.describe())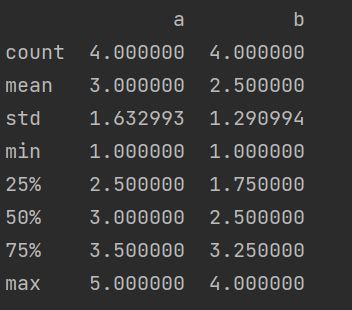
不会处理字符串值哦
数据合并
设想一下,我们有一个员工姓名和工号的表格,我们还有一个员工姓名和性别的表格,我们想把这两个表通过员工姓名合在一起,怎么实现呢
merge
merge函数可以指定以某一列来合并表格
import pandas as pd
# 创建两个示例 DataFrame
df1 = pd.DataFrame({'name': ['A', 'B', 'C', 'D'],
'number': [12335, 23212, 33432, 44678]})
df2 = pd.DataFrame({'name': ['A', 'B', 'C', 'D'],
'sex': ['F', 'F', 'M', 'F']})
# 使用 merge 合并两个 DataFrame
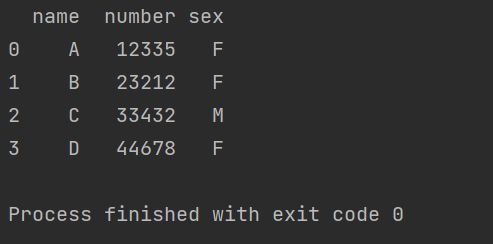
merged_df = pd.merge(df1, df2, on='name')
print(merged_df)on='name'指定函数以name这一列来合并表格
数据删除
在机器学习竞赛时,有时我们想删除一些无用特征,怎么实现删除无用特征的列呢?
drop
以上一节的员工表格为例,增添以下代码
merged_df = merged_df.drop(columns="number")
print(merged_df)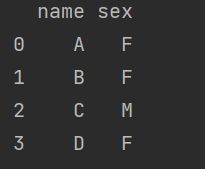
可以看到number列被删除了
drop删除多列
要想删除多列,仅需要将列的名字放在一个列表里
merged_df = merged_df.drop(columns=["number", "sex"])
print(merged_df)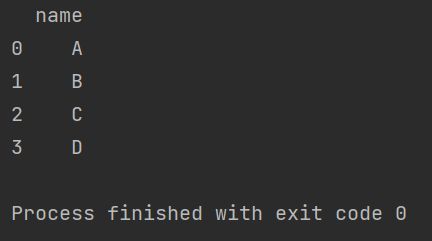
注意:在使用drop时,如果只写df.drop()是没有用的,你必须像上面两个例子一样,将drop后的df表格赋值给原来的表格。
处理缺失值
查找缺失值
isnull可以查找是否有缺失值,配合sum函数可以统计每一列缺失值的数量
import pandas as pd
a = {"a": [1, 3, np.NAN, 3], "b": [3, 4, 2, 1]}
p = pd.DataFrame(a, index=None)
print(p.isnull().sum())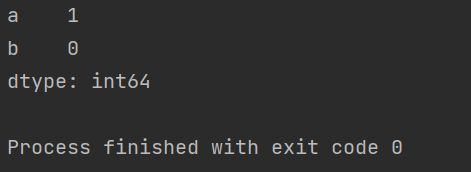
填充缺失值
因为有些机器学习模型无法处理缺失值,我们必须将缺失值补充好,可以用0填充,也可以用平均值填充,代码如下
# 0填充
print(p.fillna(0))
# 平均值填充
print(p.fillna(p["a"].mean()))