java集合
Collection接口
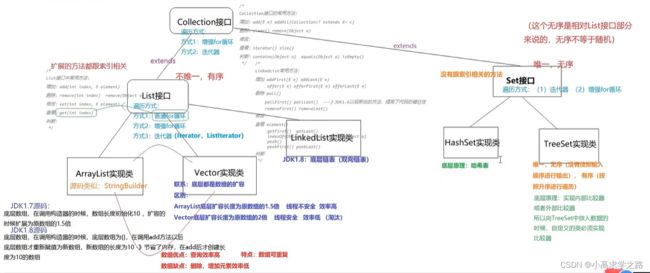
List(有序)
ArrayList(线程不安全)
分为JDK1.7和1.8版本:底层的实现如下:
- JDK1.7源码:
- 底层是数组,在调用空构造器的时候.空构造器又调用有参构造器,并且默认数组是Object [] elementData的初始值为10的数组,扩容的时候扩容为原来的1.5倍(原来的数组长度+原来的数组长度>>1)
- JDK1.8源码:
- 底层是数组,在调用构造器的时候,初始值数组Object [] elementData{},数组为空,长度为0,只有在调用add()方法的时候,才会进行扩容,扩容机制创建一个数组长度为10的新数组,然后返回该新的数组.扩容的时候扩容为也是原来的1.5倍
这样做的好处就是:有可能我创建完数组后,暂时没有存放数据,对于JDK1.7来说刚开始的数组长度就是10, 对于1.8来说,刚开始的数组长度就是0,这样就节省了内存空间
以JDK1.8的add()方法为例:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}在增加的时候,首先会判断该数组是不是需要扩容
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}Vector(线程安全)
底层也是Object [] elementData 数组,初始值是10,扩容机制是扩容成原来的2倍.并且add()方法上相对应ArrayList数组有synchronized 修饰,所以为线程安全,但是因为效率太低了,被淘汰!
iterator
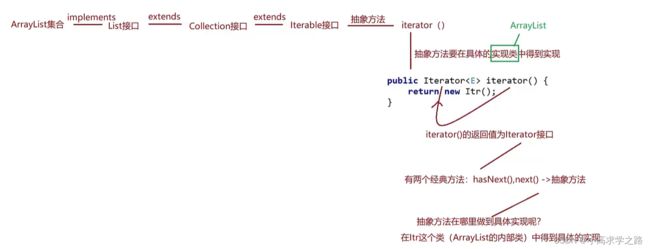
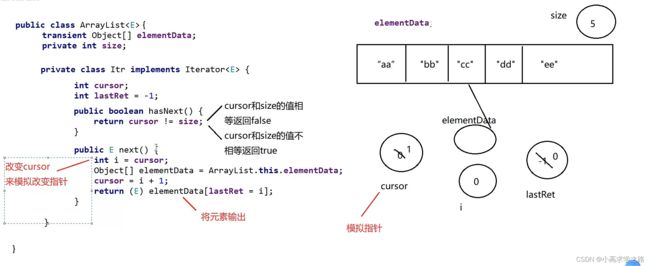
迭代器实现原理:属于ArrayList内部类,然后创建一个类似指针光标的东西,去执行下标移动,具体实现如下图:(增强for循环也是走到iterator里面来进行输出元素的)
LinkedList
1.7和1.8源码一样,底层用链表实现,其中一个节点Node,里面主要存在3种属,prev:前一个元素的地址,item代表传入的值,next代表下一个元素的地址
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 源码add()为例:
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
} LinkedList在get(int index)时候,因为是链表结构,不是连续的存储空间,所以需要从第一个元素开始找下一个元素的地址,以此类推,直到找到目标元素在输出.该过程特别耗时,但在源码中,逻辑是首先判断查找的元素索引,判断是否处于该链表位置的前半段还是后半段,这样的话,可以减少一些不必要的查询
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} Set(无序)
hashSet
底层其实就是创建了一个hashMap();只不过是key值不一样,value都是一个新的Object对象.

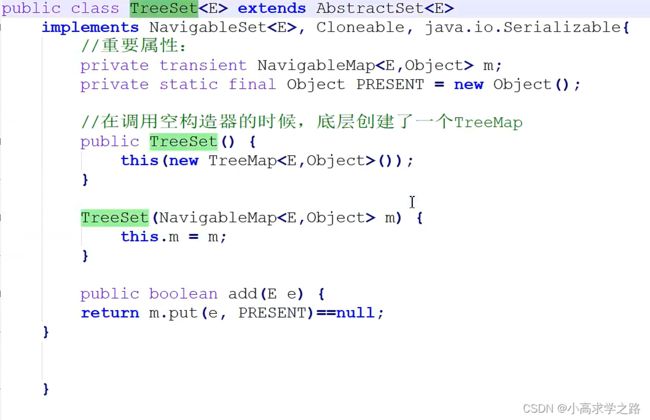
TreeSet
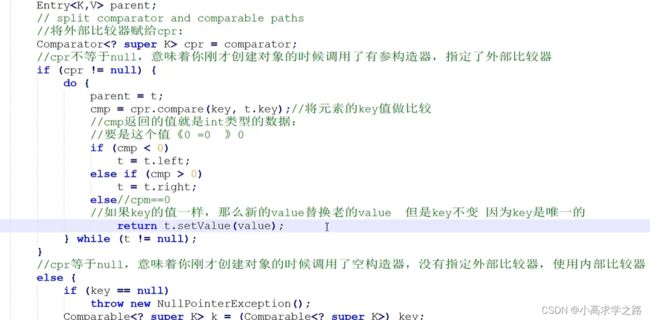
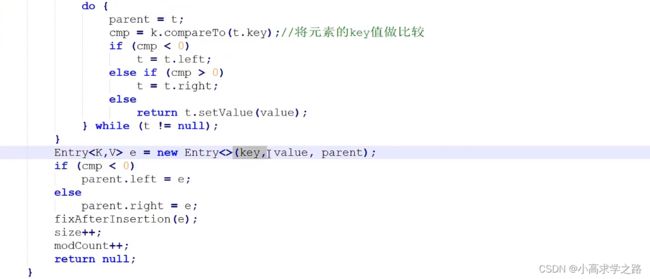
(无序,唯一)底层是通过内部比较器或者外部比较器来实现对元素的添加,如果是自定义的类则必须实现构造器. 底层原理就是创建TreeMap来实现,同样和hashSet一样,放入的只是key不同,value都是同一个的对象
核心源码如下:
Map
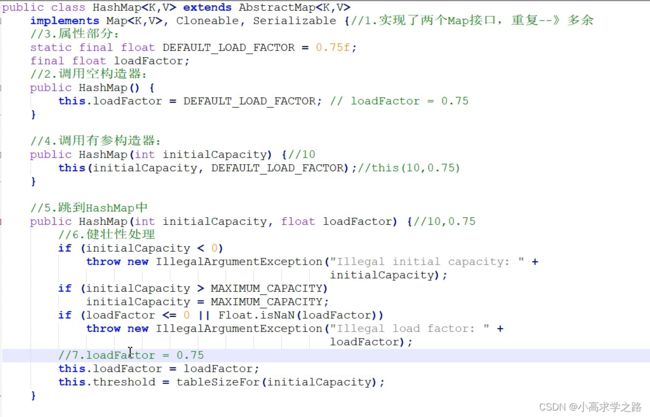
HashMap
JDK1.7
头插法 (数组+链表),数组中放的是Entry对象(哈希值,key,value,下一个元素的地址)
数组默认长度是16,扩容因子是0.75,所以16*0.75=12,当数组长度大于12的时候,数组就开始扩容了,并且扩容的大小是2的n次方,也就是扩容为原来的2倍

JDK1.8
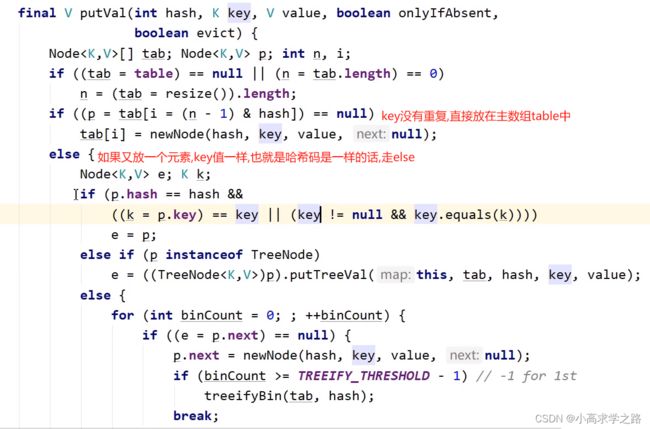
默认主数组长度默认为16,扩容因子为0.75
在执行put的时候,会将key的hash值,进行该公式:(n-1)&hash,得到的数,就是主数组table里面的索引值,(其中n代表数组的长度)
尾插法. (数组+链表(红黑树)),数组扩容的条件是,当数组的长度大于64,并且数组中的链表长度大于8的时候,才会转为红黑树
核心源码如下:
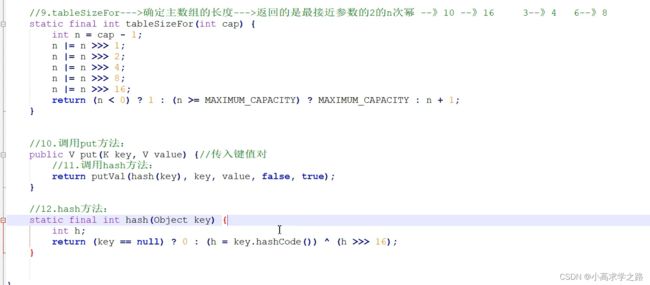
putVal:
红黑树树化代码:

面试必问
1.为啥扩容因子是0.75:
1.如果扩容因子设置为1的话,,刚开始的数组默认的长度是16也就是当数组长度达到了16,当装满后,数组才会进行扩容,这样的话虽然在空间上得到了充分的利用,但是在填入的时候,哈希碰撞的概率会增大,导致数组中某一个位置,产生了链表,导致查询效率低
2.如果扩容因子设置为0.5的话,刚开始的数组默认的长度是16,16*0.5=8,也就是说,当数组长度大于8的时候,数组就会进行扩容,虽然这样哈希碰撞的概率会变少,产生链表的概率低,提高了查询的速率,但是牺牲了空间,空间利用率很低
所以1和0.5折中,取中间值
2.为啥主数组的长度必须是2的整数倍呢?
因为底层源码有个算下标方法是 (n-1)&hash ,只有当为2^n的时候,减少哈希碰撞,位置冲突


TreeMap

底层原理:当放入第一个节点Entry的时候,这个元素就是根元素,当放入第二个元素的时候,里面有个判断,看你是用的外部比较器还是内部比较器.然后判断逻辑都是一样的,用的是do while循环,来比较.如果放入的key是一样的,则更新的一下最新的value值,然后根据key的比较,看是放在根元素的左边还是右边