LINUX入门篇【9】----进程篇【1】----进程的初步认识和理解---进程的标识符以及对应的系统调用函数
前言:
从而本章开始,我们将进行进程的正式学习和讲解,进程是我们的程序驱动最重要的一环,可以说,进程几乎承载着一个程序在冯诺依曼体系和操作系统交互的全部,因此,学好进程是我们下一步系统化编程的基础。
1.何为进程:
我们首先知道,我们所写的代码通过编译是写在我们对应的可执行文件中的,既然是文件,就对应的被写在磁盘里,当我们去运行程序的时候,早已经启动的操作系统会将代码和数据拷贝到内存中,然后由操作系统去管理这些运行起来的代码和数据。既然谈到管理,我们就要说我们上一篇文章提到的“先描述再组织”的管理模式,也就是说,操作系统需要先描述好每一段传入内存的程序和代码。就像我们之前写过的贪吃蛇,扫雷一样,利用结构体去描述再好不过,OS的底层是C语言,所以OS也就使用了一个结构体来对进程的各种属性进行描述和控制,也就是说,操作系统管理的并不是具体的代码和数据,而是进程的属性数据。通过这些属性,来管理进程,我们把进程对应的这个结构体叫做进程控制块–process control block,简称PCB。利用PCB,就可以做到控制对应的代码和数据。
如下图:

如上图,我们会发现,OS操作系统管理的本质上就是双向链表而非代码数据本身,进程的销毁和增加就是对PCB的增删查改,然后CPU由PCB的对应的成员变量提供的代码地址再去访问里面的数据和代码从而对程序进行执行。
而所谓的进程排队,即是创建一个队列,在这里就是一个双向链表,将对应的PCB链接起来进入队列,即为进程排队。
我们由此总结,何为进程呢?
进程=可执行程序和数据+内核的PCB数据结构,而这个PCB则是便于OS对进程进行管理
进程和程序的区别:
1.程序是在磁盘上的,而进程是在内存中的,由磁盘拷贝过来的程序进入到内存中,用对应的PCB管理起来,这个PCB加对应的代码和数据合一起叫进程
2.进程比程序多了PCB来控制
3.进程是动态的,可以运行也可以停止,而程序是静态的,只要开始跑就一直跑,知道程序结束为止。
进程的动态主要体现在后面的进程状态那里,之后我们会介绍进程状态,进程的多种不同状态导致了进程是动态的,不是一成不变的。
2.PCB队列原理:
可以说,在进程中PCB就是绝对的核心和大脑,控制着对应的整个程序的执行,因此,一个PCB往往要承载着众多的成员来对各种进程的状态和数据进行详细的记录。
与一般的链表不同,在LINUX中,我们的task_struct包含着前后两个指针变量,但极端的是,我们的next指针指向的并不是下一个结构体,而是下一个结构体的next指针,而prev也是同理,这种存储方式与正常的链表的节点不同。因此,我们想要找到对应的节点的地址,就需要利用偏移量来寻找,如下图:
struct dlist//专门用来存储next坐标的结构体,在我们的PCB内部
{
struct dlist*next;
struct dlist*prev;
}
struct task_struct
{
//进程的各种属性
struct dlist list;

如上图,由于结构体的next指针指向的是下一个节点的next指针,故我们想找具体的节点的地址要通过偏移量
(tash_struct)((int)&list-(int)&(task_struct)0->list)**
同时我们要记住:
不要认为PCB只能出现在一张链表里,PCB可能同时出现在多张链表里
例如:
struct task_struct
{
dlist list;//系统所有软件进程所在队列
dlist queue;//同时这个进程还在硬件队列中等待
}
这也是为什么我们的链表的指针指向不是对应的下一个节点而是下一个节点的指针的原因,因为倘若为下一个节点,它就没法存在在多个链表中,也就没法实现动态化了。
PCB内部的成员介绍:
介绍完了整体的进程概念,下面让我们来认真学习一下PCB的内部的成员都记录了一个进程的哪些相关属性呢?
常见的属性如下:
struct PCB
{
//id
//代码地址&&数据地址
//状态
//优先级
//链接字段
struct PCB* next//即指向下一个PCB进程的指针,指向下一个next
}
我将依次解析这里面的每一个成员。
1. 标识符id:
标识符id,是识别一个进程最关键的一个成员,我们的每一个进程不是通过名字来区分的,而是通过对应的标识符id来区分的,标识符id就是进程的“名字“
进程分类:
常见的标识符id有两种:
1.pid:即当前进程的标识符
2.ppid:当前进程的上一级进程的标识符,你可以理解为父进程的id
在LINUX系统中,我们的所有指令,软件,自己的程序,他们运行起来后都是进程。
进程查看:
我们查看进程的命令:ps axj这个是查看系统中所有进程的命令,我们可以配合grep进行过滤,比如:
![]()
这样,就不会把全部的进程全显示出来我们可以更好的监控我们想看到的进程。
让我们再把我们对应的第一行列标识打出来:
![]()
从上面的图片中我们看到,它的父进程为2559,子进程为6870,那么,为什么一个进程有父进程也有子进程呢?
让我们再试几次反复去执行代码:

利用脚本监视器,我们发现我们每次的PID都不相同,而对应的PPID却都是相同的?
首先,我们查找mybin的脚本程序一直在执行,并且每隔一段时间执行一次,也就是每隔一段时间进程就被启动一次,因此每次都在重新启动进程,这导致每次的进程pid都不相同,但是,我们要清楚一个结论是:
子进程是由父进程创建的,因此,我们的父进程一直不变,但是每次父进程创建的子进程,给子进程的pid都是随机的,这也就是为什么我们每次看到的子进程的pid不同,但是父进程ppid都相同的原因。
如果我们去查看父进程对应的进程信息,我们会看到如下:
![]()
没错,它对应的父进程就是bash.也就是我们之前说过的命令行就是它的父进程。
关闭进程:
进程是可以被杀死的,包括子进程和父进程,父进程一旦被杀死,则输入的任何指令都会编程乱码,子进程被杀死就是直接结束,其指令为:
kill -9 +对应的进程pid:我们这里是使用了kill的9号信号,即中止一个进程的信号,其他详细的信号,你可以用 kill -l查询,如下:

![]()
你可以发现,原本运行的子进程,被我杀死后便结束了,只有父进程在执行。

这里便是全部的kill对应的信号编码,我们可以根据编码为进程进行对应的处理。
关于获取pid,ppid的系统调用编码:
我们常见的获取pid,ppid的编码有两种:
1.利用ps axj来获取
2.利用系统调用函数
第一种我们已经说过,接下来我将讲一讲函数调用:
我们经常使用的系统调用获取pid ppid的函数对应位getpid() getppid(),其对应的头文件为两个:
《sys/types.h》《unistd.h》
关于getpid 和getppid他们的返回格式是相同的,只不过一个返回子进程,一个返回父进程而已,我以其中一个getpid为例来说:

利用man指令,我们就可以查到他们对应的函数信息,我们发现,它们返回的是一个pid_t类型的数据,实际上就是一个正整数,但我们接收时最好用pid_t来接收。我们用来接收的整型就是我们对应的进程的pid或者ppid.
拓展:
我们查看进程不仅仅可以使用[ps axj,也可以使用ls /proc/来查看进程目录。
在LINUX中,有一个动态的目录结构,用来存放所有存在的进程,而目录的名称,就是以这个进程的id来命名的

如上图,这里就是我们对应的进程的/proc/目录。因此,让我们打开我们对应的进程目录:

在这里,我们看到了两个重要的东西:
第一个是可执行程序exe,在它后面会有对应的文件所在的位置,故我们说进程是可以找到自己的可执行程序的
第二个事cwd:cwd就代表可执行程序所处的当前目录,它正好比exe前面一个路径,故结合我们之前学到的文件操作,文件操作下,当前目录中,为什么叫做当前目录呢?这里所说的当前目录,就是指我们的当前的工作目录cwd,这里更多体现的是进程的概念。
默认情况下,进程启动所处的路径,就是当前路径,但是我们也可以修改我们的默认路径,使用函数chdir即可,即可将我们的文件的工作路径进行修改。
函数chdir对应的头文件为《uistd.h》

根据函数的参数类型,我们知道我们要传入的是一个新的要修改的路径,这样就可以修改我们对应的默认目录不是当前目录。
由此,我们得出的结论是:
每一个进程,都要有自己的工作目录。
用函数fork()来创建进程:
我们创建进程的方式有两种:
1.在命令行让一个程序执行,创建一个进程
2.利用系统调用函数来创建一个进程
而我们所谓的创建一个进程,实际上就是将对应的代码和数据拷贝到我们的内存中,然后创建一个对应的PCB来管理它。第一种利用命令行创建进程的我不再多说,下面让我们来探究一下如何用系统调用函数来创建一个进程。
在这里我们引进一个新的系统调用的函数:fork()
其基本的用法如下:

也就是说它是无参数的,也会返回一个pdi_t的类型的返回值,我们需要用一个pid_t去接收。头文件为《usistd.h》
那么,它是如何创建一个进程的呢?
本质上就是系统多了一个进程,OS要管理的进程多一个,进程=可执行程序+task_struct(也就是PCB,但在LINUX中我们一般叫task_struct),对象(内核对象),创建一个进程,向系统中申请内存,保存当前父进程的可执行程序+task_struct对象,并将子进程PCB对象添加到对应的进程链表中。
故通过fork我们就可以创建一个基于当前进程的子进程,故我们大致猜测,bash源代码中创建子进程应该也是用的这个。
故我们写下一个对应的程序,来进一步我们的研究:

结果如下:

这是我截取到的一段运行结果,你会发现,fork之后父子进程是一起运行的,但是fork之前只有父进程运行,这个很好理解,毕竟新增加一个进程,对应的两个进程一起运行是没毛病的。
但是,最大的问题在于,fork的返回值会同时让两个if判断语句一起执行,也就是说fork有两个返回值,为何我只用一个变量接收却有两个不同的结果,父子进程的运行先后是什么?为什么子进程的返回值是0,而父进程是子进程的pid?
不要着急,首先1.我们先搞清楚我们为何要创建子进程,难道我们创建子进程是为了让子进程和父进程做一样的事情么?
我们当然不可能让我们的子进程和父进程做一样的事情,一般我们都是让子进程协助父进程完成一些工作,让子进程和父进程做不一样的事情,让他们执行不一样的代码,就像上面我写的那个代码一样,这些工作是单进程无法解决的。
比如,我同时打开CSGO和LOL,然后打开浏览器查找攻略,这里有三个进程同时工作,就有运用到子进程协助的使用场景。
2.那么我们是如何保证的呢?
根据fork函数的特点,它的返回值正如我们上面的疑问可知,是有两个的,一个是子进程的返回值0,一个是父进程的返回值,即子进程的pid。根据这个特点,我们就可以根据返回值判断谁是子谁是父,然后让他们执行对应的代码片段,如我上面的代码所示。
fork()创建进程的原理:
fork的工作原理,其实就是刚才我说的那几个问题,我们只要弄清楚那几个问题,其实也就掌握了fork函数的原理,故接下来让我们一个一个解答。
首先是第一个问题:fork()函数都做了哪些事情?
我们可以将其解析为一下几步:
1.以父进程为模板,为子进程创建PCB,其中PCB的大部分数据和父进程相同,但少部分数据比如pid都是和父进程不同的,可以理解为自己独有的数据内容
2.我们创建的子进程是没有对应的代码和数据的!!!故,它目前会与父进程共享父进程的代码和数据,这也是为什么fork之后父子进程执行同样的代码和判断条件分别执行的原因。
而子进程是可以看到父进程的全部代码的,那么这里又有一个问题了,为什么子进程不从头执行代码呢?
这是由于PCB继承了父进程的大部分,当然也包括对应的寄存器pc/eip,pc/eip是用来保存当前指令的下一个指令的地址的,故pc/eip执行fork后,eip指向的fork的后续的代码的地址也会被子进程复制继承,故子进程会从fork之后执行。
如下图:
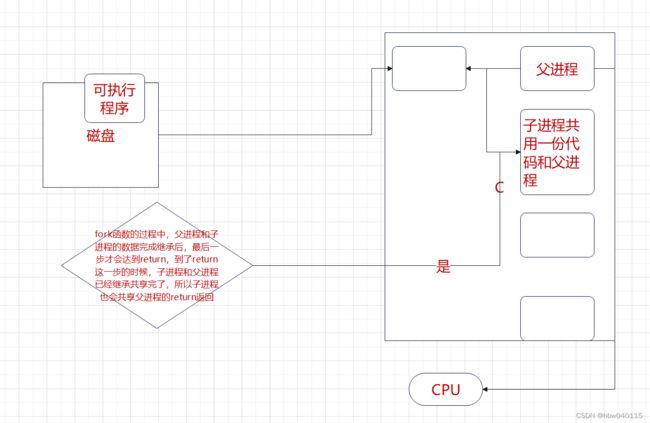
然后是下一个问题:为什么fork会有两个返回值?
我首先问一个问题:如果一个函数已经执行到return,那么它的核心工作完成了么?
很显然,它的核心工作已经完成了,在fork这里就是说,子进程已经把父进程的PCB的继承工作完成了,我们说fork的核心工作是利用父进程来创建子进程,故到return的时候,子进程已经和父进程共享一份代码了。
也就是说,子进程继承了父进程的代码,包括父进程的return代码,也就是说,他们两个是各自返回一个值,然后在同一段代码中分别去做判断。因此,会给我们一种一个函数返回了两个返回值的错觉,实际上本质上还是一个。
然后是下一个问题:为什么fork的两个返回值一个返回给子进程是0,给父进程的是子进程的pid?
这是由于,在实际情况中,我们的父进程与子进程往往是1对多的关系,因此,父进程就起到管理子进程的责任,既然涉及到管理,就又涉及到我们说过的:先描述再组织的过程。在描述的时候,我们得区分每一个子进程,但子进程大部分的数据都是继承父进程的,唯独这个pid是子进程独有的,故我们的父进程就会接收子进程的pid,从而更好的区分子进程方便管理。而对于子进程来说,他们不用管理他们的父进程,并且他们的父进程唯一,故返回0判断一下子进程是否被创建即可。
然后是下一个问题:fork之后,父子进程的运行顺序是什么?谁先被运行?
注意,创建完子进程只是一个开始,也就是说fork()函数仅仅是把子进程PCB放入到对应的进程队列中,但具体的CPU调用顺序,系统的其他进程,父进程和子进程接下来都会在PCB队列中被调用执行。
当父进程和子进程在同一个进程队列中时,哪一个进程先被CPU调用哪一个就先运行,这个是不确定的,因为它取决于操作系统是如何安排的,而操作系统会根据PCB的调度信息,比如时间片,优先级这些因素+调度器算法共同决定,因此,无法确定谁先执行,主要看实际情况,和OS的自主决定。
最后一个问题:为什么接收的变量只有一个,却同时接收不同的值?
启动不同的软件,就相当于启动不同的进程,若kill掉其中一个进程,对其他进程会有影响么?
你打LOL的时候打开又关上QQ会影响你的LOL对局么?当然不会,因此,kill掉一个进程,对其他进程是没有影响的,其他进程依旧存在。
因此我们可以总结:进程之间运行的时候,是具有独立性的,无论是什么关系,父子也好,平行关系也好,都是独立运行的。
说到独立运行,那么OS是如何保持这种独立运行的特点的呢?
首先,每一个进程都有自己对应的PCB,也就是自己独特的一套进程管理结构,这就保持了进程之间不会互相影响。但是代码和数据呢?
子进程可是会和父进程共享代码的,但是我们通过加上的判断可以使代码达到分别执行对应的效果,那么数据呢?如果我想要子进程单独处理一批数据呢?怎样保持数据的独立性呢?也就是说,如何保证数据私有呢?
在这里我们可以使用我们在**实现string的时候使用的写时拷贝的方式,**即修改数据时再重新深拷贝一份数据,如果数据相同,就直接浅拷贝一份数据这样就保证了数据私有的同时又不会频繁的调用深拷贝,节省了时间提高了效率。
因此我们总结:返回的本质就是写入,而变量存储的就是数据,返回的时候,发生了写时拷贝,所以同一个变量会有不同的值。
既然是这样的话,那么子进程对应的fork接收的值和父进程对应的fork接收的值的地址应该是不同的吧。
我们来打印出来看看:

什么?竟然地址相同,意味着这两个值对应的值是相同的?这不可能呀?
对于变量来说,同一个地址却有不同的内容,这在物理意义上是不可能的,所以,这里的地址,绝对不是物理地址,至于它是什么地址,我们今后随着学习的深入,会了解这一方面的内容。这里涉及到虚拟地址的问题,我目前是很难说明白的,但是大家可以看我下面推荐的关于虚拟内存虚拟地址的讲解的文章:
名字就为:彻底搞懂虚拟内存,虚拟地址,虚拟地址空间
这篇文章很深入的讲解了虚拟地址,是一种可以存在于磁盘上的地址,与实际存储在物理内存上的数据不同,它是通过映射去反映到磁盘上的空间,所以我在这里大胆猜测的是:
父进程的数据是实际上的物理内存,而新开辟的子进程的id数据其实就是映射到磁盘上的虚拟内存,也就是说,子进程把父进程的地址当成一个数字,然后映射到磁盘空间存储这个数据。
总结:
在这篇文章中,我们系统的初步认识了进程的各种概念,并且学习了PCB的第一个数据段:标识符和相关的系统函数调用。后面我们还会继续学习关于进程的数据段的其他内容,所以继续努力!!!!
·