SpringCloudGateway网关
SpringCloudGateway网关
- 欢迎学习SpringCloudGateway
-
- 基本概念
- Spring Cloud Gataway的特点
- Spring Cloud Gataway核心组件
- Spring Cloud Gateway的工作方式
- Spring Cloud Gataway入门
-
-
- Predicate断言工厂
-
- 根据查询参数断言- Query Route Predicate Factory
- 根据path断言-Path Route Predicate Factory
- 根据权重比例断言-Weight Route Predicate Factory
- 根据远程ip断言 - RemoteAddr Route Predicate Factory
- 指定时间之后断言-After Route Predicate Factory
- 在指定时间之前断言-Before Route Predicate Factory
- 在指定时间段之间断言-Between Route Predicate Factory
- 根据cookie断言-Cookie Route Predicate Factory
- 根据请求头断言-Header Route Predicate Factory
- 根据主机断言-Host Route Predicate Factory
- 根据请求方式断言-Method Route Predicate Factory
- Gateway 的 Filter 过滤器
-
- 内置的Gateway filter
-
- 自定义Gateway Filter
- 自定义GlobalFilter
- Gateway跨域配置
- Gateway超时
-
欢迎学习SpringCloudGateway
作为一名勤劳码农,记录一些学习的历程,希望各位大佬能够多多指教…
基本概念
Zuul是Netflix的开源项目,Spring Cloud将其收纳成为自己的一个子组件。zuul用的是多线程阻塞模型,它本质上就是一个同步 Servlet,这样的模型比较简单,他都问题是多线程之间上下文切换是有开销的,线程越多开销就越大。线程池数量固定意味着能力接受的请求数固定,当后台请求变慢,面对大量的请求,线程池中的线程容易被耗尽,后续的请求会被拒绝。
在Zuul 2.0中它采用了 Netty 实现异步非阻塞(NIO)编程模型,异步非阻塞模式对线程的消耗比较少,对线程上线文切换的消耗也比较小,并且可以接受更多的请求。它的问题就是线程模型比较复杂,要求深究底层原理需要花一些功夫。
Spring Cloud Gateway是Spring Cloud自己的产物,基于Spring 5 和Spring Boot 2.0 开发,Spring Cloud Gateway的出现是为了代替zuul,在Spring Cloud 高版本中没有对zuul 2.0进行集成,SpringCloud Gateway使用了高性能的Reactor模式通信框架Netty。
Spring Cloud Gateway 的目标,不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
所以说其实Gateway和zuul 2.0差别不是特别大,都是采用Netty高性能通信框架,性能都挺不错。
Spring Cloud Gataway的特点
在Spring Cloud官方定义了SpringCloud Gateway 的如下特点:
- 基于 Spring 5,Project Reactor , Spring Boot 2.0
- 默认集成 Hystrix 断路器
- 默认集成 Spring Cloud DiscoveryClient
- Predicates (断言)和 Filters 作用于特定路由,易于编写的 Predicates 和 Filters
- 支持动态路由、限流、路径重写
Spring Cloud Gataway核心组件
- Predicate(断言):
这是一个 Java 8 的 Predicate,可以使用它来匹配来自 HTTP 请求的任何内容,例如 headers或参数。断言的输入类型是一个ServerWebExchange。简单理解就是处理HTTP请求的匹配规则,在什么样的请情况下才能命中资源继续访问。 - Route(路由):
网关配置的基本组成模块,和Zuul的路由配置模块类似。一个Route模块有一个 ID,一个目标URI,一组断言和一组过滤器定义。如果断言为真,则路由匹配,目标URI会被访问。说白了就是把url请求路由到对应的资源(服务),或者说是一个请求过来Gateway应该怎么把这个请求转发给下游的微服务,转发给谁。 - Filter(过滤器):
Spring CloudGateway的Filter和Zuul的过滤器类似,可以在请求发出前后进行一些业务上的处理,这里分为两种类型的Filter,分别是Gateway Filter网关filter 和 Global Filter全局Filter,他们的区别在后续会讲到。
Spring Cloud Gateway的工作方式
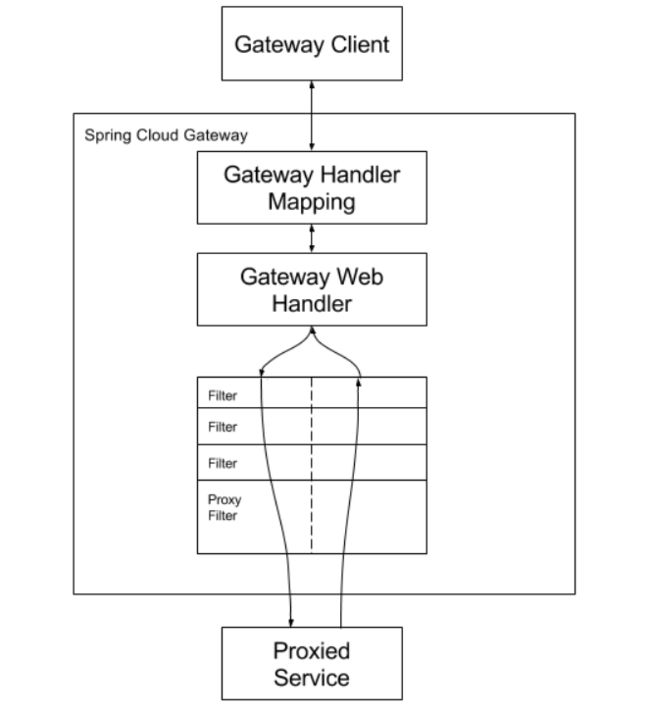 客户端向Spring Cloud Gateway发出请求。如果网关处理程序映射确定请求与路由匹配,则将其发送到网关Web处理程序。该处理程序通过特定于请求的过滤器链来运行请求。筛选器由虚线分隔的原因是,筛选器可以在发送代理请求之前和之后运行逻辑。所有“前置”过滤器逻辑均被执行。然后发出代理请求。发出代理请求后,将运行“后”过滤器逻辑。
客户端向Spring Cloud Gateway发出请求。如果网关处理程序映射确定请求与路由匹配,则将其发送到网关Web处理程序。该处理程序通过特定于请求的过滤器链来运行请求。筛选器由虚线分隔的原因是,筛选器可以在发送代理请求之前和之后运行逻辑。所有“前置”过滤器逻辑均被执行。然后发出代理请求。发出代理请求后,将运行“后”过滤器逻辑。
Spring Cloud Gataway入门
- 新建工程导入依赖
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
org.springframework.cloud
spring-cloud-starter-gateway
com.alibaba
fastjson
1.2.58
- 主启动类
@SpringBootApplication
@EnableDiscoveryClient
public class GateWayServerApplication1060 {
public static void main(String[] args) {
SpringApplication.run(GateWayServerApplication1060.class);
}
}
- yml配置
server:
port: 1060 #端口
eureka:
instance:
prefer-ip-address: true
instance-id: gateway-server:1060
client:
serviceUrl:
defaultZone: http://localhost:1010/eureka/
spring:
application:
name: gateway-server
cloud:
gateway:
discovery:
locator:
enabled: false #开放服务名访问方式
lower-case-service-id: true #服务名小写
routes:
- id: application-user #指定服务名
uri: lb://user-server #去注册中心找这个服务名
predicates: #断言,匹配访问的路径
- Path=/apis/user/** #服务访问路径
filters:
- StripPrefix=2 #请求转发的时候会去掉 /user访问路径
- id: application-order #指定服务名
uri: lb://order-server #去注册中心找这个服务名
predicates: #断言,匹配访问的路径
- Path=/apis/order/** #服务访问路径 localhost:10060/apis/order/order/getuser/1
filters:
- StripPrefix=2 #请求转发的时候会去掉 /apis/order/访问路径 ,/order/getuser/1
这里除了要注册到Eureak以外,还需要配置Gataway的路由
spring.cloud.gateway.discovery.locator.enabled=false: 不开放服务名访问方式spring.cloud.gateway.discovery.locator.lower-case-service-id: true忽略服务名大小写,大写小写都可以匹配spring.cloud.gateway.routes.id: 指定了路由的服务名,可以自己定义spring.cloud.gateway.routes.uri=lb://user-server: 去注册中心找服务,采用负载均衡的方式请求。其实就是找要调用的服务。spring.cloud.gateway.routes.predicates: 断言,这里使用的Path=/user/**,即匹配访问的路径如果匹配/user/就可以将请求路由(分发)到user-server这个服务上。spring.cloud.gateway.routes.filters:这里使用StripPrefix=1主要是处理前缀 /user ,访问目标服务的时候会去掉前缀访问。这个需要根据url情况来定义。
Predicate断言工厂
- 什么是断言工厂
什么是断言工程,在Spring Cloud Gateway官方文档有如下解释:
Spring Cloud Gateway将路由作为Spring WebFlux HandlerMapping基础架构的一部分进行匹配。Spring Cloud Gateway包括许多内置的路由断言工厂。所有这些断言都与HTTP请求的不同属性匹配。您可以将多个路由断言工厂与逻辑and语句结合使用。
这里不难理解,其实断言工厂就是用来判断http请求的匹配方式。比如我们再上面案例中配置的:“Path=/user/**” ,就是使用的是 “Path Route Predicate Factory” 路径匹配工厂,意思是http请求的资源地址必须是 /user 才会被匹配到对应的路由,然后继续执行对应的服务获取资源。
在Spring Cloud Gateway中,针对不同的场景内置的路由断言工厂,比如
Query Route Predicate Factory:根据查询参数来做路由匹配
2.RemoteAddr Route Predicate Factory:根据ip来做路由匹配
3.Header Route Predicate Factory:根据请求头中的参数来路由匹配
4.Host Route Predicate Factory:根据主机名来进行路由匹配
5.Method Route Predicate Factory:根据方法来路由匹配
6.Cookie Route Predicate Factory:根据cookie中的属性值来匹配
7.Before Route Predicate Factory:指定时间之间才能匹配
8.After Route Predicate Factory: 指定时间之前才能匹配
9.Weight Route Predicate Factory: 根据权重把流量分发到不同的主机
根据查询参数断言- Query Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: query_route
uri: https://example.org
predicates:
- Query=green
上面配置表达的试试是如果请求参数中包含了 green,那么就会断言成功,从而执行uri后面的地址。
根据path断言-Path Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: path_route
uri: https://example.org
predicates:
- Path=/red/{segment},/blue/{segment}
请求路径如: /red/1或/red/blue或/blue/green 就可以断言成功
根据权重比例断言-Weight Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: weight_high
uri: https://weighthigh.org
predicates:
- Weight=group1, 8
- id: weight_low
uri: https://weightlow.org
predicates:
- Weight=group1, 2
大约80%的请求转发到weighthigh.org,将大约20%的流量转发到weightlow.org。
根据远程ip断言 - RemoteAddr Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: remoteaddr_route
uri: https://example.org
predicates:
- RemoteAddr=192.168.1.1/24
如果请求的远程地址为 192.168.1.1到192.168.1.24之间,则此路由匹配
指定时间之后断言-After Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- After=2017-01-20T17:42:47.789-07:00[America/Denver]
在atfer配置的时间之后才能访问
在指定时间之前断言-Before Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: before_route
uri: https://example.org
predicates:
- Before=2017-01-20T17:42:47.789-07:00[America/Denver]
在before配置的时间之前才能访问
在指定时间段之间断言-Between Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: between_route
uri: https://example.org
predicates:
- Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2017-01-21T17:42:47.789-07:00[America/Denver]
请求时间在两个时间之内者允许访问
根据cookie断言-Cookie Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://example.org
predicates:
- Cookie=chocolate, ch.p
cookies中必须有Cookie配置的属性才能匹配
根据请求头断言-Header Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: header_route
uri: https://example.org
predicates:
- Header=X-Request-Id, \d+
请求头必须出现 X-Request-Id 才可以访问
根据主机断言-Host Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://example.org
predicates:
- Host=**.somehost.org,**.anotherhost.org
如果请求的主机头具有值**.somehost.org,或者**.anotherhost.org这匹配路由
根据请求方式断言-Method Route Predicate Factory
spring:
cloud:
gateway:
routes:
- id: method_route
uri: https://example.org
predicates:
- Method=GET,POST
只允许 GET和POST请求
Gateway 的 Filter 过滤器
Gateway的Filter的zuul的Filter有相似之处,与zuul不同的是,Gateway的filter从生命周期上可以为“pre”和“post”类型。根据作用范围可分为针对于单个路由的gateway filter,和针对于所有路由的Global Filer。
内置的Gateway filter
针对单个路由的Filter, 它允许以某种方式修改HTTP请求或HTTP响应。过滤器可以作用在某些特定的请求路径上。Gateway内置了很多的GatewayFilter工厂。如果要使用这些Filter只需要在配置文件配置GatewayFilter Factory的名称。下面拿一个内置的Gateway Filter举例:
AddRequestHeader GatewayFilter Factory
该Filter是Gateway内置的,它的作用是在请求头加上指定的属性。配置如下:
spring:
cloud:
gateway:
routes:
- id: add_request_header_route
uri: https://example.org
filters:
- AddRequestHeader=X-Request-red, blue
在spring.cloud.gateway.routes.filters配置项配置了一个AddRequestHeader ,他是“AddRequestHeader GatewayFilter Factory”的名称,意思是在请求头中添加一个“X-Request-red”的属性,值为blue 。
其他的Filter可以去看 AbstractGatewayFilterFactory 的实现类。
自定义Gateway Filter
在Spring Cloud Gateway自定义过滤器,过滤器需要实现GatewayFilter和Ordered这两个接口。我们下面来演示自定义filter计算请求的耗时。
public class RequestTimeFilter implements GatewayFilter, Ordered {
private static final Log log = LogFactory.getLog(GatewayFilter.class);
private static final String COUNT_Start_TIME = "countStartTime";
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//开始时间
exchange.getAttributes().put(COUNT_Start_TIME, System.currentTimeMillis());
//执行完成之后
return chain.filter(exchange).then(
Mono.fromRunnable(() -> {
//开始时间
Long startTime = exchange.getAttribute(COUNT_Start_TIME);
//结束时间
Long endTime=(System.currentTimeMillis() - startTime);
if (startTime != null) {
log.info(exchange.getRequest().getURI().getRawPath() + ": " + endTime + "ms");
}
})
);
}
@Override
public int getOrder() {
return Ordered.LOWEST_PRECEDENCE;
}
}
提示: getOrder返回filter的优先级,越大的值优先级越低 , 在filterI方法中计算了请求的开始时间和结束时间
最后我们还需要把该Filter配置在对应的路由上,配置如下:
@Configuration
public class FilterConfig {
//配置Filter作用于那个访问规则上
@Bean
public RouteLocator customerRouteLocator(RouteLocatorBuilder builder) {
return builder.routes().route(r -> r.path("/services/user/**")
//去掉2个前缀
.filters(f -> f.stripPrefix(2)
.filter(new RequestTimeFilter())
.addResponseHeader("X-Response-test", "test"))
.uri("lb://service-user")
.order(0)
.id("test-RequestTimeFilter")
).build();
}
}
}
自定义GlobalFilter
GlobalFilter:全局过滤器,不需要在配置文件中配置,作用在所有的路由上,最终通过GatewayFilterAdapter包装成GatewayFilterChain可识别的过滤器,它为请求业务以及路由的URI转换为真实业务服务的请求地址的核心过滤器,不需要配置,系统初始化时加载,并作用在每个路由上。
这里我们模拟了一个登陆检查的Filter.
@Component
@Slf4j
public class TimeGlobleFilter implements GlobalFilter , Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
List<String> token = exchange.getRequest().getHeaders().get("token");
log.info("检查 TOKEN = {}" ,token);
if(token == null || token.isEmpty()){
//响应对象
ServerHttpResponse response = exchange.getResponse();
//构建错误结果
HashMap<String,Object> data = new HashMap<>();
data.put("code",401);
data.put("message","未登录");
DataBuffer buffer = null;
try {
byte[] bytes = JSON.toJSONString(data).getBytes("utf-8");
buffer = response.bufferFactory().wrap(bytes);
//设置完成相应,不会继续执行后面的filter
//response.setComplete();
response.setStatusCode(HttpStatus.UNAUTHORIZED);
response.getHeaders().add("Content-Type","application/json;charset=UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//把结果写给客户端
return response.writeWith(Mono.just(buffer));
}
log.info("Token不为空 ,放行");
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 0;
}
}
如果请求头中没有 token ,就返回咩有权限的状态吗。
使用 buffer = response.bufferFactory().wrap(bytes) 构建响应内容,通过response.writeWith(Mono.just(buffer)); 把内容写给客户端。
Gateway跨域配置
所谓的跨域是因为浏览器的同源(同一个域)策略限制,其实就是同源策略会阻止一个域的javascript脚本和另外一个域的内容进行交互 ,在前后端分离的项目架构中就会出现跨域问题,因为Gateway 网关是微服务的访问入口,所以我们只需要在Gateway配置跨域即可。
spring:
cloud:
globalcors: #跨域配置
cors-configurations:
'[/**]':
allowedOrigins: "https://docs.spring.io" #允许的站点
allowedMethods: #允许的请求方式
- GET
- POST
- DELETE
- PUT
- HEAD
- CONNECT
- TRACE
- OPTIONS
allowHeaders: #允许的请求头
- Content-Type
Gateway超时
超时配置在微服务调用和数据读取的时候显得尤为重要,下面演示Gateway中的全局超时设置:
spring:
cloud:
gateway:
httpclient:
connect-timeout: 1000
response-timeout: 5s
指定路由超时配置:
spring:
cloud:
gateway:
routes:
- id: per_route_timeouts
uri: https://example.org
predicates:
- name: Path
args:
pattern: /delay/{timeout}
metadata:
response-timeout: 200
connect-timeout: 200