多个 ConvNeXt 模型并行?详解RevCol(ICLR 2023)
作者 | 科技猛兽 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
本文只做学术分享,如有侵权,联系删文
导读
将解耦学习(disentangled feature learning)的思想引入模型设计中,提出以 reversible column 为单元来传递信息,既保证特征解耦,同时信息在网络中的传递不受到损失。
本文目录
1 RevCol:可逆的柱状神经网络 (来自旷世,张祥雨老师团队)
1 RevCol 论文解读
1.1 背景:从信息瓶颈理论的角度,让预训练好的特征能够更加普遍和通用
1.2 RevCol 的特点和主要贡献
1.3 可逆多级融合模块的原理
1.4 RevCol 的宏观架构设计
1.5 特征解耦的可视化结果
1.6 RevCol 的微观架构设计
1.7 RevCol 训练的目标函数
1.8 ImageNet-1K 图像分类实验结果
1.9 COCO 检测,ADE20K 分割实验结果
1.10 系统级别的性能比较
太长不看版
RevCol 这个模型可以看做是:多个并行的 ConvNeXt 模型。每个 ConvNeXt 认为是一个柱子 (Column),每个 Column 之间通过可逆操作连接,使得信息得以最大程度地保持。传统的 ConvNeXt 可以看成是单柱状的神经网络架构,而 RevCol 很显然是一个多柱状的网络架构,相当于是从横向扩展了 ConvNeXt 这个经典的模型。在 RevCol 中,靠近输入的层包含更多的 low-level 信息,而靠近输出的特征具有丰富的 high-level 语义信息,而且不同 Column 的架构自然而然地实现了特征的解耦。
1 RevCol:可逆的柱状神经网络
论文名称:Reversible Column Networks (ICLR 2023)
论文地址:
https://arxiv.org/pdf/2212.11696.pdf
原作者官方解读:
给神经网络架构增加了一个维度!RevCol:大模型架构设计新范式(ICLR 2023)
https://zhuanlan.zhihu.com/p/593850929
Valse 2023 张祥雨老师 talk 第三方记录 (感谢记录者们的总结整理):
https://zhuanlan.zhihu.com/p/636466772
https://zhuanlan.zhihu.com/p/637371566
1.1 背景:从信息瓶颈理论的角度,让预训练好的特征能够更加普遍和通用
信息瓶颈理论 (Information Bottleneck Principle, IB[1][2]) 是深度学习世界中的重要规则。
下图 1(a) 所示的典型有监督学习框架,比如 ResNet 就可以用图 1(a) 表示,可以看成是单柱状的神经网络架构。靠近输入的层包含更多的 low-level 信息 (黄色表示),而靠近输出的特征具有丰富的 high-level 语义信息 (蓝色表示)。换句话说,与目标无关的信息在逐层传播过程中逐渐被压缩 (Compressed) 了。尽管这种学习的范式在许多实际的计算机视觉应用中取得了巨大的成功,但是,在特征学习方面可能不是最佳的选择。如果学习到的特征被过度压缩 (Over Compressed) 了,或者学习到的语义信息与目标任务无关,那么下游任务可能会出现比较差的性能,尤其是当上下游任务之间存在显著的域的 gap 时。为了让预训练好的特征能够更加普遍和通用,研究者之前通过自监督预训练 (比如著名的 BERT[3],MAE[4]) 或者多任务学习[5][6]的方式。
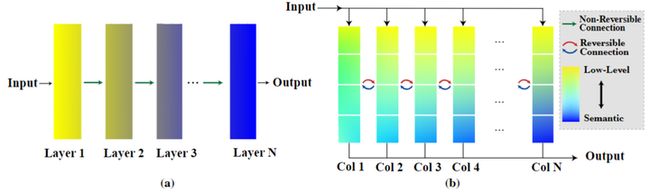 图1:(a) 原始的单柱状神经网络架构。(b) 本文提出的可逆多柱状神经网络架构。黄色表示 low-level 信息,蓝色表示 high-level 的语义信息
图1:(a) 原始的单柱状神经网络架构。(b) 本文提出的可逆多柱状神经网络架构。黄色表示 low-level 信息,蓝色表示 high-level 的语义信息
本文为了达到让预训练好的特征能够更加普遍和通用,没有采用自监督预训练或者多任务学习的范式,而是关注另一种:构建一个学习解耦特征 (Disentangled Representations) 的神经网络的方法。
解耦学习:
目的是将与任务相关的概念或语义词分别嵌入到几个解耦维度中。
希望学到的整个特征向量大致与输入保持尽可能差不多的信息量。
与生物细胞中的机制非常相似:每个细胞都共享基因组的副本,但是表达强度不同。
在计算机视觉任务里面,解耦学习也是很合理的。比如在 ImageNet 预训练期间需要 high-level 的语义表征,而在目标检测等下游任务的需求时,也应该其他特征维度中保持一些 low-level 的信息。
1.2 RevCol 的特点和主要贡献
Reversible Column Networks (RevCol) 模型的提出受到 Hinton 的 GLOM[7] 的影响。RevCol 模型的宏观架构如上图 1(b) 所示,它包含 个子网络 (也叫 Column),特点如下:
每个 Column 架构一样,但是权重是不同的。
每个 Column 都输入相同的 input,并生成自己的预测结果。
从低到高级的特征,依次存入每个 Column 里面。
引入可逆变换 (Reversible Transformation),在不损信息前提下将第 个 Column 的特征传播到第 个。
在传播过程中,随着复杂度和非线性的增加,所有特征的 level 逐渐提高。
最后一列预测输入的解耦表征。
RevCol 的主要贡献是受了 Reversible Networks 的启发,引入了 Column 之间的可逆变换[8]。但是传统的 RevNet 有两个缺点:
可逆 Block 内的特征映射被限制为具有相同的形状。
最后两个特征映射由于可逆的性质,必须包含 low-level 和 high-level 信息,很难优化,与 IB 原理冲突。
所以本文针对这两个问题提出了一种可逆多级融合模块 (Reversible Multi-Level Fusion Module),可以解决尺度不匹配的问题。
1.3 可逆多级融合模块的原理
可逆模块的典型案例是 RevNet ,如下图 2(a) 所示是 RevNet 中的可逆模块。RevNet 首先把输入特征 分为两组: 和 。对于后面的 Block, 比如第 个 Block 而言, 它以两个前块的输出 和 为输入, 生成输出 。
 图2:(a) RevNet 中的可逆模块。(b) 可逆多级融合模块。(c) 整个的可逆柱状网络的架构
图2:(a) RevNet 中的可逆模块。(b) 可逆多级融合模块。(c) 整个的可逆柱状网络的架构
第 个 Block 如果是可逆的, 则 可以由两个后续的 Block 和 算出来:
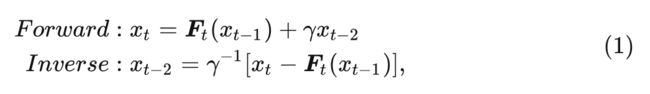
其中, 表示类似于标准 ResNet 中的残差函数的任意非线性操作, 表示一个简单的可逆操作。
但是, 上述公式涉及对特征维度过于强的约束, 即 的维度必须大小严格相等, 使 得我们模型的架构设计不灵活。
为了解决这个问题, 本文提出下面的设计:
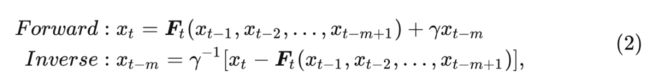
式中, 是递归的阶数, 一般满足 。把每 个特征划分为一个组, 。
2式相比于1式多了两个比较好的性质,即:
1. 当 的值比较大时,对特征维度的限制大大减小了。不再需要一个组内的特征图维度一致,只要求组间的特征维度一致。因此,我们可以使用不同形状的张量来表示不同语义级别或不同分辨率的特征。
2. 很容易与现有的网络架构协同。
然后,可以接着把图 2(b) 变为图 2(c) 的 Multi-Column 的形式,每个 Column 都由 mm 个特征组成,作者称之为可逆多级融合模块,是 RevCol 的基本组成架构。
1.4 RevCol 的宏观架构设计
RevCol 的宏观架构由可逆多级融合模块组成,具体来讲有多个子网络 (Column) 构成,各个子网络之间通过可逆变换进行连接,执行特征的解耦。RevCol 的宏观架构可以概括如下:
输入图片首先按照 ViT 的方式执行分 Patch 的操作,然后输入给每个 Column 中。
Column 可以是各种经典的 CNN, Transformer,比如 ConvNeXt 或者 ViT。
每个 Column 都有 4 个 level 的特征图,可以简单地从每个阶段的输出中提取多分辨率特征。
分类任务仅使用最后1个 Column 的最后一层的特征图进行丰富的语义信息。
检测分割等使用最后1个 Column 的所有4个 level 的特征,因为同时有 low-level 和 high-level 的语义信息。
作者实际上使用了一个简化的版本, 即只使用当前 Column 的 low-level 特征 和前序 Column 的 high-level 特征 。简化不会破坏可逆性质, 而且作者发现更多的输入会带来很小的准 确度增益,但消耗更多的 GPU 资源。
因此,2式可以重写为:

RevCol 的宏观架构设计的优势是:
1. 特征的解耦:
在 RevCol 中,每个 Column 的接近输入部分的特征是 low-level 的,而最后一个 Column 的最接近输出部分的特征是 high-level 的,因为它接近监督信号。因此,在 Column 之间信息的传播过程中,不同层次的信息逐渐解开:一些特征图中的语义信息更加丰富,而另一些特征的特征更加 low-level。这个性质带来了许多潜在的优势,比如对依赖于高级特征和低级特征的下游任务更灵活。而且,RevCol 中的这种可逆操作对于信息的保留也是比较重要的。
2. 节约内存:
传统网络的训练需要大量的 memory footprint 来存储前向传播期间的 Activation 作为反向传播时梯度计算的需求。
而在 RevCol 网络中,Column 之间通过可逆操作连接,在反向传播期间,我们可以动态地从最后一个 Column 重建所需的 Activation 到第一个 Column。这意味着我们只需要存储1个 Column 的 Activation 就可以。
如下图3所示是随着模型缩放而造成的 GPU 内存消耗。作者将单个 Column 的计算复杂度固定为 1G FLOPs 并增加 Column 的数量。同时测量了训练过程中的内存消耗,包括前向和后向传播。这个实验是在 Batch Size 为64,FP16 精度和 Nvidia Tesla V100 GPU 上使用 PyTorch 进行的。随着 Column 数量的增加,可以看到 RevCol 保持了 \mathcal{O}(1)\mathcal{O}(1) 的 GPU 内存消耗,而不可逆啊架构的内存消耗随着 Column 数量的增加而线性增加。RevCol 的 GPU 内存消耗也不会随着 Column 的增加而保持严格不变。
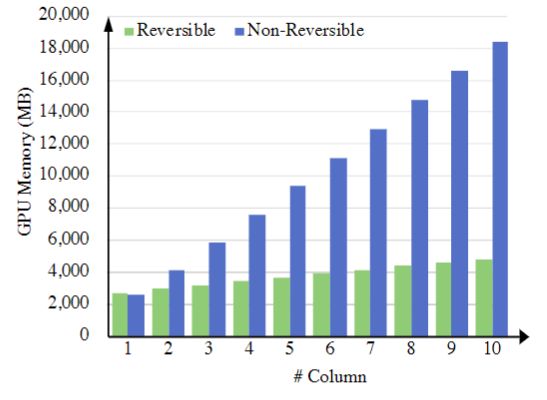 图3:随着模型缩放带来的 GPU 内存消耗
图3:随着模型缩放带来的 GPU 内存消耗
3. 大模型新的放大方式:
在 RevCol 架构中,如果想放大这个模型,除了常规的放大 Depth 和 Width 之外,还可以放大 Column 的数量,而且增加 Column 的数量在一定范围内增加宽度和深度具有相似的效果。
1.5 特征解耦的可视化结果
作者还展示了 RevCol 可以完成特征解耦。作者使用在 ImageNet-1K 上预训练的 RevCol-S 进行分析。
作者首先可视化了每个 Column 的每个 level 的最后一层的 Class Activation Maps (CAMs),采用 LayerCAM 技术,结果如下图4所示。可以看到,随着 level 和 Column 的深入,特征集中在语义较多的区域。RevCol-S 的输出是最后一列不同 level 的特征,这些具有高级语义的特征侧重于图像的不同部分和对象的整个部分,实现了与任务相关的和与任务无关的特征的解耦。
 图4:每个 Column 的每个 level 的最后一层的 Class Activation Maps (CAMs)
图4:每个 Column 的每个 level 的最后一层的 Class Activation Maps (CAMs)
为了对解耦的程度进行量化,作者使用 Centered Kernel Alignment (CKA) 相似度来测量 RevCol-S 中特征之间的相似性。
 图5:不同 level 和 Column 的特征和图像或者标签的 CKA 相似度
图5:不同 level 和 Column 的特征和图像或者标签的 CKA 相似度
作者计算了 ImageNet 验证集中每个类别的不同 level 和 Column 之间的中间特征与图像或标签之间的 CKA 相似度。可视化结果如图5所示,Column 2-Column 5 中不同 level 的图像和中间特征之间的相似度没有明显区别,而较高 level 的特征与 Column 6-Column 8 中的图像的相似度较低。在较高的 Column 中,标签和中间特征之间的相似性也更加明显。
1.6 RevCol 的微观架构设计
RevCol 的每一列都是一个 ConvNeXt,作者使用一个融合模块 (Fusion Block) 来融合当前 Column 和上一个 Column 的特征。LayerNorm 放在 patch-merging 卷积操作之后。
Kernel Size 不使用 ConvNeXt 的 7×7 大小,而是使用 3×3 大小,主要是为了加速训练。增加 Kernel Size 的大小可以进一步提升性能,但不是很多,部分原因可能是多个 Column 的设计扩大了有效的感受野。
可逆操作 是一个可学习的 Channel-Wise 的参数, 用以使得模型训练更加稳定。作者在训练时对 的值进行了截断操作, 使之永远不可能小于 , 因为当 太小时, 反向计算中的数值误差可能会变得很大。
1.7 RevCol 训练的目标函数
虽然可逆多级融合模块可以在 Column 之间用可逆变换的方式保持信息,但是网络中的下采样操作仍然会丢弃掉 Column 内的信息,导致每个 Column 的输出都很接近最终输出,导致整个模型的性能较差。为了缓解信息崩溃的问题,本文采用了中间监督目标函数,该方法在前面的 Column 中添加了额外的监督信息。
作者想通过中间监督损失函数,希望尽可能地保留特征和输入图像之间的互信息,以使得网络每个 Column 中丢弃的信息较少。
作者在最后一个 level 的特征上面加了两个辅助头,一个是 decoder,用于重建输入图片,使用 BCE Loss 来训练。另一个是分类头,用于做分类任务,使用 CE Loss 来训练。
总的训练目标函数是:

式中, 和 分别代表 BCE Loss 和 CE Loss, 和 随着不同 Column 的变化而变化。早期的 Column 使用较大的 和较小的 来维持互信息。后期的 Column 使用较小的 和较大的 来提升性能。
1.8 ImageNet-1K 图像分类实验结果
不同 RevCol 模型架构细节:
RevCol-T: C = (64, 128, 256, 512), B = (2, 2, 4, 2), COL = 4
RevCol-S: C = (64, 128, 256, 512), B = (2, 2, 4, 2), COL = 8
RevCol-B: C = (72, 144, 288, 576), B = (1, 1, 3, 2), COL = 16
RevCol-L: C = (128, 256, 512, 1024), B = (1, 2, 6, 2), COL = 8
RevCol-XL: C = (224, 448, 896, 1792), B = (1, 2, 6, 2), COL = 8
RevCol-H: C = (360, 720, 1440, 2880), B = (1, 2, 6, 2), COL = 8
实验结果如下图6所示。超参数、数据增强和正则化策略遵循 ConvNeXt 的设定。本文的模型优于大量单 Column 架构的 CNN 和 Transformer。比如 RevCol-S 达到了 83.5% 的 Top-1 精度,比 ConvNeXt-S 高出 0.4%。当使用更大的 ImageNet-22K 数据集进行预训练时,RevCol-XL 达到了 88.2% 的 Top-1 精度。由于 RevCol 在预训练过程中维护了一些与任务无关的低级信息,因此放宽 Params 和 FLOPs 的约束并扩大数据集大小可以进一步提高它的性能。作者构建了一个 168 亿张图像半标记数据集,通过额外的数据预训练和 ImageNet-1K 的微调,RevCol-H 达到了 90.0% 的 top-1 精度,这个结果很好地证明了 CNN 模型也可以吃到大模型+大数据的红利。
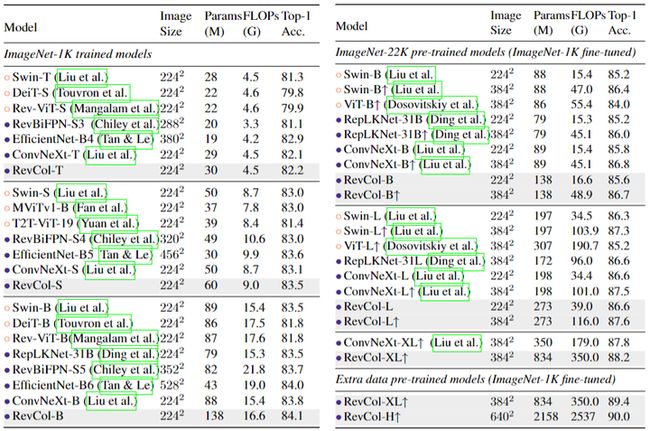 图6:ImageNet-1K 实验结果
图6:ImageNet-1K 实验结果
1.9 COCO 检测,ADE20K 分割实验结果
COCO 目标检测和实例分割的检测头使用的是 Cascade Mask R-CNN,最大的模型 RevCol-H 使用了 HTC++ 和 DINO 进行微调。实验结果如下图7所示。RevCol 模型超越了其他计算复杂度相似的模型。预训练中保留的信息有助于 RevCol 模型在下游任务中取得更好的结果。当模型大小变大时,这个优势变得更加显著。在 Objects365 数据集和 DINO 框架进行微调后,最大的模型 RevCol-H 在 COCO 检测集上实现了 63.8% 的 APbox。
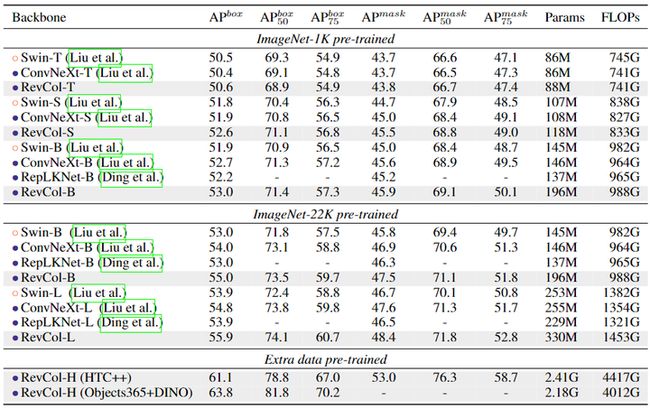 图7:COCO 目标检测实例分割实验结果
图7:COCO 目标检测实例分割实验结果
ADE20K 语义分割的分割头使用的是 UperNet,也尝试了最近的分割头 Mask2Former。实验结果如下图8所示。RevCol 模型可以在不同的模型容量上实现具有竞争力的性能,进一步验证了多柱状架构设计的有效性。值得注意的是,当使用 Mask2Former 检测器和额外的预训练数据时,RevCol-H 的 mIoU 为 61.0%,证明了这种架构对于大规模视觉应用的可扩展性。
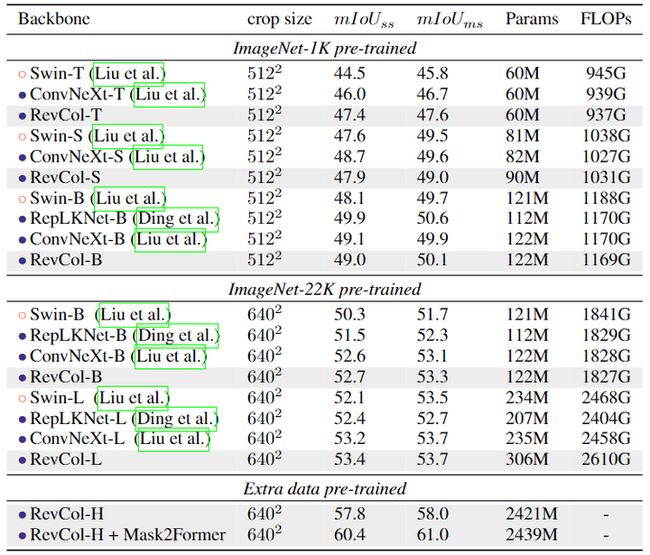 图8:ADE20K 语义分割实验结果
图8:ADE20K 语义分割实验结果
1.10 系统级别的性能比较
 图9:基础模型系统级别的性能比较
图9:基础模型系统级别的性能比较
如图9所示,作者展示了各种基础模型之间的比较,包括 Vision Transformers 和 Vision-Language 模型,即 SwinV2、BEiT-3 和 Florence。虽然 RevCol-H 是纯卷积和在单个模态数据集上预训练的,但是在对不同任务的上的实验结果证明了 RevCol 在大规模参数下的显著的泛化能力。
参考
^The information bottleneck method
^Deep Learning and the Information Bottleneck Principle
^BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
^Masked Autoencoders Are Scalable Vision Learners
^An Overview of Multi-Task Learning in Deep Neural Networks
^Multi-Task Learning as Multi-Objective Optimization
^How to represent part-whole hierarchies in a neural network
^abThe Reversible Residual Network: Backpropagation Without Storing Activations
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
