shell:正则表达式及三剑客grep命令
目录
一、grep和元字符
1、grep
2、元字符
三、正则匹配
1.查找特定字符
2、使用[ ]来查找集合字符
3、查找行首"^"与行尾字符"$"
4、查找任意一个字符"."与重复字段"*"
5、查找连续字符范围{}
四、扩展正则表达式
五、正则的一些实用写法
正则表达式又称为正规表达式、常规表达式、在代码中常简写为regex、regex或RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说,是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定的字符串。
简单来说:通配符功能是用来处理文件名而正则表达式是处理文本内容中字符
这里不得不提的是shell三剑客:grep,sed,awk。
一、grep和元字符
1、grep
grep [选项] [查找条件(正则)] [目标文件]
-color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息 $?
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接2、元字符
| . |
匹配任意单个字符,可以是一个汉字 |
| [ ] |
匹配指定范围内的任意单个字符,示例:[zhou] [0-9] [] [a-zA-Z] |
| [^] |
匹配指定范围外的任意单个字符,示例:[^zhou] [^a.z] a.z 如果 . 写在 [ ] 就是 . 不需要转义 转义 . \. 代表转义 |
| * |
代表前面的字符出现 0次 或任意次 |
| .* |
任意长度的任意字符(要有) |
| \? |
匹配其前面的字符出现0次或1次 |
| \+ |
匹配其前面的字符出现一次以上 |
| \{n\} |
精确匹配 n 次 |
| \{m,n} |
至少m,至多n次 |
| \{,n} |
匹配前面的字符至多n次,<=n,n可以为0 |
| \{n,} |
匹配前面的字符至少n次,<=n,n可以为0 |
三、正则匹配
1.查找特定字符
(1)grep -n 'the' tesst.txt

(2)grep -vn 'the' test.txt #匹配除了包含the的行

2、使用[ ]来查找集合字符
我们要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含sh与rt。此时执行下面命令可以提示查找到“shirt”和“short”这两个字符串,其中“[ ]”无论有几个字符,都代表一个字符,但是会按照[ ]内的每个字符都去做一次匹配,比如[io]表示要匹配“i”或者“o”。
grep -n "sh[io]rt" test.txt

要查找包含重复或单个字符oo时
grep -n 'oo' test.txt

查找oo前面不是w的字符串
若查找“oo”前面不是“w”的字符串,只需要通过集合字符的反向选择“[A]”来实现该目的。例如执行“grep -n‘[^w]oo’test.txt”命令表示在 test.txt 文本中查找“oo”前面不是“w”的字符串。
grep -n '[^w]oo' test.txt
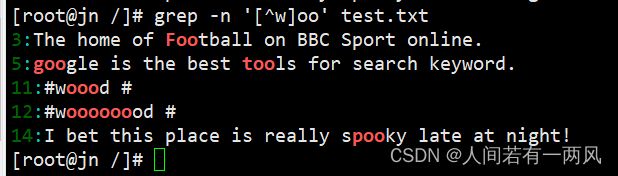
在上述命令的执行结果中发现“woood”与“wooooood”也符合匹配规则,二者均包含“w”。其实通过执行结果就可以看出,符合匹配标准的字符加粗显示,而上述结果中可以得知, “#woood #”中加粗显示的是“ooo”,而“oo”前面的“o”是符合匹配规则的。同理“#woooooood#”也符合匹配规则。
grep -n '[0-9]' test.txt

3、查找行首"^"与行尾字符"$"
grep -n '^the' test.txt

grep -n '^[a-z]' test.txt

grep -n '^[A-Z]' test.txt

查找以.结尾的行
grep -n '\.$' test.txt

查询空行
grep -n '^$' test.txt #查看空行

4、查找任意一个字符"."与重复字段"*"
grep -n 'w..d' test.txt

查询多个o
在上述结果中,“wood”字符串“w..d”匹配规则。若想要查询 oo、ooo、ooooo 等资料, 则需要使用星号(*)元字符。但需要注意的是,“*”代表的是重复零个或多个前面的单字符。 “o*”表示拥有零个(即为空字符)或大于等于一个“o”的字符,因为允许空字符,所以执行“grep -n'o*'test.txt”命令会将文本中所有的内容都输出打印。如果是“oo*”,则第一个 o 必须存在, 第二个 o 则是零个或多个 o,所以凡是包含 o、oo、ooo、ooo,等的资料都符合标准。同 理,若查询包含至少两个 o 以上的字符串,则执行“grep -n 'ooo*' test.txt”命令即可。
grep -n 'ooo*' test.txt #匹配两个以上的o

查找w开头d结尾至少包含一个o
grep -n 'woo*d' test.txt#查询以 w 开头 d 结尾,中间包含至少一个 o 的字符串,执行以下命令即可实现。

查询以 w 开头 d 结尾,中间的字符可有可无的字符串。
grep -n 'w.*d' test.txt

执行以下命令即可查询任意数字所在行
grep -n '[0-9][0-9]*' test.txt

5、查找连续字符范围{}
在上面的示例中,使用了“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一个 范围内的重复的字符串该如何实现呢?例如,查找三到五个 o 的连续字符,这个时候就需 要使用基础正则表达式中的限定范围的字符“{}”。因为“{}”在 Shell 中具有特殊意义,所以在 使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。“{}”字符的使用方法如下所示。
查找两个o字符
grep -n 'o\{2\}' test.txt

查询以 w 开头以 d 结尾,中间包含 2~5 个 o 的字符串
grep -n 'wo\{2,5\}' test.txt

查询以 w 开头以 d 结尾,中间包含 2 个或 2 个以上 o 的字符串
grep -n 'wo\{2,\}d' test.txt

四、扩展正则表达式
+
作用:重复一个或者一个以上的前一个字符
示例:执行“egrep -n 'wo+d' test.txt”命令,即可查询"wood" "woood" "woooooood"等字符串
?
作用:零个或者一个的前一个字符
示例:执行“egrep -n 'bes?t' test.txt”命令,即可查询“bet”“best”这两个字符串
|
作用:使用或者(or)的方式找出多个字符
示例:执行“egrep -n 'of|is|on'test.txt”命令即可查询"of"或者"if"或者"on"字符串
()
作用:查找“组”字符串
示例:“egrep-n't(a|e)st'test.txt”。“tast”与“test”因为这两个单词的“t”与“st”是重复的,所以将“a”与“e” 列于“()”符号当中,并以“|”分隔,即可查询"tast"或者"test"字符串
()+
作用:辨别多个重复的组
示例:“egrep -n 'A(xyz)+C' test.txt”。该命令是查询开头的"A"结尾是"C",中间有一个以上的"xyz"字符串的意五、正则的一些实用写法
比如我们要查看apache中有哪些IP对我们进行了访问,并进行计数
cat access_log | grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}' | sort -n | uniq -c | sort -nr | head -10
[0-9]\{1,3\}:匹配0-9的数字三次
\.:IP的分割符“.”
这样循环4次,就能识别网络IP
sort -n :对数字开头字符进行排序
sort -nr:对数字开头字符逆向排序
uniq -c:对重复项进行计数
###后面文章我也会对sort和uniq详细说明###
执行效果:
