HARVEST基音检测算法
Harvest: A high-performance fundamental frequency estimator from speech signals一种基于语音信号的高性能基频估计算法
Harvest的独特之处在于可以获得可靠的F0轮廓,减少了将浊音部分错误地识别为清音部分的错误。
它包括两个步骤:估计F0候选点和在这些候选点的基础上生成可靠的F0轮廓。
在第一步中,算法使用多个不同中心频率的带通滤波器提取基本分量,从滤波信号中得到基本F0候选值;然后利用瞬时频率对基本F0候选对象进行细化和评分,然后估计出每帧中的几个F0候选对象。由于基于基本成分提取的逐帧处理对时间局部噪声的鲁棒性较差,在第二步中使用了使用相邻f0的连接算法。这种连接利用了F0等高线在短时间内不会急剧变化的事实。
引言
语音参数(基频(F0)、频谱包络和非周期性)被广泛用于统计参数语音合成SPSS。由于SPSS需要大量的语音数据进行训练,高性能的语音分析仪不仅可以提高音质,还可以避免手工进行后期处理。现在有很多语音分析方法,哪种合适取决于研究的目的。例如,实时语音转换需要一个实时F0估计器,而SPSS通常优先考虑估计精度而不是实时性。
在最近的SPSS中,使用连续F0建模的深度神经网络(DNNs)已被使用。该F0建模通过样条插值方法对清音部分给出一定的F0。此建模首选的F0估计器应该具有为所有帧提供平滑F0轮廓的功能。因此,Harvest旨在减少将浊音部分错误地识别为清音部分。
相关研究
传统的F0估计器使用波形特征和功率谱。在基于波形的算法中,提出了平均幅差函数[7]和加权自相关。YIN是一个主要的估计算法,并在2014年开发了改进版本。在基于功率谱的算法中,基于倒谱的方法比较流行,SWIPE作为一种高性能的F0估计器最近被提出。
对于实时语音分析/合成应用,如DIO及其改进版本。
使用哪个F0估计器取决于研究的目的。对于实时语音分析/合成应用[14,2],已经提出了DIO[15]及其改进版本[16]。对于高质量的语音分析/合成系统,首选STRAIGHT[18]中使用的NDF[17]和TANDEM-STRAIGHT[19,20]中使用的XSX。特别是基音同步分析[21]可以提高频谱包络和非周期估计的估计性能。在使用F0作为估计其他语音参数的输入的情况下,估计精度很重要。F0自适应多帧集成分析[25]和D4C[26],world中使用的CheapTrick[22,23]需要一个高性能的F0估计器。对于自动语音识别,由于系统经常在嘈杂的环境中使用,一个鲁棒的F0估计器[27]十分重要。
Harvest是为高质量的语音分析/合成系统和SPSS提出的。特别是,由于连续的F0建模[4]会给清音部分一定的F0, Harvest会尝试减少清音帧,给它一个可靠的F0。Harvest的基本思想是基于基于事件的F0估计器[28],并利用滤波提取基本成分[15]。它包括两个步骤:估计F0候选点和在这些候选点的基础上生成可靠的F0轮廓。
具体算法
第一步:F0候选值估计
目的:收集所有F0候选值,即使它们包含估计错误。在每帧中获得许多F0候选项及其可信度分数。

参数设置:
def harvest(x: np.ndarray, fs: int, f0_floor: int=71, f0_ceil: int=800, frame_period: int=5) -> dict:
basic_frame_period: int = 1 #1ms 用于计算候选值
target_fs = 8000
num_samples = int(1000 * len(x) / fs / basic_frame_period + 1)
basic_temporal_positions = np.arange(0, num_samples) * basic_frame_period / 1000
channels_in_octave = 40
f0_floor_adjusted = f0_floor * 0.9 #63.9
f0_ceil_adjusted = f0_ceil * 1.1 #880.00000000001
#把频率范围划分,作为中心频率
boundary_f0_list = np.arange(np.ceil(np.log2(f0_ceil_adjusted / f0_floor_adjusted) * channels_in_octave)) + 1
boundary_f0_list = boundary_f0_list / channels_in_octave
boundary_f0_list = 2.0 ** boundary_f0_list
boundary_f0_list *= f0_floor_adjusted
basic_frame_period=1ms,用于计算候选值,如3387帧
frame_period=5ms,将F0轮廓降采样5倍,降到3387/5=678帧
1.估计基本的F0候选值
首先,将语音波形输入到多个中心频率不同的带通滤波器进行滤波。滤波器h(t)由纳托尔窗w(t)与正弦波相乘。这与YANGsaf的想法相似。

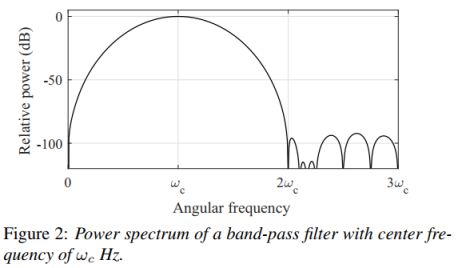
式中,ωc和Tc分别为滤波器的中心频率和周期(Tc = 2π/ωc)。滤波器的取值范围为−2Tc < t < 2Tc。功率谱的一个例子如图2所示。该滤波器可以提取基波分量,只要它包含在ωc Hz附近的范围内。将中心频率设置为从floor到ceiling每40ch/oct划分。
当只提取到基本分量时,输出信号波形正好为正弦波。此时,图3所示的波形四个间隔值相同(说明提到了基频或谐频)。四个间期的平均值的倒数,就是F0候选值。Harvest去除ωc±10%范围以外的估计候选值。

对应代码:
def CalculateCandidates(number_of_frames: int,
boundary_f0_list: np.ndarray, y_length: int, temporal_positions: np.ndarray, actual_fs: int, y_spectrum: np.ndarray,
f0_floor: int, f0_ceil: int) -> np.ndarray:
raw_f0_candidates = np.zeros((len(boundary_f0_list), number_of_frames))
for i in range(len(boundary_f0_list)):
raw_f0_candidates[i, :] = \
CalculateRawEvent(boundary_f0_list[i], actual_fs, y_spectrum,
y_length, temporal_positions, f0_floor, f0_ceil)
return raw_f0_candidates
能得到多少个候选值呢,boundary_f0_list个。根据设置的参数决定。
其中调用函数CalculateRawEvent:
def CalculateRawEvent(boundary_f0: float, fs: int, y_spectrum: np.ndarray, y_length: int, temporal_positions: np.ndarray, f0_floor: int, f0_ceil: int) -> np.ndarray:
filter_length_half = int(Decimal(fs / boundary_f0 * 2).quantize(0, ROUND_HALF_UP))
band_pass_filter_base = nuttall(filter_length_half * 2 + 1)
shifter = np.cos(2 * math.pi * boundary_f0 * np.arange(-filter_length_half, filter_length_half + 1) / fs)
band_pass_filter = band_pass_filter_base * shifter
index_bias = filter_length_half + 1
spectrum_low_pass_filter = np.fft.fft(band_pass_filter, len(y_spectrum))
filtered_signal = np.real(np.fft.ifft(spectrum_low_pass_filter * y_spectrum))
filtered_signal = filtered_signal[index_bias + np.arange(y_length)]
# calculate 4 kinds of event
neg_loc, neg_f0 = ZeroCrossingEngine(filtered_signal, fs)
pos_loc, pos_f0 = ZeroCrossingEngine(-filtered_signal, fs)
peak_loc, peak_f0 = ZeroCrossingEngine(np.diff(filtered_signal), fs)
dip_loc, dip_f0 = ZeroCrossingEngine(-np.diff(filtered_signal), fs)
f0_candidates = GetF0Candidates(neg_loc, neg_f0, pos_loc, pos_f0,
peak_loc, peak_f0, dip_loc, dip_f0, temporal_positions)
f0_candidates[f0_candidates > boundary_f0 * 1.1] = 0
f0_candidates[f0_candidates < boundary_f0 * 0.9] = 0
f0_candidates[f0_candidates > f0_ceil] = 0
f0_candidates[f0_candidates < f0_floor] = 0
return f0_candidates
2.从基本候选F0中再估计候选F0(筛选)
图4显示了语音框架中中心频率ωc和基本候选F0之间的关系。当基本候选F0来自基波分量时,在一定带宽内观察到相同的值(梯形上面),因为中心频率在wc附近的滤波器输出的几乎都是相同的波形。当滤波器在一定带宽内输出相同的基本F0候选时,Harvest获得候选F0。我们把这个带宽设为ωc ± 10% Hz。

对应代码:
def DetectCandidates(raw_f0_candidates: np.ndarray):
number_of_channels, number_of_frames = raw_f0_candidates.shape
f0_candidates = np.zeros((int(number_of_channels / 10 + 0.5), number_of_frames))
number_of_candidates = 0
threshold = 10
for i in np.arange(number_of_frames):
tmp = np.array(raw_f0_candidates[:, i])
tmp[tmp > 0] = 1
tmp[0] = 0
tmp[-1] = 0
tmp = np.diff(tmp)
st = np.where(tmp == 1)[0]
ed = np.where(tmp == -1)[0]
count = 0
for j in np.arange(len(st)):
dif = ed[j] - st[j]
if dif >= threshold:
tmp_f0 = raw_f0_candidates[st[j] + 1: ed[j] + 1, i]
f0_candidates[count, i] = np.mean(tmp_f0)
count += 1
number_of_candidates = max(number_of_candidates, count)
return f0_candidates, number_of_candidates
3.重叠F0候选值
由于该算法的精度取决于每帧的信噪比,因此由于噪声的影响,通常会出现没有候选帧的情况。Harvest将所有F0候选值重叠3毫秒。
如:图5显示了重叠效果的一个示例。圆圈和圆点分别代表F0候选点和重叠候选点。在这个例子中,第254毫秒的帧中没有候选帧,但是重叠可以弥补这个不足。接下来的过程中,所有的F0候选项都被细化并通过瞬时频率进行评分。

对应代码:
def OverlapF0Candidates(f0_candidates: np.ndarray, max_candidates: int) -> np.ndarray:
n = 3 # This is the optimzied parameter.
number_of_candidates = n * 2 + 1
new_f0_candidates = np.zeros((number_of_candidates * max_candidates, f0_candidates.shape[1]))
new_f0_candidates[0, :] = f0_candidates[number_of_candidates - 1, :]
for i in np.arange(number_of_candidates):
st1 = max(-(i - n) + 1, 1)
ed1 = min(-(i - n), 0)
new_f0_candidates[np.arange(max_candidates) + i * max_candidates, st1 - 1 : new_f0_candidates.shape[1] + ed1] = \
f0_candidates[np.arange(max_candidates), -ed1 : new_f0_candidates.shape[1] - (st1 - 1)]
return new_f0_candidates
4.对所有F0候选值通过瞬时频率进行细化
如图4所示,不仅对目标F0进行了估计,还对几个误差进行了估计。为了有效地选择目标F0, Harvest利用瞬时频率对所有候选F0进行细化和评分。
瞬时频率即波形相位的导数。采用Flanagan公式[31]计算瞬时频率ωi(ω,t):

其中S(ω, t)表示位移为t的窗函数,加窗的波形的频谱。Harvest使用Blackman窗,窗长为3T0,周期T0是候选值F0的倒数。R[x]和ζ[x]为输入信号x的实部和虚部。
周期信号的瞬时频率是指频率在F0附近时接近F0的值。由于F0附近的频谱具有更大的功率,因此这种细化比通过滤波提取基本分量更健壮。因此,即使候选F0包含一定数量的噪声误差,也可以将F0细化为更精确的F0。
实际的细化是用下面的公式进行的。在时间位置t处的细化F0候选值ω0:

其中ω0表示候选值F0在时间位置t的角频率,K表示用于细化的谐波数。由于语音具有谐波结构,使用一些谐波成分有助于语音的细化。在Harvest中将谐波K的个数设置为6。
细化前的候选F0等于目标F0的情况下,候选F0和细化后的候选F0表示相同的值。同理,ωi(kω0, t)表示kω0。因此,它们之间的差异可以用作可靠性评分。分数r为:

在此处理过程中,分数低于2.5的F0候选值将被删除。
对应代码:
def RefineCandidates(x: np.ndarray, fs: float, temporal_positions: np.ndarray,
f0_candidates: np.ndarray, f0_floor: float, f0_ceil: float) -> tuple:
new_f0_candidates = copy.deepcopy(f0_candidates)
f0_candidates_score = f0_candidates * 0
N, f = f0_candidates.shape
if 1: # parallel
frame_candidate_data = [(x, fs, temporal_positions[i], f0_candidates[j, i], f0_floor, f0_ceil)
for j in np.arange(N)
for i in np.arange(f)]
with mp.Pool(mp.cpu_count()) as pool:
results = np.array(pool.starmap(GetRefinedF0, frame_candidate_data))
new_f0_candidates = np.reshape(results[:, 0], [N, f])
f0_candidates_score = np.reshape(results[:, 1], [N, f])
else:
# old one
for i in range(f):
for j in range(N):
new_f0_candidates[j,i], f0_candidates_score[j,i] = GetRefinedF0(x, fs, temporal_positions[i], f0_candidates[j,i], f0_floor, f0_ceil)
return new_f0_candidates, f0_candidates_score
用到GetRefinedF0函数:
#@numba.jit((numba.float64[:], numba.float64, numba.float64, numba.float64, numba.float64, numba.float64), nopython=True, cache=True)
def GetRefinedF0(x: np.ndarray, fs: float, current_time: float, current_f0: float, f0_floor: float, f0_ceil: float) -> tuple:
if current_f0 == 0:
return 0, 0
half_window_length = np.ceil(3 * fs / current_f0 / 2)
window_length_in_time = (2 * half_window_length + 1) / fs
base_time = np.arange(-half_window_length, half_window_length + 1) / fs
fft_size = int(2 ** np.ceil(np.log2((half_window_length * 2 + 1)) + 1))
# First-aid treatment
index_raw = round_matlab((current_time + base_time) * fs + 0.001)
common = math.pi * ((index_raw - 1) / fs - current_time) / window_length_in_time
main_window = 0.42 + 0.5 * np.cos(2 * common) + 0.08 * np.cos(4 * common)
diff_window = np.empty_like(main_window)
diff_window[0] = - main_window[1] / 2
diff_window[-1] = main_window[-2] / 2
diff = np.diff(main_window)
diff_window[1:-1] = - (diff[1:] + diff[:-1]) / 2
index = (np.maximum(1, np.minimum(len(x), index_raw)) - 1).astype(np.int)
spectrum = fft(x[index] * main_window, fft_size)
diff_spectrum = fft(x[index] * diff_window, fft_size)
numerator_i = spectrum.real * diff_spectrum.imag - spectrum.imag * diff_spectrum.real
power_spectrum = np.abs(spectrum) ** 2
instantaneous_frequency = (np.arange(fft_size) / fft_size + numerator_i / power_spectrum / 2 / math.pi) * fs
number_of_harmonics = min(np.floor(fs / 2 / current_f0), 6) # with safe guard
harmonic_index = np.arange(1, number_of_harmonics + 1)
index = round_matlab(current_f0 * fft_size / fs * harmonic_index).astype(np.int)
instantaneous_frequency_list = instantaneous_frequency[index]
amplitude_list = np.sqrt(power_spectrum[index])
refined_f0 = np.sum(amplitude_list * instantaneous_frequency_list) / np.sum(amplitude_list * harmonic_index)
variation = np.abs(((instantaneous_frequency_list / harmonic_index) - current_f0) / current_f0)
refined_score = 1 / (0.000000000001 + np.mean(variation))
if refined_f0 < f0_floor or refined_f0 > f0_ceil or refined_score < 2.5:
refined_f0 = 0
refined_score = 0
return refined_f0, refined_score
第二步:在估计候选F0的基础上生成最佳F0轮廓
在第一步中,每帧得到多个F0候选值。第二步的目的是从所有候选F0中生成可靠的F0轮廓。首先,选取可靠性最高的F0候选轮廓作为基本F0轮廓。
代码:
def FixF0Contour(f0_candidates: np.ndarray, f0_candidates_score: np.ndarray) -> tuple:
f0_base = SearchF0Base(f0_candidates, f0_candidates_score)
f0_step1 = FixStep1(f0_base, 0.008) # optimized
f0_step2 = FixStep2(f0_step1, 6) # optimized
f0_step3 = FixStep3(f0_step2, f0_candidates, 0.18, f0_candidates_score) # optimized
f0 = FixStep4(f0_step3, 9) # optimized
vuv = copy.deepcopy(f0)
vuv[vuv != 0] = 1
return f0, vuv
调用SearchF0Base函数:
# F0s with the highest score are selected as a basic f0 contour.
def SearchF0Base(f0_candidates: np.ndarray, f0_candidates_score: np.ndarray) -> np.ndarray:
f0_base = np.zeros((f0_candidates.shape[1]))
for i in range(len(f0_base)):
max_index = np.argmax(f0_candidates_score[:, i])
f0_base[i] = f0_candidates[max_index, i]
return f0_base
1.删除不需要的候选F0
由于浊音是周期信号,根据F0的定义,F0轮廓在一个基本周期内不会发生快速变化。因此将超过阈值的快速变化的F0删除,并将此帧计算为清音部分。图6显示了可以算作浊音部分的频率范围。

N ms内的频率范围由N−1和N−2 ms处的F0s决定。两个频率f1和f2分别计算为f0(N−1)和2f0(N−1)- f0(N−2)。如果N ms的F0候选值不在f1±0.8%或f2±0.8%的范围内,则将其移除。
对应代码:
# Step 1: Rapid change of f0 contour is replaced by 0
@numba.jit((numba.float64[:], numba.float64), nopython=True, cache=True)
def FixStep1(f0_base: np.ndarray, allowed_range: float) -> np.ndarray:
f0_step1 = np.empty_like(f0_base)
f0_step1[:] = f0_base
f0_step1[0] = 0
f0_step1[1] = 0
for i in np.arange(2, len(f0_base)):
if f0_base[i] == 0:
continue
reference_f0 = f0_base[i - 1] * 2 - f0_base[i - 2]
if np.abs((f0_base[i] - reference_f0) / (reference_f0 + EPS)) > allowed_range and \
np.abs((f0_base[i] - f0_base[i - 1]) / (f0_base[i - 1] + EPS)) > allowed_range:
f0_step1[i] = 0
return f0_step1
2.去除过短的浊音部分
F0轮廓至少具有基本周期的长度,并且噪声可能偶然导致具有短周期的连续F0。长度低于阈值的短浊音段将被删除并计算为非浊音段。我们将阈值设置为6毫秒,以便删除不需要的部分。
对应代码:
# Step 2: Voiced sections with a short period are removed
def FixStep2(f0_step1: np.ndarray, voice_range_minimum: float):
f0_step2 = np.empty_like(f0_step1)
f0_step2[:] = f0_step1
boundary_list = GetBoundaryList(f0_step1)
for i in np.arange(1, len(boundary_list) // 2 + 1):
distance = boundary_list[2 * i - 1] - boundary_list[(2 * i) - 2]
if distance < voice_range_minimum:
f0_step2[boundary_list[(2 * i) - 2] : boundary_list[2 * i - 1] + 1] = 0
return f0_step2
3.扩展每个浊音部分
每个浊音部分通过使用清音部分的F0候选值扩展。用浊音帧N ms处的F0候选值来确定清音帧N + 1 ms处的F0。如果在N + 1 ms时最接近的候选f0包含在f0 (N)±18%的范围内,则选择并扩展为浊音帧。如果在N + 1 ms内没有F0候选,则在下一帧N + 2 ms内进行相同的处理。如果在N + 1 ~ N + 3ms内没有F0候选节点,则扩展过程结束。最大扩展限制为100ms。
这种扩张是在前后方向上进行的。扩展后harvest会再次移除短浊音部分。阈值设置为2200 / fms,其中f是浊音部分F0s的平均值。当扩展的F0等高线重叠时,选择重叠部分中平均可靠度得分较高的F0等高线。
对应代码:
# Step 3: Voiced sections are extended based on the continuity of F0 contour
def FixStep3(f0_step2: np.ndarray, f0_candidates: np.ndarray, allowed_range: float, f0_candidates_score: np.ndarray) -> np.ndarray:
f0_step3 = np.array(f0_step2)
boundary_list = GetBoundaryList(f0_step2)
multi_channel_f0 = GetMultiChannelF0(f0_step2, boundary_list)
range = np.zeros((len(boundary_list) // 2, 2))
threshold1 = 100
threshold2 = 2200
count = -1
for i in np.arange(1, len(boundary_list) // 2 + 1):
tmp_range = np.zeros(2)
# Value 100 is optimized.
extended_f0, tmp_range[1] = ExtendF0(multi_channel_f0[i - 1, :], boundary_list[i * 2 - 1], min(len(f0_step2) - 2,
boundary_list[i * 2 - 1] + threshold1), 1, f0_candidates, allowed_range)
tmp_f0_sequence, tmp_range[0] = ExtendF0(extended_f0, boundary_list[(i * 2) - 2],
max(1, boundary_list[(i * 2) - 2] - threshold1), -1, f0_candidates, allowed_range)
mean_f0 = np.mean(tmp_f0_sequence[int(tmp_range[0]) : int(tmp_range[1]) + 1])
if threshold2 / mean_f0 < tmp_range[1] - tmp_range[0]:
count += 1
multi_channel_f0[count, :] = tmp_f0_sequence
range[count, :] = tmp_range
multi_channel_f0 = multi_channel_f0[0 : count + 1, :]
range = range[0 : count + 1, :]
if count > -1:
f0_step3 = MergeF0(multi_channel_f0, range, f0_candidates, f0_candidates_score)
return f0_step3
4.F0轮廓的插值和平滑
因为Harvest的目的之一是防止浊音部分被误识别为清音部分,短清音部分被修改为F0s。将9 ms周期内的非浊音部分作为浊音,该部分的f0由其边界的前后浊音部分的f0之间的线性插值得到。
连接的F0轮廓在每个浊音部分通过零延时巴特沃斯滤波器平滑。清音部分中的f0由每个边界中的f0填充。平滑后,清音部分的F0被重置为0。平滑结果也是Harvest估计的最终F0轮廓。我们将滤波器的阶数设置为2,截止频率设置为30 Hz。
对应代码:
# Step 4: F0s in short unvoiced section are faked
def FixStep4(f0_step3: np.ndarray, threshold:float) -> np.ndarray:
f0_step4 = np.empty_like(f0_step3)
f0_step4[:] = f0_step3
boundary_list = GetBoundaryList(f0_step3)
for i in np.arange(1, len(boundary_list) // 2 ):
distance = boundary_list[2 * i] - boundary_list[2 * i - 1] - 1
if distance >= threshold:
continue
tmp0 = f0_step3[boundary_list[2 * i - 1]] + 1
tmp1 = f0_step3[boundary_list[2 * i]] - 1
c = (tmp1 - tmp0) / (distance + 1)
count = 1
for j in np.arange(boundary_list[2 * i - 1] + 1, boundary_list[2 * i]):
f0_step4[j] = tmp0 + c * count
count += 1
return f0_step4