【网安专题10.25】10 TitanFuzz完全自动化执行基于变异的模糊测试:生成式(如Codex)生成种子程序,逐步提示工程+第一个应用LLM填充模型(如InCoder)+差分测试
Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models
- 写在最前面
-
- 可学习借鉴的思路
- 进一步创新
- 概述
- 背景
-
- 深度学习
-
- LLM类型(如图3所示)
- 问题背景
-
- 第一类:API级模糊测试
- 第二类:模型级模糊测试(model-level)
- Bugs in DL Libraries DL库中的bug
-
- a
- b
- 方法: TitanFuzz
-
- 3.1 生成种子
- 3.2 种子演化
-
- 算子定义
- 算子选择
- 生成用例
- 适应度分数
- 3.3 Oracle测试
- 实验
-
- 实验设置
-
- 种子生成:
- 模糊测试:
- 实验对象:
- 实验环境:
- 评估指标:
- 实验结果(部分)
-
- RQ1:与之前的工作比较 表1:API覆盖率比较
- R1Q 表2:与现有最佳技术的比较
- RQ2:关键部件评估 表3:突变符的消融实验
- RQ3:检测到的bug 表7:检测到的bug汇总
- 总结
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
张和禹同学分享了University of IllinoisUrbana-Champaign伊利诺伊大学厄巴纳 香槟分校团队的
Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models《大语言作为零样本模糊器:使用LLM模糊测试深度学习库 》
ISSTA 2023- International Symposium on Software Testing and Analysis
论文:https://dl.acm.org/doi/abs/10.1145/3597926.3598067
代码:https://github.com/ise-uiuc/TitanFuzz
2023/7/12 18:13 Recent Fuzzing Paper
张和禹同学建议我看原文,当我看原文时发现确实很有意思,设计精巧
但工作量好大,比如生成进化变异算子、β -伯努利强盗问题中平衡开发和探索的权衡,利用了经典的汤普森采样(TS)算法
推荐阅读原文

可学习借鉴的思路
-
应用大型预训练语言模型:TitanFuzz使用了大型预训练语言模型来生成和变异测试程序,这种方法不仅适用于深度学习库的测试,还可以应用于其他领域,如软件测试、自然语言处理、自动化代码生成等。研究人员可以考虑在其他领域中使用预训练语言模型来改进测试和质量保证方法。
-
结合生成和进化算法:TitanFuzz结合了生成式和进化算法来生成和变异测试程序,这种方法可以在其他自动化测试领域中使用。研究人员可以探索如何结合生成和进化算法以改进测试用例的生成和变异。
-
基于差分测试的错误检测:TitanFuzz使用差分测试Oracle在不同后端上运行生成的代码片段,以检测错误。这个思路可以应用于其他领域,例如软件测试、硬件测试和安全性研究,以帮助发现和修复潜在的问题。
-
使用MAB算法进行变异操作符选择:TitanFuzz使用汤普森抽样算法来选择变异操作符,以平衡探索和利用的权衡。这种多臂赌博机算法可以在其他领域中用于选择最佳的操作或策略。
-
评估和比较性能:TitanFuzz进行了广泛的评估和性能比较,这个方法可以在其他研
进一步创新
领域:深度学习库的测试和质量保证领域。
在这篇论文的基础上,进一步探索和创新,以提高深度学习库的质量和可靠性。
-
改进深度学习库的质量保证方法:后续研究可以建立在TitanFuzz的基础上,进一步改进深度学习库的质量保证方法,包括增加测试覆盖率、发现更多的错误和漏洞,以提高库的稳定性和可靠性。
-
探索其他预训练语言模型的应用:TitanFuzz使用了Codex和InCoder这两种大型预训练语言模型,后续研究可以探索其他预训练语言模型的应用,以比较它们在模糊测试中的性能和效果。
-
深度学习库的安全性研究:这篇论文主要关注了质量保证方面,后续研究可以进一步探讨深度学习库的安全性,包括发现潜在的安全漏洞和防御机制的开发。
-
应用于其他领域的自动化测试:TitanFuzz的方法可以被应用于其他领域的自动化测试,例如软件工程、自然语言处理等,后续研究可以研究其在这些领域的适用性和性能。
-
深度学习库测试工具的开发:基于TitanFuzz的思想,后续研究可以开发深度学习库测试工具,以帮助研究人员和开发人员提高他们的测试和质量保证流程。
概述
TitanFuzz:第一个应用填充模型(例如InCoder)直接执行基于变异的模糊测试
使用大型预训练语言模型进行深度学习库的模糊测试
背景
深度学习库(TensorFlow和Pytorch)中的bug对下游任务系统是重要的,保障安全性和有效性。
在深度学习(DL)库的模糊测试领域,直接生成满足输入语言(例如Python)语法/语义和张量计算的DL API输入/形状约束的深度学习程序具有挑战性。
此外,深度学习API可能包含复杂的输入条件约束,难以在没有人工干预的情况下生成符合条件的输入用例。
解决方案
为了解决这些问题,本论文提出了一种全自动方法称为“TitanFuzz”,它是首个使用大型预训练语言模型(LLMs)对DL库进行模糊化的方法。该方法包括以下步骤:
-
生成初始种子程序:首先,使用生成式LLM产生模糊测试的初始种子程序。
-
自动变异程序:然后,使用多个变异算子和LLMs来自动变异种子程序,生成新的测试程序。
-
设计适应函数:设计一个适应函数,
根据数据依赖深度和唯一库API的数量对种子或变异测试程序进行优先级排序。这有助于“TitanFuzz”能够发现仅在研究复杂API关系时才能发现的Bug。 -
差分测试:最后,对生成的测试程序在不同的后端执行差分测试,以检测Bug。
实验结果
根据实验结果,TitanFuzz在TensorFlow和PyTorch上取得了显著的成果:
-
TitanFuzz的代码覆盖率分别比传统的模糊测试高30.38%和50.84%。
-
TitanFuzz能够检测到65个Bug,其中44个已经被确认为以前未知的Bug。
这些结果表明TitanFuzz是一种有潜力的工具,LLM可以直接执行基于生成和基于突变的模糊测试,完全自动化可通用性,可用于改进深度学习库的质量和可靠性,尤其是在处理复杂API和输入条件约束时。
背景
深度学习
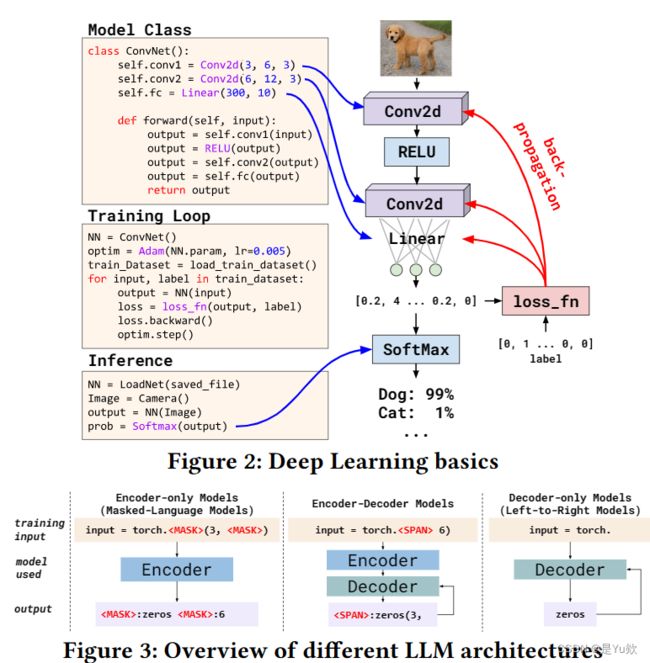
大型预训练语言模型(LLM)的架构和应用,特别是在与编程和代码相关的任务中的应用。
-
LLM架构:大型预训练语言模型通常采用Transformer架构,分为编码器和解码器。编码器用于生成输入的编码表示,而解码器用于生成输出令牌。
-
预训练和下游任务:LLM在数十亿可用文本上进行预训练,然后可以应用于各种自然语言处理(NLP)任务。通过提示工程,LLM可以在不需要专门数据集微调的情况下直接用于特定数据集的下游任务,以提高性能。
-
LLM类型:根据模型架构和预训练任务,LLM可以分为三种类型:仅解码器模型,仅编码器模型,和编码器-解码器模型。这些模型在不同的任务上表现出色,如代码完成、代码合成和自动程序修复。
-
生成和填充任务:LLM可以执行两种主要类型的代码生成任务,包括生成式任务和填充任务。生成式任务涉及在给定左侧上下文的情况下自动完成完整的代码片段,通常使用仅解码器模型。填充任务旨在插入基于双向上下文的最自然的代码,可以使用不同类型的模型来完成,例如仅编码器、编码器-解码器和InCoder。
-
突变和程序生成:文本中提到了使用填充模型来执行突变任务,即通过替换输入程序的一小部分来生成更多样化的程序。这有助于生成多样性的代码。
LLM类型(如图3所示)
-
仅解码器模型:
- 特点:解码器被用于生成输出令牌,通常根据所有先前的令牌来预测下一个令牌的概率。
- 应用:这些模型适用于生成式任务,例如在给定左侧上下文(例如一些起始代码或自然语言描述)的情况下自动完成完整的代码片段。它们可以执行自动补全,生成连贯的文本或代码。
-
仅编码器模型:
- 特点:只使用编码器组件,旨在提供输入的表示,而不生成输出令牌。
- 应用:这些模型通常在预训练过程中使用蒙面语言模型(MLM)目标,其中一定比例的标记被蒙面,任务是根据前后的上下文恢复这些蒙面标记的真实值。它们适用于填充任务,例如插入基于双向上下文的最自然的代码,使代码连贯性更高。
-
编码器-解码器模型:
- 特点:这些模型通常使用掩码跨度预测(MSP)目标进行训练,其中一系列令牌被替换为掩码跨度令牌,然后模型需要在训练期间恢复整个序列。
- 应用:编码器-解码器模型可以用于生成式任务,类似于仅解码器模型,同时也适用于填充任务,因为它们可以使用前后的上下文来填充中间的代码。这些模型在多个领域,包括自然语言处理和代码生成任务中表现出色。
问题背景
在以往的研究中,关于模糊深度学习库的工作主要可以分为两个类别:
第一类:API级模糊测试
API级模糊测试侧重于通过为每个目标API生成各种不同的输入,以测试单个库API,从而发现潜在的崩溃或结果不一致的问题。
然而,这一方法存在一些问题:
-
缺乏多样化的API序列:目前的
API级模糊测试方法主要关注对每个深度学习库的单个API进行模糊测试[16,72]。这些技术试图通过简单的变异规则为特定的目标API创建许多不同的输入。
然而,这些输入通常由单个代码行构建,最多是一个库API创建的输入,例如,随机初始化具有特定数据类型和形状的张量,因此无法揭示由链式API序列引起的错误。 -
无法生成任意代码:某些方法,如FreeFuzz[72],首先通过挖掘开源代码片段来收集目标API的有效参数空间,例如输入张量的类型和形状。
在模糊循环期间,FreeFuzz将对这些有效输入进行小的突变以生成新的输入,例如,更改数据类型,如从float32到float16。
然而,这种方法受到跟踪参数空间和预定义突变规则的限制,无法生成任意代码。
以上问题表明,现有的API级模糊测试方法在测试深度学习库时存在一些限制,无法有效地揭示由多个API序列调用引起的错误。因此,需要一种新的方法来克服这些问题,以提高深度学习库的测试质量。
[16] Yinlin Deng, et al. 2022. Fuzzing Deep-Learning Libraries via Automated Relational API Inference. ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2022).
[72] Anjiang Wei, et al. 2022. Free Lunch for Testing: Fuzzing Deep-Learning Libraries from Open Source. In 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE).
第二类:模型级模糊测试(model-level)
模型级模糊测试技术的主要目标是生成各种不同的深度学习模型,然后比较这些模型在不同后端(例如Keras)上的输出,以发现潜在的错误。
然而,这一方法也存在一些问题:
-
缺乏多样化的API序列:模型级模糊测试器只能涵盖一组有限模式的API,无法充分覆盖许多可能导致错误的多样化API序列。举例来说,某些工具如LEMON[71]的层(layer)添加规则无法应用于具有不同输入和输出形状的层,或者Muffin[25]需要手动注释考虑的深度学习API的输入/输出限制,并使用额外的整形(reshaping)操作来确保有效的连接。
-
无法生成任意代码:类似于上述问题,模型级模糊测试工具,如Muffin[25],需要手动生成不同的模型,为每个被操作的深度学习API和预定义的代码结构注释规范,以维持模型的有效性。因此,这些先前的深度学习库模糊测试工具无法完全探索使用深度学习库API时存在的庞大搜索空间。
这些问题表明,现有的模型级模糊测试方法在测试深度学习库时也存在一些限制,无法充分覆盖多样性的API序列和无法生成任意代码,从而限制了其测试能力。因此,需要开发新的方法以解决这些问题,以提高深度学习库的测试质量。
[25] J. Gu, et al. 2022. Munffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing. In 2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE).
[71] Zan Wang, et al. 2020. Deep learning library testing via effective model generation. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering.
Bugs in DL Libraries DL库中的bug
a

创建了一个随机输入,可能包含负数
正常:log函数应该为负数产生NaN(Not a Number)
CPU调用matrix_exp时,它也应该包含NaN值
但是在GPU上运行此代码时,它不会输出任何NaN值
该bug只会在“log传递给matrix_exp”时才会在GPU上出现,如果定义了中间变量不会出现该bug。因此:
- 以前的API级模糊器无法找到此bug,因为该bug涉及API嵌套调用;
- 模型级模糊器也几乎无法检测到此bug。因为日志后跟matrix_exp的特定序列很少用于构建DL模型,尤其是构建Conv2d或MaxPool2d很少用。
b

创建向量:包含0和-0
Bug:在CPU上计算时分正负号,导致分别出现正/负无穷(INF)
正常:在GPU上计算时不分正负号,1除以零出现正无穷(INF)
- 图B展示了一个在PyTorch中的错误,之前的模糊测试技术无法检测到。
- 这个错误是由
clamp函数在CPU上未将负零限制为正零引起的。 - 尽管这个错误是由单个API引起的,但之前的技术无法检测到这个错误,因为负零几乎等于零。
- 当我们将1除以被限制的列表时,这个错误会显现出来,正确的值应该是正无穷而不是负无穷(值的差异显著)。
- 这种Python基本表达式通常与库API结合使用,但由于现有API级和模型级技术的生成方法的限制,之前的工作未能发现这个错误。
方法: TitanFuzz
TitanFuzz是一种基于生成式语言模型(LLM)的演化模糊测试方法,旨在改进深度学习库的测试质量。
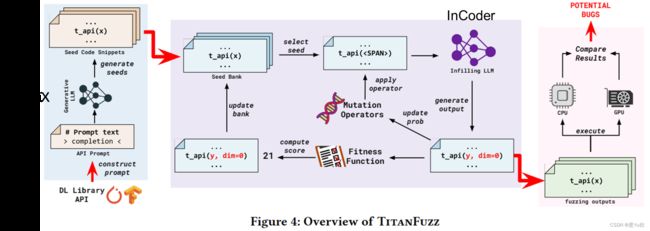
它的工作流程包括以下步骤:
Step 1:
- 通过为目标API提供逐步提示,生成直接使用目标API的代码片段。
Step 2:
- 使用进化模糊算法,迭代生成新的代码片段。
- 这一过程包括选择具有高适应度得分的种子程序,并使用不同的变异操作替换选定种子程序的部分,从而生成具有掩码输入的变异体。
- 利用LLMs的填充能力,将掩码标记替换为新代码,生成具有不同输入的变异体。
Step 3:
- 最后,使用差分测试(differential testing oracle),在不同的执行后端(CPU/GPU)上运行所有生成的程序,以识别潜在的错误。
这一方法的关键优势在于结合了生成式语言模型的能力和进化模糊测试算法,以生成多样化的测试用例并检测深度学习库中的潜在错误。通过迭代生成和测试新代码片段,TitanFuzz有望提高深度学习库的鲁棒性和质量。
3.1 生成种子


图5中展示了提示(prompt)和模型输出的示例。这些提示的构建过程如下:
- 在提示(prompt)中,任务描述被包装在一个文档字符串下面。
-
- 提示中包括了目标库(如TensorFlow)和目标API定义(如tf.nn.conv2d(…))。
- API定义是通过爬虫从官方文档中自动获取的,以确保准确性和一致性。
-
- 提示还设计了一个分步指令,如图中的Task 1, 2, 3 等,以提高模型的性能。
- 这些任务按顺序执行,包括(1)导入目标库;(2)生成输入数据;(3)调用目标API。
- 构建的提示被用作Codex的初始输入,原始种子程序则通过从Codex中采样自动完成来获得。
这一方法旨在为生成式语言模型提供明确的上下文,以更准确地生成代码或执行任务,确保生成的代码符合任务要求和目标API的定义。这有助于提高生成式语言模型的性能和可用性。
3.2 种子演化

下面是关于生成种子库和进化模糊测试算法的流程的描述:
-
使用Codex生成的种子(第2行)初始化种子库。种子库用于维护到目前为止已经生成的代码片段列表。
-
初始化每个突变算子的先验分布,这些分布将在选择突变算子的主循环中使用和更新(第3行)。
-
在进入生成循环之前,根据适应度得分(fitness score)选择当前的种子进行变异(第5行)。种子的选择过程如下:首先选择适应度得分高的前N个种子,然后对它们的精确适应度得分执行softmax操作,以确定选择每个种子的概率。
-
决定在选定的种子上应用哪种变异操作符(第6行)。由于在帮助模型生成有效变异方面表现良好的变异操作符对于不同的目标API可能是不同的,因此使用Multi-Armed Bandit(MAB)算法动态学习操作符优先级策略。
-
每个变异操作符将使用特殊的标记(标记,第7行)来屏蔽当前种子程序的一个或多个片段。
-
随后,屏蔽的输入将被馈送到InCoder模型中,以采样填充屏蔽区域的代码片段(第8行)。
-
对于生成的每个样本,运行并静态分析代码片段(第9行)。具体而言,确定可以编译的代码片段(ValidSamples)。然后,根据它生成的有效和无效样本数量,更新变异操作符的后验分布(第10行)。
-
对于每个有效样本,使用适应度函数(FitnessFunction)计算适应度分数,该函数旨在优先选择具有不同API之间高数量的唯一交互的多样化种子,从而能够发现更多潜在的错误。
-
使用适应度分数,将这些样本添加到种子库中,以供下一轮种子选择使用(第12行)。
-
最后,当时间预算用尽时,终止生成过程,并返回种子库,其中包含使用目标API的多个唯一代码片段。
这一方法通过不断迭代生成、变异、和测试代码片段,以发现深度学习库中的潜在错误,提高测试质量和库的鲁棒性。
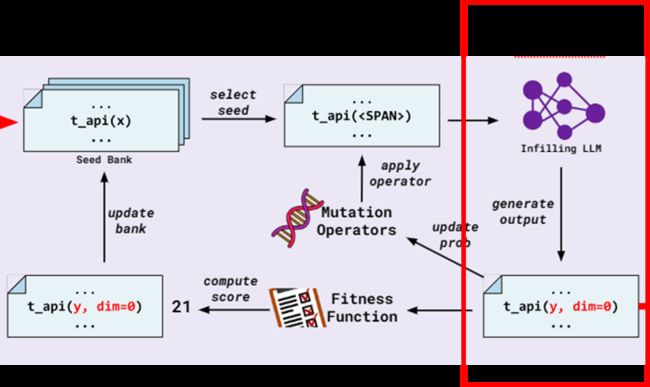
算子定义

作者定义了四种变异算子,它们是参数(argument)、前缀(prefix)、后缀(suffix)和方法(method)。这些变异操作符的作用如下:
-
参数(argument):这个变异操作符将选择目标API调用中的参数,并替换它们为掩码标记()。通过这种方式,可以在代码中替换参数,改变API调用的输入数据。
-
前缀(prefix):前缀变异操作符将在目标API调用之前插入代码片段,并用掩码标记替换一部分目标API调用的前缀。这可以在调用API之前执行其他操作,以改变程序行为。
-
后缀(suffix):后缀变异操作符与前缀操作符相似,但是它在目标API调用之后插入代码片段,并用掩码标记替换一部分目标API调用的后缀。这可以在API调用后执行其他操作。
-
方法(method):方法变异操作符替换目标API调用为一个新的API调用,这个新API调用通常是与目标API相似,但具有不同的行为。这可以改变程序中的API调用,从而引入不同的行为。
这些变异操作符通过识别目标API调用中的代码位置,将其替换为掩码标记(),然后利用语言模型的能力,生成替代掩码标记的代码片段。这种方法有助于生成具有独特且不同行为的代码,以进行模糊测试,以便更全面地测试目标API。
算子选择

变异算子选择问题: 伯努利赌博机Bernoulli Bandit 问题建模
在TitanFuzz中,解决变异操作符选择问题时,作者采用了Bernoulli Bandit问题建模的方法。Bernoulli Bandit是一种多臂赌博机(MAB)问题,其中每个臂代表一个潜在的操作,其成功或失败的结果由未知的成功概率决定。作者使用了经典的汤普森抽样算法(TS),以平衡探索和利用的权衡,来选择最有效的变异操作符,以生成有效且独特的代码片段。
此外,作者还采用了Beta-Bernoulli Bandit模型,这是一种概率模型,用于解决多臂赌博机问题,其中每个臂代表一个未知的成功概率。
在该模型中,作者使用了贝叶斯框架,并将贝塔分布作为先验,通过观察成功或失败的结果来更新每个臂的后验分布。
这种模型用于选择适合生成代码的变异操作符,以提高生成有效和独特代码片段的能力。
对于TitanFuzz来说,每个变异操作符可以被视为一个带有未知预期成功概率的“臂”,该概率定义为使用变异操作符生成的代码片段的独特通过率(与历史生成的代码片段不同且有效)。
当进行变异操作符选择时,在时间,“玩”一个“臂”意味着应用变异操作符生成程序,验证它们,并将每个程序的执行状态解释为成功或失败。这个方法帮助TitanFuzz动态学习哪些变异操作符在生成有效和独特代码片段方面表现最佳,以提高深度学习库的测试质量。

m.S:m变异成功计数;
m.F:m变异失败计数
变异算子选择算法使用了经典的汤普森抽样(TS)算法来平衡探索和开发的权衡,以选择最有效的变异操作符。以下是该算法的执行过程:
-
初始化每个变异操作符的成功次数.S和失败次数.F为1(第2-3行)。这意味着每个操作的先验分布被假设为Beta(1, 1),即均匀分布。
-
在观察到.S-1次成功和.F-1次失败后,更新操作的后验分布为Beta(.S, .F)。
-
为了选择一个操作(arm),从每个操作的后验分布中抽取一个样本(第6行),然后选择具有最大样本值的操作(表示它具有最高的成功率概率)。
-
在使用LLMs生成代码后,根据生成的程序的执行状态,更新所选择的变异操作的后验分布(第10-11行)。与随机选择变异操作相比,这种方法可以帮助识别有助于生成更有效和独特代码片段的变异操作。
-
需要注意的是,最佳的变异操作可能因不同的目标API而异,因此为每个针对一个API的演化模糊测试的端到端运行开始一个单独的MAB游戏,并重新初始化操作符的先验分布。
这个算法的目的是动态学习哪些变异操作符在生成有效和独特代码片段方面表现最佳,以提高深度学习库的测试质量。汤普森抽样算法有助于在选择操作时权衡探索新操作和利用已知操作的经验,从而提高了测试的效率和有效性。
生成用例
使用InCoder大模型填充部分,生成模糊测试用例
InCoder模型的损失函数

适应度分数
静态分析被用来计算每个测试程序的适应度分数,以帮助选择最有前途的变异程序。适应度计算的目标是根据以下特征为生成的变异程序赋予适应度分数:
-
数据流图的深度:静态分析代码片段内变量的数据流,以构建一个数据流图,其中每个边代表两个操作之间的数据依赖关系。数据流图的深度(D)定义为图的任何路径中的最大边数。较深的数据流图表示更复杂的数据流关系。
-
API调用的数量:计算每个代码片段中存在的唯一库API调用的数量(U)。由于生成的代码片段可能包含重复的代码行,还计算和惩罚使用相同输入(R)多次调用库API的数量。

根据TitanFuzz的适应度计算公式,这个模糊测试工具更倾向于生成包含长链API序列和更多独特API调用的代码片段。这样可以增加覆盖不同API之间的交互,有望引发更有趣的程序行为或错误。这种策略有助于提高测试的全面性和深度。
然而,仅追求长链API序列和更多独特API调用可能导致测试效率下降,因为会涵盖越来越长的API序列,还可能导致重复调用API,增加测试的计算负担。
为解决这个问题,TitanFuzz采取进一步的措施,惩罚重复API调用的序列。这意味着如果同一API在代码片段中多次重复调用,那么这些额外的重复调用会减少代码片段的适应度分数,从而鼓励生成更多多样化的API调用,提高测试效率和效力。这种权衡和惩罚机制有助于保持模糊测试过程的效率,并确保生成的代码片段既具有高适应度,又不过分依赖重复调用API。
3.3 Oracle测试
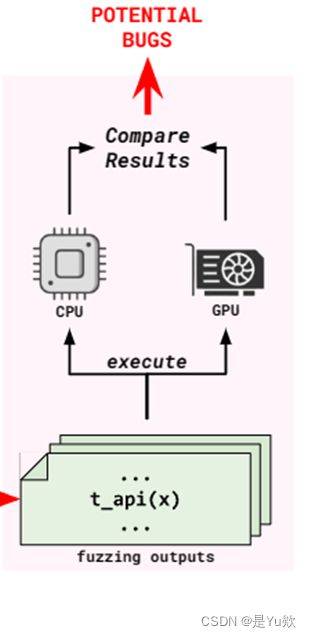
TitanFuzz利用差分测试Oracle在两个独立的后端(CPU和GPU)上运行生成的代码片段,以检测潜在的错误。主要关注以下两种错误类型:
-
Wrong-Computation(错误计算):这种错误类型涉及比较两个执行后端上所有中间变量的值,并在值显著不同时找到错误计算。由于某些计算的非确定性特性可能导致CPU和GPU上的结果略有不同,为了区分真正的错误和非关键差异,TitanFuzz使用容差阈值来检查值是否显著不同。计算值的差异可能表明库API的不同后端实现或不同API之间的交互存在潜在的语义错误。
-
Crash(崩溃):在程序执行期间,TitanFuzz还会检测到意外的崩溃,例如分段错误、中止、INTERNAL_ASSERT_FAILED错误等。这些崩溃表明无法检查或处理无效输入或极端情况,可能导致安全风险。
通过在不同后端上运行生成的代码片段,并使用差分测试Oracle来检测上述错误类型,TitanFuzz能够发现潜在的问题和漏洞,从而提高深度学习库的质量和稳定性。
实验
实验设置
种子生成:
- 种子生成使用Codex模型,其中针对每个API采样25个程序。
- Codex模型引擎为code-davinci-002。
- 默认采用top-(nucleus)采样策略,其中=0.95。
- 最大令牌数为256,时间参数为0.4。
- 由于生成的程序可能以不完整的行结束,迭代地删除每个程序的最后一行,直到语法解析成功。
模糊测试:
- 在模糊测试中,种子选择策略为 = 10。
- 使用Hugging Face上的InCoder 1.3B模型的PyTorch实现。
- 默认的InCoder参数为temperature=1,top-=0.95。
- 应用代码过滤以删除模型生成的不必要代码,例如打印语句。
- 执行数据流分析以进行死代码消除。
实验对象:
- TensorFlow 2.10
- PyTorch 1.12
实验环境:
- 64核工作站,拥有256 GB RAM和4个NVIDIA RTX A6000 GPU。
- 操作系统为Ubuntu 20.04.5 LTS。
- 使用coverage.py工具来测量Python代码覆盖率。
评估指标:
- 检测到的漏洞数量
- 代码覆盖率
- 被覆盖的API数量
- 执行时间
这些设置和指标用于评估TitanFuzz的性能和有效性,以发现深度学习库中的潜在漏洞和错误。
实验结果(部分)
RQ1:与之前的工作比较 表1:API覆盖率比较
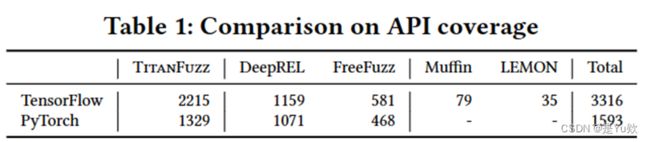
表1显示了TensorFlow和PyTorch上的所有研究技术所涵盖的库API数量。在每个工具上,使用默认设置运行了各种模糊测试工具。由于LEMON和Muffin不支持PyTorch模型,因此它们的结果仅在TensorFlow上报告。总计列显示了每个深度学习库中的API总数。需要注意的是,在计算API总数时,排除了TensorFlow中的弃用API和兼容性API,因为它们不再由开发人员积极维护。
这些数据用于比较TitanFuzz和其他模糊测试工具在涵盖不同库API方面的性能和有效性。
R1Q 表2:与现有最佳技术的比较

表2显示了整体代码覆盖率的比较。在这个比较中,根据API覆盖率选择性能最好的API级和模型级基线DeepREL和Muffin,并使用它们的默认设置运行。观察到TitanFuzz在PyTorch和TensorFlow上表现出明显优越性,实现了分别为20.98%和39.97%的最先进的覆盖率结果。相对于DeepREL,TitanFuzz在PyTorch和TensorFlow上分别提高了50.84%和30.38%的代码覆盖率。
需要指出的是,由于TitanFuzz测试的API数量更多,并且使用了语言模型,它的时间成本较高。然而,观察到,仅运行TitanFuzz来生成种子,并仅针对DeepREL已经覆盖的API进行测试(即"仅Row TitanFuzz种子(w/DeepREL API)"),也能够在更短的时间内明显优于DeepREL。这突显了直接使用语言模型生成高质量种子的潜力。TitanFuzz的性能和效力使其成为深度学习库的质量保证工具的有力选择。
RQ2:关键部件评估 表3:突变符的消融实验
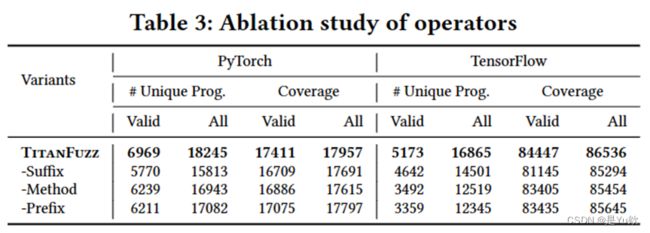
表3展示了当从TitanFuzz中移除每种类型的突变运算符时的结果。"列有效"表示仅考虑唯一的有效程序,而"列都"包括了运行时错误的程序。观察到,当使用完整的突变运算符集时,获得了最高数量的唯一程序和代码覆盖率。这表明每个突变运算符都对生成更多独特的程序和覆盖额外的代码行具有积极作用。
这个结果强调了TitanFuzz中突变运算符的重要性,它们的组合有助于增加模糊测试的全面性和深度,从而更好地发现潜在的漏洞和错误。这也进一步验证了TitanFuzz的有效性。
RQ3:检测到的bug 表7:检测到的bug汇总
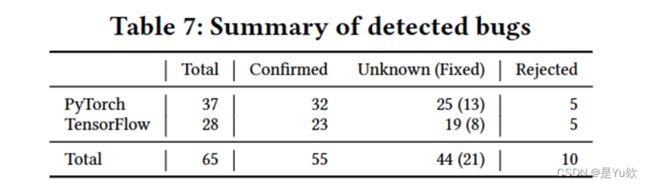
表7总结了TitanFuzz检测到的BUG的统计数据。TitanFuzz共检测到65个错误,其中55个已经确认,其中包括20个崩溃错误和35个错误计算错误。这些检测到的错误为深度学习库的质量提供了宝贵的反馈,有助于改进和修复潜在问题,从而提高库的稳定性和可靠性。 TitanFuzz的能力在检测深度学习库中的错误方面表现出色。
总结
本研究提出并实现了TitanFuzz,这是第一个通过大型预训练语言模型对深度学习库进行模糊测试的方法。TitanFuzz的方法包括以下步骤:
- 使用
生成式大型预训练语言模型(如Codex)生成高质量的种子程序,通过提供逐步提示工程。 - 利用填充式大型预训练语言模型(如InCoder)使用进化模糊算法对种子程序进行变异。
- 利用差分测试Oracle在两个独立的后端(CPU和GPU)上运行生成的代码片段,以检测错误。
经过广泛的评估,TitanFuzz在两个流行的深度学习库(PyTorch和TensorFlow)上表现出了显著的改进,包括:
- 增加了库API的数量和代码覆盖率。
- 直接利用现代大型预训练语言模型进行模糊测试的前景。
这些结果突出了TitanFuzz的有效性和潜力,为提高深度学习库的质量和可靠性提供了有力的工具。 TitanFuzz的方法还为使用预训练语言模型进行自动化测试和质量保证提供了新的方法。