24 LLM错误代码补全:机器学习顶会NeurIPS‘23 智能体评估:自行构建数据集Buggy-HumanEval、Buggy-FixEval+错误代码补全+修复模型【网安AIGC专题11.22】
Large Language Models of Code Fail at Completing Code with Potential Bugs
- 写在最前面
- 论文名片
- 对于命名实体识别、关系抽取任务的启发
- 课堂讨论
-
- 实验
- 自己构建的数据集
- 价值
- 1、论文介绍
-
- 相关工作:代码补全
- 存在的问题
- 研究的重点
- 论文结论与改进
- 2、Buggy-Code Completion
-
- 代码补全任务的基本概念
- 有错误的代码补全的挑战
- 方案设计的其他考虑
- 3. 评估方法
-
- 评估方法概述
- 3.1 基准数据集
-
- Buggy-HumanEval
- Buggy-FixEval
- 3.2 提升Code-LLM性能的方法
- 3.3 评估指标
- 4.实验设计
-
- 实验概述
- 4.1 实验设置
-
- Code-LLMs(代码大规模语言模型)
- Generating completions(通用补全方式)
- Repari models(修复模型)
- 4.2 现有的代码 LLM 在有错误的代码环境中表现如何?(bCC评估实验)
- 4.3 用现有工具可以简单缓解修复Bugy代码吗?(缓解修复实验)
- 4.4 如果部分代码没有错误怎么办?(缓解方法在没有错误的代码上的效果)
- 4.5 Bug位置和分割位置的影响
- 4.6 案例研究
-
- 潜在的错误总是有害的吗
- Code-LLM 何时能在 bCC 取得成功?
- 5、结论与不足
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
一位同学分享了Large Language Models of Code Fail at Completing Code with Potential Bugs《大语言模型在具有潜在错误代码补全中的问题》
论文发表在NeurIPS’23,机器学习三大顶会之一。
分享时的PPT简洁大方
后来重读论文时,发现汇报时的中文翻译特别精确
论文:https://arxiv.org/pdf/2306.03438.pdf
https://dev.neurips.cc/virtual/2023/poster/70988
论文名片
本文的研究成果对于理解和改进代码自动补全系统具有重要意义,特别是在处理含有错误的代码环境中的应用。它提供了对代码补全模型在现实世界场景中的应用局限性的深入见解。
- 问题研究:本文研究了buggy-code completion(错误代码补全)问题,这是一个在给定问题描述和含有潜在错误的代码片段下完成编程任务的问题。该研究受到现实生活中代码建议系统的启发。
- 数据集引入:
- buggy-HumanEval:包含由语义操作符变化产生的合成错误。
- buggy-FixEval:由用户提交的编码问题产生的实际错误。
- 主要发现:研究发现,潜在错误的存在显著降低了高性能代码大语言模型(Code-LLMs)的生成能力。
在存在潜在错误的情况下,CodeLMs性能出现了明显下降
对于命名实体识别、关系抽取任务的启发
这篇关于buggy-code completion的论文虽然主要关注于代码补全领域,但它对命名实体识别(NER)和关系抽取(RE)任务也提供了一些启发性的思路:
-
数据质量的重要性:论文强调了代码中潜在错误的影响。在这些任务中,数据集的质量、特别是实体和关系标记的准确性,对模型的性能有显著影响。模型训练时使用的数据若包含错误或歧义,可能导致模型性能下降。
-
鲁棒性的提升:这篇论文通过研究代码中的错误对模型性能的影响,启发在任务中考虑模型对于错误或不准确输入的鲁棒性。例如,开发能够处理不完整、不准确或歧义信息的模型,能提高其在真实世界数据上的应用效果。
-
任务特定优化:论文通过分析不同类型的错误对模型性能的影响,表明了任务特定优化的重要性。可以针对特定类型的文本或实体关系,调整和优化模型可能会取得更好的效果。
-
创新的评估方法:论文提出了新的评估标准来衡量模型在处理有错误代码时的性能。可以开发新的评估标准来更准确地衡量模型在处理复杂、多变或噪声数据时的性能是有价值的。
-
错误分析和诊断:论文中对错误模式的详细分析提供了灵感,即通过深入分析模型失败的案例来识别和解决模型的弱点。
其研究方法和发现对于提升NER和RE任务的模型设计、数据处理和评估方法都有借鉴意义。
课堂讨论
实验
虽然论文中提到了三种,但实验中只用到一种:补全后重写
该方法旨在评估模型在处理含有错误的代码时,通过补全和随后的重写是否能有效改善代码的质量。
自己构建的数据集
- 数据集构成:自行构建了一个包含1904个buggy-code completion(bCC)实例的数据集。
价值
-
构造数据集,做了一个大模型的评估。
-
主要发现:
- 当代码中存在错误时,代码补全效果不佳。
- 代码补全模型可能无法有效识别和纠正这些错误,从而影响最终的代码质量。
代码中有错误的话,代码补全是不好的
-
安全问题的提出:讨论还涉及到代码中的错误可能带来的安全问题,强调了在实际应用中对这些问题的重视。
1、论文介绍
相关工作:代码补全
代码大语言模型(简称Code-LLM)应用场景:代码补全等,需要自动化对代码实现补全
代码补全,即在编写程序时自动填充代码片段。
代码补全目前的技术:
1、从概率或序列建模 ,将代码结构作为先验知识结合起来,以预测下一步的最佳代码
2、采用深度神经网络和预训练技术来学习代码的表示
3、最新:基于 Transformer 的代码大语言模型 (Code-LLM) (学术界)
存在的问题
代码大语言模型 (Code-LLM)存在的问题:
-
完美假设问题:现有研究通常
假设待补全的代码中没有错误
事实:代码上下文很可能包含拼写错误或不太完善、可能存在错误的实现,平均每 1000 行代码会产生 70 个错误 ; 而修复这些错误常常占用了开发者一半的时间 。 -
问题解决的情况:由于代码上下文不完整且内容较短,错误检测和代码修复的问题定义不明确,使得现有错误检测或代码修复工具的应用不是最佳的或不可行的
即,在语义变化存在的情况下,现有的 Code-LLM 是否仍然可以提供良好的代码建议?
研究的重点
本论文的研究重点是,评估 Code-LLM 在面对包含潜在错误的代码上下文时的代码补全能力。主要工作包括:
- 定义“错误代码补全”任务( buggy-code ),即在包含潜在错误的代码上下文中进行代码补全。
- 任务中代码上下文中,包括
问题描述和代码片段组成
- 任务中代码上下文中,包括
- 构建两个基准数据集进行定量研究:
- buggy-HumanEval:通过
引入语义改变的运算符作为错误源,生成含有错误/正确部分的代码,以评估模型在控制良好的环境下对潜在错误的反应。 - buggy-FixEval:从用户提交的编码问题中提取现实漏洞,以评估模型在潜在错误的实际分布情况下的性能。
- buggy-HumanEval:通过
- 证实 Code-LLM 在处理潜在 bug 方面的不足。
- 测试几种旨在改善 Code-LLM 在错误代码上的性能的方法。
图1:代码完成(左)和bug-代码完成(右)的llustrations。
(顶部)描述需求的Prob-lem语句,您将获得一个银行帐户的存款和取款操作列表,从零余额开始。 您的任务是检测帐户余额是否在任何时候低于零,并且此时函数应返回 True。 否则它应该返回 False。
(中间)有(右)或无(左)潜在的代码(突出显示),
(底部)CoDEGEN-2B-mono[2]的代码完成。
完成代码在左边是正确的,在右边是不正确的,失败的测试用例低于零([1,2])==False,这个例子基于buggv-HumanEval中的HumanEval/3。

图 1 显示了基于大语言模型代码补全任务示例vs与传统代码补全的对比。
代码补全模型 CODEGEN-2B-MONO 通过生成不同的补全(右下)来对潜在错误 (-=) 的存在做出反应。 然而,完整的代码在功能上是不正确的。
论文结论与改进
-
论文结论:发现潜在错误的存在极大地降低了高性能 Code-LLM 的代码补全性能,所有测试模型变体在两个数据集的测试用例通过率降至 5% 以下
-
论文改进:
尝试几种修复缓解方法:如通过外部代码修复程序来增强 Code-LLM
补全→重写(补全程序,然后重写已补全的程序)
重写→补全(重写潜在的错误代码,然后补全)
结果表明,这些方法提高了所有测试模型的补全度。 然而,它们与从正确的部分代码补全之间的性能差距仍然很大。
2、Buggy-Code Completion
代码补全任务的基本概念
-
代码补全任务 包括两个核心部分:
- 规范 (h):这是程序应该实现的功能描述(problem statement),通常以英文文档字符串或问题陈述的形式给出。
- 代码上下文 (s):这是一些已经开始但尚未完成的代码片段(code context),即程序的初始部分或前缀。
-
传统代码补全的目标:传统上,代码补全的目标是提出一个补全
c,使得t = s :: c(::表示代码串联)是一个满足规范h的完整程序。
有错误的代码补全的挑战
-
潜在错误的问题:在有错误的代码补全中,关键问题是代码上下文
s可能包含错误。这意味着即使存在一个补全c使t = s :: c满足规范h,但因为s中的小错误e,修改后的s'可能导致t' = s' :: c不再满足规范h。 -
错误代码补全的定义(bCC):在这种情况下,错误代码补全的任务是,在给定规范
h和含错误的代码前缀s'的情况下,生成一个满足h的程序t。
方案设计的其他考虑
-
错误代码前缀的角色:这种设定认为错误代码前缀提供了嘈杂且可能有缺陷的先决条件,代表了用户的初步尝试。理想情况下,一个高效的模型应该能利用这些前缀作为提示,即使在最坏情况下也应该比没有前缀时表现得更好。然而,我们的测试表明,现有模型并未达到这一效果。
-
任务的特殊性:我们的任务设定不仅仅是代码修复和代码完成的简单组合。特别是,对于部分代码的修复本身就是一个不明确的问题,因此将其与代码完成结合仍然存在不确定性。尽管如此,我们的错误代码补全任务可以看作是代码完成的一个扩展,其额外的挑战在于在给定部分代码的情况下,找到语义上正确的延续可能很困难。
-
灵活性的重要性:为了应对这些挑战,我们故意放宽了
t必须包含s'作为前缀的约束。从图 1 中的示例中可以看出,专注于有缺陷的代码前缀可能导致找到满意解决方案变得困难,甚至不可能的情况下,模型需要灵活性来建议修复这些缺陷,这将显著提高生成程序通过测试的可能性。然而,通常仍然可以将有缺陷的前缀继续到有效的程序解决方案中(参见图 12 中的示例)。
3. 评估方法
评估方法概述
在本研究中,构建了两个基准数据集来评估代码大语言模型(Code-LLM)在处理错误代码补全(bCC)任务的能力。这些数据集满足以下条件:
- 问题描述:明确指定程序所需实现的功能。
- 有缺陷的代码前缀:包含潜在错误的未完成代码部分。
- 正确性测试用例:用于评估完成后代码的正确性。
这些数据集的构建考虑到有缺陷的代码前缀可以看作是用户在解决编码问题时的初步尝试,虽然可能含有错误,但应该被模型视为有价值的输入。理想情况下,模型应该利用这些前缀作为提示,最差情况下也不应该比没有前缀时表现更差。
3.1 基准数据集
Buggy-HumanEval
- 目的:在存在单个语义错误的情况下评估 bCC。
- 构成:含有 1904 个 bCC 实例,这些实例来自于 HumanEval 数据集,涉及手动编写的编程问题。
- 典型应用:
(1)搜索适用的二元运算符,并将它们更改为语义相反的形式,例如,将 + 更改为 -。
(2)为了确保修改确实引入了错误,行更改后的程序,并且仅在某些测试失败时才保留它。
(3) 在更改后的运算符后面指定一行,将解决方案拆分为代码前缀和后缀。 将 buggy 前缀保留为 bCC 输入的一部分。 在同一行拆分未更改的解决方案以获得相应的clean前缀。
(4)测试修改后的代码,并使用保留的后缀进行对比验证
Buggy-FixEval
- 数据来源:结合了 CodeNet 和 FixEval 数据集的 266 个 bCC 实例。
- 构建方法:
- 将 FixEval 中的问题与 CodeNet 中找到的问题陈述进行匹配。
- 确定潜在错误为被拒绝和接受的提交之间的差异。
- 排除包含语法错误的提交,保留至少有一个失败测试用例的提交。
- 典型应用:
(1)将数据分成两半,并将被拒绝的解决方案的前缀视为包含潜在的错误,而将接受的解决方案的前缀视为干净。
(2)消除数据干扰,确保代码生成的差异确实与潜在的错误相关。 对 buggy 前缀和 clean 前缀之间的字符级编辑距离施加限制,忽略注释和空格,手动检查并排除不需要的其他情况。
(3)在数据集上执行代码生成补全,并进行对比验证
3.2 提升Code-LLM性能的方法
为了减轻bCC任务中潜在错误的影响,提出了几种增强Code-LLM的方法:
-
删除→补全:这种方法涉及删除有缺陷的代码部分,以避免它们的负面影响。虽然这保证了输入没有错误,但同时也丢失了原始代码提供的信息。
-
补全→重写:在完成代码补全后,使用代码修复程序对结果进行修复。
-
重写→补全:在执行代码补全之前,先修复部分代码中的潜在错误。这是通过识别含有错误的代码行,然后使用代码语言模型(如 INCODER-6B)来重写这些行来实现的。为了确定哪些行最有可能包含错误,采用了基于可能性的度量方法,该方法通过比较每个标记位置上最有可能(最高似然性)的标记(即 argmax 标记)与实际观察到的标记之间的似然差来评估每行代码的可能性。选择分数最高的行进行重写。
3.3 评估指标
通过执行补全后的程序,并根据测试用例的通过情况来评估其功能性。具体的评估方法如下:
pass@k 公式表明了评估代码补全模型性能的一种更细致的方法。让我们来详细解读一下这个公式:
pass@k 指标的计算公式是:
p a s s @ k : = 1 − ( n − c k ) ( n k ) {pass@k} := 1 - \frac{{\binom{n - c}{k}}}{{\binom{n}{k}}} pass@k:=1−(kn)(kn−c)
这里各部分代表的含义如下:
n是从模型中抽样出的补全总数。c是通过所有测试的补全数。k是考虑的尝试次数。- 项 ( n k ) \binom{n}{k} (kn) 是二项式系数,代表从
n个可能的补全中选择k个的方式数。 - ( n − c k ) \binom{n - c}{k} (kn−c)代表从未通过测试的
n - c个补全中选择k个的方式数。
这个公式实际上计算的是从 n 个抽样中选择 k 个补全,通过的补全占所有可能组合的比例。这种方法考虑了多次尝试成功的概率,给出了模型性能的更全面的画面。
在实际操作中,n 设置为 100,并且使用 1、10 和 100 作为 k 的值。这样的参数选择允许评估模型在从单次尝试到多达 100 次尝试的不同场景下的性能。
最后,为了确保评估平衡,且不受少数编程问题的主导,采用宏观平均方法。这意味着首先在每个问题内部对 pass@k 分数进行平均,然后再对所有问题的这些平均值进行平均。这种方法对模型在不同编码挑战中的性能进行了更公平、全面的评估。
虽然通过所有测试用例不能百分百保证程序的正确性,但pass@k指标为评估功能正确性提供了一个实用且有效的方法。
4.实验设计
实验概述
设计了两组实验来评估代码大语言模型(Code-LLMs)在错误代码补全(bCC)任务中的表现:
- bCC评估实验:这一实验旨在测试现有的Code-LLMs对bCC任务的适应程度。
- bCC缓解修复实验:这一实验旨在探索是否可以对bCC任务进行简单的修复。
4.1 实验设置
Code-LLMs(代码大规模语言模型)
选择了两个具有高性能代码生成能力的最新且公开可用的模型:
-
CODEGEN:
- 特点:经过自然语言和编程语言语料库训练的代码大语言模型,已在HumanEval上显示出卓越的代码生成能力。
- 使用版本:CODEGEN-350MMONO 和 CODEGEN-2B-MONO。
-
INCODER:
- 特点:使用因果屏蔽目标进行训练,能够填充以任意上下文为条件的代码块。
Generating completions(通用补全方式)
对输入格式和抽样细节进行了设置
-
输入格式设置:
- 对于 buggy-HumanEval:模型期望补全未完成的程序。输入包括指向补全位置的部分代码和问题描述(未完成函数的文档字符串)。
- 对于 buggy-FixEval:模型同样期望补全未完成的程序,输入包括文档字符串的问题描述和指向补全位置的部分代码。
-
具体采样设置:
- CODEGEN:使用温度(temperature)设置为0.6进行采样。
- INCODER:使用 top-p 采样,参数设置为 p = 0.95 和温度为0.2。
有缺陷的代码前缀实际上代表了用户尝试解决编码问题时的初步努力,虽然可能含有错误。理想情况下,一个高效的模型应该能利用这些前缀作为提示,即使在最坏的情况下也不应比没有前缀时表现得更差。然而,测试的模型却并非如此(第 4.2 节)。
Repari models(修复模型)
用以消除其他潜在的影响
- 补全 → 重写的程序修复方法:使用了最新的模型 RealiT ,该模型针对代码中人工和现实错误进行了训练和测试。
该设置的另一种观点是,有缺陷的代码前缀为生成编码问题的解决方案提供了嘈杂且可能有缺陷的先决条件。 它代表了用户的善意努力,指导该工具获得他们想要的代码解决方案类型。 一个表现良好的模型应该将此作为提示,最坏的情况是丢弃它,这样生成性能不应该比没有给出代码前缀时更差。 然而,我们测试的模型却并非如此(第 4.2 节)。
4.2 现有的代码 LLM 在有错误的代码环境中表现如何?(bCC评估实验)
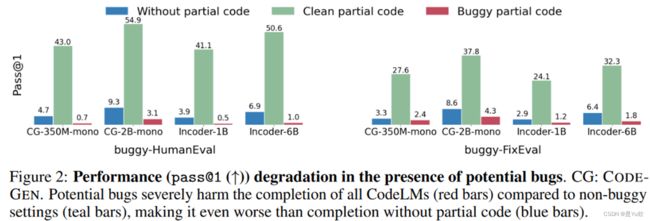
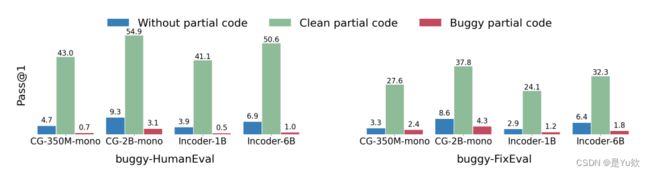
测试模型在具有错误信息的代码补全的性能:
- 性能指标:使用pass@1来衡量性能。
- 测试模型:包括CODEGEN-350M-MONO、CODEGEN-2B-MONO、INCODER-1B和INCODER-6B。
结果分析:
- 性能下降:与含有错误的代码相比,所有模型在clean代码上的pass@1显著下降。例如,buggy-HumanEval的pass@1从41.1–54.9%下降到0.5–3.1%,buggy-FixEval从24.1–37.8%下降到1.2–4.3%。
- 测试结论:Code-LLM在bCC任务上几乎完全失败,潜在错误的存在破坏了部分代码的益处。
测试结论:
(1)测试的 Code-LLM 在我们的数据集实例化的 bCC 上彻底失败
(2)潜在错误的存在完全破坏了部分代码带来的好处。
原因分析
分析思路:手动检查性能最佳的 CODEGEN-2B-MONO 模型中的样本,并在失败的样本中找到两种最常见的故障模式。
分析原因:
(1) 对微小代码变更不敏感。这种模式发生在 90% 的实例中,并且 93% 的问题至少有一个失败的实例。 图 8 显示了一个示例。

(2)模型无法绕过潜在的错误。模型可能已经识别出潜在的错误并显著改变了输出分布,但仍然失败。 图 7 展示了这种情况的一个示例。

4.3 用现有工具可以简单缓解修复Bugy代码吗?(缓解修复实验)
减少潜在影响。使用三种消除潜在影响的bCC 设置方法,结果如表 1 所示

(1)去掉潜在影响后的效果。所有三种错误感知方法都优于简单的错误代码完成。
(2)语言模型能力的影响。 对于每种类型的代码补全模型,使用相同方法时,较大版本比较小版本获得更好的性能。
(3)合成错误与真实错误。 在两个 bCC 数据集中,缓解方法的整体性能在 buggy-HumanEval 上优于 buggy-FixEval。
不同错误感知方法的效果。所有三种错误感知方法都优于简单的错误代码完成基线。 在 buggy-HumanEval 上,我们观察到完成→重写的总体趋势优于重写→完成,而重写→完成又优于删除→完成。 在 buggy-FixEval 上,我们观察到删除→完成优于重写→完成,而重写→完成又优于完成→重写。 随着完成模型规模的增大,性能差距也会增大。 对于 k = 10, 100 的 pass@k 观察到类似的比较趋势。尽管它们有效,但对于所有设置,最佳方法和上限(从干净的部分代码完成)之间的性能差距仍然很大。
语言模型能力的影响。 对于每种类型的代码完成模型,使用相同方法时,较大版本比较小版本获得更好的性能。 例如,对于两个数据集中的所有设置,CODEGEN-2B-MONO 的性能均优于 CODEGEN-350M-MONO。 与 CodeGen 相比,INCODER 模型通常获得更好的 pass@1,但较差的 pass@10 和 pass@100。 这表明 CODEGEN 模型生成更多样化的补全,而 INCODER 模型生成更精确的补全。 此外,INCODER 比 CODEGEN 模型对有错误的部分代码更敏感,朴素 bCC 的较低分数就证明了这一点。
合成错误与真实错误。 在两个 bCC 数据集中,我们观察到缓解方法的整体性能在 buggy-HumanEval 上优于 buggy-FixEval。 这表明 buggy-FixEval 中实际潜在错误的难度:可能有多个错误; 错误可能会与非错误修复更改混合在一起; 而且错误比单个操作员的更改更加微妙。 此外,虽然在大多数情况下实现了最佳性能,但在 buggy-FixEval 上使用较大模型时,完成 → 重写仅显示出与其他方法的微小差异。 要点:我们的基准方法提高了所有评估的 Code-LLM 的完成度。 然而,与干净的部分代码的完成相比,剩余的性能差距仍然很大。
4.4 如果部分代码没有错误怎么办?(缓解方法在没有错误的代码上的效果)
一般代码补全的实用解决方案应该考虑存在或不存在潜在错误的两种情况。
如表 2 所示,bCC 的缓解方法可能会损害clean代码上下文的完成。

改进方法:通过使用检测阈值来控制两者之间的平衡。
具体示例:重写 → 完成过程中,只有当阈值与 argmax 阈值的似然差距超出阈值(0 到 1 之间)时,才被视为潜在错误。
表 3 显示了使用 CODEGEN-2B-MONO 在 buggy-FixEval 上重写的 pass@1 → 完成的不同阈值。
看到 0.9 在这两种情况下实现了相对较好的平衡。

4.5 Bug位置和分割位置的影响
位置定位:通过潜在 Bug 的位置和 buggy-HumanEval 中部分代码分割的位置来聚合结果。
这些位置定义为 (潜在错误行 #)/(# 行) 和 (分割行 #)/(# 行)
其中潜在错误行 #、分割行 # 和 # 行是从函数开始的行数 header 到包含潜在错误的行到部分代码的末尾,以及到规范解决方案的末尾。
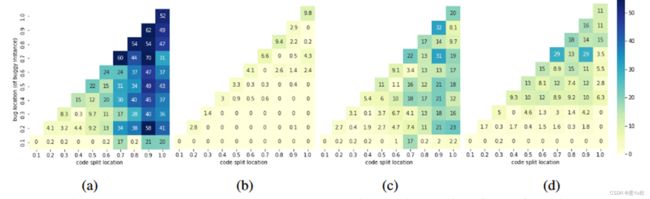 纵轴是bug location(of buggy instance)
纵轴是bug location(of buggy instance)
横轴是code split location
测试数据集和模型 :在 buggy-HumanEval 数据集上对CODEGEN-2B-MONO 模型上评估的 pass@1 分数(对落入每个单元的 bCC 实例进行平均), 从左往右:(a) naive completion on clean code, (b), ©, (d) naive completion, completion → rewriting, and rewriting → completion on buggy code.
结论:(1)在clean的情况下,较长的部分代码,CODEGEN-2B-MONO 的性能更好(图 3a)
(2)在有潜在错误的情况下朴素补全总体表现不佳(图 3b)
(3)但当潜在错误出现在部分代码的最后一行或附近(沿对角线)时,它的表现相对较好。
(4) 在图 3d 中,当潜在错误稍后出现时,重写 → 补全会获得更高的分数。
相比之下,补全→重写(图3c)在代码前缀较长时获得高分,表明该方法可以修复程序早期出现的潜在错误。
4.6 案例研究
潜在的错误总是有害的吗
潜在的错误并不能保证补全的代码一定有错误。
如图 12 显示,对于从 != 修改而来的潜在错误 (突出显示),补全模型使用 continue 命令偏离其原始算法流程,并以正确的功能完成,尽管与规范解决方案不同。 说明一些 bCC 案例是可以恢复的,并且 Code-LLM 可以适应它们。

Code-LLM 何时能在 bCC 取得成功?
对于 bCC 的简单补全的成功案例,模型有可能
(i)忽略不正确的状态并生成正确的补全
(ii)考虑潜在的错误但生成适应它的补全。
图 9 显示了 Code-LLM 忽略 if-else 语句以绕过潜在错误的示例

5、结论与不足
-
本文主要工作
(1)本文引入并定义了错误代码完成问题,
(2)构建了两个新的数据集 buggy-HumanEval 和 buggy-FixEval 作为任务基准,并发现潜在错误的存在会显着降低所有评估的大型语言代码模型的完成性能。
(3)对 Code-LLM 的缓解策略的进一步研究表明,尽管使用外部程序修复模型来增强模型,但完成潜在错误的任务仍然具有挑战性。
(4)本文提供修复案例研究,以进一步理解和分析错误代码补全设置 -
不足之处
(1)选取了2中大语言模型进行测试,测试面不足。Code-LLM 进行研究可以进一步支持我们的发现。
(2)bCC 假设代码文本中存在潜在错误。 当不存在潜在错误时,本文的方法可能会损害完成性能,bCC 的未来解决方案可能需要考虑平衡这两种情况