计算机组成原理——主存储器
存储器
4.1 概 述
一、存储器分类
1. 按存储介质分类
- 半导体存储器 TTL 、MOS 易失
- 磁表面存储器 磁头、载磁体 非易失
- 磁芯存储器 硬磁材料、环状元件 非易失
- 光盘存储器 激光、磁光材料 非易失
2. 按存取方式分类
- 存取时间与物理地址无关(随机访问)
- 随机存储器(RAM) 在程序的执行过程中可读可写
- 只读存储器(ROM) 在程序的执行过程中只读
- 存取时间与物理地址有关(串行访问)
- 顺序存取存储器 磁带
- 直接存取存储器 磁盘
- 按在计算机中的作用分类
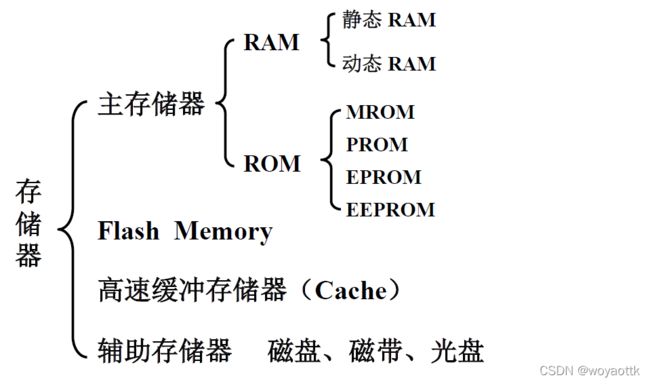
二、存储器的层次结构
1. 存储器三个主要特性的关系
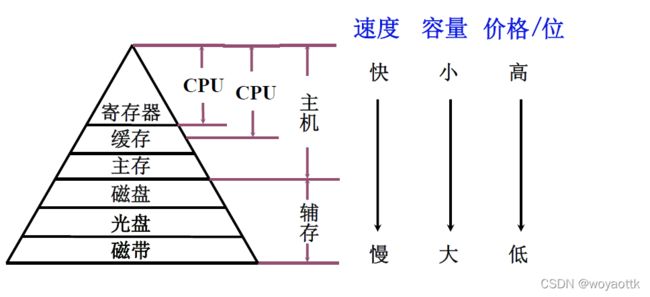
2. 缓存 主存层次和主存 辅存层次

4.2 主存储器
一、概述
1. 主存的基本组成
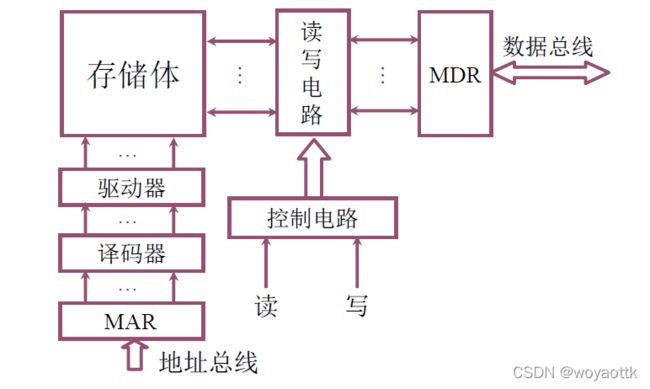
2. 主存和 CPU 的联系
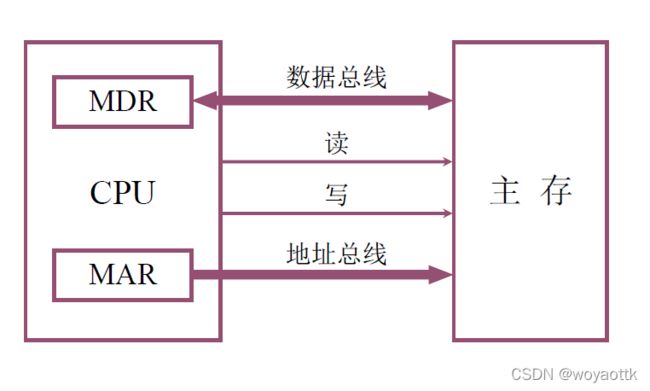
MRD、MAR逻辑上属于主存但物理上属于CPU
3. 主存中存储单元地址的分配

4. 主存的技术指标
- 存储容量:主存存放二进制代码的总位数
- 存储速度
- 存取时间:存储器的访问时间、读出时间、写入时间
- 存取周期:连续两次独立的存储器操作(读或写)所需的最小间隔时间读周期写周期
- 存储器的带宽:位/秒
二、半导体存储芯片简介
1. 半导体存储芯片的基本结构

CPU外部设备给出地址,通过译码驱动电路在存储矩阵中找到数据,再通过读写电路传输数据
片选线:控制线的一种,用于传递芯片选择信号,用来找到数据存储的目标芯片,CS’芯片选择,CE‘芯片使能
读写控制信号:控制读写信号,如果只有一根读写线,那么WE’0表示写,1表示读,如果有两根OE‘只允许读,WE’只允许写
地址线是单向的,数据线是双向的

2. 半导体存储芯片的译码驱动方式
(1) 线选法
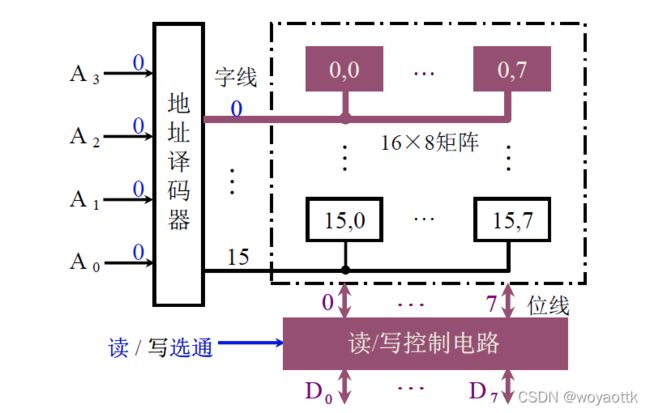
将地址线接入地址译码器,通过译码找到指定的一组芯片,然后通过读写信号控制信号的传输
问题:假如是1M*8位那么译码器将位于1M根线!!!
(2) 重合法
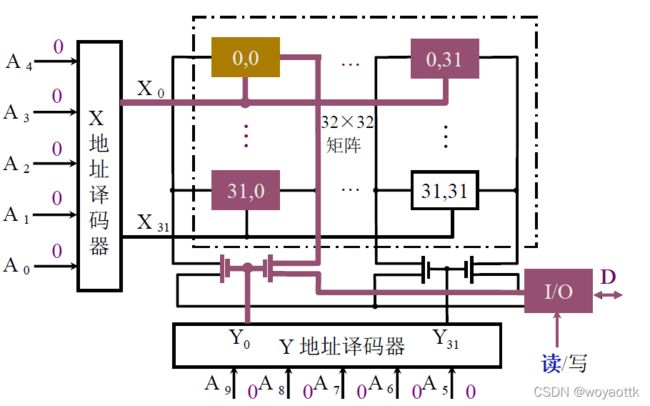
更上面线选法的区别在于将一位改为二维,只有在XY重合的交点才能输出/出数据
三、随机存取存储器 ( RAM )
1. 静态 RAM (SRAM)
(1)静态RAM 基本电路
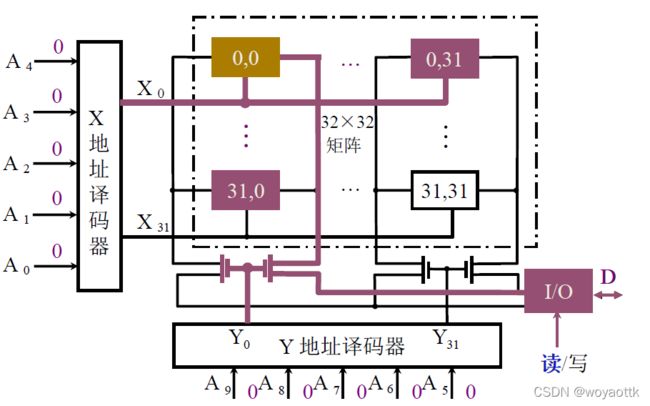
跟半导体芯片的重合法相似,只有行列交点能用
(2)静态 RAM 基本电路的 读 操作
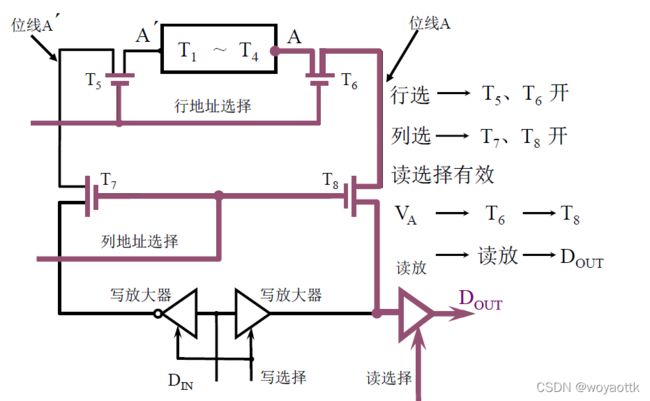
- 给出行选信号 -> T5、T6打开
- 给出列选信号 -> T7、T8打开
- 读信号打开VA -> T6 -> T8 -> 读放 -> Dout
(3)静态 RAM 基本电路的 写 操作

- 给出行选信号 -> T5、T6打开
- 给出列选信号 -> T7、T8打开
- 给出写选择信号DIN两边开放,其中一遍需要取反,因为写入信号需要同时写入0另一半写入1
2. 动态 RAM ( DRAM )
(1) 动态 RAM 基本单元电路
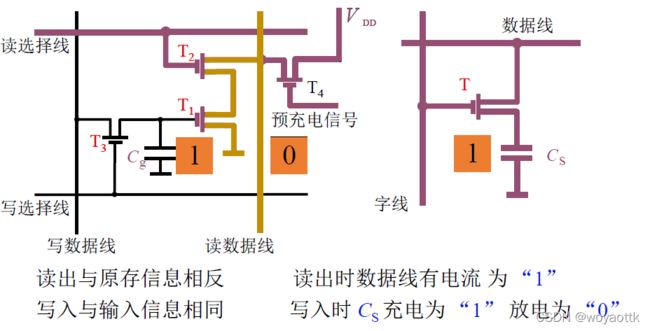
读操作流程:预充电信号导通T4打开,由于读数据线与VDD直接相连故读数据为1,传入读信号T2 打开如果Cg=1那么T1打开导致读数据线直接接地,最后读出数据为0,反之为1。因此读出数据与原存储信息相反故保证读操作的正确性需要添加一个非门。写入操作与输入信息相同。
另一种结构的读操作:子痫导通T打开Cg=1则数据线有电流通过,此时数据为1否则为0,写入时数据线为1,Cg进行充电,反之放电。
(2) 动态 RAM 刷新***
因为电容长时间后会漏电导致数据丢失故需要定期刷新。
注意:刷新与行地址有关而不是列
1) 集中刷新(存取周期为0.5 us )
以 128 × 128 矩阵为例
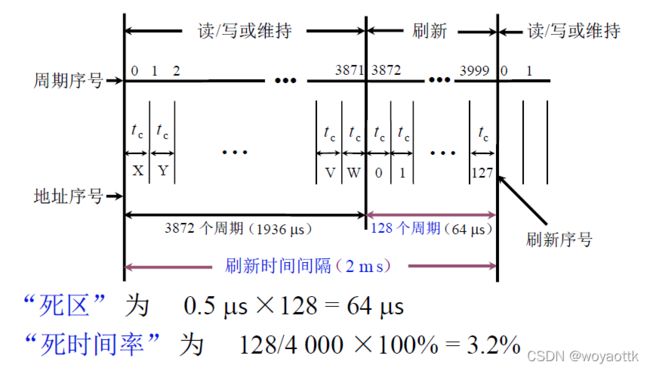
专门拿出一段时间用于刷新操作
死区:这段时间用于刷新CPU不能对其进行操作
死区肯定是越少越好故有了下面的分散式刷新
2) 分散刷新(存取周期为1 us )
还是以 128 × 128 矩阵为例
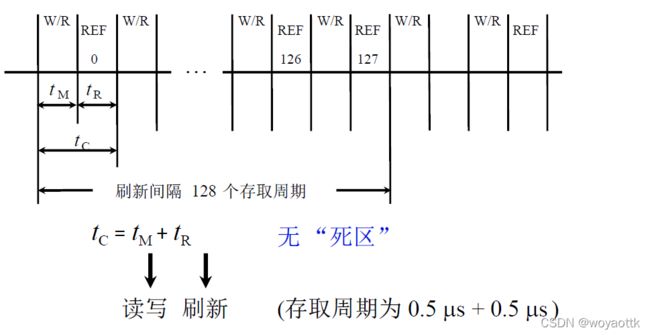
这种方式是边读边刷新这样就可以解决死去的问题但是这样也就导致了存取周期的时间翻倍了,而且假如128us内就可以完成刷新全部数据的操作在2ms内就是进行15.6次刷新,这是一种过度刷新降低了CPU的效率
3) 分散刷新与集中刷新相结合(异步刷新)
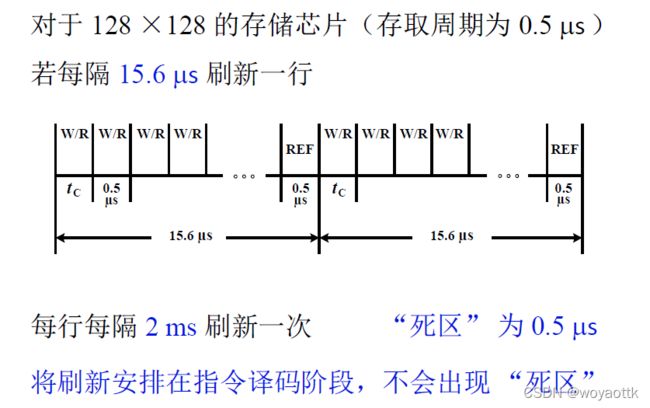
将2ms非为128粉每份15.6us,在每一份中抽出0.5us用于刷新这样就可以实现局部内是集中式刷新,整体式分散式刷新了,并且如果将刷新时间安排的恰当就不会出现死区,比如说将刷新安排在指令译码阶段就不会出现死区
3. 动态 RAM 和静态 RAM 的比较
| 动态RAM(DPAM)一般用作主存 | 静态RAM(SRAM)一般用作Cache缓存 | |
|---|---|---|
| 存储原理 | 电容 | 触发器 |
| 集成度 | 高 | 低 |
| 芯片引脚 | 少 | 多 |
| 功耗 | 小 | 大 |
| 价格 | 低 | 高 |
| 速度 | 慢 | 高 |
| 刷新 | 需要 | 不需要 |
四、只读存储器(ROM)
一般用于存储系统程序,系统配置信息等
1. 掩模 ROM ( MROM )
行列选择线交叉处有 MOS 管为“1”
行列选择线交叉处无 MOS 管为“0”
2. PROM (一次性编程)

3. EPROM (多次性编程 )
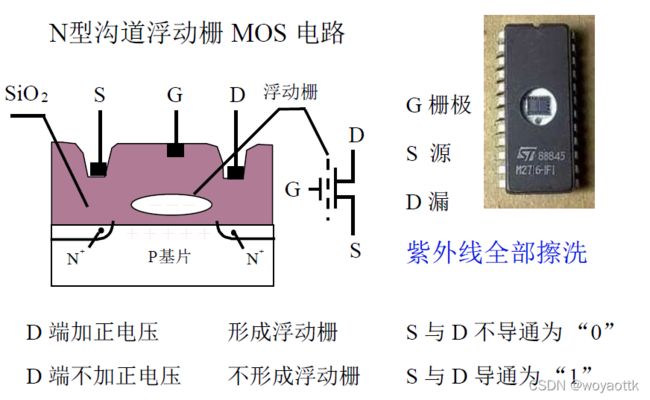
4. EEPROM (多次性编程 )
电可擦写
局部擦写
全部擦写
5. Flash Memory (闪速型存储器)
例如U盘就是Flash Memory
EPROM 价格便宜 集成度高
EEPROM 电可擦洗重写 比 EPROM快 具备 RAM 功能
五、存储器与 CPU 的连接***
1. 存储器容量的扩展
(1) 位扩展(增加存储字长)
目的是怎加存储字的字长
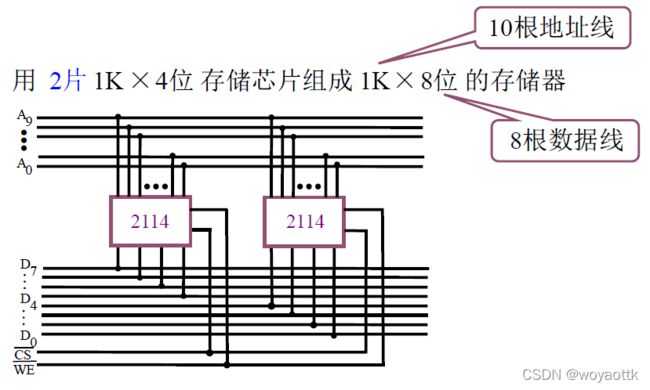
将两片芯片用片选线连在一起组成一块新的存储体,其中一块芯片接到高位的四根数据线,另一个芯片接到地位的四根地址线
位扩展的关键就是将两个芯片连接成一个芯片,同时(通过片选线来实现)进行读写操作。
(2) 字扩展(增加存储字的数量)
目的是增加存储在的数量

可以将多余的一根地址线当作片选线,例如A10=0则第一个芯片工作,A10=0第二个芯片工作
(3) 字、位同时扩展

将两个芯片为一组构成一个1K x 8位的存储体,然后适用多余的两根地址线通过译码器生成四根片选线,利用片选线找到目标存储体
2. 存储器与 CPU 的连接
基本方法有:
- 地址线的连接
- 数据线的连接
- 读/写命令线的连接
- 片选线的连接
- 合理选择存储芯片
- 其他 时序、负载
六、存储器的校验
编码的检测能力和纠错能力取决于任意两组合法代码之间二进制位的最少差异数
编码的最小距离:任意两组合法代码之间 二进制位数 的 最少差异
编码的纠错 、检错能力与编码的最小距离有关

汉明码是具有一位纠错能力的编码
关于汉明码的介绍可以看我的另一篇文章http://t.csdn.cn/ujnc6
七、提高访存速度的措施
- 采用高速器件
- 采用层次结构 Cache –主存
- 调整主存结构
1. 单体多字系统
增加存储器的带宽
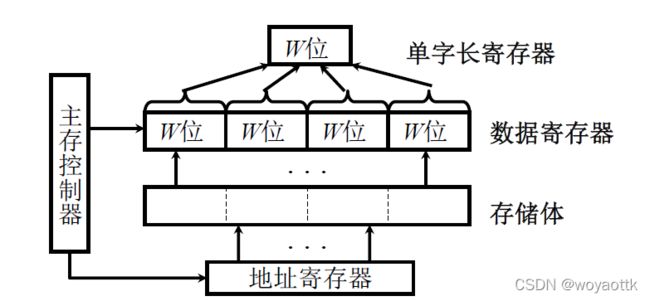
设计:主存控制器16位,存储体64位
这样异常能取出4个数据或指令于数据寄存器中下次直接从数据寄存器中取而不是存储体,相当于缓存
问题:
- 写数据的时候异常只能写入16位,但存储体是64位一下得写入64位故会有48位数据是错误数据
- 如果数据于指令(跳转指令)不是连续的那么就会造成资源浪费
2. 多体并行系统
(1) 高位交叉 顺序编址
各个体并行工作
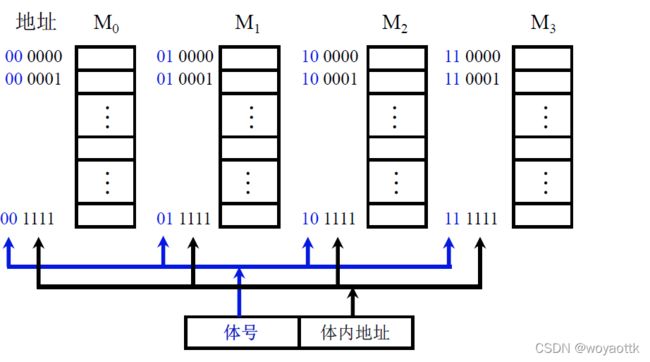
这样就也进行并行存储了,通过体号控制某个存储体体内地址找到具体的位置,这样存储体与存储体之间是相互独立的,可以并行使用
问题:程序是顺序存储的,故会导致某一个存储体过于繁忙,其余存储体过于空闲
(2) 低位交叉 各个体轮流编址
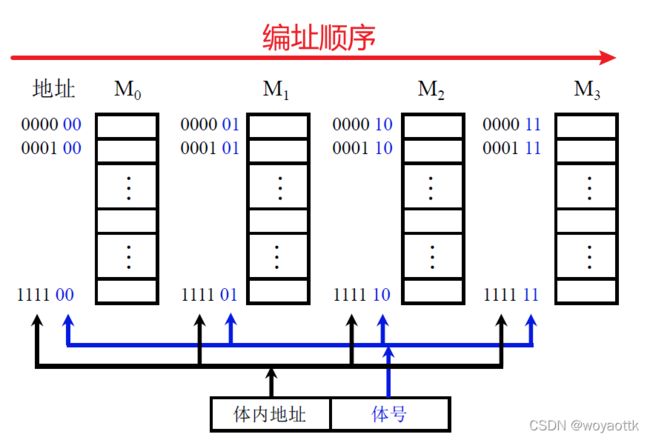
用低位存储将原本纵向的存储改为横向的存储,这样就可以让每一个存储体都用上,解决了高位交叉的连续地址读取效率低下的问题
低位交叉的特点:在不改变存取周期的前提下,增加存储器的带宽

在一个单体访存周期中当M0接受到CPU发出的取数指令,M0开始准备数据,在M0准备数据的时候CPU再给M1发生取数指令,依次循环。这样就可以进行并行操作
高位加成主要用于存储器容量的扩展
低位交叉主要用于存储器带宽和速度的提高
3.高性能存储芯片
(1) SDRAM (同步 DRAM)
在系统时钟的控制下进行读出和写入
CPU 无须等待
(2) RDRAM
由 Rambus 开发,主要解决 存储器带宽 问题
(3) 带 Cache 的 DRAM
在 DRAM 的芯片内 集成 了一个由 SRAM 组成的 Cache ,有利于 猝发式读取
4.3 高速缓冲存储器
一、概述
1. 问题的提出
避免 CPU “空等” 现象
CPU 和主存(DRAM)的速度差异
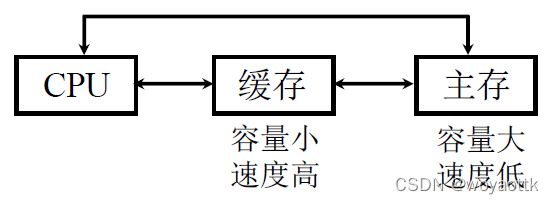
程序访问的局部性原理:时间局部性,当前使用的指令与数据在不久的将来相邻的指令与数据还要继续被使用到
2. Cache 的工作原理
(1) 主存和缓存的编址

主存和缓存按块存储
块的大小相同
缓存共有 C 块 主存共有 M 块
M >> C
(2) 命中与未命中
- 命中:
- 主存块 调入 缓存
- 主存块与缓存块 建立 了对应关系
- 未命中:
- 主存块 未调入 缓存
- 主存块与缓存块 未建立 对应关系
- 用 标记记录 与某缓存块建立了对应关系的 主存块号
(3) Cache 的命中率
CPU 欲访问的信息在 Cache 中的 比率
命中率 与 Cache 的 容量 与 块长 有关
一般每块可取 4 ~ 8 个字
块长取一个存取周期内从主存调出的信息长度
(4) Cache –主存系统的效率
效率 e 与 命中率 有关

设 Cache 命中率 为 h,访问 Cache 的时间为 tc ,访问 主存 的时间为 tm

3. Cache 的基本结构
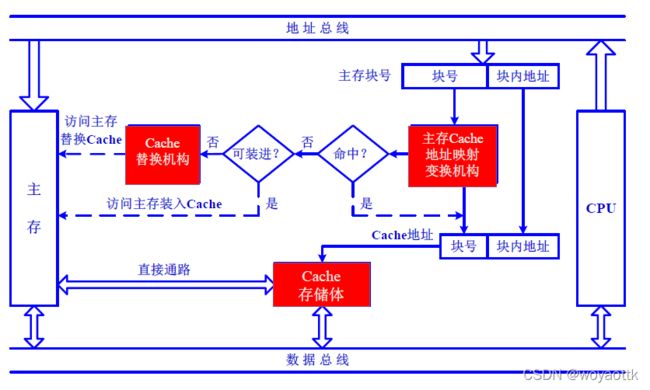
映射:主存与Cache地址之间的映射关系 Map
变换:将主存地址转换为Cache地址
替换机构:当Cache已满时,应该采用替换算法,替换Cache中的内容
当CPU需要的数没有事,主存会先将数据给CPU然后再存入Cache
4. Cache 的读写操作
读操作
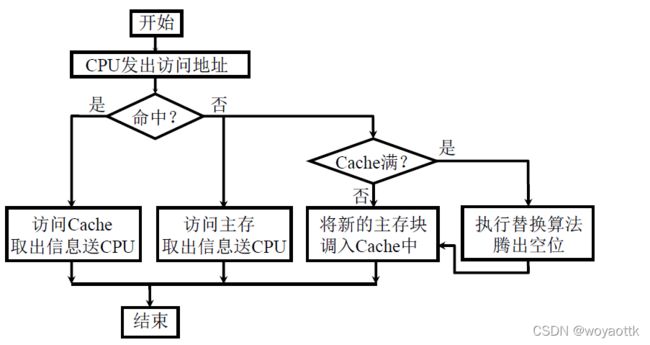
写操作
写操作与读操作不同,写操作需要考虑Cache 和主存的一致性
常见的有两种方法:
- 写直达法(Write – through)
- 写操作时数据既写入Cache又写入主存
- 写操作时间就是访问主存的时间,Cache块退出时,不需要对主存执行写操作,更新策略比较容易实现
- 优点:Cache与主存数据始终保持一致
- 缺点:CPU效率降低
- 写回法(Write – back)
- 写操作时只把数据写入 Cache 而不写入主存
- 当 Cache 数据被替换出去时才写回主存
- 写操作时间就是访问 Cache 的时间,Cache块退出时,被替换的块需写回主存,增加了Cache 的复杂性
- 优点:CPU效率提高
- 缺点:当CPU有多个核并行运行时,每个核都会有一个属于自己的Cache,这样就会导致数据不同步,类似于单例bean线程不安全的问题
5. Cache 的改进
(1) 增加 Cache 的级数
片载(片内)Cache
片外 Cache
(2) 统一缓存和分立缓存
统一缓存:将指令与数据保存到同一个Cache中
分立缓存:将指令与数据分开保存到指令Cache和数据Cache
二、Cache – 主存的地址映射
1. 直接映射

主存当中任意一个给的的它都只能映射到某一个指定的Cache块中
具体做法:将主存中一部分对映到Cache中的某一块,且每个部分划分的大小与Cache一样
问题:Cache的利用率低,冲突率高
2. 全相联映射

主存中的任一块可以映射到缓存中的任一块,Cache利用率高
问题:CPU从Cache中取数据时需要遍历一遍Cache,效率低
3. 组相联映射
直接映射与全相联映射走了两个极端
直接映射:一个主存块只能放到一个Cache块中
全相联映射:一个主存块能放在任意一个Cache中
而组相联映射就是这两种映射的折中
先把Cache块分成若干组,每组有若干块
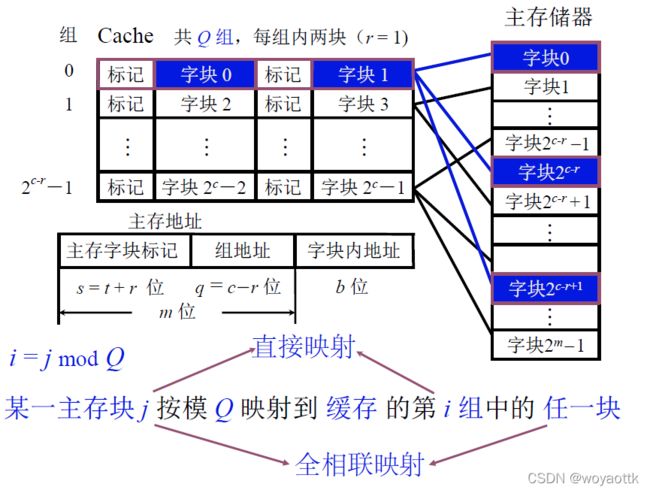
与直接映射比一个主存块可以存放在若干个地方,与全相联映射比,主存块将会存放到某个指定的区域当中,而不是任意
其实直接映射与全相联映射可以理解为组相联映射的一种极端,直接映射就是每组只有一个Cache块,而全相联映射就是分组的时候之分一组
对于分层Cache靠近CPU的Cache要求高速故可以采用直接映射,而远离CPU的Cache可以采用全相联映射,中间部分采用组相联映射。

三、替换算法
- 先进先出 ( FIFO )算法:先放入的Cache先出去
- 近期最少使用( LRU)算法:最近时间内使用次数最少的Cache先出去
4.4 辅助存储器(非重点,了解即可)
一、概述
-
特点:不直接与 CPU 交换信息
-
磁表面存储器的技术指标
- 记录密度:道密度Dt 位密度 Db
- 存储容量:C = n × k × s
- 平均寻址时间:寻道时间+ 等待时间
- 数据传输率:Dr =Db × V V旋转速度
- 误码率:出错信息位数与读出信息的总位数之比
二、磁记录原理
写操作
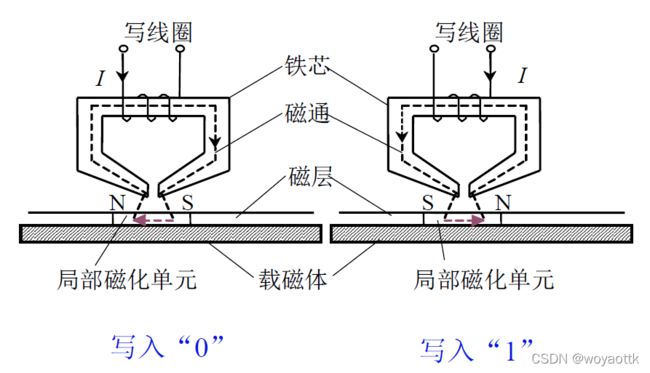
写线圈通电的方向不同导致产生的磁场方向不同存储体的磁场磁化方向就不同,磁场方向就代表0或1
读操作
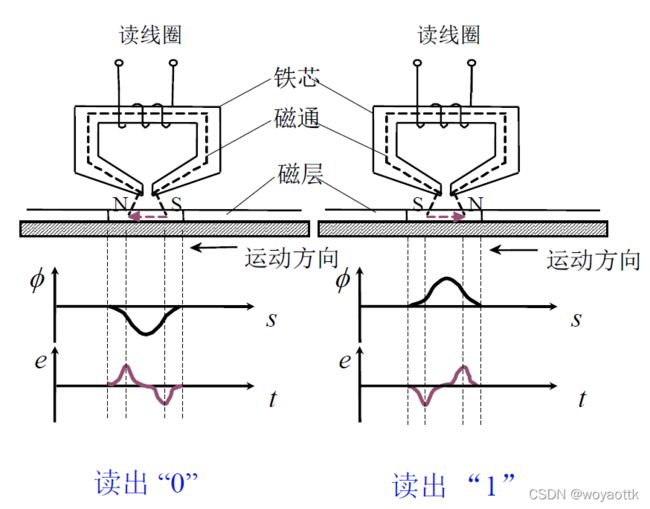
磁层在旋转,存储体经过读线圈就会切割磁感线产生电流,电流方向代理0或1
三、硬磁盘存储器
1. 硬磁盘存储器的类型
(1) 固定磁头和移动磁头
(2) 可换盘和固定盘
2. 硬磁盘存储器结构
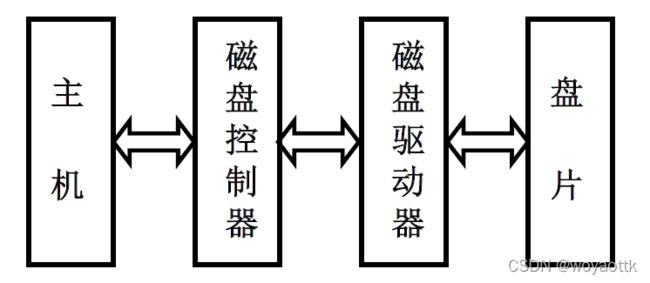
四、软磁盘存储器
1. 概述
| 硬盘 | 软盘 | |
|---|---|---|
| 速度 | 高 | 低 |
| 磁头 | 固定、活动、浮动 | 活动、接触盘片 |
| 盘片 | 固定盘、盘组大部分不可换 | 可换盘片 |
| 价格 | 高 | 低 |
| 环境 | 苛刻 | 不苛刻 |
2. 软盘片
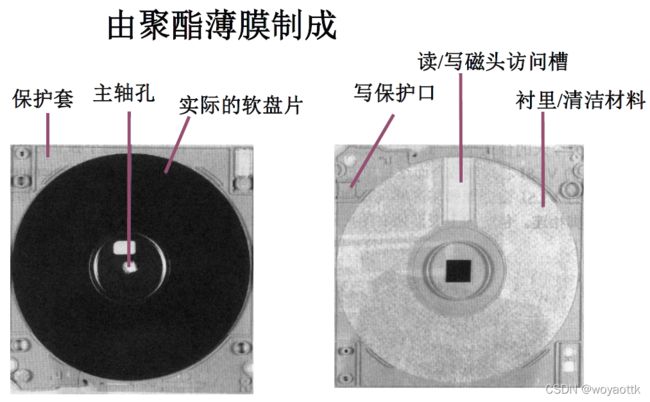
五、光盘存储器
1. 概述
采用光存储技术 利用激光写入和读出
第一代光存储技术 采用非磁性介质 不可擦写
第二代光存储技术 采用磁性介质 可擦写
2. 光盘的存储原理
只读型和只写一次型 热作用(物理或化学变化)
可擦写光盘 热磁效应