经典神经网络——GoogLeNet模型论文详解及代码复现
论文地址:[1409.4842] Going Deeper with Convolutions (arxiv.org)
一、GoogLeNet概述
创新点
我认为,这篇文章最大的创新点是引入了一个名为Inception块的结构,能够增加神经网络模型大小的同时,减缓参数量的爆炸式增长,从而提升神经网络模型的表现。
准确率
一个简单的网络,是无法达到很好的表现,因为它的参数简单,表达的信息很少。所以我们想要一个表现很好的网络模型,我们就需要将这个网络变宽、变深。对应到网络模型中就是增加网络的层数(变深),增加通道数(变宽)。
问题
有过基础知识的我们都知道,增加网络的层数和通道数,这件事会让模型的参数增加,会需要占用很多的算力,我们有可能算不动;而且参数多了,容易过拟合。
所以我们需要一个能够代替堆叠卷积层,既可以让网络变宽变深的同时,又能够让参数爆炸式增长的东西。
解决方法
本文提出了一个名为Inception的模块,如图2,可以实现在不改变图片尺寸的前提下,只改变输入输出的通道数,关键这个模块比使用较大的kernel的卷积核所带来的参数量更少,使用Inception模块就可以让网络变宽变深,从而提高模型的准确率。
二、GoogLeNet网络结构
GoogLeNet开始模块
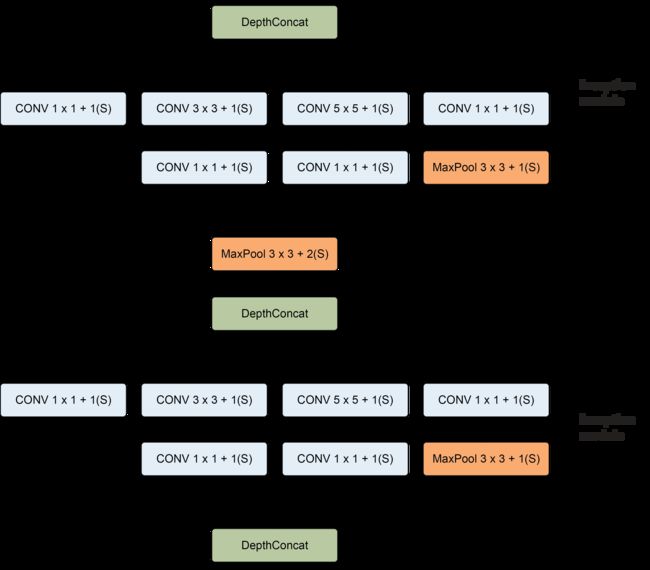
GoogLeNet架构
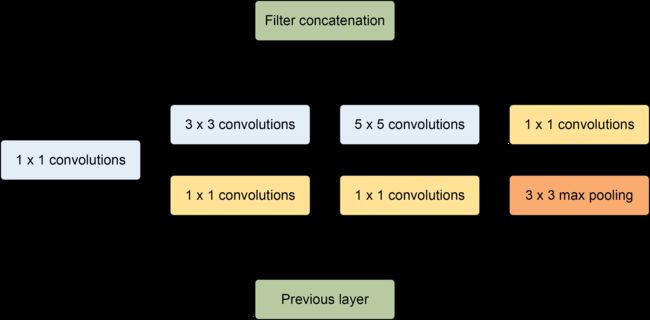
Inception Module基本组成结构有四个成分:1x1卷积,3x3卷积,5x5卷积,3x3最大池化,最后对四个成分运算结果进行通道上组合,这就是Naive Inception的核心思想:利用不同大小的卷积核实现不同尺度的感知,最后进行融合,可以得到图像更好的表征。
注意:每个分支得到的特征矩阵高和宽必须相同。
但是Naive Inception有两个非常严重的问题:首先,所有卷积层直接和前一层输入的数据对接,所以卷积层中的计算量会很大;其次,在这个单元中使用的最大池化层保留了输入数据的特征图的深度,所以在最后进行合并时,总的输出的特征图的深度只会增加,这样增加了该单元之后的网络结构的计算量。所以这里使用1x1 卷积核主要目的是进行压缩降维,减少参数量,也就是上图b,从而让网络更深、更宽,更好的提取特征,这种思想也称为Pointwise Conv,简称PW。
三、GoogLeNet使用PyTorch框架实现
因需要对GPU显存要求过高,本人在kaggle上的GPU T4X2上运行的
kaggle地址:GoogLeNet | Kaggle
import torch
from torch import nn
import sys
sys.path.append("../input/d2ld2l")
import d2l
from d2l.torch import load_data_fashion_mnist
from d2l.torch import train_ch6
from d2l.torch import try_gpuclass Inception(nn.Module):
def __init__(self,in_channels,c1,c2,c3,c4,**kwarqs):
super(Inception,self).__init__(**kwarqs)
self.p1 = nn.Sequential(
nn.Conv2d(in_channels,c1,kernel_size=1),
nn.ReLU()
)
self.p2 = nn.Sequential(
nn.Conv2d(in_channels,c2[0],kernel_size=1),
nn.ReLU(),
nn.Conv2d(c2[0],c2[1],kernel_size=3,padding=1),
nn.ReLU()
)
self.p3 = nn.Sequential(
nn.Conv2d(in_channels,c3[0],kernel_size=1),
nn.ReLU(),
nn.Conv2d(c3[0],c3[1],kernel_size=5,padding=2),
nn.ReLU()
)
self.p4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3,padding=1,stride=1),
nn.Conv2d(in_channels,c4,kernel_size=1),
nn.ReLU()
)
def forward(self,x):
return torch.cat((self.p1(x),self.p2(x),self.p3(x),self.p4(x)),dim=1)in_channels =1
b1 = nn.Sequential(
nn.Conv2d(in_channels,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
b2 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=1),
nn.ReLU(),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
b3 = nn.Sequential(
Inception(192,64,(96,128),(16,32),32),
Inception(256,128,(128,192),(32,96),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
b4 = nn.Sequential(
Inception(480,192,(96,208),(16,48),64),
Inception(512,160,(112,224),(24,64),64),
Inception(512,128,(128,256),(24,64),64),
Inception(512,112,(144,288),(32,64),64),
Inception(528,256,(160,320),(32,128),128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
b5 = nn.Sequential(
Inception(832,256,(160,320),(32,128),128),
Inception(832,384,(192,384),(48,128),128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Dropout(p=0.4),
nn.Flatten()
)
net = nn.Sequential(b1,b2,b3,b4,b5,nn.Linear(1024,10))test = torch.rand((1,1,224,224))
for layer in net:
test = layer(test)
print(layer.__class__.__name__,'output shape:\t',test.shape)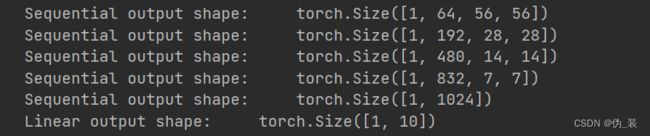
lr,num_epochs,batch_size = 0.1,10,128
train_iter,test_iter = load_data_fashion_mnist(batch_size,resize=128)
train_ch6(net,train_iter,test_iter,num_epochs,lr,try_gpu())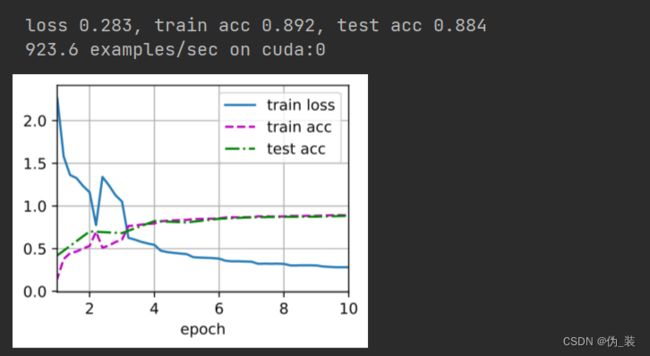
四、GoogLeNet使用keras框架实现
1、导入库
import cv2
import numpy as np
import keras
import math
import keras.backend as K
import tensorflow as tf
from keras.datasets import cifar10
from keras.models import Model
from keras.layers import Conv2D, MaxPool2D, \
Dropout, Dense, Input, concatenate, \
GlobalAveragePooling2D, AveragePooling2D,\
Flatten
from keras.datasets import cifar10
from keras import backend as K
from keras.utils import to_categorical
from keras.optimizers import SGD
from keras.callbacks import LearningRateScheduler2、准备数据集
num_classes = 10
def load_cifar10_data(img_rows, img_cols):
# Load cifar10 training and validation sets
(X_train, Y_train), (X_valid, Y_valid) = cifar10.load_data()
# Resize training images
X_train = np.array([cv2.resize(img, (img_rows,img_cols)) for img in X_train[:,:,:,:]])
X_valid = np.array([cv2.resize(img, (img_rows,img_cols)) for img in X_valid[:,:,:,:]])
# Transform targets to keras compatible format
Y_train = to_categorical(Y_train, num_classes)
Y_valid = to_categorical(Y_valid, num_classes)
X_train = X_train.astype('float32')
X_valid = X_valid.astype('float32')
# preprocess data
X_train = X_train / 255.0
X_valid = X_valid / 255.0
return X_train, Y_train, X_valid, Y_validX_train, y_train, X_test, y_test = load_cifar10_data(224, 224)3、创建初始模块
def inception_module(x,
filters_1x1,
filters_3x3_reduce,
filters_3x3,
filters_5x5_reduce,
filters_5x5,
filters_pool_proj,
name=None):
conv_1x1 = Conv2D(filters_1x1, (1, 1), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filters_3x3_reduce, (1, 1), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filters_3x3, (3, 3), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_3x3)
conv_5x5 = Conv2D(filters_5x5_reduce, (1, 1), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(x)
conv_5x5 = Conv2D(filters_5x5, (5, 5), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(conv_5x5)
pool_proj = MaxPool2D((3, 3), strides=(1, 1), padding='same')(x)
pool_proj = Conv2D(filters_pool_proj, (1, 1), padding='same', activation='relu', kernel_initializer=kernel_init, bias_initializer=bias_init)(pool_proj)
output = concatenate([conv_1x1, conv_3x3, conv_5x5, pool_proj], axis=3, name=name)
return output4.创建 GoogLeNet 架构
kernel_init = keras.initializers.glorot_uniform()
bias_init = keras.initializers.Constant(value=0.2)input_layer = Input(shape=(224, 224, 3))
x = Conv2D(64, (7, 7), padding='same', strides=(2, 2), activation='relu', name='conv_1_7x7/2', kernel_initializer=kernel_init, bias_initializer=bias_init)(input_layer)
x = MaxPool2D((3, 3), padding='same', strides=(2, 2), name='max_pool_1_3x3/2')(x)
# x = Conv2D(64, (1, 1) padding='same', strides=(1, 1), activation='relu', name='conv_2a_3x3/1')(x)
x = Conv2D(192, (3, 3), padding='same', strides=(1, 1), activation='relu', name='conv_2b_3x3/1')(x)
x = MaxPool2D((3, 3), padding='same', strides=(2, 2), name='max_pool_2_3x3/2')(x)
x = inception_module(x,
filters_1x1=64,
filters_3x3_reduce=96,
filters_3x3=128,
filters_5x5_reduce=16,
filters_5x5=32,
filters_pool_proj=32,
name='inception_3a')
x = inception_module(x,
filters_1x1=128,
filters_3x3_reduce=128,
filters_3x3=192,
filters_5x5_reduce=32,
filters_5x5=96,
filters_pool_proj=64,
name='inception_3b')
x = MaxPool2D((3, 3), padding='same', strides=(2, 2), name='max_pool_3_3x3/2')(x)
x = inception_module(x,
filters_1x1=192,
filters_3x3_reduce=96,
filters_3x3=208,
filters_5x5_reduce=16,
filters_5x5=48,
filters_pool_proj=64,
name='inception_4a')
classifier_1 = AveragePooling2D((5, 5), strides=3)(x)
classifier_1 = Conv2D(128, (1, 1), padding='same', activation='relu')(classifier_1)
classifier_1 = Flatten()(classifier_1)
classifier_1 = Dense(1024, activation='relu')(classifier_1)
classifier_1 = Dropout(0.7)(classifier_1)
classifier_1 = Dense(10, activation='softmax', name='auxilliary_output_1')(classifier_1)
x = inception_module(x,
filters_1x1=160,
filters_3x3_reduce=112,
filters_3x3=224,
filters_5x5_reduce=24,
filters_5x5=64,
filters_pool_proj=64,
name='inception_4b')
x = inception_module(x,
filters_1x1=128,
filters_3x3_reduce=128,
filters_3x3=256,
filters_5x5_reduce=24,
filters_5x5=64,
filters_pool_proj=64,
name='inception_4c')
x = inception_module(x,
filters_1x1=112,
filters_3x3_reduce=144,
filters_3x3=288,
filters_5x5_reduce=32,
filters_5x5=64,
filters_pool_proj=64,
name='inception_4d')
classifier_2 = AveragePooling2D((5, 5), strides=3)(x)
classifier_2 = Conv2D(128, (1, 1), padding='same', activation='relu')(classifier_2)
classifier_2 = Flatten()(classifier_2)
classifier_2 = Dense(1024, activation='relu')(classifier_2)
classifier_2 = Dropout(0.7)(classifier_2)
classifier_2 = Dense(10, activation='softmax', name='auxilliary_output_2')(classifier_2)
x = inception_module(x,
filters_1x1=256,
filters_3x3_reduce=160,
filters_3x3=320,
filters_5x5_reduce=32,
filters_5x5=128,
filters_pool_proj=128,
name='inception_4e')
x = MaxPool2D((3, 3), padding='same', strides=(2, 2), name='max_pool_4_3x3/2')(x)
x = inception_module(x,
filters_1x1=256,
filters_3x3_reduce=160,
filters_3x3=320,
filters_5x5_reduce=32,
filters_5x5=128,
filters_pool_proj=128,
name='inception_5a')
x = inception_module(x,
filters_1x1=384,
filters_3x3_reduce=192,
filters_3x3=384,
filters_5x5_reduce=48,
filters_5x5=128,
filters_pool_proj=128,
name='inception_5b')
x = AveragePooling2D(pool_size=(7,7), strides=1, padding='valid',name='avg_pool_5_3x3/1')(x)
x = Dropout(0.4)(x)
x = Dense(1000, activation='relu', name='linear')(x)
x = Dense(1000, activation='softmax', name='output')(x)不带 1 类和 2 类过滤器的 GoogleNet 模型
model = Model(input_layer, [x], name='googlenet')model.summary()添加分类器 1 和 2 后的 GoogLeNet 模型
model_with_classifiers = Model(input_layer, [x, classifier_1, classifier_2], name='googlenet_complete_architecture')
model_with_classifiers.summary()用三个模型编制网络
epochs = 25
initial_lrate = 0.01
def decay(epoch, steps=100):
initial_lrate = 0.01
drop = 0.96
epochs_drop = 8
lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
sgd = SGD(lr=initial_lrate, momentum=0.9, nesterov=False)
lr_sc = LearningRateScheduler(decay, verbose=1)
model_with_classifiers.compile(loss=['categorical_crossentropy', 'categorical_crossentropy', 'categorical_crossentropy'],
loss_weights=[1, 0.3, 0.3], optimizer=sgd, metrics=['accuracy'])
history = model_with_classifiers.fit(X_train, [y_train, y_train, y_train], validation_data=(X_test, [y_test, y_test, y_test]),
epochs=epochs, batch_size=256, callbacks=[lr_sc])