还不会用Mybatis-Plus?快看全网最通俗易懂的MyBatis-Plus讲解(入门)
概述
为什么出现MyBatis-Plus
登陆Mybatis-Plus的官网,可以看到显目的给出一句话,为简化开发而生
用过Mybatis的伙伴应该知道项目中的大量业务都是CRUD操作,业务逻辑不复杂,但是我们总是要去写重复的增删改查的Sql语句,这样很影响我们的开发效率,而Mybatis-Plus的出现解决了这一问题,他在内部已经实现了我们常用的CRUD操作,我们直接调用即可,这样可以大大增加我们的开发效率
Mybatis的历史
原是apache的一个开源项目iBatis, 2010年6月这个项目由apache software foundation迁移到了google code,随着开发团队转投Google Code旗下,ibatis3.x正式更名为Mybatis ,代码于2013年11月迁移到Github。
到现在的Mybatis-Plus的版本,针对Mybatis的情况做了更多的简化
MyBatis-Plus和Mybatis的区别
MyBatis-Plus(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
MP是在Mybatis的基础上做的升级,并不会影响之前Mybatis的所有操作
特性
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
安装配置
添加依赖
在Pom中加入对应的Plus依赖以及数据库驱动等依赖
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.3.2version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.10version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.16version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-validationartifactId>
dependency>
yaml文件配置
mybatis-plus:
#配置Mapper.xml文件的存放位置
mapper-locations: classpath:/mapper/**/*.xml
configuration:
#下划线转驼峰
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #想要查看执行的 sql 语句
spring:
datasource:
url: jdbc:mysql://localhost:3306/tiny?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: 123456
快速入门
数据库环境
MySql中执行以下sql命令,创建对应的表结构
DROP TABLE IF EXISTS user;
CREATE TABLE user
(
id BIGINT(20) NOT NULL COMMENT '主键ID',
name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',
age INT(11) NULL DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (id)
);
INSERT INTO user (id, name, age, email) VALUES
(1, 'Jone', 18, '[email protected]'),
(2, 'Jack', 20, '[email protected]'),
(3, 'Tom', 28, '[email protected]'),
(4, 'Sandy', 21, '[email protected]'),
(5, 'Billie', 24, '[email protected]');
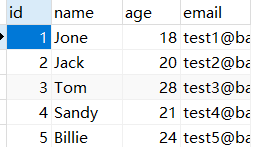
得到以下数据表
启动类配置
在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹
@SpringBootApplication
@MapperScan("com.boss.bk.demo.mapper")
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
编码
编写实体类 User.java(此处使用了 Lombok简化代码)
@Data
public class User {
private Long id;
private String name;
private Integer age;
private String email;
}
编写Mapper类 UserMapper.java
public interface UserMapper extends BaseMapper<User> {
}
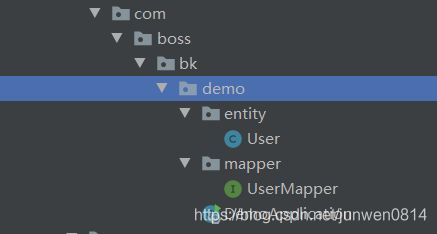
代码结构如下
开始使用
直接通过userMapper内置的selectList方法获取数据表里的数据,不需要再去写重复性的sql语句了
@RunWith(SpringRunner.class)
@SpringBootTest
public class SampleTest {
@Autowired
private UserMapper userMapper;
@Test
public void testSelect() {
System.out.println(("----- selectAll method test ------"));
List<User> userList = userMapper.selectList(null);
userList.forEach(System.out::println);
}
}
输出
User(id=1, name=Jone, age=18, [email protected])
User(id=2, name=Jack, age=20, [email protected])
User(id=3, name=Tom, age=28, [email protected])
User(id=4, name=Sandy, age=21, [email protected])
User(id=5, name=Billie, age=24, [email protected])
进阶学习
这里介绍一下MP中内置的功能
注解
@TableName
- 描述:表名注解
用于指定实体类上绑定的是数据库中的哪个表名称,如果不指定的话,他会按照实体类的类名去数据库搜索
CRUD接口
Mapper CRUD 接口
- 继承于BaseMapper接口,接口中内置了常用的CRUD的方法
- 对象
Wrapper为 条件构造器,条件就是类似我们Sql里的where语句,传NULL表示没有条件
Insert
User user = new User();
user.setId(7L);
user.setAge(12);
user.setEmail("123333@[email protected]");
user.setName("张三");
userMapper.insert(user);
Delete
LambdaUpdateWrapper是使用了lambda表达式的条件构造器,可以直接指定对象的get方法,防止硬编码写数据库字段不好维护
以下的条件的是删除用户表中id为7的用户信息
//方式一,通过条件删除
LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper<>();
wrapper.eq(User::getId, 7L);
userMapper.delete(wrapper);
//方式二,直接传用户ID进行删除
userMapper.deleteById(7L);
Update
//方式一 通过条件删除,注意如果没有给条件会全表更新的
User user = new User();
user.setName("修改的名称");
LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper();
wrapper.eq(User::getId, 7L);
userMapper.update(user, wrapper);
//方式二 通过实体类给的ID进行修改数据
User user = new User();
user.setId(7L);
user.setName("修改的名称222");
userMapper.updateById(user);
Select
//方式一 通过ID查找
User user = userMapper.selectById(7L);
//方式二 通过条件查找唯一的一条记录
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper();
wrapper.eq(User::getId,7);
User user = userMapper.selectOne(wrapper);
//方式三 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
//方式四 分页查询,需要搭配分页插件并注册到Spirng中进行使用,下面会讲到
Page<User> page = new Page<>();
Page<User> pageResult = userMapper.selectPage(page, null);
Serviec CRUD接口
一、配置
这个Service的方式是在Mapper方式基础上升级的,配置方式如下
创建一个Service接口,实现IService接口
public interface UserService extends IService {
}
创建Service接口的实现类,继承ServiceImpl类并实现用户接口
继承这个操作其实就是保留原有的mapper一系列的方法进行,在这基础上还可以使用Service新的接口,如果你想要使用mapper里的方法,你可以在类中直接调用方法即可
@Service
public class UserServiceImpl extends ServiceImpl implements UserService {
}
二、使用
Save
//方式一 插入单个对象
User user = new User();
user.setId(7L);
user.setAge(12);
user.setEmail("123333@[email protected]");
user.setName("张三");
userService.save(user);
//方式二 批量插入对象
List<User> list = new ArrayList<>();
...
userService.saveBatch(list);
//方式三 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList);
saveOrUpdate
//方式一 User对象字段上有加TableId注解的判断存在就更新,否则插入
User user = new User();
user.setId(7L);
user.setAge(13);
user.setEmail("123333@[email protected]");
userService.saveOrUpdate(user);
//方式二 也可以放入更新的条件进入方法中,如果没有找到可更新的就会继续执行saveOrUpdate(T)方法
LambdaUpdateWrapper<User> wrapper = new LambdaUpdateWrapper();
wrapper.eq(User::getAge, 12);
userService.saveOrUpdate(user, wrapper);
Remove
// 根据 entity 条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);
Update
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);
Get
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
List
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
Page
// 无条件分页查询
IPage<T> page(IPage<T> page);
// 条件分页查询
IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);
// 无条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page);
// 条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);
Count
// 查询总记录数
int count();
// 根据 Wrapper 条件,查询总记录数
int count(Wrapper<T> queryWrapper);
Chain
query
// 链式查询 普通
QueryChainWrapper<T> query();
// 链式查询 lambda 式。注意:不支持 Kotlin
LambdaQueryChainWrapper<T> lambdaQuery();
// 示例:
query().eq("column", value).one();
lambdaQuery().eq(Entity::getId, value).list();
update
// 链式更改 普通
UpdateChainWrapper<T> update();
// 链式更改 lambda 式。注意:不支持 Kotlin
LambdaUpdateChainWrapper<T> lambdaUpdate();
// 示例:
update().eq("column", value).remove();
lambdaUpdate().eq(Entity::getId, value).update(entity);
分页
要使用分页需要增加一个分页配置类,把PaginationInterceptor注册给Spring容器
@Configuration
public class MybatisPageConfig {
@Bean
public PaginationInterceptor paginationInterceptor() {
PaginationInterceptor paginationInterceptor = new PaginationInterceptor();
paginationInterceptor.setCountSqlParser(new JsqlParserCountOptimize(true));
return paginationInterceptor;
}
}
测试分页
@Test
public void pageTest() {
Page<User> page = new Page<>();
Page<User> result = userService.page(page);
System.out.println(result);
}
Wrapper条件筛选
在搜索的时候,可以使用LambdaQueryWrapper这个条件类,支持lambda,这样指定数据库字段的时候可以用对象的字段指定,不需要硬编码的写上去
LambdaQueryWrapper<BannerItem> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(BannerItem::getBannerId, id);
List<BannerItem> bannerItems = bannerItemMapper.selectList(wrapper);
项目示例
这里提供了本文章介绍的项目示例,想要验证的可以下载下来调用一下
项目源码
个人公众号
喜欢的可以关注我的公众号,不定期会发布相关技术的文章
