【公开课】百度——开放域对话技术
【语言与知识技术峰会系列公开课】开放域对话技术
视频链接地址:https://www.bilibili.com/video/BV1754y1m7x6
对开放域对话系统感兴趣的同学,强烈推荐大家去观看原视频学习
目录
- 【语言与知识技术峰会系列公开课】开放域对话技术
- 前言
-
- 对话系统分类:
- 端到端对话生成的挑战
- 多样化对话生成
-
- 相关工作
- 训练阶段
- 预测阶段
- 实验效果
- 知识对话生成
-
- 相关工作
- 训练阶段
- 预测阶段
- 实验效果
- 自动化评价和对话流控制
-
- 实验效果
- 大规模和超大规模空间对话生成模型——PLATO
-
- 模型结构与训练语料
- PLATO全览
- 实验结果
前言
对话系统分类:
- 任务型对话系统 Task-Oriented
- 开放域对话系统 Open-Domain
对于其中开放域对话系统,有下图这样常见的模型结构seq2seq,通过损失函数Negative Log-Likelihood即Cross-Entropy训练模型:

使用Encoder端编码对话上文,在Decoder端逐字进行解码回复
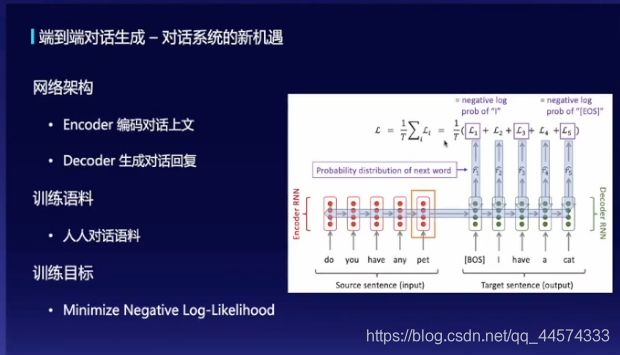
端到端对话生成的挑战

在生成对话中,还有这样一个不可避免的问题:一对多问题(一个上文,可能对应多个不同的下文回复)。但传统的神经网络始终是个一一映射的函数。
在上述问题思考上,本次公开课给出了下面的四种解答方案
百度NLP:做有知识、可控的对话生成
多样化对话生成
如何用神经网络(传统一对一映射网络)来拟合来自不同背景的语料(一对多回复问题)
这里,引出了一种多映射机制的端到端生成模型
假设:每一句回复可能来自于一个独特的映射机制
相关工作

- 连续高斯空间比较难平衡对话的多样性和回复的流畅性
- 先验和后验差异大,导致映射模块很差
对此,老师给出了他们做的两个创新点:
- 离散的映射机制
- 分离后验和先验推断
训练阶段
模型结构概览如下图
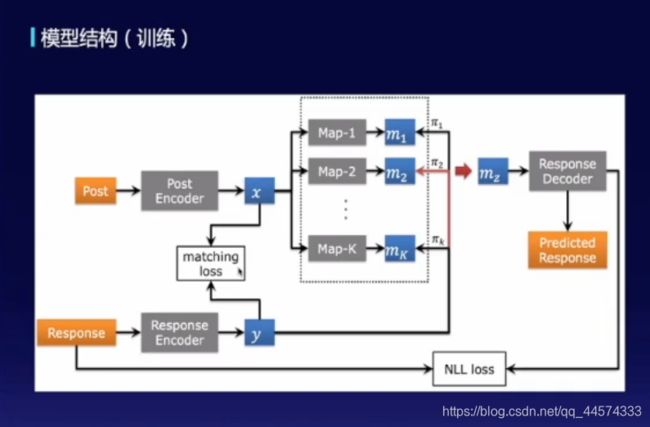
Post:上文经过编码得到x,通过不同的映射模块得到不同的语义空间表示 m 1 — — m k m1——m_k m1——mk,此时利用回复信息y当作后验的估计来进行采样找到合适的语义空间 m z m_z mz进行回复的生成
Response:回复经过编码得到y

上述的采样,使用Gumbel-Softmax来做近似,使得梯度并不会断掉
对于Gumbel-Softmax的解释,简单而言,就是将在已有概率分布下如果用argmax则是确定的将不连续、不可导,无法更新梯度,故填加了一个概率分布参数并使用softmax替代argmax,这样就可导了。
重参数技巧就是解决概率分布矩阵如果用argmax反向更新梯度时不存在。在采样前(前向)用z=loga+G替代了argmax,G是gumbel分布,在采样后(反向)用更新loga代表更新probality distribution,且这种对于离散隐变量的采样,保证梯度不会断,且有这比argmax更概率的表示
回到模型部分,此时损失函数不仅有常用的NLL loss(Negative Log-Likelihood即Cross-Entropy),还有一个辅助的matching loss。引入这个matching loss的原因是,在模型训练时发现根据response y 去选映射模块m时总会去选某一个模块,又变成了传统的seq2seq,其解释为可能因为训练刚开始阶段Response的Encoder区分能力不够,导致抽出的y不够好,所以在后验估计上就不够准确,为了提升Response的Encoder的区分度,就引入了matching loss,用来判断x、y是否是来自同一个上下文的(二分类)
预测阶段

训练阶段:
Post:上文经过编码得到x,通过不同的映射模块得到不同的语义空间表示 m 1 — — m k m1——m_k m1——mk,此时利用回复信息y当作后验的估计来进行采样找到合适的语义空间 m z m_z mz进行回复的生成
预测阶段:
Post:上文经过编码得到x,通过不同的映射模块得到不同的语义空间表示 m 1 — — m k m1——m_k m1——mk,此时随机选择一个或多个映射模块,这样就可以得到多个候选回复
实验效果


对于多样化对话生成,可以参考上图论文链接深入了解学习
知识对话生成
相关工作

对于知识对话,我们不仅有对话的上下文还有一定的知识库,如个人背景设定、知识信息

该怎么在对话中引入知识呢?算Attention是一种直接想法
但也会有这样的问题,先验和后验之间有较大差异。比如在先验中应该使用知识K1、K3,但是后验仅使用了K3
针对这个问题,提出了一个新的模型架构
训练阶段

utterrance X:对话上文X经过编码得到x
knowledge:知识经过编码得到k1、k2、k3等
response Y:对话回复经过编码得y
-
首先,会使用上文x和回复y去做知识的后验估计,即posterior distribution
p ( k i ∣ x , y ) p(k_i|x,y) p(ki∣x,y)
有了这个后验估计posterior distribution,就可以采样(Gumbel-Softmax)得到某一知识k,然后用这条知识k与对话上下文去生成回复,计算NLL loss -
然后,还有这样一个辅助loss:BOW Loss,使用采样得到的知识k来尽可能预测response Y中的信息(单词)。也就是说如果知识k选的准,去估计response的loss就会小;选的不准loss就会比较大。这个BOW Loss提升了后验估计的效果
-
最后,还有这样的loss:KLDivLoss,先验模块损失函数,就是说在仅有对话上文x时,要尽量找到选取合适的知识。因为在后验估计中还有回复信息,故使得估计的posterior distribution概率更容易更好,所以希望先验的估计prior distribution与posterior distribution越接近越好,拉近先验和后验的距离
预测阶段
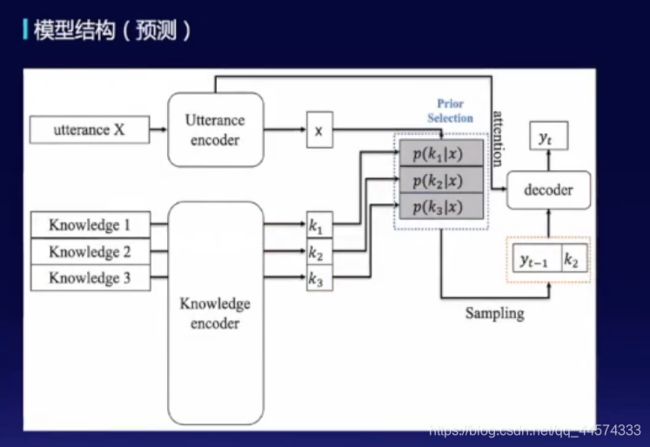
预测阶段仅使用先验模块,根据x和k的prior distribution选取合适知识 k i k_i ki,将 k i k_i ki与上文一起交给Decoder端解码生成回复
实验效果

对于知识对话生成,可以参考上图论文链接深入了解学习
自动化评价和对话流控制
在知识引入的生成对话中,还是存在下面的问题

为解决多轮对话的上述问题,提出了这样的系统:自进化对话系统(SEEDS)

通过两个机器人进行对话,使用自动评测指标返回Reward进行“自进化”训练
Controller:根据上文来估计Controller z(如知识)
Generation:根据选择不同的Controller z和上文进行不同的对话生成
实验效果

对于自进化对话生成,可以参考上图论文链接深入了解学习
大规模和超大规模空间对话生成模型——PLATO
模型结构与训练语料
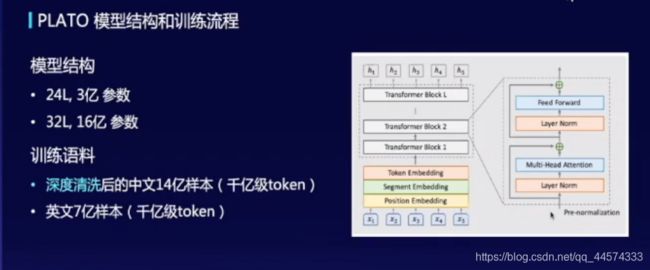
上图有些不清晰,模型概要请参照下图
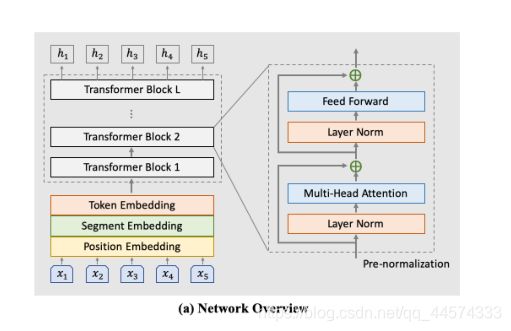
对于PLATO模型结构中,也是使用了多个Transformer Block组成,值得注意的在其中使用的是与GPT一致的Pre-normalization:layerNorm在残差连接前,而BERT使用的Post-normalization:layerNorm在残差连接后。实验表明Pre-normalization可以在更多的数据量和参数量扩展效果更好

在PLATO中,使用了两个训练阶段:第一阶段就是简化的一对一映射,第二阶段就是一对多建模
PLATO全览
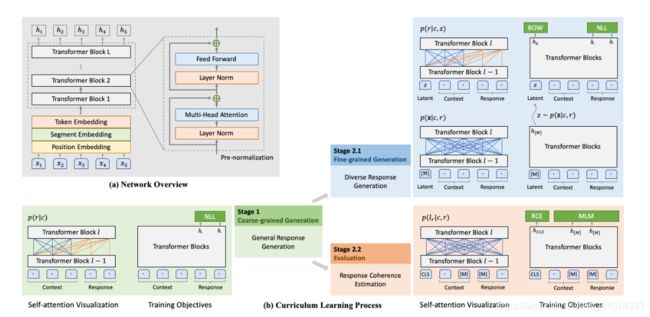
PLATO在Transformer Block结构上,进行了两个阶段的课程训练
第一阶段:一对一训练,训练时是双向的attention,回复时是单向的attention
第二阶段:在第一阶段基础上,2.1阶段引入离散隐变量Latent,首先进行Latent的概率估计,然后进行采样得到 L a t e n t i Latent_i Latenti,与上文一起来控制回复生成。此时的损失函数除了NLL loss外也还有BOW loss,而BOW是不考虑词的顺序性的,一次性就估计出来了,而NLL loss在产生第t个单词,是只能看到t-1、t-2等等之前的单词。也就是说BOW是考虑到了整个response的全局信息。除了2.1的细粒度生成过程,还有2.2的评估模型,用于判断上文和回复的相关性,除了RCE回复相关度的判断,还有MLM的loss,掩码语言模型loss。
最终,我们可以得到两个模型的,一个是细粒度生成(2.1),一个是评估模型(2.2),最终根据这两个模型进行回复生成
实验结果

实验效果简要概括:SOTA!
最后老师给出了开放域对话系统的未来研究方向:
