Python爬虫入门基础及正则表达式抓取博客案例分享
文章目录
- 一.什么是网络爬虫
- 二.正则表达式
-
- 1.re模块
- 2.complie方法
- 3.match方法
- 4.search方法
- 5.group和groups方法
- 三.Python网络数据爬取的常用模块
-
- 1.urllib模块
- 2.urlparse模块
- 四.正则表达式抓取网络数据的常见方法
-
- 1.抓取标签间的内容
- 2.爬取标签中的参数
- 3.字符串处理及替换
- 五.个人博客爬取实例
-
- 1.分析过程
- 2.代码实现
- 六.总结
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤
QQ群:623406465
一.什么是网络爬虫
随着互联网的迅速发展,万维网成为大量信息的载体,越来越多的网民可以通过互联网获取所需的信息,同时如何有效地提取并利用这些信息也成为了一个巨大的挑战。搜索引擎(Search Engine)作为辅助人们检索信息的工具,它成为了用户访问万维网的入口和工具,常见的搜索引擎比如Google、Yahoo、百度、搜狗等。但是,这些通用性搜索引擎也存在着一定的局限性,比如搜索引擎返回的结果包含大量用户不关心的网页;再如它们是基于关键字检索,缺乏语义理解,导致反馈的信息不准确;通用的搜索引擎无法处理非结构性数据,图片、音频、视频等复杂类型的数据。
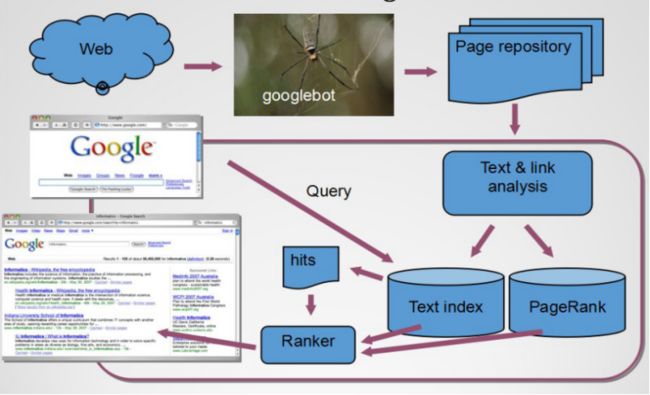
为了解决上述问题,定向抓取相关网页资源的网络爬虫应运而生,下图是Google搜索引擎的架构图,它从万维网中爬取相关数据,通过文本和连接分析,再进行打分排序,最后返回相关的搜索结果至浏览器。同时,现在比较热门的知识图谱也是为了解决类似的问题而提出的。
网络爬虫又被称为网页蜘蛛或网络机器人,它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。网络爬虫根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫不同,定向爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
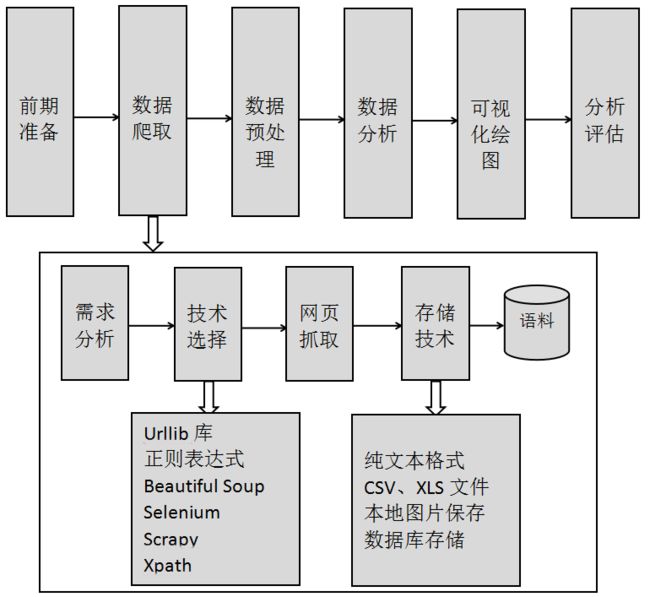
数据分析通常包括前期准备、数据爬取、数据预处理、数据分析、可视化绘图及分析评估六个步骤,如下图所示。其中数据爬取主要划分为四个步骤:
- 需求分析。首先需要分析网络数据爬取的需求,了解所爬取主题的网址、内容分布,所获取语料的字段、图集等内容。
- 技术选择。网页抓取技术可以通过Python、Java、C++、C#等不同编程语言实现,主要涉及的技术包括:Urllib库、正则表达式、Selenium、BeautifulSoup、Scrapy等技术。
- 网页抓取。确定好爬取技术后,需要分析网页的DOM树结构,通过XPATH技术定位网页所爬取内容的节点,再抓取数据;同时,部分网站涉及到页面跳转、登录验证等。
- 存储技术。数据存储技术主要是存储爬取的数据信息,主要包括SQL数据库、纯文本格式、CSV\XLS文件等。
作者希望大家能从基础跟着我学习Python知识,最后能抓取你需要的数据集并进行深入的分析,一起加油吧!
二.正则表达式
正则表达式是用于处理字符串的强大工具,通常被用来检索、替换那些符合某种规则的文本。这篇文章首先引入正则表达式的基本概念,然后讲解其常用的方法,并结合Python网络数据爬取常用模块和常见正则表达式的网站分析方法进行讲解,最后使用正则表达式爬取了个人博客网站。
正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索、替换那些符合某个模式的文本,它首先设定好了一些特殊的字符及字符组合,通过组合的“规则字符串”来对表达式进行过滤,从而获取或匹配我们想要的特定内容。它非常灵活,其逻辑性和功能性也非常强,并能迅速地通过表达式从字符串中找到所需信息,但对于刚接触的人来说,比较晦涩难懂。
由于正则表达式主要应用对象是文本,因此它在各种文本编辑器中都有应用,小到著名编辑器EditPlus,大到Microsoft Word、Visual Studio等大型编辑器,都可以使用正则表达式来处理文本内容。
1.re模块
Python通过re模块提供对正则表达式的支持,但在使用正则表达式之前需要导入re模块,才能调用该模块的功能函数。
- import re
其基本步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得一个匹配(match)实例,再使用match实例获得所需信息。常用的函数是findall,原型如下:
- findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
该函数表示搜索字符串string,以列表形式返回全部能匹配的子串。其中参数re包括三个常见值,每个常见值括号内的内容是完整的写法。
- re.I(re.IGNORECASE):使匹配忽略大小写
- re.M(re.MULTILINE):允许多行匹配
- re.S(re.DOTALL):匹配包括换行在内的所有字符
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。Pattern不能直接实例化,必须使用re.compile()进行构造。
2.complie方法
re正则表达式模块包括一些常用的操作函数,比如complie()函数。其原型如下:
- compile(pattern[,flags] )
该函数根据包含正则表达式的字符串创建模式对象,返回一个pattern对象。参数flags是匹配模式,可以使用按位或“|”表示同时生效,也可以在正则表达式字符串中指定。Pattern对象是不能直接实例化的,只能通过compile方法得到。
简单举个实例,使用正则表达式获取字符串中的数字内容,如下所示:
>>> import re
>>> string="A1.45,b5,6.45,8.82"
>>> regex = re.compile(r"\d+\.?\d*")
>>> print regex.findall(string)
['1.45', '5', '6.45', '8.82']
>>>
3.match方法
match方法是从字符串的pos下标处起开始匹配pattern,如果pattern结束时已经匹配,则返回一个match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。该方法原型如下:
- match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
参数string表示字符串;pos表示下标,pos和endpos的默认值分别为0和len(string);参数flags用于编译pattern时指定匹配模式。
4.search方法
search方法用于查找字符串中可以匹配成功的子串。从字符串的pos下标处尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个match对象;若pattern结束时仍无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。函数原型如下:
- search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
参数string表示字符串;pos表示下标,pos和endpos的默认值分别为0和len(string));参数flags用于编译pattern时指定匹配模式。
5.group和groups方法
group([group1, …])方法用于获得一个或多个分组截获的字符串,当它指定多个参数时将以元组形式返回,没有截获字符串的组返回None,截获了多次的组返回最后一次截获的子串。groups([default])方法以元组形式返回全部分组截获的字符串,相当于多次调用group,其参数default表示没有截获字符串的组以这个值替代,默认为None。
三.Python网络数据爬取的常用模块
本小节介绍Python网络数据爬取的常用模块或库,主要包括urlparse模块、urllib模块、urllib2模块和requests模块,这些模块中的函数都是基础知识,但也非常重要。
1.urllib模块
本书首先介绍Python网络数据爬取最简单并且应用比较广泛的第三方库函数urllib。urllib是Python用于获取URL(Uniform Resource Locators,统一资源定址器)的库函数,可以用来抓取远程数据并保存,甚至可以设置消息头(header)、代理、超时认证等。
urllib模块提供的上层接口让我们像读取本地文件一样读取www或ftp上的数据。它比C++、C#等其他编程语言使用起来更方便。其常用的方法如下:
- urlopen
urlopen(url, data=None, proxies=None)
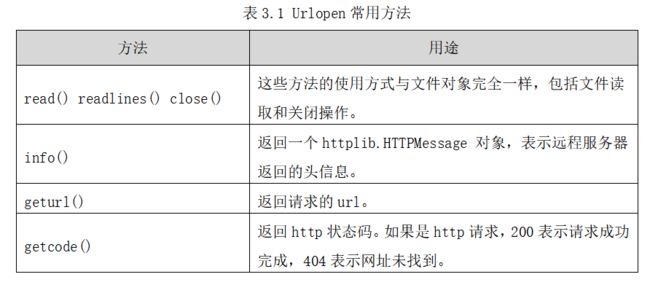
该方法用于创建一个远程URL的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。参数url表示远程数据的路径,一般是网址;参数data表示以post方式提交到url的数据;参数proxies用于设置代理。urlopen返回一个类文件对象。urlopen提供了如下表所示。
注意,在Python中我们可以导入相关扩展包,通过help函数查看相关的使用说明,如下图所示。

下面通过一个实例讲述Urllib库函数爬取百度官网的实例。
# -*- coding:utf-8 -*-
import urllib.request
import webbrowser as web
url = "http://www.baidu.com"
content = urllib.request.urlopen(url)
print(content.info()) #头信息
print(content.geturl()) #请求url
print(content.getcode()) #http状态码
#保存网页至本地并通过浏览器打开
open("baidu.html","wb").write(content.read())
web.open_new_tab("baidu.html")
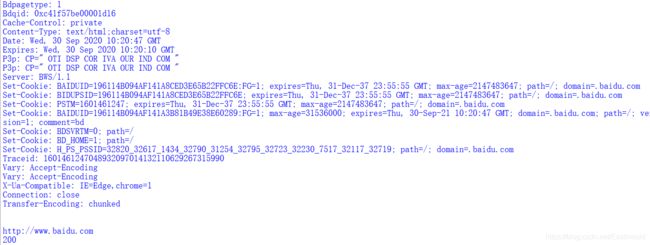
该段调用调用urllib.urlopen(url)函数打开百度链接,并输出消息头、url、http状态码等信息,如下图所示。
代码import webbrowser as web引用webbrowser第三方库,然后可以使用类似于“module_name.method”调用对应的函数。open().write()表示在本地创建静态的baidu.html文件,并读取已经打开的百度网页内容,执行文件写操作。web.open_new_tab(“baidu.html”)表示通过浏览器打开已经下载的静态网页新标签。其中下载并打开的百度官网静态网页“baidu.html”文件如下图所示。
同样可以使用web.open_new_tab(“http://www.baidu.com”)在浏览器中直接打开在线网页。
- urlretrieve
urlretrieve(url, filename=None, reporthook=None, data=None)
urlretrieve方法是将远程数据下载到本地。参数filename指定了保存到本地的路径,如果省略该参数,urllib会自动生成一个临时文件来保存数据;参数reporthook是一个回调函数,当连接上服务器,相应的数据块传输完毕时会触发该回调,通常使用该回调函数来显示当前的下载进度;参数data指传递到服务器的数据。下面通过例子来演示将新浪首页网页抓取到本地,保存在“D:/sina.html”文件中,同时显示下载进度。
# -*- coding:utf-8 -*-
import urllib.request
# 函数功能:下载文件至本地,并显示进度
# a-已经下载的数据块, b-数据块的大小, c-远程文件的大小
def Download(a, b, c):
per = 100.0 * a * b / c
if per > 100:
per = 100
print('%.2f' % per)
url = 'http://www.sina.com.cn'
local = 'd://sina.html'
urllib.request.urlretrieve(url, local, Download)
上面介绍了urllib模块中常用的两个方法,其中urlopen()用于打开网页,urlretrieve()方法是将远程数据下载到本地,主要用于爬取图片。注意,Python2可以直接引用,而Python3需要通过urllib.request调用。
# -*- coding:utf-8 -*-
import urllib.request
url = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
local = 'baidu.png'
urllib.request.urlretrieve(url, local)
抓取百度logo图片如下图所示:

2.urlparse模块
urlparse模块主要是对url进行分析,其主要操作是拆分和合并url各个部件。它可以将url拆分为6个部分,并返回元组,也可以把拆分后的部分再组成一个url。主要有函数有urljoin、urlsplit、urlunsplit、urlparse等。
- urlparse
urlparse.urlparse(urlstring[, scheme[, allow_fragments]])
该函数将urlstring值解析成6个部分,从urlstring中取得url,并返回元组(scheme, netloc, path, params, query, fragment)。该函数可以用来确定网络协议(HTTP、FTP等)、服务器地址、文件路径等。实例代码如下所示。
# coding=utf-8
from urllib.parse import urlparse
url = urlparse('http://www.eastmount.com/index.asp?id=001')
print(url) #url解析成六部分
print(url.netloc) #输出网址
输出如下所示,包括scheme、netloc、path、params、query、fragment六部分内容。
>>>
ParseResult(
scheme='http',
netloc='www.eastmount.com',
path='/index.asp',
params='',
query='id=001',
fragment=''
)
www.eastmount.com
>>>
同样可以调用urlunparse()函数将一个元组内容构建成一条Url。函数如下:
- urlunparse
urlparse.urlunparse(parts)
该元组类似urlparse函数,它接收元组(scheme, netloc, path, params, query, fragment)后,会重新组成一个具有正确格式的url,以便供Python的其他HTML解析模块使用。示例代码如下:
# coding=utf-8
import urllib.parse
url = urllib.parse.urlparse('http://www.eastmount.com/index.asp?id=001')
print(url) #url解析成六部分
print(url.netloc) #输出网址
#重组URL
u = urllib.parse.urlunparse(url)
print(u)
输出如下图所示。

四.正则表达式抓取网络数据的常见方法
接着介绍常用的正则表达式抓取网络数据的一些技巧,这些技巧都是来自于作者自然语言处理和数据抓取的项目经验,可能不是很系统,但也希望能给读者提供一些抓取数据的思路,从而更好地解决一些实际问题。
1.抓取标签间的内容
HTML语言是采用标签对的形式来编写网站的,包括起始标签和结束标签,比如< head>、< tr>、< script>< script>等。下面讲解抓取标签对之间的文本内容,比如抓取< title>Python标签对之间的“Python”内容。
(1) 抓取title标签间的内容
'(.*?) '
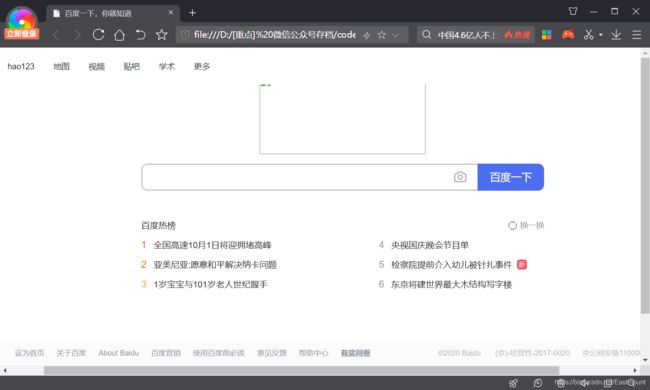
首先我们可以采用该正则表达式来抓取起始标签< title >和结束标签< /title >之间的内容,“(.*?)”就代表着我们需要抓取的内容。下面这段代码是爬取百度官网的标题,即“百度一下,你就知道”。
# coding=utf-8
import re
import urllib.request
url = "http://www.baidu.com/"
content = urllib.request.urlopen(url).read()
title = re.findall(r'(.*?) ', content.decode('utf-8'))
print(title[0])
# 百度一下,你就知道
代码调用urllib库的urlopen()函数打开超链接,并调用正则表达式re库中的findall()函数寻找title标签间的内容。由于findall()函数是获取所有满足该正则表达式的文本,这里只需要输出第一个值title[0]即可。注意,Python3需要转换utf8编码,否则会报错。
下面讲解另一种方法,用来获取标题起始标签(< title>)和结束标签()之间的内容,同样输出百度官网标题“百度一下,你就知道”。
# coding=utf-8
import re
import urllib.request
url = "http://www.baidu.com/"
content = urllib.request.urlopen(url).read()
pat = r'(?<=).*?(?= )'
ex = re.compile(pat, re.M|re.S)
obj = re.search(ex, content.decode('utf-8'))
title = obj.group()
print(title)
# 百度一下,你就知道
2.抓取超链接标签间的内容
在HTML中,< a href=url>超链接标题用于标识超链接,下面的代码用于获取完整的超链接,同时获取超链接< a>和之间的标题内容。
# coding=utf-8
import re
import urllib.request
url = "http://www.baidu.com/"
content = urllib.request.urlopen(url).read()
#获取完整超链接
res = r""
urls = re.findall(res, content.decode('utf-8'))
for u in urls:
print(u)
#获取超链接和之间内容
res = r'(.*?)'
texts = re.findall(res, content.decode('utf-8'), re.S|re.M)
for t in texts:
print(t)
输出结果部分内容如下所示,这里如果采用“print(u)”或“print(t)”语句直接输出结果。

3.抓取tr标签和td标签间的内容
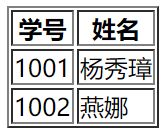
网页常用的布局包括table布局或div布局,其中table表格布局中常见的标签包括tr、th和td,表格行为tr(table row),表格数据为td(table data),表格表头为th(table heading)。那么如何抓取这些标签间的内容呢?下面是获取它们之间内容的代码。假设存在HTML代码如下所示:
表格
学号 姓名 1001 杨秀璋 1002 燕娜
运行结果如下图所示:
正则表达式爬取tr、th、td标签之间内容的Python代码如下。
# coding=utf-8
import re
import urllib.request
content = urllib.request.urlopen("test.html").read() #打开本地文件
#获取(.*?) '
texts = re.findall(res, content.decode('utf-8'), re.S|re.M)
for m in texts:
print(m)
#获取(.*?) '
m_th = re.findall(res_th, m, re.S|re.M)
for t in m_th:
print(t)
#直接获取(.*?) (.*?) '
texts = re.findall(res, content.decode('utf-8'), re.S|re.M)
for m in texts:
print(m[0],m[1])
输出结果如下,首先获取tr之间的内容,然后再在tr之间内容中获取< th>和之间值,即“学号”、“姓名”,最后是获取两个< td>和之间的内容。注意,Python3解析本地文件可能会出错,掌握方法更重要。

如果包含属性值,则正则表达式修改为“< td id=.?>(.?)”。同样,如果不一定是id属性开头,则可以使用正则表达式“
2.爬取标签中的参数
(1) 抓取超链接标签的url
HTML超链接的基本格式为“< a href=url>链接内容”,现在需要获取其中的url链接地址,方法如下:
# coding=utf-8
import re
content = '''
新闻
hao123
地图
视频
'''
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
urls = re.findall(res, content, re.I|re.S|re.M)
for url in urls:
print(url)
输出内容如下:

2.抓取图片超链接标签的url
在HTML中,我们可以看到各式各样的图片,其图片标签的基本格式为“< img src=图片地址 />”,只有通过抓取了这些图片的原地址,才能下载对应的图片至本地。那么究竟怎么获取图片标签中的原图地址呢?下面这段代码就是获取图片链接地址的方法。
content = ''' '''
urls = re.findall('src="(.*?)"', content, re.I|re.S|re.M)
print urls
# ['http://www.yangxiuzhang.com/eastmount.jpg']
'''
urls = re.findall('src="(.*?)"', content, re.I|re.S|re.M)
print urls
# ['http://www.yangxiuzhang.com/eastmount.jpg']
原图地址为“http://…/eastmount.jpg”,它对应一张图片,该图片是存储在“www.yangxiuzhang.com”网站服务器端的,最后一个“/”后面的字段为图片名称,即为“eastmount.jpg”。那么如何获取url中最后一个参数呢?
3.获取url中最后一个参数
在使用Python爬取图片过程中,通常会遇到图片对应的url最后一个字段用来命名图片的情况,如前面的“eastmount.jpg”,需要通过解析url“/”后面的参数来获取图片。
content = ''' '''
urls = 'http://www..csdn.net/eastmount.jpg'
name = urls.split('/')[-1]
print name
# eastmount.jpg
'''
urls = 'http://www..csdn.net/eastmount.jpg'
name = urls.split('/')[-1]
print name
# eastmount.jpg
该段代码urls.split(’/’)[-1]表示采用字符“/”分割字符串,并且获取最后一个所获取的值,即为图片名称“eastmount.jpg”。
3.字符串处理及替换
在使用正则表达式爬取网页文本时,通常需要调用find()函数找到指定的位置,再进行进一步爬取,比如获取class属性为“infobox”的表格table,再进行定位爬取。
start = content.find(r'') #终点位置
infobox = text[start:end]
print infobox
同时,爬取过程中可能会爬取到无关变量,此时需要对无关内容进行过滤,这里推荐使用replace函数和正则表达式进行处理。比如爬取内容如下所示:
# coding=utf-8
import re
content = '''
1001 杨秀璋
1002 燕 娜 1003 Python (.*?) (.*?) '
texts = re.findall(res, content, re.S|re.M)
for m in texts:
print(m[0],m[1])
输出内容如下所示:

此时需要过滤多余字符串,如换行(< br />)、空格(& nbsp;)、加粗(< B>),过滤代码如下:
# coding=utf-8
import re
content = '''
1001 杨秀璋
1002 颜 娜 1003 Python (.*?) (.*?) '
texts = re.findall(res, content, re.S|re.M)
for m in texts:
value0 = m[0].replace('
', '').replace(' ', '')
value1 = m[1].replace('
', '').replace(' ', '')
if '' in value1:
m_value = re.findall(r'(.*?)', value1, re.S|re.M)
print(value0, m_value[0])
else:
print(value0, value1)
采用replace将字符串“< br />”和“’& nbsp;”替换成空白,实现过滤,而加粗(< B>)需要使用正则表达式过滤。输出结果如下:

五.个人博客爬取实例
切记:这个例子可能不是非常好,但是作为入门及正则表达式结合挺好的。刚开始学习Python网络爬虫不要嫌麻烦,只有通过类似的训练,以后面对类似的问题你才会得心应手,更好的抓取需要的数据。
1.分析过程
在讲述了正则表达式、常用网络数据爬取模块、正则表达式爬取数据常见方法等内容之后,我们将讲述一个简单的正则表达式爬取网站的实例。这里讲解使用正则表达式爬取作者个人博客网站的简单示例,获取所需内容。
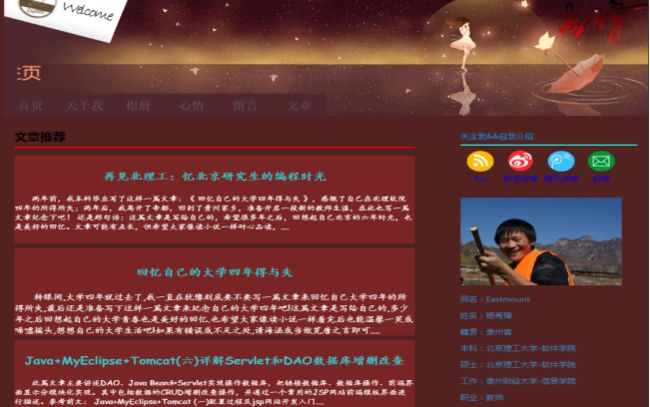
作者的个人网址“http://www.eastmountyxz.com/”打开如图所示。假设现在需要爬取的内容如下:
- 博客网址的标题(title)内容
- 爬取所有图片的超链接,比如爬取< img src=”xxx.jpg” />中的“xxx.jpg”
- 分别爬取博客首页中的四篇文章的标题、超链接及摘要内容,比如标题为“再见北理工:忆北京研究生的编程时光”。
第一步 浏览器源码定位
首先通过浏览器定位需要爬取元素的源代码,比如文章标题、超链接、图片等,发现这些元素对应HTML源代码存在的规律,这称为DOM树文档节点分析。通过浏览器打开网页,选中需要爬取的内容,右键鼠标并点击“审查元素”或“检查”,即可找到所需爬取节点对应的HTML源代码,如图所示。
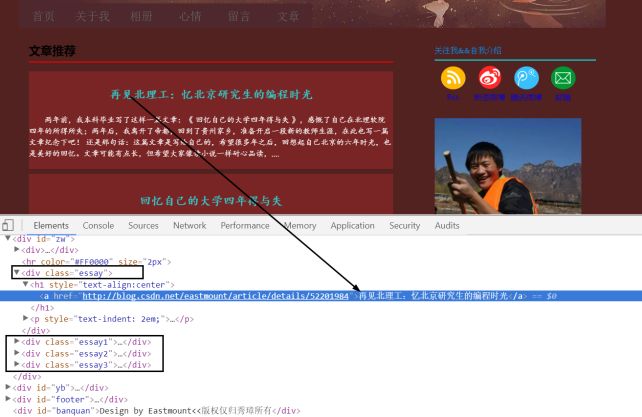
标题“再见北理工:忆北京研究生的编程时光”位于< div class=”essay”>节点下,它包括一个< h1>记录标题,一个< p>记录摘要信息,即:

这里需要通过网页标签的属性和属性值来标记爬虫节点,即找到class属性为“essay”的div,就可以定位第一篇文章的位置。同理,其余三篇文章为< div class=”essay1”>、< div class=”essay2”>和< div class=”essay3”>,定位这些节点即可。
第二步 正则表达式爬取标题
网站的标题通常位于< head>< title>…之间,该网站标题HTML代码如下:
秀璋学习天地
....
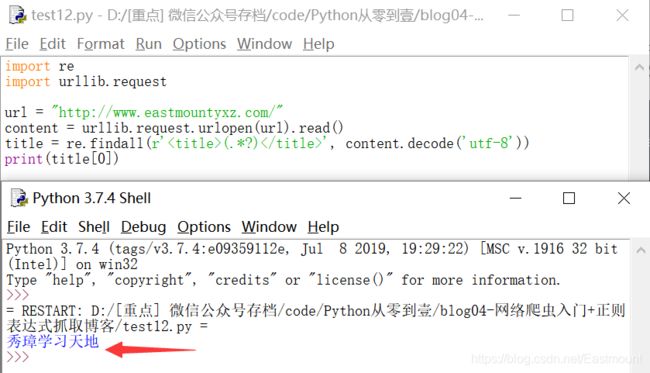
爬取博客网站的标题“秀璋学习天地”的方法是通过正则表达式“< title>(.*?)”实现,代码如下,首先通过urlopen()函数访问博客网址,然后定义正则表达式爬取。
import re
import urllib.request
url = "http://www.eastmountyxz.com/"
content = urllib.request.urlopen(url).read()
title = re.findall(r'(.*?) ', content.decode('utf-8'))
print(title[0])
输出结果如下图所示:
第三步 正则表达式爬取所有图片地址
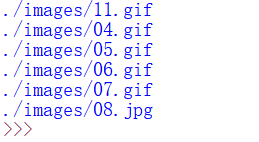
由于HTML插入图片标签格式为“< img src=图片地址 />”,则使用正则表达式获取图片地址的方法为:获取以“src=”开头,以双引号结尾的内容即可。代码如下:
import re
import urllib.request
url = "http://www.eastmountyxz.com/"
content = urllib.request.urlopen(url).read()
urls = re.findall(r'src="(.*?)"', content.decode('utf-8'))
for url in urls:
print(url)
输出的结果如下所示,共显示了6张图片。
需要注意:这里的每张图片都省略了博客地址:
- http://www.eastmountyxz.com/
我们需要对所爬取的图片地址进行拼接,增加原博客地址拼成完整的图片地址,再进行下载,并且该地址通过浏览器可以直接访问查看。如:
- http://www.eastmountyxz.com/images/11.gif
第四步 正则表达式爬取博客内容
前面第一步讲述了如何定位四篇文章的标题,第一篇文章位于< div class=”essay”>和标签之间,第二篇位于< div class=”essay1”>和,依次类推。但是该HTML代码存在一个错误:class属性通常表示一类标签,它们的值都应该是相同的,所以这四篇文章的class属性都应该是“essay”,而name或id才是用来标识标签的唯一属性。
这里使用find(’< div class=“essay” >’)函数来定位第一篇文章的起始位置,使用find(’< div class=“essay1” >’)函数来定位第一篇文章的结束位置,从而获取< div class=”essay”>到之间的内容。比如获取第一篇文章的标题和超链接代码如下:
import re
import urllib.request
url = "http://www.eastmountyxz.com/"
content = urllib.request.urlopen(url).read()
data = content.decode('utf-8')
start = data.find(r'')
end = data.find(r'')
print(data[start:end])
输出内容如下,获取第一篇博客的HTML源代码。

该部分代码分为三步骤:
- 调用urllib库的urlopen()函数打开博客地址,并读取内容赋值给content变量。
- 调用find()函数查找特定的内容,比如class属性为“essay”的div标签,依次定位获取开始和结束的位置。
- 进行下一步分析,获取源码中的超链接和标题等内容。
定位这段内容之后,再通过正则表达式获取具体内容,代码如下:
import re
import urllib.request
url = "http://www.eastmountyxz.com/"
content = urllib.request.urlopen(url).read()
data = content.decode('utf-8')
start = data.find(r'')
end = data.find(r'')
page = data[start:end]
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
t1 = re.findall(res, page) #超链接
print(t1[0])
t2 = re.findall(r'(.*?)', page) #标题
print(t2[0])
t3 = re.findall('(.*?)
', page, re.M|re.S) #摘要
print(t3[0])
调用正则表达式分别获取内容,由于爬取的段落(P)存在换行内容,所以需要加入re.M和re.S支持换行查找,最后输出结果如下:

2.代码实现
完整代码如下:
#coding:utf-8
import re
import urllib.request
url = "http://www.eastmountyxz.com/"
content = urllib.request.urlopen(url).read()
data = content.decode('utf-8')
#爬取标题
title = re.findall(r'(.*?) ', data)
print(title[0])
#爬取图片地址
urls = re.findall(r'src="(.*?)"', data)
for url in urls:
print(url)
#爬取内容
start = data.find(r'')
end = data.find(r'')
page = data[start:end]
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
t1 = re.findall(res, page) #超链接
print(t1[0])
t2 = re.findall(r'(.*?)', page) #标题
print(t2[0])
t3 = re.findall('(.*?)
', page, re.M|re.S) #摘要
print(t3[0])
print('')
start = data.find(r'')
end = data.find(r'')
page = data[start:end]
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
t1 = re.findall(res, page) #超链接
print(t1[0])
t2 = re.findall(r'(.*?)', page) #标题
print(t2[0])
t3 = re.findall('(.*?)
', page, re.M|re.S) #摘要
print(t3[0])
输出结果如图所示。

通过上面的代码,读者会发现使用正则表达式爬取网站还是比较繁琐,尤其是定位网页节点时,后面将讲述Python提供的常用第三方扩展包,利用这些包的函数进行定向爬取。
六.总结
正则表达式是通过组合的“规则字符串”来对表达式进行过滤,从复杂内容中匹配想要的信息。它的主要对象是文本,适合于匹配文本字符串等内容,不适合匹配文本意义,比如匹配URL、Email这种纯文本的字符就非常适合。各种编程语言都能使用正则表达式,比如C#、Java、Python等。
正则表达式爬虫常用于获取字符串中的某些内容,比如提取博客阅读量和评论数的数字,截取URL域名或URL中某个参数,过滤掉特定的字符或检查所获取的数据是否符合某个逻辑,验证URL或日期类型等。由于其比较灵活、逻辑性和功能性较强的特点,使它能迅速地以极简单的方式从复杂字符串中达到匹配目的。
但它对于刚接触的人来说,正则表达式比较晦涩难懂;同时,通过它获取HTML中某些特定文本也比较困难,尤其是当网页HTML源代码中结束标签缺失或不明显的情况。接下来作者将讲述更为强大、智能的第三方爬虫扩展包,主要是BeautifulSoup和Selenium技术。
你可能感兴趣的:(python,编程语言,Python爬虫,网络爬虫,Python编程)