正则表达式 通配符 awk文本处理工具
目录
什么是正则表达式
概念
正则表达式的结构
正则表达式的组成
元字符
元字符点(.)
代表字符.
点值表示点需要转义 \
r..t 代表r到t之间任意两个字符
过滤出小写
过滤出非小写
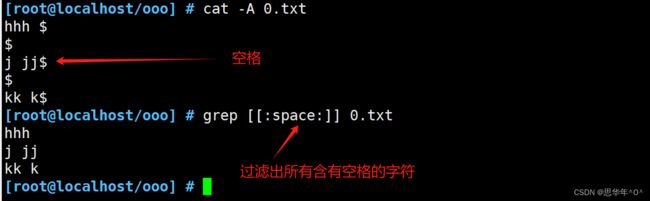
space空格 [[:space:]]
表示次数
位置锚定
例:
分组 或
扩展
表示邮箱
表示手机号
AWk
格式
选项
表达式
处理动作
例:
awk 常见的内置变量
拓展
awk数组计算 (默认使用关联数组)
什么是正则表达式
概念
正则表达式(Regular Expression,在代码中常简写为regex、regexp或RE),又称规则表达式,是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。
正则表达式的结构
shell: /bin/bash
正则表达式:匹配的是文章中的字符
通配符:匹配的是文件名 (?任意单个字符)
元字符:不表示本来的含义,在正则表达式中有特殊含义的字符
正则表达式的组成
1.代表字符 . 单个任意字符 [ ]单个字符 [a b c] a或b或c
2.表示次数
3.位置锚定 ^ $
4.分组 或
元字符
. 匹配任意单个字符,可以是一个是汉字
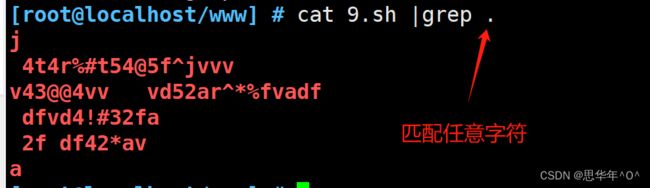
[ ] 匹配指定范围内的任意单个字符 [af]
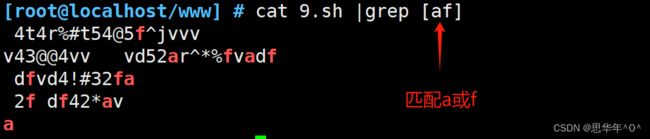
[^] 匹配指定范围外的任意单个字符 [^af]
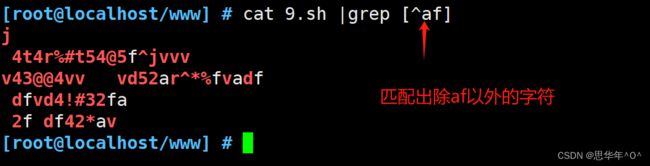
元字符点(.)
代表字符.
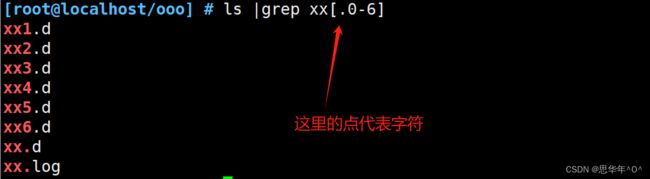
点值表示点需要转义 \

r..t 代表r到t之间任意两个字符

过滤出小写

过滤出非小写

space空格 [[:space:]]
表示次数
* 表示0到正无穷
.* 表示任意长度的字符 (不包括0次)
\? 可有可无 0或1次
\+ 一次及以上, 一次到正无穷 >=1 ( [[:alnum:]] 字母和数字 )
![]()
\{3\} 前面字符出现最少三次 \{N\}
![]()
\{3,5} 前面字符出现3到5次 \{n,m\}
位置锚定
^ 开头
$ 结尾
^[[:space:]]*$ 空白行
\b 字符串开头
\< 字符串开头
\b 字符串结尾
\> 字符串结尾
例:
词首锚定

词尾锚定

分组 或
分组 ( ) 使用括号将需要组合的字符 括起来

或 : \|

扩展
grep -E 使用拓展表达式
egrep 默认使用扩展表达式 (简便操作)
表示邮箱
echo "[email protected]" |grep -E "[[:alnum:]_]+@[[:alnum:]_]+\.[[:alnum:]_]+"
[email protected]![]()
表示手机号
echo "13384402293"|grep -E "\b1[3456789][0-9]{9}\b"
13384402293

AWk
AWK 是一种与语言,文本处理工具 加载一行处理一行
vim 也是文本处理工具 缺点:内存不足时打不开文件
vim是将整个文件加载到内存中处理,如果内存不够大,无法打开处理文件
akw的内置变量和shell环境中的变量会有冲突 ,必须使用‘ ’单引号
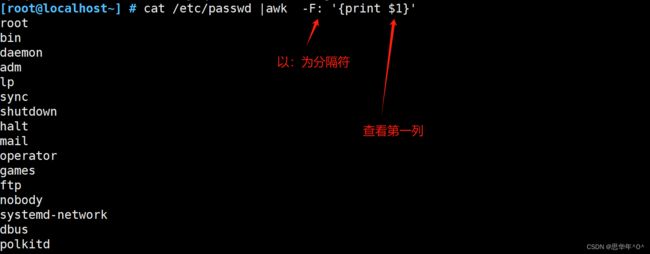
awk 取列 主要功能
格式
awk 选项 ‘表达式 {处理动作}‘
选项
-F 指定分隔符
-V 指定变量
表达式
awk 的语言的表达式
1.不写没有
2.找到特定行
处理动作
print 打印
prontf 打印
awk ’{print $2}' 以空格为分隔符 取第n列 ,n大于等于0
awk 内置变量
$0(全文) $1(第一列) $2(第二列)
例:
awk 'root‘开头的行{print}'
[root@localhost/lll] # awk '/^root/ {print } ' /etc/passwd
root:x:0:0:root:/root:/bin/bash

awk 内置变量 $0(全文) $1(第一列) $2(第二列)
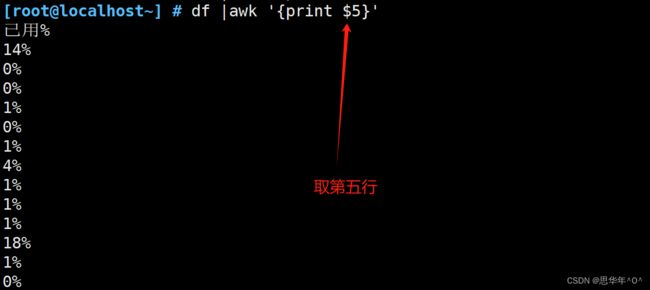
查看磁盘大小 打印第五行
awk 常见的内置变量
awk 选项 ‘模式{print }’
FS 指定分隔符 默认空格 与 “-F”作用相同 -v "FS=:"
[root@localhost~] # awk -v FS=':' '{print $1FS$3}' /etc/passwd
#此处FS 相当于于变量 -v 变量赋值 相当于 指定: 为分隔符
root:0
bin:1
daemon:2
adm:3
lp:4
sync:5
shutdown:6
halt:7
OFS 输出时的分割符
[root@localhost~] # awk -v FS=':' -v OFS='==' '{print $1,$3}' /etc/passwd
root==0
bin==1
daemon==2
adm==3
lp==4
sync==5
shutdown==6
halt==7
mail==8
operator==11
games==12
NF 打印每行有多少字段 倒数第二列 $(NF-1) 倒数第一列$NF
[root@localhost~] # awk -F: '{print NF}' /etc/passwd
7
7
7
7
7
7
7
[root@localhost~] # df |awk '{print $(NF-1) }' #倒数第二行
已用%
14%
0%
0%
1%
0%
1%
4%
1%
1%
1%
18%
1%
0%
[root@localhost~] # df |awk '{print $(NF) }'
挂载点
/
/dev
/dev/shm
/run
/sys/fs/cgroup
/123
/456
/zzz
/mnt
/home
/boot
/run/user/42
/run/user/0
NR 显示行号 awk ‘NR==2 {print $1}' 打印第二行的第一个字段
[root@localhost~] # awk '{print $1,NR}' /etc/passwd #显示第一列的行号
root:x:0:0:root:/root:/bin/bash 1
bin:x:1:1:bin:/bin:/sbin/nologin 2
daemon:x:2:2:daemon:/sbin:/sbin/nologin 3
adm:x:3:4:adm:/var/adm:/sbin/nologin 4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 5
sync:x:5:0:sync:/sbin:/bin/sync 6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7
halt:x:7:0:halt:/sbin:/sbin/halt 8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 9
operator:x:11:0:operator:/root:/sbin/nologin 10
[root@localhost~] # awk 'NR==2 {print $1}' /etc/passwd
#只取第二行的第一个字段
bin:x:1:1:bin:/bin:/sbin/nologin
拓展
打印出几点几分到几点几分的日志?
awk '/几点几分/,/几点几分/' 日志文件
awk数组计算 (默认使用关联数组)
关联数组下标为单词
awk 建立数组
[root@localhost~] # awk 'BEGIN {a[1]="lisi"; a[2]="liwu";print a[1],a[2]}'
lisi liwu
awk 'BEGIN {a[1]="lisi"; a[2]="liwu";for(i in a) print a[1],a[2]}'
lisi liwu
lisi liwu