数据库的分库分表 详解
前言
一个系统随着用户量上升,产生的数据也越来越多,到达一定程度,数据库就会产生瓶颈。
首先单机数据库所能承载的连接数,io和吞吐量都是有限的,并发量上来数据库就渐渐顶不住了。
如果单表的数据量过大,查询的性能也会下降,B+Tree层数可能增加,io次数增加,原理可以看我以前的文章。
此时就不得不分库分表。
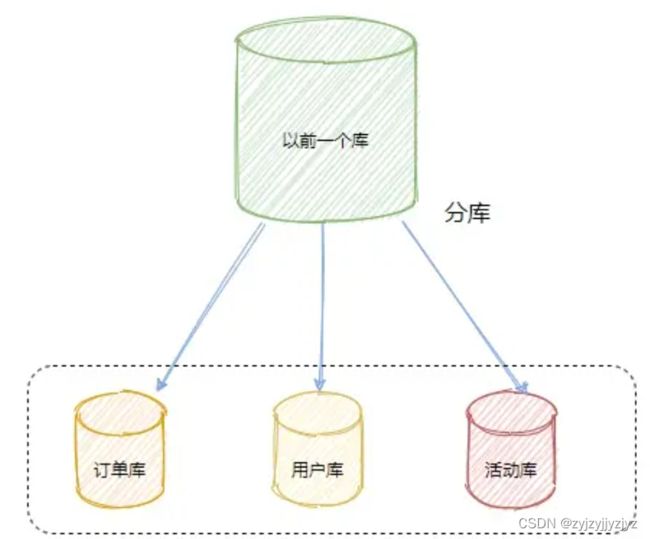
分库
把以前存在一个数据库实例的数据拆分成多个数据库实例,部署在不同的服务器中。
分表
把以前存在一张表里的数据拆分成多张表。
字面的意思理解:分库就是把原在一个库的数据查分成不同的库,部署在不同的服务器,分表就是把表拆分成多个表,表还在一个库中。
解决的问题
分表:为了解决由于单表数据量大,从而导致查询慢的问题。三、四千万行数据就得拆分
分库:为了解决服务器资源受单机限制,顶不住高并发访问的问题,把请求分配到多台服务器上,降低服务器的压力。
怎么进行分库、分库的例子
一般分库都是按照业务划分的,比如订单表、用户表等
因为做活动的时候并发量会很高,怕影响现有的核心业务,所以及时有关联,也会单独做拆分。
分库带来的问题
事务问题
关系型数据库的优势就是他能保证事务的完整性
分库之后单机事务就用不上了,必须使用分布式事务来解决,而分布式事务基本都是残缺的。
join问题
在一个库中的表我们可以join进行表连接,跨库之后就无法join了。
解决方法1就是在业务代码中进行关联(原先是在数据库中进行关联,现在是在业务代码中进行关联),也就是先查出一个表,之后通过得到的结果再去查另一个表。利用代码来关联最终得到的结果。
解决方法2就是适当的冗余一些字段。
怎么进行分表、分表的方式
分表分为两种
垂直分表
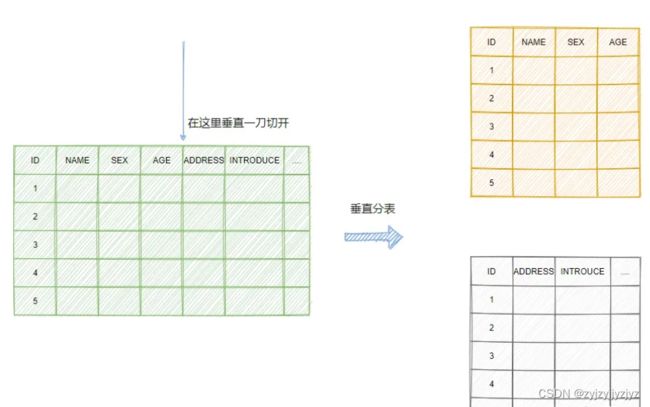
垂直分表就是把一些不常用的大字段分离出去
就像上面的例子,用户名是很常用的搜索字段,性别年龄占用的空间不大,但是地址和个人简介占用的空间很大,我们都知道数据页是有限的,一行记录越大一个数据页存的及记录越少。把一些无用的大字段分离出来,一页就能放很多数据。内存就能存放更多有用的数据,减少了io,性能就得到提升。
水平分表
水平分表是因为一张表的数据太多,导致B+Tree高了,性能就差,所以进行水平拆分。

分表产生的问题
垂直分表还好,查询数据就是需要关联一下,而水平分表就麻烦了,排序,count,分页都会产生问题 。
数据如果拆分成多个表,那查询结果分页就不像以前单张表那样直接就能查出来,像count操作也是一样的。只能由业务代码来实现。当然像count操作的结果其实可以缓存下来,然后每次数据的增删都更新计数。
路由问题(查找数据)
分表可以分为:
Hash路由:选择表中的某一列,然后进行hash运算,将hash运算得到的结果在对子表进行取模,这样就能均匀的将数据分到不同的子表上。和HashMap选择桶的原理相同。
优点:数据分布均匀
缺点:迁移数据很麻烦
范围路由(其实和分区的实现挺像的,但是分区和分表有本质的区别)
可以是时间也可以是地址,表示一定范围的即可。
比如本来一张 User 表,按照地名来划分 User。
再比如 log 表,我可以将表分为 一个一个时间的表,把日志按照年月来划分。
优点就是相对而言比较容易扩展,比如现在来个 GZ,那就加个 User_GZ。如果到了 5 月,那就建个五月的表。
缺点就是数据可能分布不均匀,例如 BJ 的用户特别多或者某个月搞了促销,日志量特别大,等等。
路由表
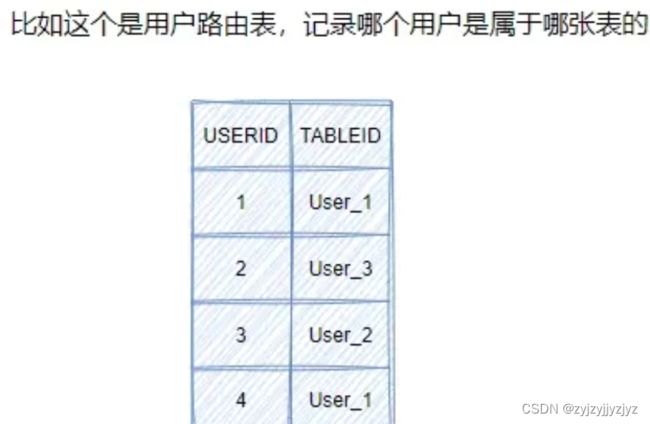
从这张表我们就知道用户对应的表,查到该用户就去对应的表中找他的信息。
优点:灵活,如果要迁移数据,直接迁移之后改路由表就行
缺点:就是多了一次查询,每次都得访问路由表,一般会做缓存
全局主键问题
单表的时候主键自增,主键不会重复,那分表之后怎么办,注意这是水平分表会产生的问题。
怎么保证全局主键的唯一性
1、自增,设置自增步长,比如有三张表,不长为几都行,三张表初始值分别为1、2、3,这样自增后都不会相同不会重复。
2、UUID,肯定不会重复,但是因为主键不是自增的可能会产生页分裂。