SpringIOC-初始化-LoadBeanDefinitions
文章目录
- 程序入口
- 解析文件的核心类
- 执行流程
- 详细流程解析
-
- 从refreshBeanFactory --> loadBeanDefinitions
-
- 1. 从ClassPathXmlApplicationContext入口,传入配置文件地址,供spring解析
- 2. ClassPathXmlApplicationContext的构造方法中设置,做一些初始化,调用refresh核心方法
- 3. AbstractApplicationContext.refresh(),refresh()方法为了加载ApplicationContext ,调用obtainFreshBeanFactory()方法获取新的beanFactory
- 声明XmlBeanDefinitionReader来实现XML方式的loadBeanDefinitions
-
- 4. 父类AbstractXmlApplicationContext实现loadBeanDefinitions()方法
- 5. 调用抽象类AbstractBeanDefinitionReader的loadBeanDefinitions方法
- 6. 子类XmlBeanDefinitionReader具体实现loadBeanDefinitions()逻辑
- 生成dom对象
-
- 7. DefaultDocumentLoader.loadDocument 方法
- 8. 后面将XML parse就交给JDK的JAXP了
- 注册BeanDefinitions
-
- 9. 创建BeanDefinitionDocumentReader来进行registerBeanDefinitions
- 10. BeanDefinitionDocumentReader.registerBeanDefinitions来执行doRegisterBeanDefinitions
- 11. BeanDefinitionDocumentReader.parseDefaultElement方法进行标准的命名空间解析
-
- 包含import、alias、bean、beans节点的解析
- 解析到“import”标签,则执行importBeanDefinitionResource方法
- 解析“alias”标签,执行processAliasRegistration()方法
- 解析bean标签processBeanDefinition
- 再解析beans标签,递归调用DefaultBeanDefinitionDocumentReader.doRegisterBeanDefinitions()方法。
- 总结
目前IOC管理Spring Bean的配置方式主要是两种:
- XML方式:更经典
- Annotion注解方式:流行
这边看看Spring是怎么解析XML的,Spring将这一步的动作命名成loadBeanDefinitions ,将XML parse成 Document对象,再解析DOM对像创建BeanDefinition并进行装配,最后注册到注册表
程序入口
从在使用Spring获取ApplicationContext的方法中,有如下的一个API
BeanFactory context = new ClassPathXmlApplicationContext("ioc.xml");
这个就能进入到Spring处理ioc.xml的配置文件的代码。从这个入口进入到ClassPathXmlApplicationContext类,可以关联出解析文件的核心类群
解析文件的核心类
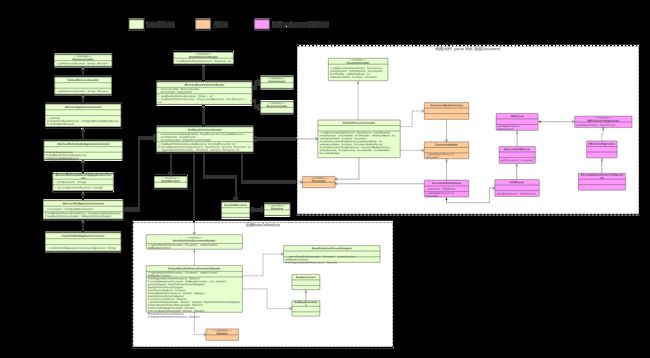
从源码对应的核心类图中可以看出来,解析配置文件有两个模块:
- 生成DOM对象
- 解析DOM对象,注册BeanDefinition
BeanDefinitionReader类群下面的DocumentLoader类群和BeanDefinitionDocumentReader类群
执行流程

从执行流程图中可以看到,在进行dom解析之前,从refresh方法一步步往下,解析dom和注册beanDefinitions都是创建组装BeanFactory中的两个子环节。从类图上也能看出来,Spring在处理这些逻辑是有精心的面向对象设计。
详细流程解析
从refreshBeanFactory --> loadBeanDefinitions
1. 从ClassPathXmlApplicationContext入口,传入配置文件地址,供spring解析
ApplicationContext context = new ClassPathXmlApplicationContext("ioc/ioc.xml");
2. ClassPathXmlApplicationContext的构造方法中设置,做一些初始化,调用refresh核心方法
public ClassPathXmlApplicationContext(String[] configLocations, boolean refresh, ApplicationContext parent)
throws BeansException {
// 构造AbstractApplicationContext父类中 resourcePatternResolver 和 environment属性
super(parent);
// 解析文件路径
setConfigLocations(configLocations);
if (refresh) {
// 调用核心方法,初始化ApplicationContext
refresh();
}
}
3. AbstractApplicationContext.refresh(),refresh()方法为了加载ApplicationContext ,调用obtainFreshBeanFactory()方法获取新的beanFactory
refresh()方法是加载ApplicationContext的核心方法,由AbstractApplicationContext类定义了主流程,具体的方法由子类去具体场景实现。obtainFreshBeanFactory()调用refreshBeanFactory(), 该方法由AbstractRefreshableApplicationContext子类来实现
protected final void refreshBeanFactory() throws BeansException {
// 1、已经存在beanFactory,则删除原来的beanFactory
if (hasBeanFactory()) {
// 销毁bean
destroyBeans();
// 置beanFactory == null
closeBeanFactory();
}
try {
// 2、 创建beanFactory,new DefaultListableBeanFactory()
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
// 3、加载beanDefinitions,该方法后续会解析xml文件,加载bean
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
声明XmlBeanDefinitionReader来实现XML方式的loadBeanDefinitions
4. 父类AbstractXmlApplicationContext实现loadBeanDefinitions()方法
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// 创建XmlBeanDefinitionReader来读取xml ,注册beanDefinitions
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 指定一些配置
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// 子类自定义一些初始化配置
initBeanDefinitionReader(beanDefinitionReader);
// 核心加载方法
loadBeanDefinitions(beanDefinitionReader);
}
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
// 默认返回的是null,除非子类重写
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);
}
// 根据配置文件路径加载
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);
}
}
5. 调用抽象类AbstractBeanDefinitionReader的loadBeanDefinitions方法
同样的是定义的抽象的load流程,具体的实现由子类实现,使用ResourceLoader获取配置文件的Resource
public int loadBeanDefinitions(String... locations) throws BeanDefinitionStoreException {
Assert.notNull(locations, "Location array must not be null");
int counter = 0;
// 首先遍历配置文件,一个个解析,并且设计计数器
for (String location : locations) {
counter += loadBeanDefinitions(location);
}
return counter;
}
public int loadBeanDefinitions(String location, Set<Resource> actualResources) throws BeanDefinitionStoreException {
// 1、获取ResourceLoader,是在new XmlBeanDefinitionReader的时候设置的,beanDefinitionReader.setResourceLoader(this); 这边的this就是当前的ClassPathXmlApplicationContext对象
ResourceLoader resourceLoader = getResourceLoader();
// resourceLoader判空
......
// 2、资源加载器属于资源模式解析器,比如文件路径是classpath*:来的
if (resourceLoader instanceof ResourcePatternResolver) {
try {
// 解析到多个配置文件,赋值Resource[]数组
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
// 可以批量执行解析和加载
int loadCount = loadBeanDefinitions(resources);
// 遍历结果,将Resource add到actualResources Set集合中
......
}
catch (IOException ex) {
// 异常log
......
}
return loadCount
}
else {
// 3、非一定格式加载,则进行绝对路径获取文件,只能单个文件的加载
Resource resource = resourceLoader.getResource(location);
// 单个文件解析和加载
int loadCount = loadBeanDefinitions(resource);
// 将Resource add到actualResources Set集合中
......
return loadCount;
}
}
6. 子类XmlBeanDefinitionReader具体实现loadBeanDefinitions()逻辑
包装了EncodedResource对象,解析过程做防并发,将Resource转成InputStream输入流,继续解析;
用DocumentLoader的loadDocument()方法来返回Document对象
// Resource对象包装一个EncodedResource对象
loadBeanDefinitions(new EncodedResource对象(resource));
// XmlBeanDefinitionReader中的全局变量,用于存放当前线程下已经处理过的xml Resource
private final ThreadLocal<Set<EncodedResource>> resourcesCurrentlyBeingLoaded = new NamedThreadLocal<Set<EncodedResource>>("XML bean definition resources currently being loaded");
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
......
// 1、这边有个判断这个文件是否在解析中
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
// 初始化resourcesCurrentlyBeingLoaded
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
// 由于Set不能重复,如果正在执行解析当前的Resource,添加到set中就抛出异常。说明可能配置中重复配置了
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
// 2、从resource中获取InputStream 输入流
InputStream inputStream = ......
// 3、核心流程:继续解析
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
......// 抛出异常
}
finally {
// 4、执行完成移除Resource控制
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
// 全局变量,DocumentLoader默认生命DefaultDocumentLoader来实现解析功能
private DocumentLoader documentLoader = new DefaultDocumentLoader();
private boolean namespaceAware = false;
private ErrorHandler errorHandler = new SimpleSaxErrorHandler(logger);
// 这个方法中执行了两件时间解析dom和注册BeanDefinitions
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 设定验证模式,默认是VALIDATION_AUTO自动
int validationMode = getValidationModeForResource(resource);
// 1、使用默认的DefaultDocumentLoader的loadDocument方法解析
// 这个方法的入参分别是:inputSource文件输入流
// EntityResolver entityResolver : ResourceEntityResolver : 实体解析器,new对象时出示化:beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this)); this是ClassPathXmlApplicationContext实例
// ErrorHandler errorHandler : SimpleSaxErrorHandler 默认new SimpleSaxErrorHandler
// boolean namespaceAware : 默认是false
Document doc = this.documentLoader.loadDocument(
inputSource, getEntityResolver(), this.errorHandler, validationMode, isNamespaceAware());
// 2、根据解析的Document对象构造BeanDefinitions
return registerBeanDefinitions(doc, resource);
}
......// catch各类异常进行定义明确的含义抛出
}
生成dom对象
Document doc = this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler, validationMode, isNamespaceAware());
7. DefaultDocumentLoader.loadDocument 方法
创建DocumentBuilderFactory,构建DocumentBuilder,进行parse解析
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
// 1、创建DocumentBuilderFactory
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
// 2、创建DocumentBuilder
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
// 3、进行解析
return builder.parse(inputSource);
}
createDocumentBuilderFactory():DocumentBuilderFactory.newInstance()
createDocumentBuilder():factory.newDocumentBuilder();
这两个方法中就是利用JAXP 实现DOM解析XML的API
8. 后面将XML parse就交给JDK的JAXP了
DocumentBuilderImpl.parse();
DOMParser.parse();
DOMParser.getDocument();
最后返回Document对象。中间包含了xml的所有节点。后续进行注册BeanDefinitions
注册BeanDefinitions
registerBeanDefinitions(doc, resource)
9. 创建BeanDefinitionDocumentReader来进行registerBeanDefinitions
很显然BeanDefinitionDocumentReader就是设计用来读取Document–>BeanDefinition的
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
documentReader.setEnvironment(this.getEnvironment());
// 获取之前已经注册的数量
int countBefore = getRegistry().getBeanDefinitionCount();
// 进行注册
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
// 创建的BeanDefinitionDocumentReader就是定义的成员变量DefaultBeanDefinitionDocumentReader的实例
private Class<?> documentReaderClass = DefaultBeanDefinitionDocumentReader.class;
protected BeanDefinitionDocumentReader createBeanDefinitionDocumentReader() {
return BeanDefinitionDocumentReader.class.cast(BeanUtils.instantiateClass(this.documentReaderClass));
}
private ProblemReporter problemReporter = new FailFastProblemReporter();
private ReaderEventListener eventListener = new EmptyReaderEventListener();
private SourceExtractor sourceExtractor = new NullSourceExtractor();
// 创建一个XmlReaderContext上下文
protected XmlReaderContext createReaderContext(Resource resource) {
if (this.namespaceHandlerResolver == null) {
this.namespaceHandlerResolver = createDefaultNamespaceHandlerResolver();
}
// 入参resource 文件资源
// problemReporter : FailFastProblemReporter 实例
// eventListener : EmptyReaderEventListener 实例
// sourceExtractor : NullSourceExtractor 实例
// this : 就是当前XmlBeanDefinitionReader实例
// namespaceHandlerResolver : DefaultNamespaceHandlerResolver 实例
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,
this.sourceExtractor, this, this.namespaceHandlerResolver);
}
// 创建命名空间解析器
protected NamespaceHandlerResolver createDefaultNamespaceHandlerResolver() {
return new DefaultNamespaceHandlerResolver(getResourceLoader().getClassLoader());
}
10. BeanDefinitionDocumentReader.registerBeanDefinitions来执行doRegisterBeanDefinitions
doRegisterBeanDefinitions:从root的节点开始注册每一个bean;创建委托类BeanDefinitionParserDelegate,遍历节点:parseDefaultElement()处理标准默认的命名空间,delegate.parseCustomElement()委托类处理自定义命名空间
// 声明一个上下文,在XmlBeanDefinitionReader的方法createReaderContext()中创建的。
private XmlReaderContext readerContext;
// Element root 从Document的根节点开始解析
protected void doRegisterBeanDefinitions(Element root) {
// 获取当前节点“profile”属性
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
// 判断profileSpec 字符串是否有实际文字,就是判空并且不能是全空格
if (StringUtils.hasText(profileSpec)) {
......
}
// 创建BeanDefinitionParser的解析委托类 BeanDefinitionParserDelegate,封装具体解析的逻辑
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createHelper(readerContext, root, parent);
// 处理之前:空实现,可重写加入自定义逻辑
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
// 处理之后:空实现,可重写加入自定义逻辑
postProcessXml(root);
this.delegate = parent;
}
protected BeanDefinitionParserDelegate createHelper(XmlReaderContext readerContext, Element root, BeanDefinitionParserDelegate parentDelegate) {
// 创建委托类
BeanDefinitionParserDelegate delegate = new BeanDefinitionParserDelegate(readerContext, environment);
// 初始化默认值
delegate.initDefaults(root, parentDelegate);
return delegate;
}
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 判断是否默认的命名空间
// 判断方法:node.getNamespaceURI() equals BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans"
if (delegate.isDefaultNamespace(root)) {
// 获取子节点,并且遍历子节点,子节点是Element则进行判断解析
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
// 再次判断是否默认命名空间
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
11. BeanDefinitionDocumentReader.parseDefaultElement方法进行标准的命名空间解析
包含import、alias、bean、beans节点的解析
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// 发现是beans标签,则递归解析beans节点下面的节点
doRegisterBeanDefinitions(ele);
}
}
解析到“import”标签,则执行importBeanDefinitionResource方法
判断路径格式,拿到具体的文件资源,逻辑上递归执行AbstractBeanDefinitionReader.loadBeanDefinitions(String location, Set actualResources)方法
protected void importBeanDefinitionResource(Element ele) {
// "resource" 属性,即为import 引用的文件路径
String location = ele.getAttribute(RESOURCE_ATTRIBUTE);
// 判空
if (!StringUtils.hasText(location)) {
getReaderContext().error("Resource location must not be empty", ele);
return;
}
// 这个为了解析这个如果路径中有${}这种匹配的格式替换
location = environment.resolveRequiredPlaceholders(location);
Set<Resource> actualResources = new LinkedHashSet<Resource>(4);
boolean absoluteLocation = false;
try {
// 判断路径是URI还是绝对路径
absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
}
catch (URISyntaxException ex) {
}
// 绝对路径
if (absoluteLocation) {
try {
// 调用AbstractBeanDefinitionReader.loadBeanDefinitions()方法
int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources);
......
}
catch (BeanDefinitionStoreException ex) {
......
}
}
else {
// 相对路径
try {
int importCount;
// 获取相对路径资源 处理调用loadBeanDefinitions方法
Resource relativeResource = getReaderContext().getResource().createRelative(location);
if (relativeResource.exists()) {
importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource);
actualResources.add(relativeResource);
}
else {
String baseLocation = getReaderContext().getResource().getURL().toString();
importCount = getReaderContext().getReader().loadBeanDefinitions(
StringUtils.applyRelativePath(baseLocation, location), actualResources);
}
......
}
}
Resource[] actResArray = actualResources.toArray(new Resource[actualResources.size()]);
// 触发ImportProcessed处理, 空实现 no-op
getReaderContext().fireImportProcessed(location, actResArray, extractSource(ele));
}
解析“alias”标签,执行processAliasRegistration()方法
protected void processAliasRegistration(Element ele) {
// 获取name属性
String name = ele.getAttribute(NAME_ATTRIBUTE);
// 获取alias属性
String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
// 判空
boolean valid = true;
if (!StringUtils.hasText(name)) {
getReaderContext().error("Name must not be empty", ele);
valid = false;
}
if (!StringUtils.hasText(alias)) {
getReaderContext().error("Alias must not be empty", ele);
valid = false;
}
if (valid) {
try {
// 注册别名,实现逻辑是往aliasMap 的map中写入
getReaderContext().getRegistry().registerAlias(name, alias);
}
catch (Exception ex) {
getReaderContext().error("Failed to register alias '" + alias +
"' for bean with name '" + name + "'", ele, ex);
}
// 触发别名注册完逻辑,空实现 no-op
getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
}
}
解析bean标签processBeanDefinition
由于bean标签的解析和创建BeanDefinition是耦合在一起,同步进行的。所以相当的复杂,更多的代码应该归类于bean定义了,就浅尝辄止了,回头在细看BeanDefinition的创建。
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 委托类来解析,并返回BeanDefinitionHolder很形象BeanDefinition拥有者
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
// 创建出来不为空
if (bdHolder != null) {
// 对BeanDefinition进行装饰
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 将最后装饰好的实例,注册到BeanDefinition注册表
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 触发注册好的事件,空实现 no-op
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
delegate.parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) 开始解析bean标签。
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) {
// 获取id属性
String id = ele.getAttribute(ID_ATTRIBUTE);
// 获取name属性
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// 存放所有bean的name
List<String> aliases = new ArrayList<String>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
// *******没有id 则用name 做为beanName*******
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
// 在delegate中有声明 private final Set usedNames = new HashSet(); 用来存放解析的beanName,可以由来判断beanName的唯一性
checkNameUniqueness(beanName, aliases, ele);
}
// 解析beanDefinition,里面的逻辑会解析bean标签的属性,并且根据节点创建bean定义,比较复杂
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
// 处理beanName
if (!StringUtils.hasText(beanName)) {
try {
......
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
// 创建bean持有者
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
delegate.parseBeanDefinitionElement(Element ele, String beanName, BeanDefinition containingBean) ,返回AbstractBeanDefinition; 开始解析bean标签的属性以及子节点等,并创建beanDefinition并且进行装配,后续再详细学习一下,目前就整理个流程吧。代码中有一个出入栈的设计(TODO:这个坑后面回来补)
// 解析Bean定义的本身,再解析过程中出现错误,则可能会返回null
public AbstractBeanDefinition parseBeanDefinitionElement(Element ele, String beanName, BeanDefinition containingBean) {
// BeanEntry,代表解析并定义的入口,开始解析对应的beanName时,做入栈的操作
this.parseState.push(new BeanEntry(beanName));
String className = null;
// xml中"class"属性获取定义的className
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
String parent = null;
// 解析"parent"属性
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
// 创建beanDefinitions,返回的是GenericBeanDefinition类的对象实例
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 解析bean定义的节点属性,给到beanDefinition上,例如:scope,singleton等等
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
// 描述
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
// 解析meta节点,set到beanDefinition上
parseMetaElements(ele, bd);
// 解析lookup-method子节点,set到beanDefinition上
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
// 解析replaced-method子节点,set到beanDefinition上
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
// 解析constructor-arg节点,set到beanDefinition上
parseConstructorArgElements(ele, bd);
// 解析property节点,set到beanDefinition上
parsePropertyElements(ele, bd);
// 解析qualifier节点,set到beanDefinition上
parseQualifierElements(ele, bd);
// 资源文件set到beanDefinition上
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
// 返回beanDefinition
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
// 处理完beanDefinition的装配,则出栈
this.parseState.pop();
}
return null;
}
再解析beans标签,递归调用DefaultBeanDefinitionDocumentReader.doRegisterBeanDefinitions()方法。
总结
通过查看Spring源码,根据源码梳理流程和类结构,可以知道了下面的几个点
-
解析xml的过程,作为整个流程节点的第一步,是位于创建BeanFactory的流程中的。核心做的事情是loadBeanDefinitions,加载bean定义之前必须要根据解析的配置文件来加载。
-
从类结构可以看出来,Spring类设计上很讲究,各个模块都是统一抽象,上层Abstract类定义了方法,具体场景子类去实现具体的逻辑,逻辑线上只关注抽象。到处都是模板方法的设计模式,体现依赖倒转的原则。例如核心的XmlBeanDefinitionReader解析类,loadBeanDefinitions这个方法是BeanDefinitionReader接口定义的,入口实现是***AbstractBeanDefinitionReader***抽象类定义的。XmlBeanDefinitionReader只是实现xml情况下的doLoadBeanDefinitions。
-
从源码上看出来Spring解析xml是利用的jdk提供的JAXP xml解析类库,利用的是DOM技术来转换xml文件到Document对象的,然后解析整个文档树,最后进行Bean定义。在解析文档树的时候类结构也很清晰BeanDefinitionDocumentReader类库来控制解析流程,具体的解析动作委托给BeanDefinitionParserDelegate来做,专项专办。并且用上下文类ReaderContext来作为过程中的纽带和存储。
-
在XmlBeanDefinitionReader.loadBeanDefinitions方法中,除了关注调用流程,还进行了简单防重的实现,因为这个方法会存在递归或循环执行,所以设置了在线程中存储set(set本身不能重复),存当前正在解析的Resource,防止并发解析导致出现问题。