KerberOS Hadoop 认证安装配置
目录
1. 关闭 selinux
2. 安装 yum 源配置参考
3. 安装 kerberos 的 server 端
4. 配置 krb5.conf 文件
5. 配置 kdc.conf
6. 配置 kadm5.acl 文件
7. 初始化 kerberos 库
8. Kerberos 客户端
9. hadoop kerberos 认证配置
1) 配置 HDFS
1. 添加用户 (三个节点均执行)
2. 配置HDFS相关的kerberos账户
3. 创建数据目录(这个根据自己的安装实际情况设置)
4. 配置hadoop的lib/native (本地运行库)
5. 设置HDFS的配置文件
2) 配置 yarn
1. 添加kerberos用户
2. 配置 yarn-site.xml
3. 配置mapred.xml
4. 配置container-executor.cfg
5. 提交MR程序测试
3) 配置 hive kerberos 认证
4) 使用 java 代码集成测试
1. 关闭 selinux
vim /etc/sysconfig/selinux
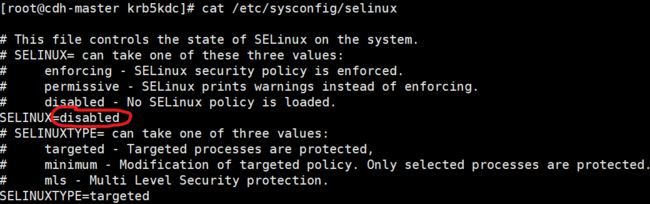
关闭防火墙,设置开机关闭
systemctl stop firewalld
chkconfig firewalld off2. 安装 yum 源配置参考
https://blog.csdn.net/Jerry_991/article/details/118910505
3. 安装 kerberos 的 server 端
(一般找一台单独的机器)
yum install -y krb5-ibs krb5-server krb5-workstation
(查看 yum list | grep krb 中是否有安装软件)
4. 配置 krb5.conf 文件
vim /etc/krb5.conf
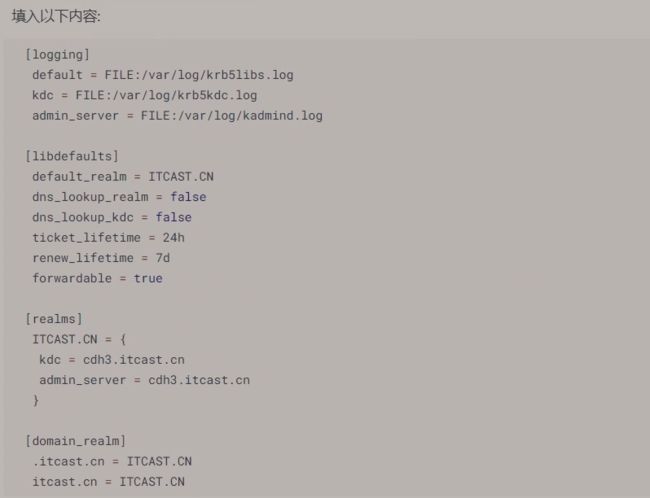
名词讲解:
realms 域 : 表示一个公司或者一个组织,逻辑上的授权认证范围,比如,某个认证账户是属于某个域下的,跨域账户不通用,域和FQDN的配置很像,使用大写。可以配置多个realm
logging :日志配置
libdefaults:配置默认的设置,包括 ticket 的生存周期
domain_real : 是 kerberos 内的域和主机名的域的一个对应关系
.itcast.cn 类似 *.itcast.cn 表示入 cdh0.itcast.cn cdh1.itcast.cn 等均是ITCAST.CN 这个 realm
itcast.cn 表示 itcast.cn 这个主机名也是 ITCAST.CN 这个 realm 的一部分
5. 配置 kdc.conf
vim /var/kerberos/krb5kdc/kdc.conf
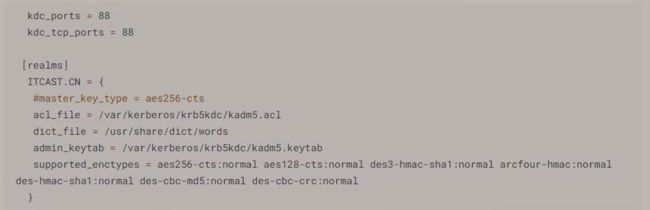
名词解释
acl_file : Kerberos acl 的一些配置对应的文件(权限管控)
admin_keytab : 登录凭证,有了这个相当于直接有了 ticket ,可以免密直接登录某个账户,所以这个文件很重要
supported_enctypes : 支持的加密方式
6. 配置 kadm5.acl 文件
vim /var/kerberos/krb5kdc/kadm5.acl
改为:
其中 */admin 是Kerberos 中的账户形式,如 rm/[email protected] 表示在 cdh0 机器上的 resourcemanager 账户,这个账户属于 ITCAST.CN 这个域
最后 * 表示符合 */admin 的账户拥有所有权限
7. 初始化 kerberos 库
输入:kdb5_util create -s -r ITCAST.CN , 其中 ITCAST.CN 是对应的域,如你的不同请修改
然后要求输入两次密码,输入 krb5kdc 即可
这样就得到数据库 master 账户:K/[email protected] , 密码:krb5kdc
会 在 /var/kerberos/krb5kdc/ 下生成相应的文件

输入:kadmin.local 进入admin 的后台,
执行 listprincs 查看机器当前的账户
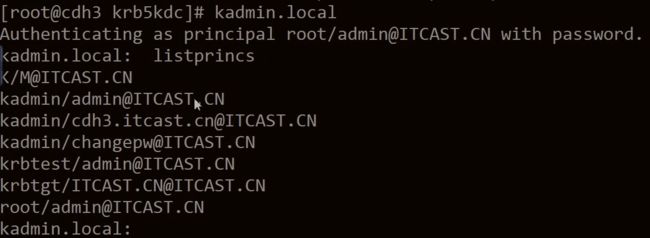
创建账户
addprinc root/[email protected] 输入密码即可,前面账户满足 ITCAST.CN 的管理员账户存在,(满足 */[email protected] 规则,拥有全部权限)
重启 kerberos
# 重启服务
systemctl restart krb5kdc.service
systemctl restart kadmin.service
# 开机启动
chkconfig krb5kdc on
chkconfig kadmin on8. Kerberos 客户端
yum install -y krb5-libs krb5-workstation
客户端 只有一个 /etc/krb5.conf 文件需要配置,复杂 server 端的即可
测试能否登录 admin 账户
kinit test/[email protected] 输入密码回车,没有任何输出说明配置成功

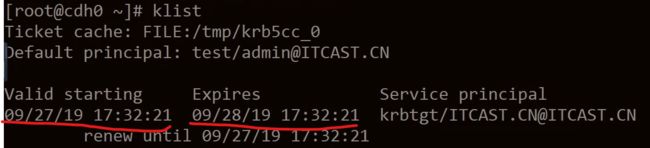
klist 验证 ticket 是否正确(24h 有效期)
kadmin 输入正确的密码 (显示和server端输入 kadmin.local 一样)
输入 listprincs
ok ... 到此,Kerberos 已经安装完成,下面需要配置Hadoop集群,针对Kerberos进行设置
9. hadoop kerberos 认证配置
1) 配置 HDFS
1. 添加用户 (三个节点均执行)
groupadd hadoop;useradd hdfs -g hadoop -p hdfs;useradd hive -g hadoop -p hive;useradd yarn -g hadoop -p yarn;useradd mapred -g hadoop -p mapred(每个账户设置免密登录)
2. 配置HDFS相关的kerberos账户
说明:Hadoop需要kerberos来进行认证,以启动服务来说,在后面配置hadoop的时候我们会给对应服务指定一个kerberos的账户,比如namenode运行在cdh-master机器上,我们将namenode指定给了nn/[email protected] 这个账户,那么想启动namenode就必须认证这个账户才可以。
1. 在每个节点执行 mkdir /etc/security/keytabs (用于存放 key 秘钥文件)
2. 配置cdh-*上运行的服务对应kerbetros账户
(kadmin 登录报错 : kadmin: GSS-API (or Kerberos) error while initializing kadmin interface , 通报不服务器时间更kdc服务器时间一致即可)
# 执行 kadmin
# 输入密码进入kerberos的admin后台 (密码自定义)
################################ cdh-master ################################
# 创建namenode的账户
addprinc -randkey nn/[email protected]
# 创建secondarynamenode的账户
addprinc -randkey sn/[email protected]
# 创建resourcemanager的账户
addprinc -randkey rm/[email protected]
# 创建用于https服务的相关账户
addprinc -randkey http/[email protected]
# 防止启动或者操作的过程中需要输入密码,创建免密登录的keytab文件
# 创建nn账户的keytab
ktadd -k /etc/security/keytabs/nn.service.keytab nn/[email protected]
# 创建rm账户的keytab
ktadd -k /etc/security/keytabs/nn.service.keytab sn/[email protected]
# 创建rm账户的keytab
ktadd -k /etc/security/keytabs/rm.service.keytab rm/[email protected]
# 创建HTTP账户的keytab
ktadd -k /etc/security/keytabs/http.service.keytab http/[email protected]
最终会得到三个文件:
-r-------- 1 hdfs hadoop 406 Sep 27 17:48 nn.service.keytab
-r-------- 1 hdfs hadoop 406 Sep 27 17:48 sn.service.keytab
-r-------- 1 yarn hadoop 406 Sep 27 17:48 rm.service.keytab
-r--r----- 1 hdfs hadoop 406 Sep 27 17:48 http.service.keytab
chmod 修改文件的读写权限
chmod 400 nn.service.keytab
chmod 400 sn.service.keytab
chmod 400 rm.service.keytab
chmod 440 http.service.keytab
(http.service.keytab 整个hadoop组需要web服务,用440权限)
################################ cdh-worker1 ################################
# 创建datanode的账户
addprinc -randkey dn/[email protected]
# 创建nodemanater的账户
addprinc -randkey nm/[email protected]
# 创建http的账户
addprinc -randkey http/[email protected]
# 防止启动或者操作的过程中需要输入密码,创建免密登录的keytab文件
# 创建dn账户的keytab
ktadd -k /etc/security/keytabs/dn.service.keytab dn/[email protected]
# 创建nm账户的keytab
ktadd -k /etc/security/keytabs/nm.service.keytab nm/[email protected]
# 创建http账户的keytab
ktadd -k /etc/security/keytabs/http.service.keytab http/[email protected]
最终会得到三个文件:
-r-------- 1 hdfs hadoop 406 Sep 27 17:48 dn.service.keytab
-r-------- 1 yarn hadoop 406 Sep 27 17:48 nm.service.keytab
-r--r----- 1 hdfs hadoop 406 Sep 27 17:48 http.service.keytab
chmod 修改文件的读写权限
chmod 400 dn.service.keytab
chmod 400 nm.service.keytab
chmod 440 http.service.keytab
(http.service.keytab 整个hadoop组需要web服务,用440权限)
################################ cdh-worker2 ################################
# 创建datanode的账户
addprinc -randkey dn/[email protected]
# 创建nodemanater的账户
addprinc -randkey nm/[email protected]
# 创建http的账户
addprinc -randkey http/[email protected]
# 防止启动或者操作的过程中需要输入密码,创建免密登录的keytab文件
# 创建dn账户的keytab
ktadd -k /etc/security/keytabs/dn.service.keytab dn/[email protected]
# 创建nm账户的keytab
ktadd -k /etc/security/keytabs/nm.service.keytab nm/[email protected]
# 创建http账户的keytab
ktadd -k /etc/security/keytabs/http.service.keytab http/[email protected]
最终会得到三个文件:
-r-------- 1 hdfs hadoop 406 Sep 27 17:48 dn.service.keytab
-r-------- 1 yarn hadoop 406 Sep 27 17:48 nm.service.keytab
-r--r----- 1 hdfs hadoop 406 Sep 27 17:48 http.service.keytab
chmod 修改文件的读写权限
chmod 400 dn.service.keytab
chmod 400 nm.service.keytab
chmod 440 http.service.keytab
(http.service.keytab 整个hadoop组需要web服务,用440权限)
3. 创建数据目录(这个根据自己的安装实际情况设置)
mkdir -p /data/nn;mkdir /data/dn;mkdir /data/nm-local;mkdir /data/nm-log;mkdir /data/mr-history#!/bin/bash
hadoop_home=/opt/bigdata/hadoop/hadoop-3.2.0
dfs_namenode_name_dir=/opt/bigdata/hadoop/dfs/name
dfs_datanode_data_dir=/opt/bigdata/hadoop/dfs/data
nodemanager_local_dir=/opt/bigdata/hadoop/yarn/local-dir1
nodemanager_log_dir=/opt/bigdata/hadoop/yarn/log-dir
mr_history=/opt/bigdata/hadoop/mapred
if [ ! -n "$hadoop_home" ];then
echo "请输入hadoop home路径 ..."
exit
fi
chgrp -R hadoop $hadoop_home
chown -R hdfs:hadoop $hadoop_home
chown root:hadoop $hadoop_home
chown hdfs:hadoop $hadoop_home/sbin/distribute-exclude.sh
chown hdfs:hadoop $hadoop_home/sbin/hadoop-daemon.sh
chown hdfs:hadoop $hadoop_home/sbin/hadoop-daemons.sh
# chown hdfs:hadoop $hadoop_home/sbin/hdfs-config.cmd
# chown hdfs:hadoop $hadoop_home/sbin/hdfs-config.sh
chown mapred:hadoop $hadoop_home/sbin/mr-jobhistory-daemon.sh
chown hdfs:hadoop $hadoop_home/sbin/refresh-namenodes.sh
chown hdfs:hadoop $hadoop_home/sbin/workers.sh
chown hdfs:hadoop $hadoop_home/sbin/start-all.cmd
chown hdfs:hadoop $hadoop_home/sbin/start-all.sh
chown hdfs:hadoop $hadoop_home/sbin/start-balancer.sh
chown hdfs:hadoop $hadoop_home/sbin/start-dfs.cmd
chown hdfs:hadoop $hadoop_home/sbin/start-dfs.sh
chown hdfs:hadoop $hadoop_home/sbin/start-secure-dns.sh
chown yarn:hadoop $hadoop_home/sbin/start-yarn.cmd
chown yarn:hadoop $hadoop_home/sbin/start-yarn.sh
chown hdfs:hadoop $hadoop_home/sbin/stop-all.cmd
chown hdfs:hadoop $hadoop_home/sbin/stop-all.sh
chown hdfs:hadoop $hadoop_home/sbin/stop-balancer.sh
chown hdfs:hadoop $hadoop_home/sbin/stop-dfs.cmd
chown hdfs:hadoop $hadoop_home/sbin/stop-dfs.sh
chown hdfs:hadoop $hadoop_home/sbin/stop-secure-dns.sh
chown yarn:hadoop $hadoop_home/sbin/stop-yarn.cmd
chown yarn:hadoop $hadoop_home/sbin/stop-yarn.sh
chown yarn:hadoop $hadoop_home/sbin/yarn-daemon.sh
chown yarn:hadoop $hadoop_home/sbin/yarn-daemons.sh
chown mapred:hadoop $hadoop_home/bin/mapred*
chown yarn:hadoop $hadoop_home/bin/yarn*
chown hdfs:hadoop $hadoop_home/bin/hdfs*
chown hdfs:hadoop $hadoop_home/etc/hadoop/capacity-scheduler.xml
chown hdfs:hadoop $hadoop_home/etc/hadoop/configuration.xsl
chown hdfs:hadoop $hadoop_home/etc/hadoop/core-site.xml
chown hdfs:hadoop $hadoop_home/etc/hadoop/hadoop-*
chown hdfs:hadoop $hadoop_home/etc/hadoop/hdfs-*
chown hdfs:hadoop $hadoop_home/etc/hadoop/httpfs-*
chown hdfs:hadoop $hadoop_home/etc/hadoop/kms-*
chown hdfs:hadoop $hadoop_home/etc/hadoop/log4j.properties
chown mapred:hadoop $hadoop_home/etc/hadoop/mapred-*
chown hdfs:hadoop $hadoop_home/etc/hadoop/workers
chown hdfs:hadoop $hadoop_home/etc/hadoop/ssl-*
chown yarn:hadoop $hadoop_home/etc/hadoop/yarn-*
chmod 755 -R $hadoop_home/etc/hadoop/*
chown root:hadoop $hadoop_home/etc
chown root:hadoop $hadoop_home/etc/hadoop
chown root:hadoop $hadoop_home/etc/hadoop/container-executor.cfg
chown root:hadoop $hadoop_home/bin/container-executor
chown root:hadoop $hadoop_home/bin/test-container-executor
chmod 6050 $hadoop_home/bin/container-executor
chown 6050 $hadoop_home/bin/test-container-executor
mkdir -p $hadoop_home/logs
mkdir -p $hadoop_home/logs/hdfs
mkdir -p $hadoop_home/logs/yarn
mkdir -p $mr_history/done-dir
mkdir -p $mr_history/intermediate-done-dir
mkdir -p $nodemanager_local_dir
mkdir -p $nodemanager_log_dir
chown -R hdfs:hadoop $hadoop_home/logs
chmod -R 755 $hadoop_home/logs
chown -R hdfs:hadoop $hadoop_home/logs/hdfs
chmod -R 755 $hadoop_home/logs/hdfs
chown -R yarn:hadoop $hadoop_home/logs/yarn
chmod -R 755 $hadoop_home/logs/yarn
chown -R hdfs:hadoop $dfs_datanode_data_dir
chown -R hdfs:hadoop $dfs_namenode_name_dir
chmod -R 700 $dfs_datanode_data_dir
chmod -R 700 $dfs_namenode_name_dir
chown -R yarn:hadoop $nodemanager_local_dir
chown -R yarn:hadoop $nodemanager_log_dir
chmod -R 770 $nodemanager_local_dir
chmod -R 770 $nodemanager_log_dir
chown -R mapred:hadoop $mr_history
chmod -R 770 $mr_history4. 配置hadoop的lib/native (本地运行库)
/opt/bigdata/hadoop/hadoop-3.2.0/lib/native 本地库无需配置
5. 设置HDFS的配置文件
1)hadoop-env.sh 增加 (根据自己的具体配置改路径)
export JAVA_HOME=/usr/java/jdk1.8.0_144
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop-3.2.0
export HADOOP_CONF_DIR=/opt/bigdata/hadoop/hadoop-3.2.0/etc/hadoop
export HADOOP_LOG_DIR=/opt/bigdata/hadoop/hadoop-3.2.0/logs
export HADOOP_COMMON_LIB_NATIVE_DIR=/opt/bigdata/hadoop/hadoop-3.2.0/lib/native
export HADOOP_OPTS="-Djava.library.path=/opt/bigdata/hadoop/hadoop-3.2.0/lib/native"
2)yarn-env.sh 增加 (根据自己的具体配置改路径)
export JAVA_HOME=/usr/java/jdk1.8.0_144
export YARN_CONF_DIR=/opt/bigdata/hadoop/hadoop-3.2.0/etc/hadoop
export YARN_LOG_DIR=/opt/bigdata/hadoop/hadoop-3.2.0/logs/yarn
3)mapred-env.sh 增加 (根据自己的具体配置改路径)
export JAVA_HOME=/usr/java/jdk1.8.0_144
4) core-site.xml 配置如下 (注意 各个节点配置文件不一致 ...)
fs.defaultFS
hdfs://cdh-master:9000
默认文件系统的名字,通常指定namenode的URL地址,包括主机和端口号
io.file.buffer.size
131072
在序列文件中使用的缓存区大小,这个缓存区大小应为页大小的倍数,它决定读写操作中缓存了多少数据
hadoop.security.authorization
true
是否开启hadoop的安全认证
hadoop.security.authentication
kerberos
使用kerberos作为hadoop的安全认证方案
hadoop.security.auth_to_local
RULE:[2:$1@$0](nn/.*@HADOOP.CN)s/.*/hdfs/
RULE:[2:$1@$0](sn/.*@HADOOP.CN)s/.*/hdfs/
RULE:[2:$1@$0](dn/.*@HADOOP.CN)s/.*/hdfs/
RULE:[2:$1@$0](rm/.*@HADOOP.CN)s/.*/yarn/
RULE:[2:$1@$0](nm/.*@HADOOP.CN)s/.*/yarn/
RULE:[2:$1@$0](http/.*@HADOOP.CN)s/.*/hdfs/
DEFAULT
将kerberos主体映射到本地用户名:匹配规则,比如第一行就是表示将nn/*@HADOOP.CN的principal绑定到hdfs账户上,也就是想要得到一个认证后的hdfs账户,请使用Kerberos的nn/*@HADOOP.CN账户来认证
同理,下面的http开头的Kerberos账户,其实也是绑定到了hdfs本地账户上,也就是如果想要操作hdfs,用nn和http都是可以的,只是我们在逻辑上多创建几个kerberos账户好分配,比如namenode分配nn,DataNode分配dn,其实nn和dn都是对应的hdfs
hadoop.proxyuser.hive.hosts
*
hadoop.proxyuser.hive.groups
*
hadoop.proxyuser.hdfs.hosts
*
hadoop.proxyuser.hdfs.groups
*
hadoop.proxyuser.HTTP.hosts
*
hadoop.proxyuser.HTTP.groups
*
hadoop.tmp.dir
/opt/bigdata/hadoop/tmp
其他临时目录的父目录,会配其他临时目录用到
hadoop.http.cross-origin.enabled
true
hadoop.http.cross-origin.allowed-origins
*
hadoop.http.cross-origin.allowed-methods
GET,POST,HEAD
hadoop.http.cross-origin.allowed-headers
X-Requested-With,Content-Type,Accept,Origin
hadoop.http.cross-origin.max-age
1800
hadoop.http.filter.initializers
org.apache.hadoop.security.HttpCrossOriginFilterInitializer
5) hdfs-site.xml 配置如下
dfs.replication
2
副本数设置,值不应大于datanode的数量
dfs.blocksize
268435456
hdfs 上块儿的大小设置
dfs.namenode.name.dir
/opt/bigdata/hadoop/dfs/name
namenode name文件夹
dfs.namenode.handler.count
200
namenode 处理rpc线程数,默认10个
dfs.datanode.data.dir
/opt/bigdata/hadoop/dfs/data
namenode data文件夹设置
dfs.block.access.token.enable
true
数据节点访问令牌标识
dfs.namenode.kerberos.principal
nn/[email protected]
namenode 对应的kerberos账户为 nn/主机名@HADOOP.CN _HOST会自动转换为主机名
dfs.namenode.keytab.file
/etc/security/keytabs/nn.service.keytab
因为使用 -randkey 创建的用户,密码随机的,所以需要用免密登录的keytab文件指定namenode需要用的keytab文件在哪里
dfs.namenode.kerberos.internal.spnego.principal
http/[email protected]
https 相关(如开启namenodeUI)使用的账户
dfs.web.authentication.kerberos.principal
http/[email protected]
web hdfs 使用的账户
dfs.web.authentication.kerberos.keytab
/etc/security/keytabs/http.service.keytab
web 使用的账户对应的keytab文件
dfs.secondary.namenode.kerberos.principal
sn/[email protected]
secondarynamenode 使用的账户
dfs.secondary.namenode.keytab.file
/etc/security/keytabs/sn.service.keytab
sn对应的keytab文件
dfs.secondary.namenode.kerberos.internal.spnego.principal
http/[email protected]
sn需要开启http页面用到的账户
dfs.datanode.kerberos.principal
dn/[email protected]
datanode用到的账户
dfs.datanode.keytab.file
/etc/security/keytabs/dn.service.keytab
datanode 对应的keytab文件路径
dfs.datanode.data.dir.perm
700
datanode data文件夹的权限级别
dfs.permissions.supergroup
hdfs
dfs 权限用户组
dfs.http.policy
HTTPS_ONLY
所有开启的web页面均使用https,细节在ssl server和client那个配置文件内配置
dfs.data.transfer.protection
integrity
dfs.https.port
50070
web 端口号
dfs.webhdfs.enabled
true
dfs.http.address
cdh-master:50070
dfs.secondary.http.address
cdh-master:50090
6. 创建HTTPS证书
每个节点创建文件夹
mkdir -p /etc/security/https
cd /etc/security/https执行 (CN=各个节点的hostname名称)
openssl req -new -x509 -keyout bd_ca_key -out bd_ca_cert -days 99999 -subj /C=CN/ST=beijing/L=beijing/0=test/OU=test/CN=test输入两次密码:(这里使用 123456),得到两个文件,复制到其他节点
然后,在每个节点的 /etc/security/https 文件夹下执行以下命令 (CN=各个节点的hostname名称)
# 1 输入密码 123456 (这里会让重新设置密码,可以同样设置123456,总共输入4次密码),生产一个keystore文件
keytool -keystore keystore -alias localhost -validity 99999 -genkey -keyalg RSA -keysize 2048 -dname "CN=test,OU=test,O=test,L=beijing,ST=beijing,C=CN"
# 2 输入密码和确认密码(123456),提示是否信任证书,输入yes,此命令成功后输入一个truststore文件
keytool -keystore truststore -alias CARoot -import -file bd_ca_cert
# 3 输入密码(123456),此命令成功后输出一个cert文件
keytool -certreq -alias localhost -keystore keystore -file cert
# 4 此命令成功后输出 cert_signed 文件
openssl x509 -req -CA bd_ca_cert -CAkey bd_ca_key -in cert -out cert_signed -days 99999 -CAcreateserial -passin pass:123456
# 5 输入密码和确认密码(123456),是否信任证书,输入yes,此命令成功后更新keystore文件
keytool -keystore keystore -alias CARoot -import -file bd_ca_cert
# 6 输入密码和确认密码(123456)
keytool -keystore keystore -alias localhost -import -file cert_signed
最终得到一下几个文件:
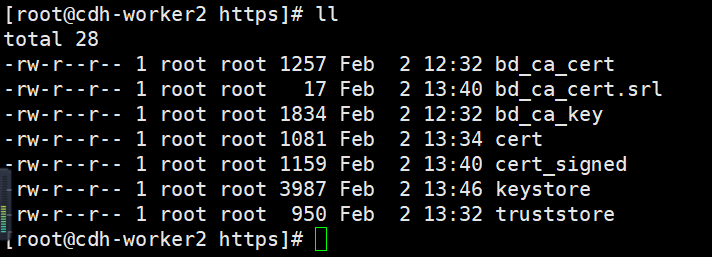
7. 配置ssl-server.xml和ssl-client.xml文件,以及workers文件,并发送到其他节点
上面配置的https证书以及设置的密码等在这里用上
1). ssl-server.xml
ssl.server.truststore.location
/etc/security/https/truststore
ssl.server.truststore.password
123456
ssl.server.truststore.type
jks
Optional. The keystore file format. default value is "jks".
ssl.server.truststore.reload.interval
10000
Truststore reload check interval. in milliseconds. Default value is 10000(10 seconds).
ssl.server.keystore.location
/etc/security/https/keystore
Keystore to be used by NN and DN. Must be specified.
ssl.server.keystore.password
123456
Must be specified.
ssl.server.keystore.keypassword
123456
Must be specified.
ssl.server.keystore.type
jks
Optional.The keystore file format.default value is "jks".
ssl.server.exclude.cipher.list
TLS_ECDHE_RSA_WITH_RC4_128_SHA,SSL_DHE_RSA_EXPORT_WITH_DES40_CBC_SHA,
SSL_RSA_WITH_DES_CBC_SHA,SSL_DHE_RSA_WITH_DES_CBC_SHA,
SSL_RSA_EXPORT_WITH_RC4_40_MD5,SSL_RSA_EXPORT_WITH_DES40_CBC_SHA,
SL_RSA_WITH_RC4_128_MD5
Optional. the weak security cipher suites that you want excluded from SSL communication.
2). ssl-client.xml
ssl.client.truststore.location
/etc/security/https/truststore
Truststore to be used by clients like distcp.Must be specified.
ssl.client.truststore.password
123456
Optional.Default value is "".
ssl.client.truststore.type
jks
Optional.The keystore file format.default value is "jks".
ssl.client.truststore.reload.interval
10000
Truststore reload check interval.in milliseconds. Default value is 10000 (10 seconds).
ssl.client.keystore.location
/etc/security/https/keystore
Keystore to be used by clients like distcp.Must be specified.
ssl.client.keystore.password
123456
Optional. Default value is "".
ssl.client.keystore.keypassword
123456
Optional.Default value is "".
ssl.client.keystore.type
jks
Optional. The keystore file format.default value is "jks".
3). workers 文件
cdh-worker1.hadoop.cn
cdh-worker2.hadoop.cn8. 设置文件权限
hadoop fs -chown hdfs:hadoop /
hadoop fs -mkdir /tmp
hadoop fs -chown hdfs:hadoop /tmp
hadoop fs -chmod 777 /tmp
hadoop fs -mkdir /user
hadoop fs -chmod hdfs:hadoop /user
hadoop fs -chmod 755 /user
hadoop fs -mkdir /mr-data
hadoop fs -chown mapred:hadoop /mr-data
hadoop fs -mkdir /tmp/hadoop-yarn
hadoop fs -chmod 770 /tmp/hadoop-yarn9. 很重要的一步:
报错如下:
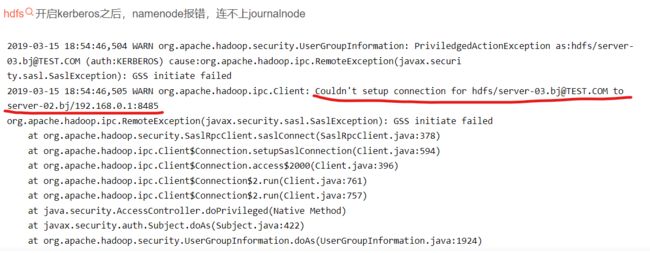
这个是因为jce的问题,下载地址:
https://www.oracle.com/technetwork/java/javase/downloads/jce8-download-2133166.html下载之后解压得到
-rw-rw-r-- 1 root root 3035 Dec 21 2013 local_policy.jar
-rw-r--r-- 1 root root 7323 Dec 21 2013 README.txt
-rw-rw-r-- 1 root root 3023 Dec 21 2013 US_export_policy.jar
拷贝至jre对应目录,然后重启hdfs即可
# cp UnlimitedJCEPolicyJDK8/*.jar $JAVA_HOME/jre/lib/security
2) 配置 yarn
1. 添加kerberos用户
kadmin 进入kerberos admin 后台
# 添加resourcemanager
addprinc -randkey rm/[email protected]
addprinc -randkey rm/[email protected]
addprinc -randkey rm/[email protected]
# 添加job history
addprinc -randkey jhs/[email protected]
addprinc -randkey jhs/[email protected]
addprinc -randkey jhs/[email protected]
# 添加到本地keytabs目录中 三个节点分别执行
ktadd -k /etc/security/keytabs/jhs.service.keytab jhs/[email protected]
ktadd -k /etc/security/keytabs/jhs.service.keytab jhs/[email protected]
ktadd -k /etc/security/keytabs/jhs.service.keytab jhs/[email protected]
# 修改权限
chown mapred:hadoop jhs.service.keytab
chmod 400 jhs.service.keytab2. 配置 yarn-site.xml
yarn.resourcemanager.hostname
cdh-master.hadoop.cn
RM的hostname
yarn.log.server.url
https://cdh-master.hadoop.cn:19888/jobhistory/logs/
yarn.nodemanager.local-dirs
/opt/bigdata/hadoop/yarn/local-dir1
中间结果存放位置,可配置多目录
yarn.log-aggregation-enable
true
是否启用日志聚合
yarn.nodemanager.remote-app-log-dir
/tmp/logs
日志聚合目录
yarn.nodemanager.log-dirs
/opt/bigdata/hadoop/yarn/log-dir
中间结果存放位置,可配置多目录
yarn.log-aggregation.retain-seconds
3600
日志过期时间
yarn.resourcemanager.principal
rm/[email protected]
yarn.resourcemanager.keytab
/etc/security/keytabs/rm.service.keytab
yarn.resourcemanager.webapp.delegation-token-auth-filter.enabled
true
yarn.http.policy
HTTPS_ONLY
yarn.nodemanager.linux-container-executor.group
hadoop
yarn.nodemanager.container-executor.class
org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor
yarn.nodemanager.linux-container-executor.path
/opt/bigdata/hadoop/hadoop-3.2.0/bin/container-executor
yarn.nodemanager.resource.memory-mb
20480
NM总可用物理内存,以MB为单位.不可动态修改
yarn.scheduler.maximum-allocation-mb
20480
可申请的最大内存资源,以MB为单位
yarn.nodemanager.resource.cpu-vcores
5
可分配的CPU个数
yarn.nodemanager.aux-services
mapreduce_shuffle
NodeManager上运行的附属服务.需配置成mapreduce_shuffle,才可运行MapReduce程序
yarn.resourcemanager.address
cdh-master.hadoop.cn:8032
RM对客户端暴露的地址,客户端通过该地址向RM提交应用程序等
yarn.resourcemanager.scheduler.address
cdh-master.hadoop.cn:8030
RM对AM暴露的地址,AM通过地址向RM申请资源,释放资源等
yarn.resourcemanager.resource-tracker.address
cdh-master.hadoop.cn:8031
RM对NM暴露地址,NM通过该地址向RM汇报心跳,领取任务等
yarn.resourcemanager.admin.address
cdh-master.hadoop.cn:8033
管理员可以通过该地址向RM发送管理命令等
yarn.resourcemanager.webapp.address
cdh-master.hadoop.cn:8088
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
yarn.acl.enable
false
Enable ACLs,Defaults to false.
yarn.admin.acl
*
注意:主节点注掉调度器 和 yarn.nodemanager.principal,然后从节点放开yarn.nodemanager.principal
3. 配置mapred.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.principal
jhs/[email protected]
mapreduce.jobhistory.keytab
/etc/security/keytabs/jhs.service.keytab
mapreduce.jobhistory.webapp.spnego-principal
http/[email protected]
mapreduce.jobhistory.webapp.spnego-keytab-file
/etc/security/keytabs/http.service.keytab
mapreduce.jobhistory.http.policy
HTTPS_ONLY
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.jobhistory.address
cdh-master.hadoop.cn:10020
JobHistory服务器IPC 主机:端口
mapreduce.jobhistory.webapp.address
cdh-master.hadoop.cn:19888
JobHistory服务器Web UI地址,用户可根据地址查看Hadoop历史作业情况
mapreduce.jobhistory.done-dir
/opt/bigdata/hadoop/mapred/done-dir
已经运行完成的hadoop作业目录
mapreduce.jobhistory.intermediate-done-dir
/opt/bigdata/hadoop/mapred/intermediate-done-dir
正在运行的hadoop作业记录
4. 配置container-executor.cfg
yarn.nodemanager.local-dirs=/opt/bigdata/hadoop/nm/nm-local
yarn.nodemanager.log-dirs=/opt/bigdata/hadoop/nm/nm-log
yarn.nodemanager.linux-container-executor.group=hadoop
banned.users=bin
min.user.id=100
allowed.system.users=root,yarn,hdfs,mapred,hive,dev注意:/opt/bigdata/hadoop文件夹所属因为 root,container-executor.cfg 文件所属因为 root:hadoop
启动 resourcemanager ,nodemanager ,jobhistory 服务
5. 提交MR程序测试
1. su yarn
2. kinit -kt /etc/security/keytabs/rm.service.keytab rm/[email protected]
2. hadoop jar /opt/bigdata/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /a.sh /a.txt
(/a.sh 和 /a.txt 为 hdfs 路径)3) 配置 hive kerberos 认证
1. 创建hive用户
useradd hive -g hadoop
chown -R hive:hadoop /opt/bigdata/apache-hive-2.3.5-bin2. 创建hive的kerberos账户
在安装 hive 节点,kadmin 进入kerberos后台
addprinc -randkey hive/[email protected]
ktadd -k /etc/security/keytabs/hive.service.keytab hive/[email protected]
修改所属权限
chown hive:hadoop hive.service.keytab
chmod 400 hive.service.keytab3. 上传 mysql-connector-java-5.1.44.jar 到hive的lib目录下
4. 安装 mysql 服务(略 ...)
5. 配置 hive-env.sh
# 参考如下:
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop-3.2.0
export JAVA_HOME=/usr/java/jdk1.8.0_144
export HIVE_HOME=/opt/bigdata/hive/apache-hive-2.3.5-bin
export HIVE_CONF_DIR=/opt/bigdata/hive/apache-hive-2.3.5-bin/conf
6. 配置 hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.88.101:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.server2.authentication
KERBEROS
hive.server2.authentication.kerberos.principal
hive/[email protected]
hive.server2.authentication.kerberos.keytab
/etc/security/keytabs/hive.service.keytab
hive.metastore.sasl.enabled
true
hive.metastore.kerberos.keytab.file
/etc/security/keytabs/hive.service.keytab
hive.metastore.kerberos.principal
hive/[email protected]
hive.metastore.schema.verification
false
datanucleus.schema.autoCreateTables
true
datanucleus.metadata.validate
false
hive.metastore.warehouse.dir
/user/hive/warehouse
7. 初始化hive源数据库
bin/schematool -dbType mysql -initSchema -verbose8. 认证hive账户(后台启动hive前需要先在本机认证kerberos)
kinit -kt /etc/security/keytabs/hive.service.keytab hive/[email protected]9. 启动hive相关服务
nohup bin/hive --service metastore > metastore.log 2>&1 &
nohup bin/hive --service hiveserver2> hiveserver2.log 2>&1 &10. 测试
1. 执行 bin/hive 成功进入后,创建库表等操作
2. 执行 bin/beeline 成功进入后
!connect jdbc:hive2://cdh-master.hadoop.cn:10000/default;principal=hive/[email protected]
然后,创建库表操作(认证完hive,记得将 hive-site.xml 发送到spark的conf目录下,否则spark无法提交任务。)
(Hive Kerberos 认证安装完毕 ...)