ElasticSearch:aggregations 聚合详解
概念
ElasticSearch 中聚合的概念,通俗的讲就是按照一些条件从一个数据集中去统计一些信息,比如统计酒店房间有多少,根据价格区间统计酒店数量这些功能。
官网的解释:聚合可以进行各种组合以构建复杂的数据汇总。可以看作是在一组文档上建立分析信息的工作单元,统计一些文档集。聚合可以将一些独立的功能单元可以被混合在一起来满足你的需求,是一种单独的语法。
kibana的可视化看板就是非常经典的聚合功能的体现。

上图中的每个看板视图的展示,其实都是通过聚合API统计出来的一些数据,比如直方图分布,数据泊松分布等特性。
聚合
ElasticSearch 中有许多不同类型的聚合,每种聚合都有自己的功能和输出,聚合类型大致有四种基本类型。
- Bucketing aggregation 一些满足特定条件的文档的集合,类似 mysql 的 group by。例如:select count(*) from user group by name, bucketing 的作用就是group by name,根据 name 去分组,返回一个特定条件的文档集合。
- Metric aggregation 一些数学运算,对文档进行统计分析,例如:select count(*) from user group by name,count 就是 Metric 的作用,对结果集进行一些计算处理。
- Matrix aggregation 对多个字段进行操作并且返回一个矩阵结果
- Pipeline aggregation 对已经产生的聚合结果进行二次聚合
聚合的基本语法
- aggs 是与query同级的,是聚合操作的根节点
- aggregation_name 是自定义的聚合名字,是在聚合结果中展示的字段名
- aggregation_type 是聚合的类型,比如 min,是 Metric 计算类型中的一种
- aggregation_body 一般是要操作的计算值,如果是脚本则是脚本

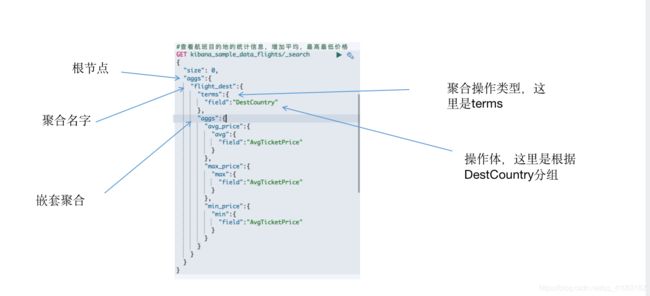
如上是一个简单的聚合语法,其中标识的地方分别对应语法中的操作。
Bucketing aggregation
bucketing的作用就是将文档进行一个分组,也就是 bucketing 的字面意思桶,ElasticSearch会将文档分成划分成为一个个的桶,ElasticSearch 提供了很多类型的 bucketing。
Terms Aggregation
就是一个最简单的分桶策略,也就是group by 策略,他是精确匹配,根据你指定的字段将值相等的文档分在一个桶中。
terms 是精确匹配,也是不分词,所以如果你想要对 text类型的使用terms,需要将field_data 开启
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"country": {
"terms": {
"field": "OriginCountry"
}
}
}
}
如上这条语义就是根据 OriginCountry 国家对航班信息进行 group by。
Filter Aggregation
Filter Aggregation,过滤聚合,其实就是添加了一个分桶的过滤匹配条件,只有符合这个条件的文档才会参与聚合统计。
- filter 为要过滤的条件,语法可以参考查询语法,使用 term、match等都可以
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"country": {
"filter": {
"term": {
"OriginCountry": "US"
}
},
"aggs": {
"ticket": {
"avg": {
"field": "AvgTicketPrice"
}
}
}
}
}
}
结果:
"aggregations" : {
"country" : {
"doc_count" : 2001,
"ticket" : {
"value" : 606.0703937315095
}
}
}
上边这个结果就是只统计国家为us的飞机航班的平均票价,filter为要过滤的条件。
Filters Aggregation
Filters Aggregation 相当于是多个 Filter Aggregation,支持多个匹配条件,但是这里的多个并不是条件叠加,而是类似buckAPi那种的多个API分别执行,然后一次返回,省去网络IO。
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"country": {
"filters": {
"filters": {
"us": {
"match": {
"OriginCountry": "US"
}
},
"cn": {
"match": {
"OriginCountry": "CN"
}
}
}
},
"aggs": {
"ticket": {
"avg": {
"field": "AvgTicketPrice"
}
}
}
}
}
}
如上的聚合语义,是分别统计国家为 us、cn的航班机票平均价格。
Range Aggregation
针对数字类型的字段进行范围分桶,会根据你设定的范围在运行期间对每个文档的这个字段进行check,然后将符合条件的划分到对应的区间中。
- field 是划分的字段
- ranges 表示区间,是个数组,from标识开始,to 表示右区间
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"range_ticket": {
"range": {
"field": "AvgTicketPrice",
"ranges": [
{"to": 400},
{"from": 400,"to": 800},
{"from": 800}
]
}
}
}
}
如上的语义,表示根据票价 0-400,400-800,800-无穷来划分文档区间。
Histogram Aggregation
Histogram Aggregation,直方图分桶统计,意思就是按照给定的区间自动增长去统计在这个区间的文档,比如给了200,那么区间统计就是 [0,200],[200,400]…
- interval 区间值
- min_doc_count 最小多少文档才会显示
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"range_ticket": {
"histogram": {
"field": "AvgTicketPrice",
"interval": 200,
"min_doc_count": 0
}
}
}
}
如上语义所示,表示显示航班票价的各个区间文档数,每隔200统计一次。
Metric aggregation
- Metric 大多数都是在做一些数学运算,除了在字段上进行计算,也自持脚本产生的结果上进行运算。
- 大多数 Metric 值输出一个值
- 部分 Metric 支持输出多个值 stats / percentiles / percentiles_ranks
Avg Min Max Sum
- Avg 是计算平均值的统计指标方法。
- Min 是计算最小值的统计指标方法。
- Max 是计算最大值的统计指标方法。
- Sum 是求和的统计指标方法。
- 只针对数字类型的字段
- missing 字段可以过滤掉那个值不参与平均值计算
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"avg_ticket": {
"avg": {
"field":"AvgTicketPrice",
"missing": 10000
}
},
"max_ticket": {
"max": {
"field": "AvgTicketPrice"
}
},
"min_ticket": {
"min": {
"field": "AvgTicketPrice"
}
},
"sum_ticket": {
"sum": {
"field": "AvgTicketPrice"
}
}
}
}
如上语法表示我们对 AvgTicketPrice 求平均值,并且过滤掉 10000 的值。
Weighted Avg Aggregation
Weighted Avg Aggregation 相对于Avg Aggregation,多了一个比重的影响因素,就是在原先的平均值上会去乘以你设置的那个比重字段然后再加入平均值的计算。
- weight 比重字段
- missing 字段可以过滤掉那个值不参与平均值计算
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"avg_ticket": {
"weighted_avg": {
"value": {
"field": "AvgTicketPrice"
},
"weight": {
"field": "dayOfWeek"
}
}
}
}
}
如上语法表示我们对 AvgTicketPrice 求平均值,并且还要与星期几相乘做计算。
Cardinality Aggregation
Cardinality Aggregation 类似于 count,但是他多了一个功能是去重,只对唯一的数字做统计,有些类似 distinct count
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"country_count": {
"cardinality": {
"field": "DestCountry"
}
}
}
}
如上的这个语义是对航班的经过的国家做了一个统计,这是去重的。
Stats Aggregation
Stats Aggregation 英译数据聚合,其实就是多个聚合的一个集合。
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"stats_ticket": {
"stats": {
"field":"AvgTicketPrice",
"missing": 10000
}
}
}
}
结果:
"aggregations" : {
"stats_ticket" : {
"count" : 13059,
"min" : 100.0205307006836,
"max" : 1199.72900390625,
"avg" : 628.2536888148849,
"sum" : 8204364.922233582
}
}
可以看到,stats其实就是将 count、min、max、avg、sum 等函数做了一个聚合。
Percentiles Aggregation
多值指标聚合,其实就是计算文档中这个字段值的百分位数,默认是有五个,大致会先将文档的值从小到大排放,然后根据公式计算出这个百分位上的数字,这个数字一般用来观察分布是否均匀,这个跟数学的统计学有关系。
百分数的概念:http://blog.sina.com.cn/s/blog_4a082449010180bo.html
- percents 可以只指定观看那几个百分位点的,“percents”: [95,99,99.9]
- keyed 决定返回的值是按照数组来返回还是按照直接文档
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"percentiles_ticket": {
"percentiles": {
"field":"AvgTicketPrice",
"keyed": true
}
}
}
}
结果:
"aggregations" : {
"percentiles_ticket" : {
"values" : {
"1.0" : 118.42046473693847,
"5.0" : 187.9974905499074,
"25.0" : 410.0089175627301,
"50.0" : 640.3872852064159,
"75.0" : 842.2746839881264,
"95.0" : 1035.2816321122016,
"99.0" : 1166.9782329101563
}
}
}
如上可以看到,每个百分位的数都已经展示出来了。
Percentile Ranks Aggregation
Percentile Ranks Aggregation 与 Percentiles Aggregation正好相反,Percentile Ranks Aggregation 是知道值以后去查看他所在的百分数是多少。
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"percentiles_ticket": {
"percentile_ranks": {
"field":"AvgTicketPrice",
"values": [410,842]
}
}
}
}
结果:
"aggregations" : {
"percentiles_ticket" : {
"values" : {
"410.0" : 25.025135114650837,
"842.0" : 74.9653263900661
}
}
}
Top Hits Aggregation
Top Hits Aggregation 是很有用的一个聚合函数,他的功能是将你当前的搜索条件中筛选出排名前几的几个文档,一般这个与terms分桶一起使用,可以很方便的统计出一些你想要的数据来。
- sort 指定要获取排名的字段,order 可以指定是倒序还是升序
- size 可以指定你获取前几条数据
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"country": {
"terms": {
"field": "OriginCountry",
"size": 3
},
"aggs": {
"ticket": {
"top_hits": {
"size": 2,
"sort": [
{
"AvgTicketPrice": {
"order": "desc"
}
}
]
}
}
}
}
}
}
这个语义就是先根据国家分桶,然后选出每个国家中机票价格排名前二的文档出来。
Pipeline aggregation
其实就是对聚合产生的结果进行第二次聚合分析,也就是管道的概念,linux的管道其实就是将一个的结果作为输入来处理。
Pipeline 的分析结果会输出到原结果中,根据位置的不同,分为两类
- Sibling - 结果和现有分析结果同级,pipeline 聚合结果会与原先的结果并立。
○ Max,min,Avg & Sum Bucket
○ Stats,Extended Status Bucket
○ Percentiles Bucket - Parent - pipeline 结果会内嵌到现有的聚合分析结果之中
○ Derivative (求导)
○ Cumultive Sum (累计求和)
○ Moving Function (滑动窗⼝)
Max min Avg & Sum Bucket Aggregation
作用与 Metric 相似,不过是对聚合产生的结果进行二次统计计算。
- 语法与正常的聚合语法一样
- buckets_path 指定你要计算的聚合字段,比如第一次聚合的字段为 tickets,那么这里可以填tickets,有可以填一个表达式,只要是第一次聚合里边有的字段就可以
- Sibling bucket是将聚合语法跟在原先的聚合后
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"tickets": {
"terms": {
"field": "OriginCountry"
},
"aggs": {
"avg_ticket": {
"avg": {
"field": "AvgTicketPrice",
"missing": 10000
}
}
}
},
"piple_avg": {
"avg_bucket": {
"buckets_path": "tickets>avg_ticket"
}
},
"piple_min": {
"min_bucket": {
"buckets_path": "tickets>avg_ticket"
}
},
"piple_max": {
"max_bucket": {
"buckets_path": "tickets>avg_ticket"
}
},
"piple_sum": {
"sum_bucket": {
"buckets_path": "tickets>avg_ticket"
}
}
}
}
如上语义标识,对第一次聚合产生的tickets进行二次聚合,第一次聚合是根据国家将平均票价统计出来,Pipeline聚合是对tickets中跳转出大于平均票价的文档进行最大最小值统计分析。
Stats,Extended Status Bucket
Stats,Extended Status Bucket 等于之前的用法相似。
Derivative
求导统计,是对聚合结果进行求导。
- Parent 与 Sibling 的写法位置是不一样的,parent的写法必须写在原先聚合的里边,写在外边会报错,当然返回结果也是在原聚合里
- Derivative 的父聚合必须为 histogram 直方图类型的。
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"tickets": {
"histogram": {
"field": "AvgTicketPrice",
"interval": 200
},
"aggs": {
"avg_ticket": {
"avg": {
"field": "AvgTicketPrice",
"missing": 10000
}
},
"piple_Derivative": {
"derivative": {
"buckets_path": "avg_ticket"
}
}
}
}
}
}
Cumulative Sum Aggregation
Cumulative Sum Aggregation 是对聚合的结果进行累计求个,会将之前的结果每次都相加。
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"tickets": {
"histogram": {
"field": "AvgTicketPrice",
"interval": 200
},
"aggs": {
"avg_ticket": {
"avg": {
"field": "AvgTicketPrice",
"missing": 10000
}
},
"piple_cumulative": {
"cumulative_sum": {
"buckets_path": "avg_ticket"
}
}
}
}
}
}
这个结果就是对之前的票价每次都叠加统计,比如第一统计为 100,第二次统计为200,那么第三次统计就成为了300.
Moving Average Aggregation
Moving Average Aggregation,其实就是给定一个偏移量,然后每次根据你给定的这个数字,取出对应的数据进行平均统计,然后将位置+1继续统计,直到文档结束。
比如给定一个这样的文档:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
设定窗口大小为5,那么他的结果为:
(1 + 2 + 3 + 4 + 5) / 5 = 3
(2 + 3 + 4 + 5 + 6) / 5 = 4
(3 + 4 + 5 + 6 + 7) / 5 = 5
…
- window 窗口大小,也就是每次选取的数据大小
- mode 移动比重的计算
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"tickets": {
"histogram": {
"field": "AvgTicketPrice",
"interval": 200
},
"aggs": {
"avg_ticket": {
"avg": {
"field": "AvgTicketPrice",
"missing": 10000
}
},
"piple_moving": {
"moving_avg": {
"buckets_path": "avg_ticket",
"window": 5,
"model": "holt"
}
}
}
}
}
}
Matrix aggregation
对多个字段进行计算并且返回相应的计算结果,也就是一个矩阵。
Matrix Stats
关于 Matrix aggregation,elasticSearch 目前只有一种 Matrix Stats 计算。
- fields中指定你要统计的字段
- count 表示统计文档总数
- mean 表示平均值
- variance 每场测量样本从均值分布的程度。
- skewness 每场测量可量化均值周围的不对称分布。
- kurtosis 每场测量可量化分布的形状。
- covariance 定量描述一个领域中的变化与另一个领域相关联的矩阵。
- correlation 协方差矩阵缩放到-1到1(含)范围。描述字段分布之间的关系。
POST kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"tickets": {
"matrix_stats": {
"fields": ["AvgTicketPrice","DistanceMiles","FlightTimeMin"]
}
}
}
}
